关于C函数参数地址和程序运行时内存空间的分配
最近利用闲暇时间,回顾了一下在程序运行时的内存的分配情况。在网上查了些资料,对于通常的32位程序来说,系统会针对程序不同的段(如代码段、常量数据段、未初始化的数据段等)分别分配一定空间,分配方式大致如下图:
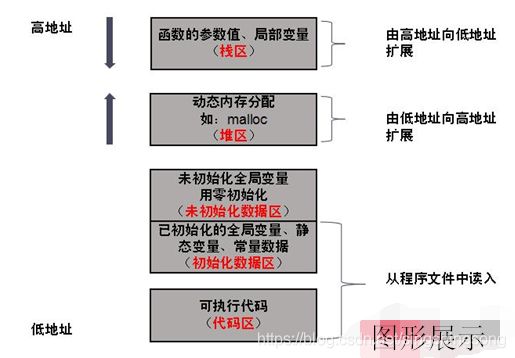
程序运行时内存空间的分配(图片摘自网络)
注意,在栈区一般会存储函数的参数值、局部变量等内容。在函数调用时,堆栈内数据的排列如下图所示:

函数调用时堆栈内数据存放位置(图片摘自网络)
为了验证函数调用时堆栈内数据存储的实际情况,调试了如下代码:
#include
#include
int localFun(char,char,char,char,char);//如果函数所有参数为int型,则从运行结果可以看出参数入栈顺序为从右至左,地址间隔为4
int main(int argc,char* argv[])
{
char c1,c2;
localFun(c1,c2,'A','$','-');
printf("Main End!\r\n");
return 0;
}
int localFun(char var1, char var2, char varA, char varB, char varC)
{
char var3='s';
char strVar[3];
printf("var1=%c;var2=%c,var3=%c,strVar=%s\r\n",var1,var2,var3,strVar);
printf("pvar1=%p;pvar2=%p,pvar3=%p,strVar=%p\r\n",&var1,&var2,&var3,strVar);
printf("\r\n");
return 0;
}
经过此实验,用GCC(G++)编译后,localFun函数输出的结果总是显示其参数的地址由var1至varC递减,明显不符合从右至左入栈的顺序。怀疑Linux下GCC(G++)编译器默认采用从左至右的入栈方式处理函数参数,即调用约定,但是查阅了一些资料后,该推测并不成立。各类资料都表示Linux下GCC(G++)也默认采用stdcall调用约定,参数入栈顺序为从右至左!
这与理论相悖的运行结果困扰了我很久,如果将localFun函数的所有参数都改成int型,则不存在这个问题,参数地址从varC至var1递减,且地址间隔均为4,符合逻辑。但是对于char型参数,参数地址从大到小排序则会颠倒过来,对此一直找不到原因。查了很久,才找到以前有人就这个现象的一个解释:
摘自:https://bbs.csdn.net/topics/260029356
函数参数入栈顺序以及参数地址间隔的问题
1。linux下写了这么一个函数
void test(short a ,char* b,int c){
printf("%p\n",&a);
printf("%p\n",&b);
printf("%p\n",&c);
}
main(){
short a = 1;
char b = '2';
int c = 3;
test(a,&b,c);
}
输出结果0xbfe77426
0xbfe77434
0xbfe77438
按着参数从右向左入栈的顺序,c的地址比b大4,正常。b的地址比a大14这是为什么啊?如果是字节补齐的话,也不该差这么多。
中间的那12个字节存放的是什么?
2。后来我将b改成char类型 test(short a,char b,int c)
输出结果0xbfe5ed56
0xbfe5ed55
0xbfe5ed68
不仅地址差很多,而且从地址上看的话,好像是a比b先进栈啊?更加迷惑。。
3。如果函数的参数都是int和地址类型的话,地址相差都是4,也符合从右向左入栈的顺序。这个倒是很正常。。
求大牛们指点。。
网友的回复:
1. 1楼的程序打印的结果不是参数进栈的地址,所以谈不上“参数入栈从右向左”的对错
2. "参数入栈从右向左"对于C是对的
3. 1楼的程序被GCC变成了类似:C/C++ code?
1
2
3
4
5
6
voidtest(shorta ,char* b,intc){
intlocal_a = a;
printf("%p\n",&local_a);
printf("%p\n",&b);
printf("%p\n",&c);
}
所以第一个地址和第二第三不连续。local_a = a的转换是因为GCC内部统一使用32位类型比较方便。
存放位置是在局部变量帧不固定的位置,当然也有一定的规律。
1. 地址一定比真正的参数地址低,也就是为什么1楼程序打印的第一行远小于2、3行
2. 地址和真正的参数地址之间隔了函数返回值和上一帧帧地址,4+4=8,而你真正的参数a在0xbfe77430,再加local_a本身,正好14:栈结构分析如下(各版本之间可能有小差异):
0xbfe77426: local_a
0xbfe77428: 上一帧帧地址
0xbfe7742c: 函数返回地址
0xbfe77430: a
0xbfe77434: b
0xbfe77438: c......
上一帧地址通常有两个作用,一是函数返回后能恢复到上一帧,局部变量和参数等都是通过当前帧便宜量找到的,不同函数实体有不同的帧地址。保存上一帧地址就像建立了一个链表一样。
二是调试的时候可以访问母函数信息,你在断点调试的时候可以看到被断函数的前辈函数的变量值,这也需要上一帧地址帮忙。......
根本原因在于C语言允许不知道函数原型的情况下调用函数,所以,为了避免出现参数类型不一致引起的问题,在函数调用时,要进行type promotion,如short、int提升为int,float提升为double等。
这样,在进入函数时,要将promote后参数根据其类型进行处理。如果参数类型就是int、void*等不需要promote的类型,则其在栈里的位置不变。如果是short、char等类型,则为其在栈里重新分配一个合适的空间(就是你的问题2中的现象)。至于此时的顺序,跟压栈的顺序完全没有关系。
大概如此。......
这是目前找到的最靠谱的解释,不过没有实际验证过。
另外,据说GCC会在函数调用时将一些压入堆栈,这样函数第一个局部变量地址与第一个参数地址之间的地址空间不会仅仅包含函数返回地址和原来ebp的地址:
摘自:https://segmentfault.com/q/1010000009037489/a-1020000009046015
函数调用时入栈参数与局部变量在栈中地址问题
#includeint foo(int a, int b, int c, int d) { int e; int f; std::cout << std::hex; std::cout << "Address of a: " << &a << std::endl; std::cout << "Address of b: " << &b << std::endl; std::cout << "Address of c: " << &c << std::endl; std::cout << "Address of d: " << &d << std::endl; std::cout << "Address of e: " << &e << std::endl; std::cout << "Address of f: " << &f << std::endl; return a + b + c + d; } int main() { foo(4, 2, 3, 4); return 0; } 输出:
gcc 4.9.2 -32bit release:
Address of a: 0x6efea0
Address of b: 0x6efea4
Address of c: 0x6efea8
Address of d: 0x6efeac
Address of e: 0x6efe8c
而就我目前的知识了解,栈是从高地址到底地址存储数据,而读取参数的顺序为从右到左,以第一次函数调用为例,入栈顺序应该是:d-c-b-a之后是按顺序将局部变量入栈,即e-f,但是比较e和a的地址可以发现二者在32位下相差14个字节,在64位下相差36个字节,感到比较奇怪,按之前看到的文章:http://blog.csdn.net/tdgx2004...,在局部变量与参数之间应该是函数地址与保护栈底(32位下8个字节),但是实际情况是14个字节,非常好奇还有6个字节装的是什么?
网友回答:
这个问题跟平台和采用的调用惯例以及编译器都有关系。
i386平台,默认的_cdecl调用惯例条件下,在运行时栈上,函数参数和函数局部变量中间还有1: 返回地址(pc after call instruction), 2: caller的栈帧基址(ebp), 3: callee save registers(不同平台个数不同),4:为了处理异常而在栈上增加的信息(不同编译器可能实现不同,gcc就会增加东西)
在函数调用时,被压入堆栈的内容包含函数返回地址和当前基址寄存器(ebp)的值,这是公认的。不过网友回答内容中的3和4点没找到其它相关依据,也有待验证。
如果GCC编译器确实向堆栈中添加了这些额外的、不确定的内容,那么,对于溢出漏洞的学习和调试十分不利,当然也就难以实施对既定函数的溢出攻击了,很难写出确定的shellcode。
——以上纯属个人学习经历,欢迎大神吐槽指正!