深度学习《Deep Learning》读书笔记 - 第二章线性代数
文章目录
- 2.1 标量、向量、矩阵和张量
- 2.2 矩阵和向量相乘
- 2.3 单位矩阵和逆矩阵
- 2.4 线性相关和生成子空间
- 2.5 范数
- 2.6 特殊类型的矩阵和向量
- 2.7 特征分解
- 2.8 奇异值分解
- 2.10 迹运算
- 2.11 行列式
线性代数其实在大一的时候学习过,但过了四年忘的差不多了,所以再次系统学习一下
在这里附上一篇能比较好说明矩阵意义的文章 ->链接
2.1 标量、向量、矩阵和张量
标量:单独的数
向量:一列数,可以把向量看作空间中的点,每个元素是不同坐标轴上的坐标
x = [ x 1 x 2 ⋮ x n ] x= \left [ \begin{matrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{matrix} \right ] x=⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤
矩阵:二位数组,每一个元素由两个索引决定。
[ A 1 , 1 A 1 , 2 A 2 , 1 A 2 , 2 ] \left [ \begin{matrix} A_{1,1} & A_{1,2} \\ A_{2,1} & A_{2,2} \\ \end{matrix} \right ] [A1,1A2,1A1,2A2,2]
张量: 超过二维的数组
转置: ( A T ) i . j = A j , i (A^T)_{i.j} = A_{j,i} (AT)i.j=Aj,i,标量的转置等于它本身
矩阵的形状一样时,矩阵是可以相加的。
矩阵和向量相加: C i , j = A i . j + b j C_{i,j}=A_{i.j}+b_j Ci,j=Ai.j+bj,意思就是向量b和矩阵A的每一行相加.
2.2 矩阵和向量相乘
矩阵乘积:矩阵A的列数要和矩阵B的行数相等。
A m × n B n × p = C m × p A^{m\times n}B^{n\times p}=C^{m\times p} Am×nBn×p=Cm×p
乘法操作(标准乘积):
C i , j = ∑ k A i , k B k , i C_{i,j}=\sum_kA_{i,k}B_{k,i} Ci,j=k∑Ai,kBk,i
两个相同维数的向量x和y的点积可以看作矩阵 x T y x^Ty xTy:
x = [ x 1 x 2 ⋮ x n ] x= \left [ \begin{matrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{matrix} \right ] x=⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤
y = [ y 1 y 2 ⋮ y n ] y= \left [ \begin{matrix} y_1 \\ y_2 \\ \vdots \\ y_n \end{matrix} \right ] y=⎣⎢⎢⎢⎡y1y2⋮yn⎦⎥⎥⎥⎤
x ⋅ y = [ x 1 y 1 + x 2 y 2 + ⋯ + x n y n ] x·y= \left [ \begin{matrix} x_1y_1+x_2y_2+\cdots+x_ny_n \end{matrix} \right ] x⋅y=[x1y1+x2y2+⋯+xnyn]
矩阵乘积运算服从分配律,结合律,不满足交换律。两个向量的点积满足交换律。
矩阵乘积的转置:
( A B ) T = B T A T (AB)^T=B^TA^T (AB)T=BTAT
2.3 单位矩阵和逆矩阵
单位矩阵: 所有沿主对角线的元素都是1,其他为0
[ 1 0 0 0 1 0 0 0 1 ] \left [ \begin{matrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{matrix} \right ] ⎣⎡100010001⎦⎤
单位矩阵极为 I n I_n In, I n ∈ R n × n I_n\in R^{n\times n} In∈Rn×n
∀ x ∈ R n , I n x = x \forall x \in R^n, I_nx=x ∀x∈Rn,Inx=x
A A A的逆矩阵计为 A − 1 A^{-1} A−1: A − 1 A = I n A^{-1}A=I_n A−1A=In
2.4 线性相关和生成子空间
一组向量的线性组合,是指每个向量乘以对应标量系数之后的和:
∑ i = c i v ( i ) \sum_i =c_iv^{(i)} i∑=civ(i)
一组向量的生成子空间,是原始向量线性组合后所能抵达的点的集合。
矩阵的列空间 ColA(参考链接)
对于 m×n 矩阵 A A A,列空间就是 A A A的各列的线性组合的集合,记为 ColA,是 R m \large R^m Rm的一个子空间,由 矩阵的主元列构成,即Ax=b中,方程的解基本变量。
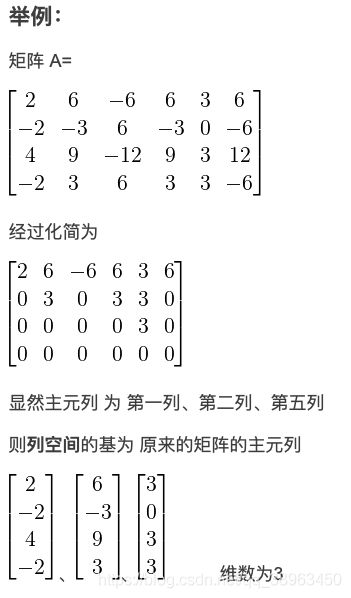
确定 A x = b Ax=b Ax=b是否有解,相当于确定向量 b b b是否在A列向量的生成子空间中。这个特殊的生成子空间被称为 A A A的列空间或者 A A A的值域
线性无关:一组向量中的任意一个向量都不能表示成其他向量的线性组合
线性相关:某个向量是一组向量中某些向量的线性组合,将这个向量加入这组向量后不会增加这组向量的生成子空间
如果一个矩阵的列空间涵盖整个 R m R^m Rm,说明该向量集恰好有m个线性无关的列向量。
2.5 范数
范数:衡量一个向量的大小。形式上, L p L^p Lp范数定义如下:
∥ x ∥ p = ( ∑ i ∣ x i ∣ p ) 1 p \parallel x \parallel _p=(\sum_i\vert x_i\vert^p)^{\frac{1}{p}} ∥x∥p=(i∑∣xi∣p)p1
其中 p ∈ R p\in R p∈R, p ≥ 1 p\ge1 p≥1。
范数是将向量映射到非负值的函数。直观上来说,向量 x x x的范数衡量从原点到点 x x x的距离。
当 p = 2 p=2 p=2时, L 2 L^2 L2范数称为欧几里得范数,它表示从原点出发到向量 x x x的点的欧几里得距离。经常简化表示为 ∥ x ∥ \parallel x \parallel ∥x∥。
L 1 L^1 L1范数可以简化为:
∥ x ∥ 1 = ∑ i ∣ x i ∣ \parallel x \parallel _1=\sum_i\vert x_i\vert ∥x∥1=i∑∣xi∣
另一个在机器学习中经常出现的是 L ∞ L^\infty L∞,也被称为最大范数,最大范数表示向量中具有最大幅值的元素的绝对值:
∥ x ∥ ∞ = m a x i ∣ x i ∣ \parallel x \parallel _\infty =max_i\vert x_i\vert ∥x∥∞=maxi∣xi∣
Frobenius范数:衡量矩阵的大小
∥ A ∥ F = ∑ i , j A i , j 2 \parallel A \parallel_F=\sqrt{\sum_{i,j}A_{i,j}^2} ∥A∥F=i,j∑Ai,j2
2.6 特殊类型的矩阵和向量
对角矩阵:只在主对角线上含有非零元素,其他位置都是零。
用diag(v)表示对角元素由向量 v v v中元素给定的一个对角方阵。
计算乘法diag ( v ) x (v)x (v)x,只需要将 x x x中的每个元素 x i x_i xi放大 v i v_i vi倍,diag ( v ) x = v ⊙ x (v)x=v\odot x (v)x=v⊙x
对角方阵的逆矩阵:diag ( v ) − 1 = (v)^{-1}= (v)−1=diag ( [ 1 / v 1 , ⋯ , 1 / v n ] ) T ([1/v_1,\cdots ,1/v_n])^T ([1/v1,⋯,1/vn])T
对称:矩阵的转置和自己相等, A = A T A=A^T A=AT
单位向量:具有单位范数的向量, ∥ x ∥ 2 = 1 \parallel x \parallel _2=1 ∥x∥2=1
正交:如果 x T y = 0 x^Ty=0 xTy=0,那么向量 x x x和 y y y互相正交。如果两个向量都有非零范数,那么这两个向量之间的夹角是90度。如果这些向量不仅互相正交,同时范数都为1,那称为标准正交。
正交矩阵: A T A = A A T = I A^TA=AA^T=I ATA=AAT=I,这意味着 A − 1 = A T A^{-1}=A^T A−1=AT
2.7 特征分解
特征分解:将矩阵分解成一组特征向量和特征值
方阵 A A A的特征向量 v v v:
A v = λ v Av=\lambda v Av=λv
其中标量 λ \lambda λ称为这个特征向量对应的特征值。
>参考链接
一个矩阵的一组特征向量是一组正交向量。特征分解是将一个矩阵分解成下面的形式:
A = V d i a g ( λ ) V − 1 A = Vdiag(\lambda)V^{-1} A=Vdiag(λ)V−1
其中 V V V是这个矩阵 A A A的特征向量组成的矩阵, d i a g ( λ ) diag(\lambda) diag(λ)是一个对角阵,每一个对角线上的元素就是一个特征值。
所有特征值都是正数的矩阵称为正定,所有特征值都是非负数的矩阵称为半正定;所有特征值都是负数的矩阵称为负定,所有特征值都是非正数的矩阵称为半负定。
2.8 奇异值分解
奇异值分解:将矩阵分解为奇异向量和奇异值
每个实数矩阵都有一个奇异值分解,但不一定有特征分解。非方阵的矩阵没有特征分解。
将矩阵 A A A奇异值分解:
A = U D V − 1 A=UDV^{-1} A=UDV−1
A A A是一个 m × n m\times n m×n的矩阵, U U U是一个 m × m m\times m m×m的矩阵, D D D是一个 m × n m\times n m×n的矩阵, V V V是一个 n × n n\times n n×n的矩阵, U U U和 V V V都是正交矩阵, D D D是对角矩阵。对角矩阵 D D D对角线上的元素是奇异值。
2.10 迹运算
迹运算返回的是矩阵对角元素的和:
T r ( a ) = ∑ i A i , i Tr(a)=\sum_iA_{i,i} Tr(a)=i∑Ai,i
迹运算提供了另一种描述矩阵Frobenius范数的方式:
∥ A ∥ F = T r ( A A T ) \parallel A \parallel_F=\sqrt{Tr(AA^T)} ∥A∥F=Tr(AAT)
2.11 行列式
行列式记为det(A),等于矩阵特征值的乘积。行列式的绝对值可以用来衡量矩阵参与矩阵乘法后空间扩大或者缩小了多少。