员工一言不合就离职怎么办?用 Python 写了个员工流失预测模型


作者 | 真达、Mika
来源 | CDA数据分析师(ID:cdacdacda)
【导读】
今天教大家如何用 Python 写一个员工流失预测模型。
Show me data,用数据说话。
今天我们聊一聊 员工离职。
点击下方视频,先睹为快:
说道离职的原因,可谓多种多样。人们归总了两点:
1. 钱没给到位
2. 心受委屈了
有人离职是因为“世界那么大,我想去看看”,也有人觉得“怀有绝技在身,不怕天下无路”。
另一方面,员工离职对于企业而言有什么影响呢?
要知道,企业培养人才需要大量的成本,为了防止人才再次流失,员工流失分析就显得十分重要了。这不仅仅是公司评估员工流动率的过程,通过找到导致员工流失的主要因素,预测未来的员工离职状况,从而进一步减少员工流失。
那么,哪些因素最容易导致员工离职呢?
这次我们用数据说话,教你如何用 Python 写一个员工流失预测模型。

数据理解
我们分析了 kaggle 平台分享的员工离职相关的数据集,共有 10 个字段 14999 条记录。数据主要包括影响员工离职的各种因素(员工满意度、绩效考核、参与项目数、平均每月工作时长、工作年限、是否发生过工作差错、5年内是否升职、部门、薪资)以及员工是否已经离职的对应记录。字段说明如下:


读入数据
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pyecharts.charts import Bar, Pie, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 读入数据
df = pd.read_csv('HR_comma_sep.csv')
df.head()

df.info()
RangeIndex: 14999 entries, 0 to 14998
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 satisfaction_level 14999 non-null float64
1 last_evaluation 14999 non-null float64
2 number_project 14999 non-null int64
3 average_montly_hours 14999 non-null int64
4 time_spend_company 14999 non-null int64
5 Work_accident 14999 non-null int64
6 left 14999 non-null int64
7 promotion_last_5years 14999 non-null int64
8 sales 14999 non-null object
9 salary 14999 non-null object
dtypes: float64(2), int64(6), object(2)
memory usage: 1.1+ MB
# 查看缺失值
print(df.isnull().any().sum())
可以发现,数据质量良好,没有缺失数据。

探索性分析
1、 描述性统计
df.describe().T
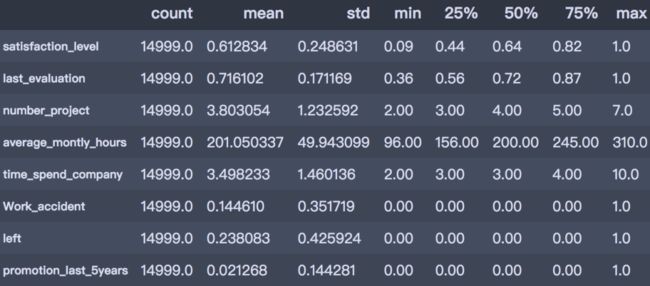
从上述描述性分析结果可以看出:
员工满意度:范围 0.09~1, 中位数 0.640, 均值 0.613, 总体来说员工对公司比较满意;
绩效考核:范围 0.36~1, 中位数 0.72, 均值 0.716, 员工平均考核水平在中等偏上;
参与项目数:范围 2~7, 中位数 4, 均值 3.8, 平均参加项目数约 4 个;
平均每月工作时长:范围 96~310 小时, 中位数 200, 均值 201。
工作年限:范围 2~10 年, 中位数 3, 均值 3.5。
2、离职人数占比
整理数据后发现,总共有 14999 人,其中红色部分代表离职人群,用数字 1 表示,蓝色为未离职人群,用数字 0 表示。离职人数为 3571,占总人数的 23.8%。

3、员工满意度
从直方图可以看出,离职员工的满意度评分明显偏低,平均值为 0.44。满意度低于 0.126 分的离职率为 97.2%。可见提升员工满意度可以有效防止人员流失。

df.groupby('left')['satisfaction_level'].describe()

def draw_numeric_graph(x_series, y_series, title):
# 产生数据
sat_cut = pd.cut(x_series, bins=25)
cross_table = round(pd.crosstab(sat_cut, y_series, normalize='index'),4)*100
x_data = cross_table.index.astype('str').tolist()
y_data1 = cross_table[cross_table.columns[1]].values.tolist()
y_data2 = cross_table[cross_table.columns[0]].values.tolist()
# 条形图
bar = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar.add_xaxis(x_data)
bar.add_yaxis(str(cross_table.columns[1]), y_data1, stack='stack1', category_gap='0%')
bar.add_yaxis(str(cross_table.columns[0]), y_data2, stack='stack1', category_gap='0%')
bar.set_global_opts(title_opts=opts.TitleOpts(title),
xaxis_opts=opts.AxisOpts(name=x_series.name, name_location='middle', name_gap=30),
yaxis_opts=opts.AxisOpts(name='百分比', name_location='middle', name_gap=30, min_=0, max_=100),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_right='2%'))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=opts.ItemStyleOpts(border_color='black', border_width=0.3))
bar.set_colors(['#BF4C51', '#8CB9D0'])
return bar
bar1 = draw_numeric_graph(df['satisfaction_level'], df['left'], title='满意度评分与是否离职')
bar1.render()
4、绩效考核
平均来看,绩效考核成绩在离职/未离职员工之间差异不大。在离职员工中,绩效考核低、能力不够和绩效考核较高但工作压力大、满意度低、对薪资不满意可能成为离职的原因。
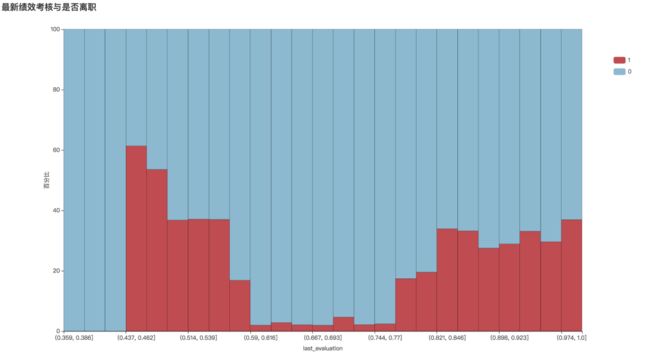
5、平均每月工作时长
从直方图可以看出,月工作时长正常的员工离职率最低。而工时过低、过高的员工离职人数最多。证明恰当的工作任务分配是非常重要的。

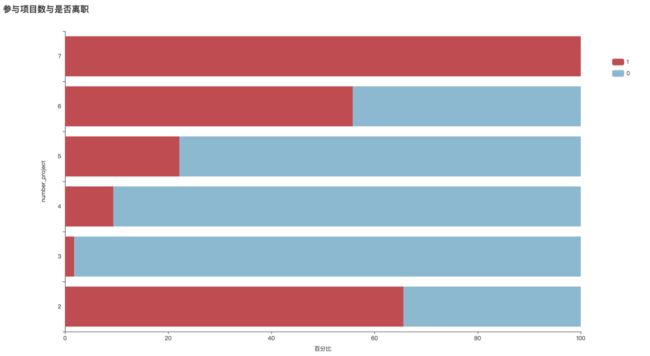
6、参加项目数
从图中可以看出:除项目数为2以外,随着项目数的增多,离职率在增大,且项目数是7的时候,离职率达到了100%以上。综上两点,项目数2的离职率高,可能是这部分人工作能力不被认可。项目数6、7的总体少,离职率高,体现了他们的工作能力强,但同时工作压力太大导致他们离职。
7、员工工龄
可以看到7年及以上工龄的员工基本没有离职,只有工龄为5年的员工离职人数超过在职人数。可见工龄长于6年的员工,由于种种原因,其“忠诚度”较高。
而员工进入公司工作的第5年是一个较为“危险”的年份,也许是该企业的“5年之痒”,应当重点关注该阶段的员工满意度、职业晋升等情况,以顺利过渡。

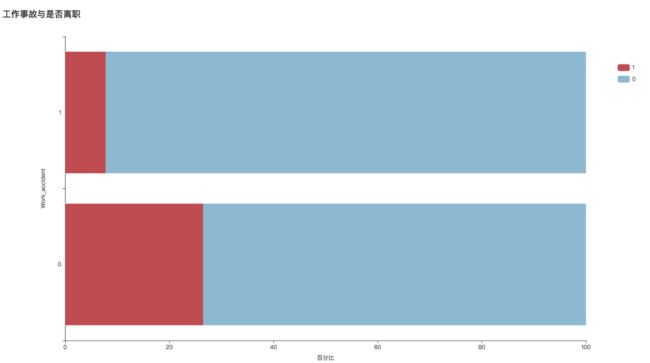
8、工作事故
从图中可看出,是否发生工作事故对员工离职的影响较小,可推测该企业处理工作事故的方式有可取之处。
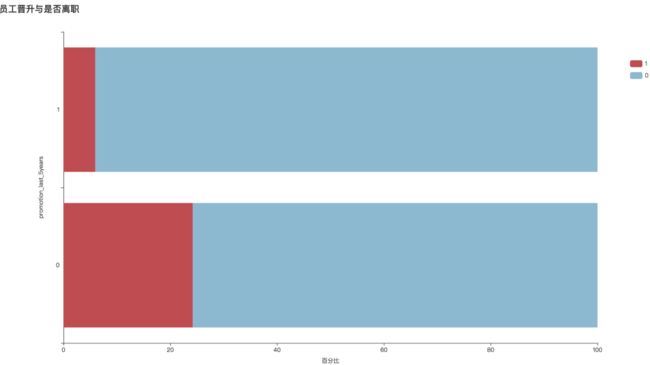
9、职位晋升
从条形图可以看出,在过去5年内获得未晋升的员工离职率为24.2%,比获得晋升的员工高4倍。设定良好的晋升通道可以很好的防止员工流失。
10、薪资水平
可明显看出,薪资越高离职人数越少。证明为了减少离职率,提升员工福利待遇是一个可行的手段。

11、不同部门
可见各部门离职率如上图,离职率由高到低,前三位分别是:人力部、财务部、科技部。之后依次是:支持部、销售部、市场部、IT 部门、产品部、研发部、管理部。对于离职率过高的部门,应进一步分析关键原因。


数据预处理
由于 sklearn 在建模时不接受类别型变量,我们主要对数据做以下处理,以方便后续建模分析:
薪资水平 salary 为定序变量, 因此将其字符型转化为数值型。
岗位是定类型变量, 对其进行 one-hot 编码。
# 数据转换
df['salary'] = df['salary'].map({"low": 0, "medium": 1, "high": 2})
# 哑变量
df_dummies = pd.get_dummies(df,prefix='sales')
df_dummies.head()


建模分析
我们使用决策树和随机森林进行模型建置,首先导入所需包:
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, f1_score, roc_curve, plot_roc_curve
然后划分训练集和测试集,采用分层抽样方法划分 80% 数据为训练集,20% 数据为测试集。
x = df_dummies.drop('left', axis=1)
y = df_dummies['left']
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y, random_state=2020)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
1、决策树
我们使用决策树进行建模,设置特征选择标准为gini,树的深度为5。输出分类的评估报告:
# 训练模型
clf = DecisionTreeClassifier(criterion='gini', max_depth=5, random_state=25)
clf.fit(X_train, y_train)
train_pred = clf.predict(X_train)
test_pred = clf.predict(X_test)
print('训练集:', classification_report(y_train, train_pred))
print('-' * 60)
print('测试集:', classification_report(y_test, test_pred))
训练集: precision recall f1-score support
0 0.98 0.99 0.98 9142
1 0.97 0.93 0.95 2857
accuracy 0.98 11999
macro avg 0.97 0.96 0.97 11999
weighted avg 0.98 0.98 0.97 11999
------------------------------------------------------------
测试集: precision recall f1-score support
0 0.98 0.99 0.98 2286
1 0.97 0.93 0.95 714
accuracy 0.98 3000
macro avg 0.97 0.96 0.97 3000
weighted avg 0.98 0.98 0.98 3000
假设我们关注的是1类(即离职类)的 F1-score,可以看到训练集的分数为 0.95,测试集分数为 0.95。
# 重要性
imp = pd.DataFrame([*zip(X_train.columns,clf.feature_importances_)], columns=['vars', 'importance'])
imp.sort_values('importance', ascending=False)
imp = imp[imp.importance!=0]
imp

在属性的重要性排序中,员工满意度最高,其次是最新的绩效考核、参与项目数、每月工作时长。
然后使用网格搜索进行参数调优。
parameters = {'splitter':('best','random'),
'criterion':("gini","entropy"),
"max_depth":[*range(1, 20)],
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(X_train, y_train)
print(GS.best_params_)
print(GS.best_score_)
{'criterion': 'gini', 'max_depth': 15, 'splitter': 'best'}
0.9800813177648042
使用最优的模型重新评估训练集和测试集效果:
# 训练模型
clf = DecisionTreeClassifier(criterion='gini', max_depth=5, random_state=25)
clf.fit(X_train, y_train)
train_pred = clf.predict(X_train)
test_pred = clf.predict(X_test)
print('训练集:', classification_report(y_train, train_pred))
print('-' * 60)
print('测试集:', classification_report(y_test, test_pred))
训练集: precision recall f1-score support
0 0.98 0.99 0.98 9142
1 0.97 0.93 0.95 2857
accuracy 0.98 11999
macro avg 0.97 0.96 0.97 11999
weighted avg 0.98 0.98 0.97 11999
------------------------------------------------------------
测试集: precision recall f1-score support
0 0.98 0.99 0.98 2286
1 0.97 0.93 0.95 714
accuracy 0.98 3000
macro avg 0.97 0.96 0.97 3000
weighted avg 0.98 0.98 0.98 3000
可见在最优模型下模型效果有较大提升,1类的 F1-score 训练集的分数为 0.99,测试集分数为 0.96。
2、随机森林
下面使用集成算法随机森林进行模型建置,并调整 max_depth 参数。
rf_model = RandomForestClassifier(n_estimators=1000, oob_score=True, n_jobs=-1,
random_state=0)
parameters = {'max_depth': np.arange(3, 17, 1) }
GS = GridSearchCV(rf_model, param_grid=parameters, cv=10)
GS.fit(X_train, y_train)
print(GS.best_params_)
print(GS.best_score_)
{'max_depth': 16}
0.988582151793161
train_pred = GS.best_estimator_.predict(X_train)
test_pred = GS.best_estimator_.predict(X_test)
print('训练集:', classification_report(y_train, train_pred))
print('-' * 60)
print('测试集:', classification_report(y_test, test_pred))
训练集: precision recall f1-score support
0 1.00 1.00 1.00 9142
1 1.00 0.99 0.99 2857
accuracy 1.00 11999
macro avg 1.00 0.99 1.00 11999
weighted avg 1.00 1.00 1.00 11999
------------------------------------------------------------
测试集: precision recall f1-score support
0 0.99 0.98 0.99 2286
1 0.95 0.97 0.96 714
accuracy 0.98 3000
macro avg 0.97 0.98 0.97 3000
weighted avg 0.98 0.98 0.98 3000
可以看到在调优之后的随机森林模型中,1类的 F1-score 训练集的分数为 0.99,测试集分数为 0.98。
模型后续可优化方向:
属性:数值型数据常常是模型不稳定的来源,可考虑对其进行分箱;重要属性筛选和字段扩充;
算法:其他的集成方法;不同效能评估下的作法调整。


更多精彩推荐
☞Kubernetes 并非灵丹妙药...
☞“云”话数字经济:2020 腾讯全球数字生态大会定档 9 月!
☞蚂蚁上市分给员工 7000 亿股权,曾有人 28 岁财务自由,这次又将产生多少千万富翁?
☞MIT 更新最大自然灾害图像数据集,囊括 19 种灾害事件
☞闲鱼的云原生故事:靠什么支撑起万亿的交易规模?
☞云交易所已成资金盘、杀猪盘重灾区,曾被寄予厚望,如今罪恶丛生
点分享点点赞点在看