【今日CV 计算机视觉论文速览 第124期】Tue, 4 Jun 2019
今日CS.CV 计算机视觉论文速览
Tue, 4 Jun 2019
Totally 62 papers
?上期速览✈更多精彩请移步主页

Interesting:
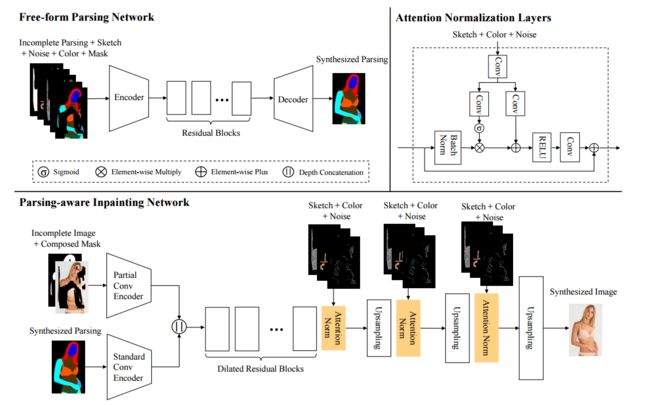
?FE-GAN)于多尺度注意力机制的时尚图像编辑, 提出了一种可交互的图像操作技术(from 中山大学)
一些交互式操作后生成的新服饰图像结果,输入包含原图、草图和稀疏的颜色线条:

首先利用不完整的部分图,草图、噪音颜色掩膜来训练如何合成图像的语义结构,随后利用不完整的图像、完整的掩膜和合成的语义结构来补全,并利用输入的草图和颜色笔画进行属性操作。主要网络框架如下图所示:
一些结果的比较:


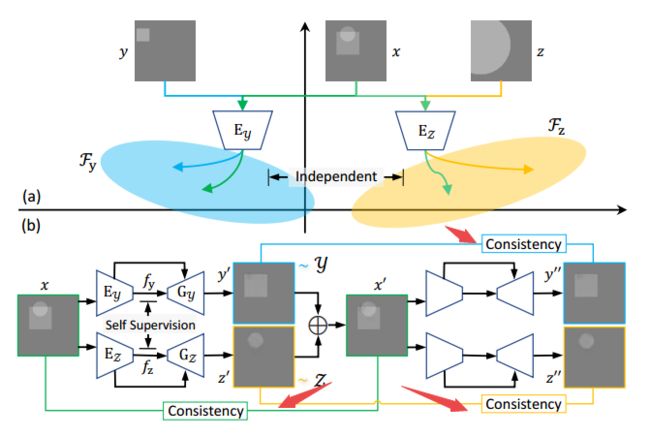
?非监督的单图像图层分离,假设前后混叠的图像互补相关,并提出了cycleGAN的方法联合自监督手段实现图层分离。对于反射混叠和图像分离十分有用 (from 北航)
假设y,z的信息在x中都可以找到,分离后的y、z是独立的分布(联合概率分布为0)。研究人员提出的USIS,将图像分别解码为fx,fy信号,并生成对应的y,z图像,并在最后实现自监督方法得到分离结果。
一些结果:

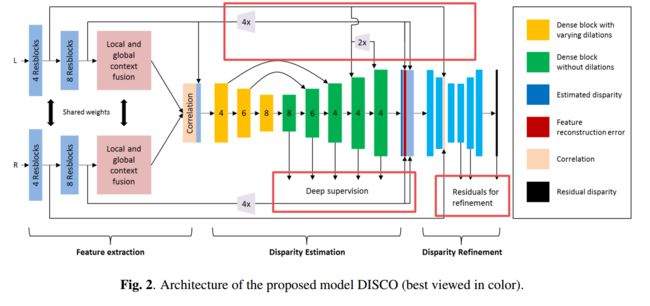
?DISCO利用立体视图输入推断深度, 为了解决对于底层信息的缺失和多级内容的探索,研究人员提出了一种网络来保留空间信息,并通过多层来实现大感受野来抽取多级特征,同时构建了合成日常视差数据集,训练了DISCO并在基准上进行测试。(from 三星印度研究院)
深度图的估计公式,f为焦距B为基线,δ为像素的视差:
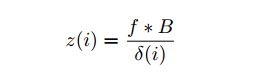
网络架构如下图所示,包含了特征抽取、视差估计和视差精炼(底层信息接入),下采样2(blue)+3(yellow)次,解码5次上采样配合:
correlation层信息融合方式:

利用Blender合成数据集:

与一些方法的对比:
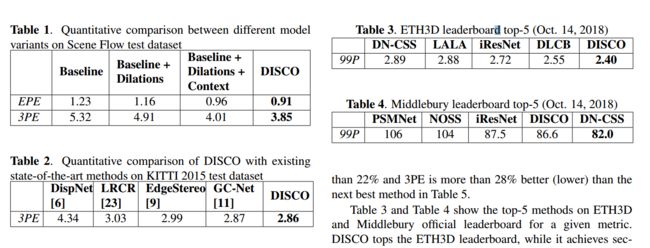
其中B代表基线,C代表纹理信息的加入:

datset:
立体视觉MiddleBury,有一些数据集获取的参考文献
视觉组
光流数据集
ETH3D multi-view stereo / 3D reconstruction
Scene Flow Datasets 包含视差图 弗莱堡大学视觉组
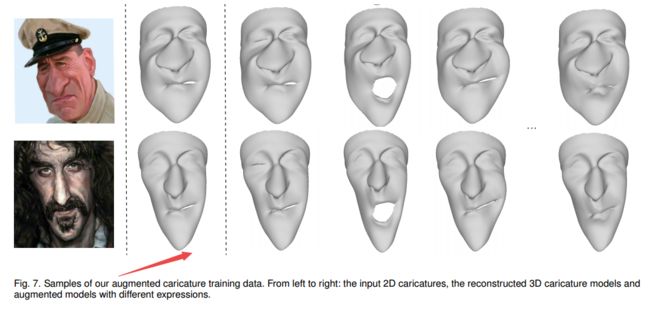
?视频三维漫画夸张卡通化技术3D Magic Mirror, 研究人员首先重建了每一帧的3D人脸,随后将将3D人脸形状从普通迁移到了漫画风格,通过新颖的识别和表情保留VAE-CycleGAN实现。并将多视角的CariGANs生成的问题重建到变性后的三维模型上去(from 中科大)

一些漫画图像的训练数据:
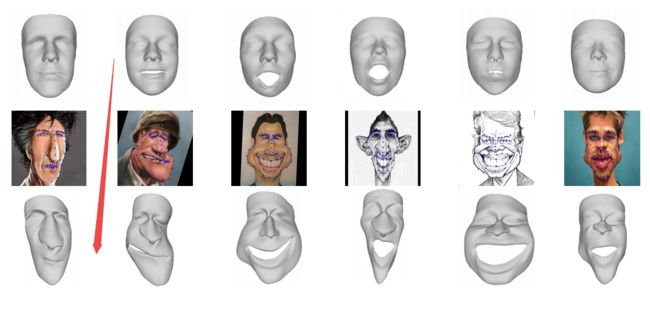
人脸变形方法:
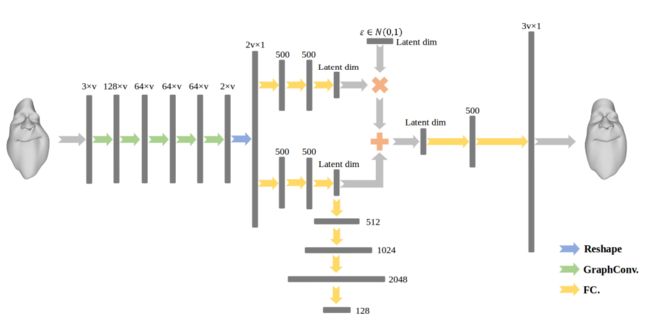
编码器架构:
?Probabilistic Noise2Void ,PN2V,无监督的基于内容的去噪方法, 研究人员提出了一种概率的Noise2Void去噪方法,通过CNN来预测每个像素的强度分布,利用这种对于噪声合适的描述得到了完全概率模型,针对每个像素获得了完整的噪声观察和信号。(from MPI-CBG/PKS ,CSBD)
基于极大似然训练的方法预测每个像素的概率分布,其中si为干净图像,x为退化后的图像。:
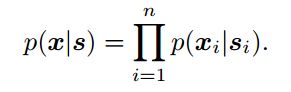 ------->
------->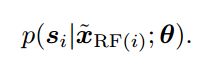
MMSE(Minimal Mean Squared Error)估计的结果如下所示,其中后验信号来自于先验蓝线与观测绿线的比例乘积

最终的估计结果如下图所示:

dataset:PN2V on datasets provided by Zhang et al. in [13]
TL;DwR
5K-Indicators方法解决K均值在大数据下的效率问题,KindAP机制
5基于纹理和法向量的三维表面高分辨生成,引入了3D appearance SR (3DASR)数据集,包含了数据集合成方法,ref: EHT3D [42], MiddleBury [43], and Collection of Bird,Beethoven and Bunny from the multi-view dataset of TUM[21], Fountain [51] and Relief [53]. code:https://github.com/ofsoundof/3D_Appearance_SR
6 VQ-VAE-2来自deepmind的高保真图像生成方法, code:https://github.com/deepmind/sonnet/blob/master/sonnet/python/modules/nets/vqvae.py https://github.com/deepmind/sonnet/blob/master/sonnet/python/modules/nets/vqvae.py, attaches
核磁共振与CT图像的融合Fusion W-Net (FW-Net), code:https://github.com/fanfanda/Medical-Image-Fusion
对于场景的视觉理解和叙述
4iMet大都会博物馆艺术品数据集
钢筋计数,中心定位
声音和视觉协同进行视觉理解
三维检索的新损失collaborative inner product loss
4RF-Net端到端的图像匹配网络,从匹配图像中输出分数图、方向图和尺度图,ref:LIFT, LF-Net,
全貌.全景边缘检测
对抗样本对于边缘检测分析研究
NIND,利用不同ISO和快门获取包含噪声的自然图像数据集 dataset:Natural Image Noise Dataset:https://commons.wikimedia.org/wiki/Natural_Image_Noise_Dataset
利用相似域网络模型进行表面建模和骨架抽取
UZSIT无监督的零样本图像迁移方法ZstGAN, code:https://github.com/linjx-ustc1106/ZstGAN-PyTorch
无监督元域图像迁移模型, code:https://github.com/linjx-ustc1106/MT-GAN-PyTorch
ArcticNet用于极地地区湿地分类的模型,code:https://github.com/geekJZY/arcticnet
用于diffuse optical tomography (DOT)光扩散层析成像的非局域前向模型
小数据集上的胸部X光检测
Daily Computer Vision Papers
| 3D Appearance Super-Resolution with Deep Learning Authors Yawei Li, Vagia Tsiminaki, Radu Timofte, Marc Pollefeys, Luc van Gool 我们解决了从多个视点捕获的对象的高分辨率HR纹理贴图的问题。在多视图情况下,最近已证明基于模型的超分辨率SR方法可恢复高质量纹理图。另一方面,基于深度学习的方法的出现已经对视频和图像SR的问题产生了重大影响。然而,仍然缺少基于深度学习的方法来超级解决3D对象的外观。在多视图情况下利用深度学习技术的力量的主要限制是缺乏数据。我们介绍了基于现有ETH3D 42,SyB3R 31,MiddleBury以及TUM 21,Fountain 51和Relief 53的3D场景集合的3D外观SR 3DASR数据集。我们提供高分辨率和低分辨率纹理贴图,3D几何模型,图像和投影矩阵。我们利用基于2D学习的SR方法和适用于3D多视图案例的设计网络的强大功能。我们通过引入法线贴图来整合几何信息,并进一步改善学习过程。实验结果表明,我们提出的网络成功地结合了3D几何信息并超级解析了纹理贴图。 |
| The iMet Collection 2019 Challenge Dataset Authors enyang Zhang, Christine Kaeser Chen, Grace Vesom, Jennie Choi, Maria Kessler, Serge Belongie 图形识别中现有的计算机视觉技术主要集中在实例检索或粗粒度属性分类上。在这项工作中,我们提出了一个新的数据集,用于细粒度的艺术品属性识别。数据集中的图像是大都会艺术博物馆的经典艺术作品的专业照片,注释由世界级博物馆专家策划和验证。此外,我们还将展示iMet Collection 2019 Challenge作为FGVC6研讨会的一部分。通过比赛,我们的目标是激发细粒度视觉识别研究社区的热情,并提升博物馆馆藏数字化的最新技术水平。 |
| Automated Steel Bar Counting and Center Localization with Convolutional Neural Networks Authors Zhun Fan, Jiewei Lu, Benzhang Qiu, Tao Jiang, Kang An, Alex Noel Josephraj, Chuliang Wei 自动钢筋计数和中心定位在钢筋的工厂自动化中起着重要作用。传统方法仅关注钢筋计数,其性能通常受到复杂工业环境的限制。卷积神经网络CNN具有很强的处理挑战环境中复杂任务的能力,适用于这项工作。提出了一种称为CNN DC的框架,以同时实现自动钢筋计数和中心定位。所提出的框架CNN DC首先用深CNN检测候选中心点。然后提出了一种有效的聚类算法 - 距离聚类DC,对候选中心点进行聚类,找到真正的钢筋中心。所提出的CNN DC可以在已建立的钢筋数据集上实现99.26的钢筋计数精度和4.1中心偏移的中心定位,这表明所提出的CNN DC在自动化钢筋计数和中心定位方面表现良好。代码公开于 |
| Fashion Editing with Multi-scale Attention Normalization Authors Haoye Dong, Xiaodan Liang, Yixuan Zhang, Xujie Zhang, Zhenyu Xie, Bowen Wu, Ziqi Zhang, Xiaohui Shen, Jian Yin 交互式时尚图像处理,使用户能够用草图和颜色笔划编辑图像,是一个有趣的研究问题,具有很大的应用价值。现有作品通常将其视为一般的修复任务,并且不充分利用时尚图像中的语义结构信息。此外,它们直接利用传统的卷积和归一化层来恢复不完整的图像,这往往会冲掉草图和颜色信息。在本文中,我们提出了一种新颖的时尚编辑生成对抗网络FE GAN,它能够通过自由形式草图和稀疏颜色笔划来操纵时尚图像。 FE GAN由两个模块1组成,一个自由形式的解析网络,通过操纵草图和颜色来学习控制人类解析生成2一个解析感知的修复网络,它使用人类解析图中的语义指导呈现详细的纹理。在修复网络的解码器中以多个尺度进一步应用新的注意归一化层,以提高合成图像的质量。对高分辨率时尚图像数据集的大量实验表明,所提出的方法明显优于图像处理的现有技术方法。 |
| Zero-Shot Semantic Segmentation Authors Maxime Bucher, Tuan Hung Vu, Matthieu Cord, Patrick P rez 语义分割模型在扩展到大量对象类的能力方面受到限制。在本文中,我们介绍了零镜头语义分割学习像素明智分类器的新任务,对于从未见过的具有零训练样例的对象类别。为此,我们提出了一种新颖的架构ZS3Net,它将深度视觉分割模型与从语义词嵌入生成视觉表示的方法相结合。通过这种方式,ZS3Net解决了像素分类任务,其中看到和看不见的类别都在测试时面对,所谓的广义零射击分类。通过自我训练步骤进一步改善了性能,该步骤依赖于来自看不见的类的像素的自动伪标记。在两个标准分段数据集Pascal VOC和Pascal Context上,我们提出零射击基准并设置竞争基线。对于Pascal Context数据集中的复杂场景,我们通过使用图形上下文编码来扩展我们的方法,以充分利用来自类智能分割图的空间上下文先验。 |
| GazeCorrection:Self-Guided Eye Manipulation in the wild using Self-Supervised Generative Adversarial Networks Authors Jichao Zhang, Meng Sun, Jingjing Chen, Hao Tang, Yan Yan, Xueying Qin, Nicu Sebe 凝视校正旨在通过操纵眼睛区域将人的注视重定向到相机中,并且可以将其视为特定的图像再合成问题。凝视校正在现实生活中具有广泛的应用,例如盯着相机拍照。在本文中,我们提出了一种基于修复模型的新方法,用于从面部图像中学习以用代表校正眼睛注视的新内容填充缺失的眼睛区域。此外,我们的模型不需要标记有特定头部姿势和眼睛角度信息的训练数据集,因此,训练数据易于收集。为了保留原始输入中眼睛区域的身份信息,我们提出了一种自引导预训练模型来学习角度不变特征。实验表明,我们的模型在从网站收集的野生数据集中实现了非常引人注目的凝视校正结果,并将详细介绍。代码可在 |
| DualDis: Dual-Branch Disentangling with Adversarial Learning Authors Thomas Robert, Nicolas Thome, Matthieu Cord 在计算机视觉中,解开技术旨在通过模拟变异因素来改善图像的潜在表示。在本文中,我们提出了DualDis,一种新的基于自动编码器的框架,它解开并线性化类和属性信息。这是通过两个分支架构来实现的,该架构强制分离两种信息,并伴有用于图像重建和生成的解码器。为了有效地分离信息,我们建议使用常规和对抗分类器的组合来指导两个分支分别专门处理类和属性信息。我们还研究了使用半监督学习即使使用少量标签进行有效解开的可能性。我们利用潜在空间的线性化属性进行语义图像编辑和生成新图像。我们通过分类指标,可视化图像处理和数据增强来衡量信息分离的效率,从而验证了我们对CelebA,耶鲁B和NORB的方法。 |
| Efficient Object Detection Model for Real-Time UAV Applications Authors Subrahmanyam Vaddi, Chandan Kumar, Ali Jannesari 无人驾驶飞行器近年来,配备有视觉技术的无人机尤其是无人机已经变得非常流行,其广泛应用于各种应用。这些应用中的许多应用需要使用计算机视觉技术,特别是从车载相机捕获的信息中检测物体。在本文中,我们提出了一种在无人机平台上运行的端到端对象检测模型,该模型适用于实时应用。我们提出了一个深度特征金字塔体系结构,它利用从卷积网络中提取的特征的固有属性,捕获图像中的更多通用特征,如边缘,颜色等,以及特定于我们问题中包含的类的细微特征。我们使用VisDrone 18数据集进行研究,其中包含不同的对象,如行人,车辆,自行车等。我们提供本研究中使用的平台的软件和硬件架构。我们将ResNet和MobileNet作为卷积基础实现了我们的模型。我们的模型结合改进的焦点丢失功能,为物体检测产生了理想的30.6 mAP性能,推理时间为14 fps。我们将我们的结果与RetinaNet ResNet 50和HAL RetinaNet进行了比较,结果表明我们的模型结合MobileNet作为后端特征提取器在精度,速度和内存效率方面给出了最佳结果,最适合用无人机进行实时物体检测。 |
| Separate from Observation: Unsupervised Single Image Layer Separation Authors Yunfei Liu, Feng Lu 无监督的单图像层分离旨在从输入图像中提取两个层,其中这些层遵循不同的分布。该问题最显着地出现在反射推断消除和固有图像分解中。由于存在可以构造给定输入图像的无限组合,因此可以在没有额外假设的情况下推断出解决方案。为了解决这个问题,我们制定了共享信息一致性假设和分离层独立性假设来约束解决方案。为此,我们提出了一种基于循环GAN和自监督学习的无监督单图像分离框架。所提出的框架适用于反射消除和内在图像问题。数值和视觉结果表明,所提出的方法在需要单个图像作为输入的无监督方法中实现了现有技术的性能。基于所提出框架的略微修改版本,我们还展示了将图像分解为三层的有希望的结果。 |
| Masked Non-Autoregressive Image Captioning Authors Junlong Gao, Xi Meng, Shiqi Wang, Xia Li, Shanshe Wang, Siwei Ma, Wen Gao 现有字幕模型通常采用编码器解码器架构,其中解码器使用自回归解码来生成字幕,使得在给定前面生成的令牌的情况下顺序地生成每个令牌。然而,自回归解码导致诸如顺序错误累积,生成缓慢,语义不正确和缺乏多样性之类的问题。已经提出非自回归解码来解决神经机器翻译的慢速生成,但是由于目标分布的间接建模而遭受多模态问题。在本文中,我们提出掩蔽的非自回归解码来解决自回归解码和非自回归解码的问题。在掩蔽的非自回归解码中,我们在训练期间掩蔽输入序列的几种比率,并且在推理期间以组合方式从完全掩蔽的序列到完全非掩蔽的序列在几个阶段中并行地生成字幕。实验上,我们提出的模型可以更有效地保留语义内容,并可以生成更多样化的字幕。 |
| cGANs with Conditional Convolution Layer Authors Min Cheol Sagong, Yong Goo Shin, Yoon Jae Yeo, Seung Park, Sung Jea Ko 已经广泛研究了条件生成对抗网络cGAN以使用单个生成器生成类条件图像。然而,在传统的cGAN技术中,由于不管条件如何都使用具有相同权重的标准卷积层,因此发生器学习条件特定特征仍然具有挑战性。在本文中,我们提出了一种新的卷积层,称为条件卷积层,它通过使用根据条件调整的权重直接生成不同的特征映射。更具体地,在每个条件卷积层中,通过滤波方式缩放和信道方式移位操作以简单但有效的方式调整权重。与传统方法相比,所提出的具有单个发生器的方法可以有效地处理条件特定的特征。 CIFAR,LSUN和ImageNet数据集的实验结果表明,与标准卷积层相比,具有所提出的条件卷积层的生成器实现了更高的条件图像生成质量。 |
| An Adaptive Training-less System for Anomaly Detection in Crowd Scenes Authors Arindam Sikdar, Ananda S. Chowdhury 人群视频中的异常检测已成为计算机视觉社区的一个热门研究领域。几种现有方法通常在使用或不使用标记数据的情况下执行关于场景的在先训练。但是,很难始终保证先前数据的可用性,特别是对于远程区域监视等情况。为了解决这样的挑战,我们提出了一种自适应训练系统,能够动态地检测异常,同时基于某些参数动态地估计和调整响应。这使得我们的系统既可以减少训练,也可以进行自适应我们的管道由三个主要部分组成,即基于多目标检测的自适应3D DCT模型,通过显着调制光流的局部运动结构描述,以及基于地球移动器距离EMD的异常检测。尽管没有经过培训,但所提出的模型在公共可用的UCSD,UMN,CHUK Avenue和ShanghaiTech数据集上与几种最先进的方法相比具有可比性。 |
| Deeply-supervised Knowledge Synergy Authors Dawei Sun, Anbang Yao, Aojun Zhou, Hao Zhao 卷积神经网络与开创性的AlexNet相比,CNN变得更加深入和复杂。然而,当前流行的训练方案遵循先前的方式,即仅对网络的最后一层添加监督并逐层传播错误信息。在本文中,我们提出深度监督的知识协同DKS,这是一种新的方法,旨在训练CNN具有改进的图像分类任务的泛化能力,而不会在推理过程中引入额外的计算成本。受深度监督学习计划的启发,我们首先在某些中间网络层之上添加辅助监督分支。虽然正确使用辅助监督可以在一定程度上提高模型的准确性,但我们更进一步探索利用连接到骨干网络的分类器动态学习的概率知识作为新的正则化来改进训练的可能性。提出了一种新的协同损失,它考虑了所有监管部门之间的成对知识匹配。有趣的是,它在每次训练迭代时都能够在自上而下和自下而上的方向上进行密集的成对知识匹配操作,类似于同一任务的动态协同过程。我们使用最先进的CNN架构评估图像分类数据集上的DKS,并显示使用它训练的模型始终优于相应的对应物。例如,在ImageNet分类基准测试中,我们的ResNet 152模型优于基线模型,前1精度为1.47。代码可在 |
| A Closed-form Solution to Universal Style Transfer Authors Ming Lu, Hao Zhao, Anbang Yao, Yurong Chen, Feng Xu, Li Zhang 通用样式传输尝试明确地最小化特征空间中的损失,因此它不需要对任何预定义样式进行训练。它通常使用不同的VGG网络层作为编码器,并训练几个解码器将特征反转为图像。因此,通过特征变换实现了样式转移的效果。尽管已经提出了许多方法,但仍然缺少对特征变换的理论分析。在本文中,我们首先提出一种新的解释,将其作为最佳运输问题。然后,我们展示了我们的配方与自适应实例标准化AdaIN和美白和着色变换WCT等以前的工作之间的关系。最后,我们通过另外考虑Gatys的内容损失,在我们的公式中得出一个封闭形式的解决方案。相比之下,我们的解决方案可以保留更好的结构并实现视觉上令人愉悦它简单而有效,我们在数量和质量上都展示了它们的优点。此外,我们希望我们的理论分析可以激发未来神经风格转移的工作。 |
| Robust copy-move forgery detection by false alarms control Authors Thibaud Ehret 可靠地检测复制移动伪造是困难的,因为图像确实包含类似的对象。问题是如何丢弃自然图像的自相似性,同时仍然检测到复制移动的部分是不自然的相似复制移动可能是在旋转,比例变化之后执行,然后是JPEG压缩或添加噪声。出于这个原因,我们将方法基于SIFT,它提供了具有缩放,旋转和光照不变描述符的稀疏关键点。为了区分自然描述符匹配和人工描述符匹配,我们引入了一种相反的方法,它为错误警报的数量提供了理论上的保证。我们在几个数据库上验证我们的方法完全无人监督,它可以集成到任何通用的自动图像篡改检测管道中。 |
| How Much Does Audio Matter to Recognize Egocentric Object Interactions? Authors Alejandro Cartas, Jordi Luque, Petia Radeva, Carlos Segura, Mariella Dimiccoli 声音是我们与对象日常交互的重要信息来源。例如,通过使用听觉,大量的人可以辨别出正在倾倒的水的温度。然而,只有少数作品探索了使用音频进行物体相互作用的分类以及视觉或单一模态。在这项初步工作中,我们提出了一个用于自我中心行为识别的音频模型,并探讨其在问题名词,动词和动作分类中的有用性。我们的模型使用相对较轻的架构,在基于视觉的最先进系统的标准基准上的动词分类34.26准确度方面取得了竞争结果。 |
| Computing Valid p-values for Image Segmentation by Selective Inference Authors Kosuke Tanizaki, Noriaki Hashimoto, Yu Inatsu, Hidekata Hontani, Ichiro Takeuchi 图像分割是计算机视觉的最基本任务之一。在许多实际应用中,必须正确评估单个分割结果的可靠性。在这项研究中,我们提出了一个新的框架,以p值的形式提供分割结果的统计显着性。具体而言,我们考虑用于确定对象和背景区域之间的差异的统计假设检验。这个问题具有挑战性,因为由于分割算法对数据的适应性,差异可能看起来很大,称为分割偏差。为了克服这个困难,我们引入了一种称为选择性推理的统计方法,并开发了一个框架来计算有效的p值,其中正确地考虑了分割偏差。尽管所提出的框架可能适用于各种分割算法,但我们在本文中主要关注基于图切割和基于阈值的分割算法,并开发两种特定方法来计算由这些算法获得的分割结果的有效p值。我们证明了这两种方法的理论有效性,并通过将它们应用于医学图像的分割问题来证明它们的实用性。 |
| Deep Face Recognition Model Compression via Knowledge Transfer and Distillation Authors Jayashree Karlekar, Jiashi Feng, Zi Sian Wong, Sugiri Pranata 完全卷积网络FCN已经成为实现许多视觉和非视觉任务以及特别是面部识别的非常高水平性能的事实上的工具。这种高水平的准确度通常是通过非常深的网络或它们的集合来获得的。然而,将这种高性能模型部署到资源约束设备或实时应用程序是具有挑战性的。在本文中,我们提出了一种基于学生教师范式的人脸识别应用的新型模型压缩方法。所提出的方法包括以更高的图像分辨率训练教师FCN,而学生FCN的训练图像分辨率低于教师FCN。我们探索了三种不同的方法来训练学生FCN知识转移KT,知识蒸馏KD及其组合。对LFW和IJB C数据集的实验评估表明,这些方法的准确度得到了可比较的改善。培养来自高分辨率教师的低分辨率学生FCN提供了加速训练,加速推理,减少内存需求和提高准确性的四重优势。我们评估了IJB C数据集上的所有模型,并在此基准测试中获得了最新的结果。教师网络和一些学生网络甚至在IJB C数据集上取得了前1名的表现。所提出的方法简单且硬件友好,因此能够将高性能面部识别深度模型部署到资源约束设备。 |
| Perceptual Embedding Consistency for Seamless Reconstruction of Tilewise Style Transfer Authors Amal Lahiani, Nassir Navab, Shadi Albarqouni, Eldad Klaiman 风格转移是一个在深度学习中越来越受关注和使用案例的领域。最近的工作表明,生成性对抗网络GAN可用于在数字病理学中创建真实染色的幻灯片图像的真实图像,并具有临床验证的可解释性。数字病理图像通常具有极高的分辨率,使得深度学习应用所需的分析分析成为必要。已经表明,当从平铺分析重建大图像时,具有实例归一化的图像生成器可能导致拼接伪像。我们引入了一种新颖的感知嵌入一致性损失,显着减少了在重建的整个幻灯片图像WSI中产生的拼接伪像。我们通过比较虚拟染色的载玻片图像和连续的真实染色组织载玻片图像来验证我们我们还通过运行比较灵敏度分析测试证明我们的模型对对比度,颜色和亮度扰动更加稳健。 |
| RF-Net: An End-to-End Image Matching Network based on Receptive Field Authors Xuelun Shen, Cheng Wang, Xin Li, Zenglei Yu, Jonathan Li, Chenglu Wen, Ming Cheng, Zijian He 本文提出了一种基于感知域RF Net的端到端可训练匹配网络,用于计算图像之间的稀疏对应关系。建立端到端可训练匹配框架是可取的和具有挑战性的。最近的方法LF Net成功地将整个特征提取管道嵌入到可联合训练的管道中,并产生最先进的匹配结果。本文介绍了LF网络结构的两种修改。首先,我们建议构建接收特征映射,从而实现更有效的关键点检测。其次,我们引入一般损失函数项,邻居掩码,以方便训练补丁选择。这导致描述符训练中的稳定性提高。我们在开放数据集HPatches上训练了RF Net,并将其与多个基准数据集上的其他方法进行了比较。实验表明,RF Net优于现有技术方法。 |
| Panoptic Edge Detection Authors Yuan Hu, Yingtian Zou, Jiashi Feng 对现实视觉应用追求更完整和连贯的场景理解,推动从类别不可知到类别感知语义级别的边缘检测。但是,实例级边界的更精细描述仍然未被挖掘。在这项工作中,我们解决了一个新的细粒度任务,称为全景边缘检测PED,旨在预测事物类别和实例级别边界的语义级别边界,以便从实例的角度提供更全面和统一的场景理解。然后,我们提出了一个通用的框架,Panoptic Edge Network PEN,它将对象检测,语义和实例边缘检测的不同任务聚合到一个具有多个分支的单个整体网络中。基于相同的特征表示,语义边缘分支为所有类别产生语义级边界,并且对象检测分支生成实例提议。在来自这两个分支的先验信息的条件下,实例边缘分支旨在实例化实例类别的边缘预测。此外,我们还为新的PED任务设计了Panoptic Dual F度量F2度量,以统一测量东西和实例的边缘预测质量。通过联合端到端培训,拟议的PEN框架优于Cityscapes和ADE20K数据集的所有竞争基线。 |
| Learning to Self-Train for Semi-Supervised Few-Shot Classification Authors Qianru Sun, Xinzhe Li, Yaoyao Liu, Shibao Zheng, Tat Seng Chua, Bernt Schiele 由于标记的训练数据的稀缺性,很少有射门分类FSC具有挑战性。每个类只有一个标记数据点。通过学习初始化FSC的分类模型,元学习已经显示出有希望的结果。在本文中,我们提出了一种新的半监督元学习方法,称为学习自我训练LST,利用未标记的数据,特别是元学习如何挑选和标记这些无监督数据,以进一步提高性能。为此,我们通过大量半监督的少数射击任务训练LST模型。在每项任务中,我们训练一些镜头模型来预测未标记数据的伪标签,然后在标记和伪标记数据上迭代自我训练步骤,每一步然后进行微调。我们还学习了一个软加权网络SWN来优化伪标签的自我训练权重,以便更好的标签可以为梯度下降优化做出更多贡献。我们在两个ImageNet基准上评估我们的LST方法,用于半监督的几次射击分类,并且在现有技术水平上实现了很大的改进。 |
| Rethinking Loss Design for Large-scale 3D Shape Retrieval Authors Zhaoqun Li, Cheng Xu, Biao Leng 学习判别性形状表示是大规模3D形状检索的关键问题。在本文中,我们提出了协同内积损失CIP损失,以获得理想的形状嵌入,该嵌入在不同类别之间进行区分并聚集在同一类中。利用简单的内积运算,CIP损失明确地强制要将相同类的特征聚集在线性子空间中,而类间子空间被约束为至少正交。与先前的度量损失函数相比,CIP损失可以为嵌入提供比欧几里德边缘更清晰的几何解释,并且易于实现而没有关于余弦余量的归一化操作。此外,我们提出的损失项可以与其他常用的损耗函数结合使用,并且可以轻松插入现有的现成架构中。在两个公共3D对象检索数据集ModelNet和ShapeNetCore 55上进行的大量实验证明了我们的提议的有效性,并且我们的方法已经在两个数据集上实现了最先进的结果。 |
| Generating Question Relevant Captions to Aid Visual Question Answering Authors Jialin Wu, Zeyuan Hu, Raymond J. Mooney 回答VQA和图像字幕的视觉问题需要一个连接语言和愿景的共同知识体系。我们提出了一种改进VQA性能的新方法,通过联合生成旨在帮助回答特定视觉问题的字幕来利用此连接。通过使用基于在线梯度的方法自动确定问题相关字幕,使用现有字幕数据集来训练模型。 VQA v2挑战的实验结果表明我们的方法获得了最先进的VQA性能,例如通过同时生成问题相关标题,使用单个模型设置测试标准集68.4。 |
| Hierarchical Video Frame Sequence Representation with Deep Convolutional Graph Network Authors Feng Mao, Xiang Wu, Hui Xue, Rong Zhang 高精度视频标签预测分类模型归因于大规模数据。这些数据可以是由预先训练的卷积神经网络提取的帧特征序列,其提高了创建模型的效率。诸如特征平均池之类的无监督解决方案作为简单的标签无关参数自由方法,具有有限的表示视频的能力。而像RNN这样的监督方法可以大大提高识别准确率。然而,视频长度通常很长,并且视频中的事件之间的帧之间存在层次关系,基于RNN的模型的性能降低。在本文中,我们提出了一种基于深度卷积图神经网络DCGN的视频分类方法。所提出的方法利用视频的分层结构的特征,并通过图形网络对视频帧序列进行多级特征提取,获得分层次地反映事件语义的视频表示。我们在YouTube 8M大规模视频理解数据集上测试我们的模型,结果优于基于RNN的基准测试。 |
| Iterative Path Reconstruction for Large-Scale Inertial Navigation on Smartphones Authors Santiago Cort s Reina, Yuxin Hou, Juho Kannala, Arno Solin 现代智能手机具有准确,强大的导航和跟踪所需的所有传感功能。在特定环境中,某些数据流可能不存在,可靠性较差或出错。特别是,GNSS信号可能在建筑物内或高层建筑的街道中变得有缺陷或无声。在本应用论文中,我们的目标是使用惯性测量结合标准智能手机上的部分GNSS数据来推进运动估计的当前技术水平。我们展示了迭代估计方法如何帮助改进回溯用例中的定位路径估计,这些用例可以涵盖固定区间和固定滞后情景。我们将全局迭代卡尔曼滤波方法提供的估计结果与视觉惯性跟踪方案Apple ARKit的估计结果进行比较。从智能手机和平板设备获取的经验数据的实际使用案例中证明了实际适用性。 |
| Data Augmentation for Object Detection via Progressive and Selective Instance-Switching Authors Hao Wang, Qilong Wang, Fan Yang, Weiqi Zhang, Wangmeng Zuo 大量注释良好的样品的收集在提高物体检测性能方面是有效的,但是非常费力且昂贵。最近提出的Cut Paste方法12,15代替了数据收集和注释,显示了通过切割前景对象并将它们粘贴在适当的新背景上来增强训练数据集的潜力。但是,现有的Cut Paste方法无法保证合成图像始终精确地模拟视觉上下文,并且所有这些都需要外部数据集。为了解决上述问题,本文提出了一种简单而有效的实例切换IS策略,该策略通过从不同图像切换相同类的实例来生成新的训练数据。我们的IS自然保留了原始图像中的上下文连贯性,同时不需要外部数据集。为了指导我们的IS获得更好的对象性能,我们探索了数据集中实例不平衡和类重要性的问题,这些问题经常发生并对检测性能产生不利影响。为此,我们提出了一种新颖的渐进和选择性实例切换PSIS方法来增强用于对象检测的训练数据。所提出的PSIS通过将选择性重新采样与类平衡损失相结合来增强实例平衡,并通过逐步增加由检测性能引导的训练数据集来考虑类别重要性。实验是在具有挑战性的MS COCO基准上进行的,结果表明我们的PSIS对各种先进的探测器(例如,更快的R CNN,FPN,掩模R CNN和SNIPER)带来了明显的改进,显示了我们PSIS的优越性和通用性。代码和型号可在以下网站获得 |
| Adversarial Examples for Edge Detection: They Exist, and They Transfer Authors Christian Cosgrove, Alan L. Yuille 卷积神经网络最近在许多任务中提出了现有技术,包括边缘和物体边界检测。然而,在本文中,我们证明了这些边缘检测器继承了神经网络的一个令人不安的特性,它们可能被对抗性的例子所欺骗。我们表明,向图像添加小的扰动会导致HED(一种基于CNN的边缘检测模型)无法定位边缘,检测不存在的边缘,甚至会产生任意边缘配置的幻觉。更令人惊讶的是,我们发现这些对抗性示例转移到其他基于CNN的视觉模型。具体而言,对边缘检测的攻击导致训练的模型的准确度显着下降,以执行不相关的高级任务,例如图像分类和语义分割。我们的代码将公开。 |
| Incremental Few-Shot Learning for Pedestrian Attribute Recognition Authors Liuyu Xiang, Xiaoming Jin, Guiguang Ding, Jungong Han, Leida Li 由于行人属性识别在视频监控应用中的重要作用,因此受到越来越多的关注。但是,大多数现有方法都是针对一组固定的属性而设计的。他们无法处理递增的少数镜头学习场景,即将训练有素的模型适应具有稀缺数据的新添加的属性,这些属性通常存在于现实世界中。在这项工作中,我们提出了一种基于元学习的方法来解决这个问题。我们框架的核心是一个元架构,能够解开多个属性信息并快速推广到新的属性。通过在增量少量射击设置下对基准数据集PETA和RAP进行大量实验,我们表明我们的方法能够以竞争性能和低资源要求执行任务。 |
| Learning to Generate Grounded Image Captions without Localization Supervision Authors Chih Yao Ma, Yannis Kalantidis, Ghassan AlRegib, Peter Vajda, Marcus Rohrbach, Zsolt Kira 在为图像生成句子描述时,常常不清楚生成的标题在图像中的接地程度,或者模型是否基于数据集和/或语言模型中的先验幻觉。将图像区域与字幕模型中的单词相关联的最常见方式是通过区域上的注意机制,该区域用作预测下一个单词的输入。因此,模型必须学会预测注意力而不知道应该本地化的词。在这项工作中,我们提出了一种新颖的循环训练方案,迫使模型在句子解码器生成后定位图像中的每个单词,然后从局部图像区域s重建句子以匹配基础事实。初始解码器和所提出的重建器在训练期间共享参数并且与定位器联合学习,允许模型规范注意机制。我们提出的框架只需要学习一个额外的完全连接层定位器,一个可以在测试时移除的层。我们表明,我们的模型显着提高了接地精度,而不依赖于接地监督或在推理过程中引入额外的计算。 |
| Natural Image Noise Dataset Authors Benoit Brummer, Christophe De Vleeschouwer 卷积神经网络一直是旨在解决图像去噪问题的研究重点,但它们的性能对于大多数应用来说仍然不能令人满意。这些网络使用合成噪声分布进行训练,这些噪声分布不能准确反映图像传感器捕获的噪声。已经引入了一些干净噪声图像对的数据集,但它们通常用于基准测试或特定应用。我们介绍了自然图像噪声数据集NIND,这是一种数码单反相机的数据集,类似于具有不同ISO噪声水平的图像,其大小足以训练模型以在各种噪声范围内进行盲目去噪。我们演示了使用NIND训练的去噪模型,并表明它明显优于BM3D对ISO图像噪点的看法,即使在推广到不同类型相机的图像时也是如此。自然图像噪声数据集发布在维基共享资源上,因此它对于策展和贡献仍然是开放的。我们希望这个数据集对未来的图像去噪应用程序有用。 |
| Parametric Shape Modeling and Skeleton Extraction with Radial Basis Functions using Similarity Domains Network Authors Sedat Ozer 我们演示了相似域SD用于形状建模和骨架提取的用途。最近提出了SD,它们可以在神经网络框架中使用,以帮助我们分析形状。 SD使用径向基函数建模,在相似域网络SDN中具有不同的形状参数。在本文中,我们演示了如何使用SDN首先帮助我们根据SD模拟基于像素的图像,然后演示如何使用这些学习的SD来提取形状的骨架。 |
| Lung cancer screening with low-dose CT scans using a deep learning approach Authors Jason L. Causey, Yuanfang Guan, Wei Dong, Karl Walker, Jake A. Qualls, Fred Prior, Xiuzhen Huang 肺癌是导致癌症死亡的主要原因。通过低剂量计算机断层扫描CT筛查的早期检测已经显示出显着降低死亡率,但是具有高假阳性率导致不必要的诊断程序。与深度学习技术相结合的定量图像分析有可能降低这种误报率。我们对来自国家肺筛查试验NLST队列的1449个低剂量CT研究进行了计算分析。我们应用于这个队列我们新开发的算法DeepScreener,它基于一种新颖的深度学习方法。在使用约3000次CT研究的训练过程之后,该算法不需要肺结节注释来进行癌症预测。该算法使用连续切片和多任务特征来确定结节是否可能是癌症,并使用空间金字塔来检测不同尺度的结节。我们发现该算法可以从体积肺CT图像预测患者的癌症状态,具有高精度78.2,接收器工作特征曲线AUC下面积为0.858。根据挑战数据集,我们的初步框架在2017年数据科学碗DSB2017竞赛中排名第19位,排名第1。我们在此报告DeepScreener在独立NLST测试集上的应用。该研究表明,深度学习方法有可能显着降低低剂量CT扫描肺癌筛查中的假阳性率。 |
| RGB and LiDAR fusion based 3D Semantic Segmentation for Autonomous Driving Authors Khaled El Madawy, Hazem Rashed, Ahmad El Sallab, Omar Nasr, Hanan Kamel, Senthil Yogamani LiDAR已成为自动驾驶应用的标准传感器,因为它们提供高精度的3D点云。 LiDAR在夜间低光场景或由于相机性能下降的阴影时也很强大。对于包括物体检测和SLAM的算法,LiDAR感知逐渐成熟。然而,语义分割算法仍然相对较少探索。由于语义分割是一种成熟的图像数据算法,我们探索了基于传感器融合的三维分割。据我们所知,这是基于RGB和LiDAR的自动驾驶3D分割的首次尝试。我们的主要贡献是将RGB图像转换为用于LiDAR的极坐标网格映射表示,并设计早期和中级融合架构。此外,我们设计了一种融合了两种融合算法的混合融合架构。我们在KITTI数据集上评估我们的算法,该数据集为汽车,行人和骑自行车者提供分段注释。我们评估了两种最先进的架构,即SqueezeSeg和PointSeg,并且在两种情况下相对于仅基于LiDAR的基线,将mIoU得分提高了10。 |
| ZstGAN: An Adversarial Approach for Unsupervised Zero-Shot Image-to-Image Translation Authors Jianxin Lin, Yingce Xia, Sen Liu, Tao Qin, Zhibo Chen 图像到图像翻译模型已经显示出在不同域之间传输图像的显着能力。大多数现有工作遵循源域和目标域在训练和推理阶段保持相同的设置,这不能概括为将图像从不可见域转换到另一个看不见的域的场景。在这项工作中,我们提出了无监督零镜头图像来翻译UZSIT问题,其目的是学习一种能够将翻译知识从被看见的域转移到看不见的域的模型。因此,我们提出了一个名为ZstGAN的框架。通过引入对抗性训练方案,ZstGAN学习使用在视觉和属性模态上在语义上一致的领域特定特征分布对每个领域进行建模。然后,域不变特征与用于图像生成的共享编码器解开。我们对CUB和FLO数据集进行了大量实验,结果证明了该方法对UZSIT任务的有效性。此外,ZstGAN显示出相对于CUB和FLO的现有技术零射击学习方法的显着精确度改进。 |
| Learning to Transfer: Unsupervised Meta Domain Translation Authors Jianxin Lin, Yijun Wang, Yingce Xia, Tianyu He, Zhibo Chen 最近,无监督域翻译通过快速开发的生成对抗网络GAN和足够的训练数据的可用性获得了令人印象深刻的性能。然而,现有的域翻译框架以一次性方式形成,其中忽略了学习体验。在这项工作中,我们将这一研究方向转向无监督的元域翻译问题。我们提出了一种名为MT GAN的元翻译模型来查找条件GAN的参数初始化,该条件GAN可以快速适应具有有限训练样本的新域翻译任务。在元训练过程中,MT GAN明确地使用主要翻译任务和合成双翻译任务进行微调。然后我们设计一个元优化目标,要求微调MT GAN产生良好的泛化性能。我们证明了我们的模型在十个不同的两个域翻译任务和多个面部身份翻译任务中的有效性。我们表明,当在每个图像域中使用不超过10个训练样本时,我们提出的方法明显优于现有的域转换方法。 |
| Temporally Coherent Full 3D Mesh Human Pose Recovery from Monocular Video Authors Jian Liu, Naveed Akhtar, Ajmal Mian 最近深度学习的进步使得从个体图像中恢复人体姿势的完整3D网格成为可能。然而,将这一概念扩展到视频以恢复时间上连贯的姿势仍然未被探索。在这方面的一个主要挑战是缺乏用于学习所需深度模型的适当注释的视频数据。现有的人体姿势数据集仅提供2D或3D骨架关节注释,而数据集也记录在受约束的环境中。我们首先提供了一种技术来合成具有丰富3D注释的单眼动作视频,这些视频适用于学习全网格3D人体姿势恢复的计算模型。与简单地将衣服贴在3D人体姿势模型上的现有方法相比,我们的方法将基于物理的现实布料变形与人体运动相结合。生成的视频涵盖了各种各样的人类动作,姿势和视觉外观,而注释记录了准确的人体姿势动态和人体表面信息。我们的第二个主要贡献是端对端可训练的回归神经网络,用于从单眼视频中恢复全姿势网格。使用提出的视频数据和基于LSTM的循环结构,我们的网络明确地学习模拟视频中的时间相干性并对恢复的网格施加几何一致性。我们使用建议和基准数据集建立定量和定性分析的模型的有效性。 |
| Region-specific Diffeomorphic Metric Mapping Authors Zhengyang Shen, Fran ois Xavier Vialard, Marc Niethammer 我们引入了区域特定的微分形式度量映射RDMM注册方法。 RDMM是非参数的,估计空间时间速度场,其参数化所寻求的空间变换。这些速度场的正则化是必要的。然而,虽然现有的非参数配准方法,例如,大位移微分同态度量映射LDDMM模型,使用固定的空间不变正则化,但是我们的模型利用估计的速度场来平衡空间变化的正则化器,从而自然地将空间时间正则化器附加到变形对象。我们探索了一系列RDMM配准方法1注册模型,其中具有单独正则化的区域被预先定义,例如,在地图集空间中,2是注册模型,其中估计一般空间变化的正则化器,以及3注册模型,其中空间变化的正则化器通过端到端训练的深度学习DL模型获得。我们提供了RDMM的变分推导,表明该模型可以确保连续体中的微变形,并且LDDMM是RDMM的特定实例。为了评估RDMM性能,我们在合成2D数据上进行了实验1,在两个3D数据集上进行了2次关于骨关节炎倡议OAI的膝关节磁共振图像和肺部计算机断层扫描图像CT的实验1。结果表明,我们的框架实现了最先进的图像配准性能,同时通过学习的空间层次正则化器提供了额外的信息。此外,我们的深度学习方法允许非常快速的RDMM和LDDMM估计。我们的代码将是开源的。代码可在 |
| ArcticNet: A Deep Learning Solution to Classify Arctic Wetlands Authors Ziyu Jiang, Kate Von Ness, Julie Loisel, Zhangyang Wang 在气候变暖的情况下,北极环境正在迅速变化。特别感兴趣的是湿地,一种构成最有效的陆地长期碳储存的生态系统。随着永久冻土融化,锁定在这些湿地土壤中数千年的碳变得可用于需氧和厌氧分解,分别释放CO2和CH4回到 |
| Driver Behavior Analysis Using Lane Departure Detection Under Challenging Conditions Authors Luis Riera, Koray Ozcan, Jennifer Merickel, Mathew Rizzo, Soumik Sarkar, Anuj Sharma 在本文中,我们提出了一种新型模型,用于检测车道区域,并提取车道偏离事件的变化以及用移动摄像机记录的具有挑战性的低分辨率视频的入侵。我们的算法使用基于掩码RCNN的车道检测模型作为预处理器。最近,基于深度学习的模型提供了用于与分割相结合的对象检测的最新技术。在几种深度学习架构中,卷积神经网络CNN优于其他机器学习模型,特别是对于区域提议和对象检测任务。区域提议方法和基于区域的CNN R CNN的成功推动了对象检测的最新发展。我们的算法利用车道分割掩模进行检测,并使用Fix lag Kalman滤波器进行跟踪,而不是通常的方法来检测来自单个视频帧的车道线。该算法允许从连续车道检测中检测到左或右车道的驾驶员车道偏离。初步结果显示了对车道偏离事件的可靠检测的希望。我们的自定义测试数据集中车道偏离事件的总体灵敏度为81.81。 |
| OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge Authors Kenneth Marino, Mohammad Rastegari, Ali Farhadi, Roozbeh Mottaghi 视觉问题以理想形式回答VQA让我们在视觉和语言的联合空间中学习推理,并作为场景理解的AI任务的代理。但是,迄今为止大多数VQA基准测试都集中在简单计数,视觉属性和对象检测等问题上,这些问题不需要超出图像内容的推理或知识。在本文中,我们解决了基于知识的视觉问答的任务,并提供了一个名为OK VQA的基准,其中图像内容不足以回答问题,鼓励依赖外部知识资源的方法。我们的新数据集包含超过14,000个需要外部知识回答的问题。我们表明,在这种新设置中,最先进的VQA模型的性能会急剧下降。我们的分析表明,与以前基于知识的VQA数据集相比,我们基于知识的VQA任务是多样的,困难的和大的。我们希望这个数据集能够让研究人员为这一领域的研究开辟新的途径。看到 |
| DISCO: Depth Inference from Stereo using Context Authors Kunal Swami, Kaushik Raghavan, Nikhilanj Pelluri, Rituparna Sarkar, Pankaj Bajpai 最近基于深度学习的方法优于传统的立体匹配方法。然而,当前基于深度学习的端到端立体匹配方法采用具有跳过连接的通用编码器解码器类型网络。为了限制计算要求,许多网络执行过度的下采样,这导致有用的低级信息的显着损失。此外,许多网络设计不利用丰富的多尺度上下文信息。在这项工作中,我们通过仔细设计网络架构来解决上述问题,以便在整个网络中保留所需的空间信息,同时实现大型有效的感知领域以提取多尺度的上下文信息。我们首次创建了一个合成视差数据集,反映了使用智能手机拍摄的真实生活图像,这使我们能够在常见的真实生活图像上获得最先进的结果。所提出的模型DISCO在合成的场景流数据集上进行了预训练,并在流行的基准测试和我们的具有挑战性的现实生活图像的内部数据集上进行了评估。所提出的模型在质量和量化指标方面优于现有技术方法。 |
| Learning Perceptually-Aligned Representations via Adversarial Robustness Authors Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Brandon Tran, Aleksander Madry 机器学习的许多应用需要人类对齐的模型,即,基于关于输入的人类有意义的信息做出决定。我们将深度网络学习表示的普遍脆弱性视为实现这一目标的基本障碍。然后,我们将强大的优化作为一种工具,用于强化人类先验深入神经网络学习的特征。由此产生的强大特征表示与人类感知更加一致。我们利用这些表示来执行输入插值,特征操作和灵敏度映射,而无需在模型训练后进行任何后处理或人工干预。我们的代码和模型可用于复制这些结果 |
| Big-Data Clustering: K-Means or K-Indicators? Authors Feiyu Chen, Yuchen Yang, Liwei Xu, Taiping Zhang, Yin Zhang K均值算法可以说是最流行的数据聚类方法,通常应用于某些特征空间中的已处理数据集,就像在谱聚类中一样。然而,对于初始化非常敏感,K意味着在大数据应用中这个数字增长时遇到了关于簇K数量的可扩展性瓶颈。在这项工作中,我们推广了一个名为K指标模型的密切相关模型,并构建了一个无需随机初始化的高效半凸松弛算法。我们提出了广泛的实证结果,以显示当K很大时新算法的优点。特别是,使用新算法启动K均值算法,没有任何复制,可以显着地胜过标准K均值,具有大量当前最先进的随机复制。 |
| A new nonlocal forward model for diffuse optical tomography Authors Wenqi Lu, Jinming Duan, Joshua Deepak Veesa, Iain B. Styles 漫射光学层析成像DOT中的正演模型描述了光如何通过混浊介质传播。它通常由扩散方程DE近似,其通过经典有限元方法FEM进行数值离散化。我们提出了一个非局部扩散方程NDE作为DOT的新正演模型,其离散化是利用基于有效图的数值方法GNM进行的。为了定量评估新的正向模型,我们首先在均质板上进行实验,其中将NDE和DE的数值精度与现有的分析解进行比较。我们通过比较其图像重建性能逆问题与DE的问题进一步评估NDE。我们的实验表明,NDE在数量上与DE相当,并且由于有效的基于图形的表示可以在不同维度的几何形状中实现相同,因此可以快速达到64。 |
| From Words to Sentences: A Progressive Learning Approach for Zero-resource Machine Translation with Visual Pivots Authors Shizhe Chen, Qin Jin, Jianlong Fu 神经机器翻译模型缺乏大规模并行语料库。相比之下,通过将我们的语言引用到外部世界,我们人类甚至可以在没有平行文本的情况下学习多语言翻译。为了模仿这种人类学习行为,我们采用图像作为枢轴来实现零资源翻译学习。然而,一张图片讲述了千言万语,这使得多个语言句子由相同的图像转动,如同相互翻译一样嘈杂,从而阻碍了翻译模型的学习。在这项工作中,我们提出了一种渐进式学习方法,用于图像旋转零资源机器翻译。由于词语在图像基础上不那么多样化,我们首先用图像枢轴学习词级翻译,然后通过利用学习词翻译来抑制图像旋转多语言句子中的噪声来学习句子级翻译。两个广泛使用的图像枢轴平移数据集IAPR TC12和Multi30k的实验结果表明,所提出的方法明显优于其他最先进的方法。 |
| Self-supervised Body Image Acquisition Using a Deep Neural Network for Sensorimotor Prediction Authors Alban Laflaqui re, Verena V. Hafner 这项工作研究了一个天真的代理人如何能够以自我监督的方式获得自己的身体形象,这是基于其感觉运动经验的可预测性。我们的工作假设是,由于其时间稳定性,代理人的身体比环境产生更一致的感官体验,环境表现出更大的可变性。鉴于其运动经验,代理人因此可以可靠地预测其身体应具有的外观。这种内在的可预测性可用于自动将身体图像与其他环境隔离。我们提出了一个两分支反卷积神经网络来预测与输入运动状态相关的视觉感知状态,以及与该输入相关的预测误差。我们在使用模拟Pepper机器人收集的第一人称图像数据集上训练网络,并显示网络输出如何用于自动将其可见臂与其他环境隔离。最后,评估由网络产生的身体图像的质量。 |
| Deep Feature Learning from a Hospital-Scale Chest X-ray Dataset with Application to TB Detection on a Small-Scale Dataset Authors Ophir Gozes, Hayit Greenspan ImageNet预训练网络的使用在医学成像领域正变得普遍。它支持小型数据集的培训,通常可用于医学成像任务。最近出现的大型胸部X射线数据集开启了学习特定于X射线分析任务的特征的可能性。在这项工作中,我们证明了所学的特征可以更好地分析结核病检测问题的分类结果,并能够推广到一个看不见的数据集。为了完成特征学习的任务,我们在ChestXray14数据集的112K图像上训练DenseNet 121 CNN,其中包括14种常见胸部病变的标签。除病理学标签外,我们还纳入了数据集患者定位,性别和患者年龄中可用的元数据。我们称这个架构为MetaChexNet。作为特征学习的副产品,我们使用CNN来展示患者年龄性别估计任务的最新表现。最后,我们展示了使用ChestXray14学习的特征,可以在结核病的小规模数据集上实现更好的转移学习。 |
| Probabilistic Noise2Void: Unsupervised Content-Aware Denoising Authors Alexander Krull, Tomas Vicar, Florian Jug 今天,卷积神经网络CNN是图像去噪的主要方法。它们传统上受到成对图像的训练,这些图像通常很难在实际应用中获得。这激发了自我监督的训练方法,例如在单个噪声图像上操作的Noise2Void N2V。遗憾的是,自我监督的方法与在图像对上训练的模型不具竞争力。在这里,我们提出了概率Noise2Void PN2V,一种训练CNN预测每个像素强度分布的方法。将这些与噪声的适当描述相结合,我们获得了完整的概率模型,用于每个像素中的噪声观测和真实信号。我们在广泛的噪声方案下对公开可用的显微镜数据集评估PN2V,并在监督的现有技术方法方面获得有竞争力的结果。 |
| Discovering Neural Wirings Authors Mitchell Wortsman, Ali Farhadi, Mohammad Rastegari 神经网络的成功推动了从功能工程到架构工程的重点转移。然而,今天成功的网络是使用一组小的手动定义的构建块构建的。即使在神经架构搜索NAS的方法中,网络连接模式也受到很大限制。在这项工作中,我们提出了一种发现神经布线的方法。我们放松了层的典型概念,而是使通道能够形成彼此独立的连接。这允许更大的可能网络空间。我们的网络布线在培训期间没有固定,因为我们学习了网络参数,我们也学习了结构本身。我们的实验表明,我们学到的连通性优于手工设计和随机有线网络。通过了解MobileNetV1 9的连接性,我们在41M FLOP时将ImageNet精度提高了10。此外,我们表明我们的方法推广到循环和连续时间网络。 |
| 3D Magic Mirror: Automatic Video to 3D Caricature Translation Authors Yudong Guo, Luo Jiang, Lin Cai, Juyong Zhang 漫画是一个真实的人的抽象,扭曲或夸大某些特征,但仍然保持相似。虽然大多数现有作品都侧重于从2D漫画中重建3D漫画或将2D照片转换为2D漫画,但本文提出了一种实时自动算法,用于从2D照片或视频中创建具有漫画风格纹理贴图的表现性3D漫画。为了解决这一具有挑战性的病态重建问题和跨域翻译问题,我们首先重建每个帧的3D人脸形状,然后通过保持VAE CycleGAN的新颖身份和表达将3D人脸形状从正常风格转换为漫画风格。基于标签公式,漫画纹理图由CariGAN生成的一组多视图漫画图像构成。通过与基线实施比较,证明了我们方法的有效性和有效性。感知研究表明,我们的方法生成的3D漫画符合人们对3D漫画风格的期望。 |
| Truncated Cauchy Non-negative Matrix Factorization Authors Naiyang Guan, Tongliang Liu, Yangmuzi Zhang, Dacheng Tao, Larry S. Davis 非负矩阵分解NMF最小化数据矩阵与其低秩近似之间的欧几里德距离,并且当应用于损坏的数据时它失败,因为损失函数对异常值敏感。在本文中,我们提出了截断CauchyNMF丢失,通过截断大误差处理异常值,并开发截断CauchyNMF以鲁棒地学习被异常值污染的噪声数据集上的子空间。我们理论上分析了截断CauchyNMF与竞争模型相比的鲁棒性,并从理论上证明了截断CauchyNMF具有一个泛化界,它以O sqrt ln n n的速率收敛,其中n是样本大小。我们通过模拟和真实数据集上的图像聚类来评估截断的CauchyNMF。包含严重破坏的数据集的实验结果验证了截断CauchyNMF用于学习鲁棒子空间的有效性和鲁棒性。 |
| On The Radon--Nikodym Spectral Approach With Optimal Clustering Authors Vladislav Gennadievich Malyshkin 考虑插值,分类和聚类的问题。在Radon Nikodym方法的原则中,langle f mathbf x psi 2 rangle langle psi 2 rangle,其中psi mathbf x是输入属性的线性函数,所有答案都是从广义的特征问题f psi获得的。我是rangle lambda i psi i rangle 。插值问题的解决方案是常规的Radon Nikodym导数。分类问题的解决方案需要使用Lebesgue积分1技术获得的先验概率和后验概率。而在贝叶斯方法中,新的观测结果仅改变了Radon Nikodym方法中的结果概率,不仅仅是结果概率,而且还改变了随着新观察而变化的概率空间。这是该方法的一个显着特征,概率和概率空间都是从数据构建的。勒贝格正交技术也可以应用于最优聚类问题。通过在Lebesgue测度上构造高斯求积来解决该问题。 Radon Nikodym方法的一个显着特征是对不变群的知识,所有答案相对于输入向量mathbf x分量的任何非简并线性变换都是不变的。作者可以获得实现插值,分类和最优聚类算法的软件产品。 |
| Generating Diverse High-Fidelity Images with VQ-VAE-2 Authors Ali Razavi, Aaron van den Oord, Oriol Vinyals 我们探索使用矢量量化变分自动编码器VQ VAE模型进行大规模图像生成。为此,我们扩展和增强VQ VAE中使用的自回归先验,以生成比以前更高的相干性和保真度的合成样本。我们使用简单的前馈编码器和解码器网络,使我们的模型成为编码和/或解码速度至关重要的应用的有吸引力的候选者。此外,VQ VAE要求仅在压缩潜在空间中对自回归模型进行采样,这比在像素空间中采样快一个数量级,特别是对于大图像。我们证明了VQ VAE的多尺度分层组织,与潜在代码相比具有强大的先验,能够生成质量与ImageNet等多方面数据集上最先进的生成对抗网络相媲美的样本,同时不会受到影响。 GAN已知的缺点,如模式崩溃和缺乏多样性。 |
| Unsupervised Bilingual Lexicon Induction from Mono-lingual Multimodal Data Authors Shizhe Chen, Qin Jin, Alexander Hauptmann 双语词典归纳,从源语言到目标语言的翻译,是一项长期的自然语言处理任务。最近的努力证明,有希望采用图像作为枢轴来学习词汇归纳而不依赖于平行语料库。然而,这些基于视觉的方法简单地将单词与整个图像相关联,这些图像被约束为翻译具体单词并且需要对象居中的图像。当人们在具有语境的句子中时,人们可以更好地理解单词。因此,在本文中,我们建议利用图像及其相关标题来解决以前方法的局限性。我们提出了一种用不同的单语多模态数据训练的多语言字幕模型,以将不同语言的单词映射到关节空间。从多语言字幕模型语言特征和局部视觉特征引出两种类型的单词表示。语义特征是从具有视觉语义约束的句子语境中学习的,这有利于学习视觉相关性较低的词语的翻译。局部视觉特征处于图像中与该单词相关的区域,从而减轻了对显着视觉表示的图像限制。这两种类型的特征是单词翻译的补充。多语言对的实验结果证明了我们提出的方法的有效性,其基本上优于先前基于视觉的方法而不使用任何平行句子或种子词对的监督。 |
| Enhancing Transformation-based Defenses using a Distribution Classifier Authors Connie Kou, Hwee Kuan Lee, Teck Khim Ng, Ee Chien Chang 对卷积神经网络的对抗性攻击CNN获得了极大的关注,研究工作集中在使分类器更加健壮的防御方法上。已经提出了随机输入变换方法,其中的想法是随机变换输入图像以试图从对抗性攻击中恢复。虽然这些基于变换的方法在从对抗图像中恢复时已经显示出相当大的成功,但是随着变换幅度的增加,干净图像上的性能恶化。在本文中,我们提出了一种防御机制,可以与现有的基于转换的防御相结合,并减少干净图像上的性能恶化。利用变换方法是随机的这一事实,我们的方法对一组变换图像进行采样,并对softmax概率的分布进行最终分类。我们训练一个单独的紧凑分布分类器,以识别转换后的清晰图像的softmax概率分布中的独特特征。在没有重新训练原始CNN的情况下,我们的分布分类器改进了基于变换的清晰和对抗图像防御的性能,即使分布分类器从未训练过从对抗图像获得的分布。我们的方法是通用的,可以与现有的基于转换的方法集成。 |
| Super-resolution of Time-series Labels for Bootstrapped Event Detection Authors Ivan Kiskin, Udeepa Meepegama, Steven Roberts 解决现实问题,特别是深度学习,依赖于丰富,高质量的数据。在本文中,我们开发了一种新的框架,可以最大化时间序列数据集的效用,该数据集仅包含少量专业标记数据,大量弱标记或粗标记数据以及大量未标记数据。这代表了现实世界中常见的场景,例如众包应用。在我们的工作中,我们使用嵌套循环使用核密度估计器KDE来超级分辨丰富的低质量数据标签,从而实现卷积神经网络CNN的有效训练。我们展示了两个关键结果:KDE能够更准确地超级分辨标签,并且具有更好的校准概率,比作为基线的完善的分类器b我们的CNN,在KDE的超级分辨标签上训练,实现了F1得分的提高22.1在我们的候选问题域中的下一个最佳基线系统。 |
| A Semantic-based Medical Image Fusion Approach Authors Fanda Fan, Yunyou Huang, Lei Wang, Xingwang Xiong, Zihan Jiang, Zhifei Zhang, Jianfeng Zhan 临床医生有必要全面分析来自不同来源的患者信息。医学图像融合是一种从不同形态的医学图像提供整体信息的有前景的方法。然而,现有的医学图像融合方法忽略了图像的语义,使得融合图像难以理解。在本文中,我们提出了一种基于语义的医学图像融合方法,并作为一种实现,我们提出了一种用于多模态医学图像融合的Fusion W Net FW网络。实验结果很有希望通过我们的方法生成的融合图像大大减少了语义信息损失,并且与现有技术方法相比具有可比较的视觉效果。我们的方法和工具在临床环境中具有很大的应用潜力。 FW Net的源代码可在以下网站获得 |
| Robust Learning Under Label Noise With Iterative Noise-Filtering Authors Duc Tam Nguyen, Thi Phuong Nhung Ngo, Zhongyu Lou, Michael Klar, Laura Beggel, Thomas Brox 我们考虑在标签噪声存在的情况下训练模型的问题。当前的方法识别具有可能不正确标签的样本,并通过为它们分配较低权重或从训练集中完全移除它们来减少它们对学习过程的影响。然而,在第一种情况下,模型仍然从后一种方法中的嘈杂标签中学习,可以丢失良好的训练数据。在本文中,我们提出了一种用于鲁棒学习的迭代半监督机制,其排除了噪声标签,但仍然能够从相应的样本中学习。为此,我们添加了一个无监督的损耗项,它也可以作为对剩余标签噪声的正则化器。我们评估了我们对具有不同噪声比的常见分类任务的方法。我们强大的模型大大超越了最先进的方法。特别是对于非常大的噪声比,与之前的最佳模型相比,我们实现了高达20的绝对改进。 |
| Perceptual Evaluation of Adversarial Attacks for CNN-based Image Classification Authors Sid Ahmed Fezza, Yassine Bakhti, Wassim Hamidouche, Olivier D forges 深度神经网络DNN最近实现了最先进的性能,并在许多机器学习任务中提供了重大进展,例如图像分类,语音处理,自然语言处理等。然而,最近的研究表明DNN容易受到对抗性攻击。例如,在图像分类域中,向输入图像添加小的不易察觉的扰动足以欺骗DNN并导致错误分类。被称为textit对抗性示例的扰动图像应在视觉上尽可能接近原始图像。然而,文献中提出的用于生成对抗性示例的所有工作都使用L p范数L 0,L 2和L infty作为距离度量来量化原始图像和对抗性示例之间的相似性。尽管如此,L p规范与人类判断无关,使得它们不适合可靠地评估对抗性实例的感知相似性保真度。在本文中,我们提出了一个用于对抗性实例的视觉保真度评估的数据库。我们描述了数据库的创建,并评估了可替代L p规范的十五种最先进的完整参考FR图像保真度评估指标的性能。数据库和主观评分可公开获取,以帮助设计对抗性示例的新指标并促进未来的研究工作。 |
| Out of Sight But Not Out of Mind: An Answer Set Programming Based Online Abduction Framework for Visual Sensemaking in Autonomous Driving Authors Jakob Suchan, Mehul Bhatt, Srikrishna Varadarajan 我们展示了在自动驾驶背景下系统集成的视觉和语义解决方案在视觉意义制定方面的需求和潜力。使用答案集编程的在线视觉意义的一般方法被系统地形式化并且完全实现。该方法在基于深度学习的视觉计算中集成了现有技术,并且被开发为可在混合架构内用于感知控制的模块化框架。我们使用社区建立的基准KITTIMOD和MOT进行评估和演示。作为用例,我们关注人类中心视觉意义的重要性,例如,语义表达和可解释性,问题回答,安全关键自动驾驶情境中的常识插值。 |
| Visual Understanding and Narration: A Deeper Understanding and Explanation of Visual Scenes Authors Stephanie M. Lukin, Claire Bonial, Clare R. Voss 我们描述了视觉理解和叙述的任务,其中机器人或代理为导航其环境时收集的图像生成文本,通过回答开放式问题,例如发生的事情,或者可能发生的事情,这里 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com