lua笔记 lua基础
Table
首先, ..表示连接
Lua里面所有使用索引的地方都是从1开始的!
Table遍历:
For key,val int pairs(tab3) do
Print(key..”:”..val)
end
表内容赋值:
或者[]的形式
Tab1.key1 或者 Tab1[“key1”]
连接:
我们可以使用 concat() 方法来连接两个 table,
print( table.concat(mytable) )
print( table.concat(mytable,","))
print(table.concat(mytable,",",2,4) )
插入:
-- 在末尾插入
table.insert(fruits,"mango")
-- 在索引为 2 的键处插入
table.insert(fruits,2,"grapes")
例子:
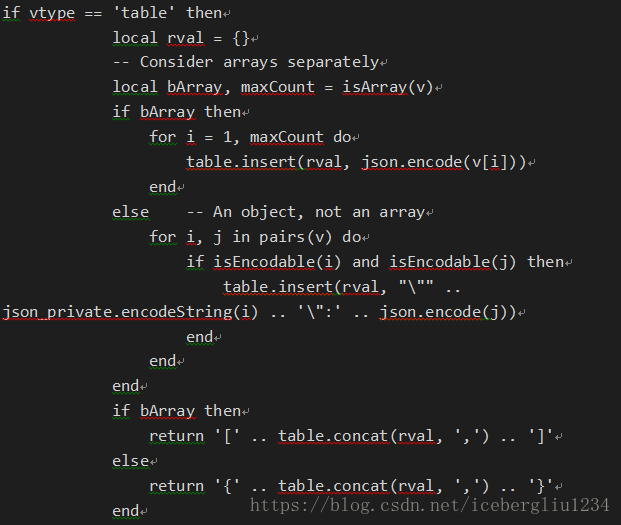
排序:
table.sort(fruits)
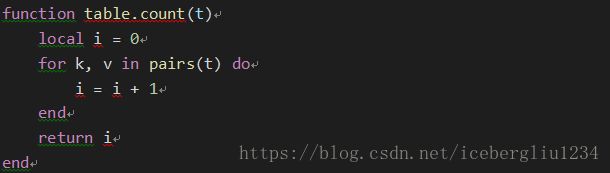
获得长度:
mytable[#mytable+1]="PHP"
!!当我们获取 table 的长度的时候无论是使用 # 还是 table.getn 其都会在索引中断的地方停止计数,而导致无法正确取得table 的长度。
比如我们写:

这个行为未定义,有时候会出错
一般会自己实现:
循环
While循环
While(condition) do
Statements
End
For 循环
For i = 1,10,2 do
Statements
End
For k,v in pairs(tab1) do
Statements
End
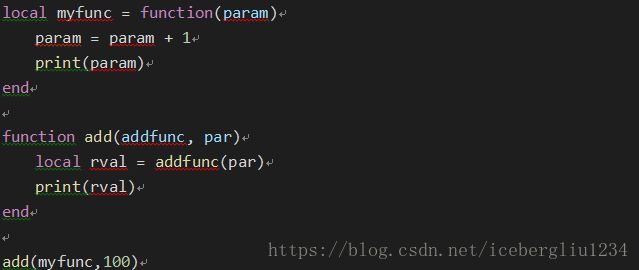
Function 可以赋值以及作为参数
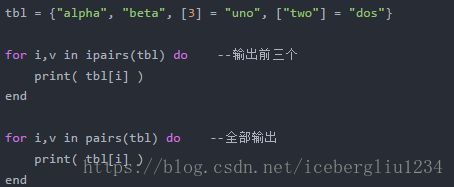
pairs和 ipairs
ipairs遇到nil就停止
for i,v in ipairs(t) do body end
will iterate over the pairs (1,t[1]), (2,t[2]), ···, up to the first integer key absent from the table.
for k,v in pairs(t) do body end
will iterate over all key–value pairs of table t.
具体参考:https://blog.csdn.net/witch_soya/article/details/7556595
可以定义自己的迭代函数
MODULE
module.lua:

usemodule.lua:
-- require "模块名"
-- require ("模块名")

eg:
包路径设置:
RootDefine.lua中:
--protobuf和消息包处理的包含路径
package.path = package.path .. ";./Protobuf/?.lua;./Packet/?.lua;"
debugger.lua中:
ZBS = "E:/ZeroBraneStudioEduPack(1)/";
LuaPath = "E:/NewClientNMG/branches/uLuaClient/src/NMGClient/Assets/DJMain/BundleData/LuaScript/";
package.path =package.path..";./?.lua;"..ZBS.."lualibs/?/?.lua;"..ZBS.."lualibs/?.lua;"..LuaPath.."?.lua;"
关于module( ... ,package.seeall)
一般在一个Lua文件内以module函数开始定义一个包。module同时定义了一
个新的包的函数环境,以使在此包中定义的全局变量都在这个环境中,而非
使用包的函数的环境中。理解这一点非常关键。 “module(...,package.seeall)”
的意思是定义一个包,包的名字与定义包的文件的名字相同,并且在包的函数
环境里可以访问使用包的函数环境。
Metatable
mytable ={"Lua","Java","C#","C++"} --普通表
mymetatable = {} --元表 元表扩展了普通表的行为
setmetatable(mytable,mymetatable)
返回普通表
当元表里面有__metadata键值的时候设置失败
比如tab =setmetatable({"Lua","Java","C#","C++"}, {__metatable="lock"} )
这样的话就可以起到保护元表的作用,禁止用户访问元表中的成员或者修改元表。
print(getmetatable(mytable))
返回普通表所对应的元表
__index元方法
__index当访问到一个不存在的索引的时候 起作用
mymetatable = {
__index = function (tab,key)
if(key>=10)then
return"Javascript"
end
end
}
newtable = {}
newtable[7]="Javascript"
newtable[8]="PHP"
newtable[9]="C"
mymetatable = {
__index = newtable
}
mytable =setmetatable(mytable,mymetatable)
当访问mytable[9]的时候,也就是mytable找不到的时候,__index开始起作用
__newindex当我们对表的数据进行修改的时候,当我们修改的是一个新的索引的时候才会起作用 当我们给表添加新的键值对的时候,起作用
--mytable ={"Lua","Java","C#","C++"}
--[[
mymetatable = {
__newindex = function(tab,key,value)
print("我们要修改的key为:"..key.."把这个key值修改为:"..value)
--tab[key]=value 这样的话就会产生死循环,报错,所以应该用下面的
rawset(tab,key,value)
end
}
--第二种方法:当修改的是不存在的索引的时候,可以修改的是新的table
newtable = {}
mymetatable = {
__newindex = newtable
}
mytable =setmetatable(mytable,mymetatable)
__add
mytable ={"Lua","Java","C#","C++"} --普通表
mymetatable = {
__add = function(tab,newtab)
localmi = 0
fork,v in pairs(tab)do --找到tab的最大index
if(k>mi)then
mi= k
end
end
fork,v in pairs(newtab) do
mi=mi+1
table.insert(tab,mi,v)
end
returntab
end
} --元表 元表扩展了普通表的行为
mytable =setmetatable(mytable,mymetatable)
newtable ={"PHP","Python"}
v=mytable+newtable
v2=newtable + mytable –也是可以的,说明只设置一个表的元表就可以了
__call 把表当成函数来使用
__tostring
mytable ={"Lua","Java","C#","C++","ccccc"}--普通表
mymetatable = {
__add = function(tab,newtab)
localmi = 0
fork,v in pairs(tab)do
if(k>mi)then
mi= k
end
end
fork,v in pairs(newtab) do
mi=mi+1
table.insert(tab,mi,v)
end
returntab
end,
__call = function (tab,arg1,arg2,arg3)
print(arg1,arg2,arg3)
return"siki"
end,
__tostring = function (mytable)
localstr = ""
fork,v in pairs(mytable) do
str= str..v..","
end
returnstr
end
} --元表 元表扩展了普通表的行为
Coroutine:
拥有独立的堆栈,独立的局部变量,独立的指令指针,同时又与其它协同程序共享全局变量和其它大部分东西。
--1,定义协同函数coroutine.create
--2,启动协同函数coroutine.resume
--3,暂停协同函数coroutine.yield
--4,继续运行 coroutine.resume(不需要传递参数)
两种定义方法:
1 co=coroutine.create(
function(a,b)
print(a+b)
end
)
coroutine.resume(co,20,30)
2 co=coroutine.wrap(
function(a,b)
print(a+b)
end
)
co(20,30)
启动方法不一样
co=coroutine.create(
function(a,b)
print(a+b)
print(a+b)
print(coroutine.status(co))–running
print(coroutine.running() ) --获得当前正在运行的协程
coroutine.yield(a*b,a/b) --yield的参数作为返回值返回
print(a-b)
returna%b,a/b+1
end
)
res1,res2,res3 = coroutine.resume(co,10,40)
yield具体的执行:
在执行到yield之后,代码跳转到上一次resume代码的后一条代码执行
再次调用resume,代码就跳转到上一次yield代码的后一条代码执行。
一般来说,resume方法在主线程中调用;而yield则是在coroutine内调用,包括coroutine内部调用的函数内部。
当然了,在coroutine中调用resume没有什么问题,但这样是没有什么意义的,因为如果代码还在coroutine中执行的话,则说明其状态一定是running的,这个时候的resume是没有任何意义的。而在主线程中调用yield,会导致 “lua: attempt to yield across metamethod/C-call boundary”的错误。
print(coroutine.status(co))
--查看coroutine的状态
--注:coroutine的状态有三种:dead,suspend,running
Coroutine eg:
function foo (a) print("foo 函数输出", a) return coroutine.yield(2 * a) -- 返回 2*a 的值end co = coroutine.create(function (a , b) print("第一次协同程序执行输出", a, b) -- co-body 1 10 local r = foo(a + 1) print("第二次协同程序执行输出", r) local r, s = coroutine.yield(a + b, a - b) -- a,b的值为第一次调用协同程序时传入 print("第三次协同程序执行输出", r, s) return b, "结束协同程序" -- b的值为第二次调用协同程序时传入end) print("main", coroutine.resume(co, 1, 10)) -- true, 4print("--分割线----")print("main", coroutine.resume(co, "r")) -- true 11 -9print("---分割线---")print("main", coroutine.resume(co, "x", "y")) -- true 10 endprint("---分割线---")print("main", coroutine.resume(co, "x", "y")) -- cannot resume dead coroutineprint("---分割线---")以上实例执行输出结果为:
第一次协同程序执行输出 1 10foo 函数输出 2main true 4--分割线----第二次协同程序执行输出 rmain true 11 -9---分割线---第三次协同程序执行输出 x ymain true 10 结束协同程序---分割线---main false cannot resume dead coroutine---分割线---讲解:
· 调用resume,将协同程序唤醒,resume操作成功返回true,否则返回false;
· 协同程序运行;
· 运行到yield语句;
· yield挂起协同程序,第一次resume返回;(注意:此处yield返回,参数是resume的参数)
· 第二次resume,再次唤醒协同程序;(注意:此处resume的参数中,除了第一个参数,剩下的参数将作为yield的参数)
· yield返回;
· 协同程序继续运行;
· 如果使用的协同程序继续运行完成后继续调用 resume方法则输出:cannot resume dead coroutine
resume和yield的配合强大之处在于,resume处于主程中,它将外部状态(数据)传入到协同程序内部;而yield则将内部的状态(数据)返回到主程中。
I/O eg:
-- 以只读方式打开文件file = io.open("test.lua", "r") -- 设置默认输入文件为 test.luaio.input(file) -- 输出文件第一行print(io.read()) -- 关闭打开的文件io.close(file) -- 以附加的方式打开只写文件file = io.open("test.lua", "a") -- 设置默认输出文件为 test.luaio.output(file) -- 在文件最后一行添加 Lua 注释io.write("-- test.lua 文件末尾注释") -- 关闭打开的文件io.close(file)
pcall, xpcall, debug.traceback
pcall以一种"保护模式"来调用第一个参数,因此pcall可以捕获函数执行中的任何错误。
通常在错误发生时,希望落得更多的调试信息,而不只是发生错误的位置。但pcall返回时,它已经销毁了调用桟的部分内容。
Lua提供了xpcall函数,xpcall接收第二个参数——一个错误处理函数,当错误发生时,Lua会在调用桟展看(unwind)前调用错误处理函数,于是就可以在这个函数中使用debug库来获取关于错误的额外信息了。
debug库提供了两个通用的错误处理函数:
· debug.debug:提供一个Lua提示符,让用户来检查错误的原因
· debug.traceback:根据调用桟来构建一个扩展的错误消息
>=xpcall(function(i)print(i) error('error..')end,function()print(debug.traceback())end,33)
33
stack traceback:
stdin:1:infunction<stdin:1>
[C]:infunction'error'
stdin:1:infunction<stdin:1>
[C]:infunction'xpcall'
stdin:1:in mainchunk
[C]:in?
false nil
GC:
Eg:
function LuaGC()
local c = collectgarbage("count")
Debugger.Log("Begin gc count = {0} kb", c)
collectgarbage("collect")
c = collectgarbage("count")
Debugger.Log("End gc count = {0} kb", c)
end
Lua 提供了以下函数collectgarbage ([opt [, arg]])用来控制自动内存管理:
· collectgarbage("collect"): 做一次完整的垃圾收集循环。通过参数 opt 它提供了一组不同的功能:
· collectgarbage("count"): 以 K 字节数为单位返回 Lua 使用的总内存数。这个值有小数部分,所以只需要乘上 1024 就能得到 Lua 使用的准确字节数(除非溢出)。
· collectgarbage("restart"): 重启垃圾收集器的自动运行。
· collectgarbage("setpause"): 将 arg 设为收集器的间歇率(参见 §2.5)。返回间歇率的前一个值。
· collectgarbage("setstepmul"): 返回步进倍率的前一个值。
· collectgarbage("step"): 单步运行垃圾收集器。步长"大小"由 arg 控制。传入 0 时,收集器步进(不可分割的)一步。传入非 0 值,收集器收集相当于 Lua 分配这些多(K 字节)内存的工作。如果收集器结束一个循环将返回 true 。
· collectgarbage("stop"): 停止垃圾收集器的运行。在调用重启前,收集器只会因显式的调用运行。
Lua是通过表来实现的面向对象:
Person ={ name="siki",age=99 }
function Person:eat() --使用冒号可以直接在函数体使用self
print(self.name.."在吃饭")
print(self.name.."的年龄是"..self.age)
end
-- 当通过:调用的时候,系统会自动传递当前的table给self, 当通过. 来调用方法的时候,self不会自动赋值,我们必须通过第一个参数来传递当前的table
a.eat(a)
a:eat()
创建对象:
function Person:new(o)
localt = o or {}
--setmetatable(t, { __index=self }) --调用一个属性的时候,如果t中不存在,那么会在__index所指定的table中查找
setmetatable(t,self)
self.__index=self
returnt
end
继承
Student = Person:new() --这样Student其实就是new返回的一张表,其元表是Person,__index指向的也是Person
Student.grade=1
stu1 = Student:new() --Student没有new方法,但是它的元表Person是有的,所以调用的是Person:new,但是因为是Student调用的,所以new里面的self代表的是Student
--所以呢,stu1的元表是Student,而Student的元表是Person
stu1:eat()
print(stu1.grade)