Python机器学习笔记二
1.Sklearn中Adaboost类库概述
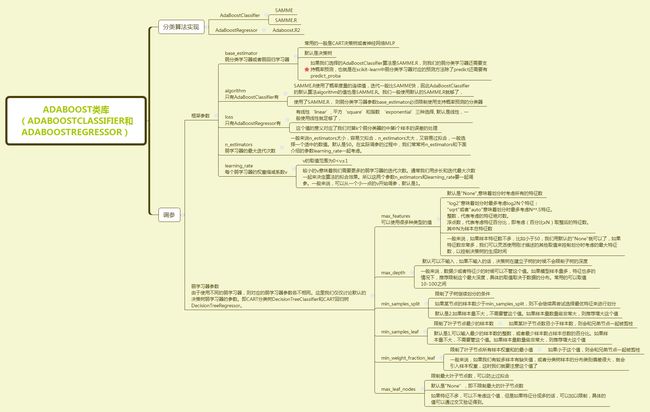
参考链接:http://www.cnblogs.com/pinard/p/6136914.html
2.随机数据生成
(1)numpy随机数据生成
1.rand(d0, d1, ..., dn) 生成d0xd1x...dn维的数组。数组的值在[0,1]之间 1
2.randn((d0, d1, ..., dn), 生成d0xd1x...dn维的数组。不过数组的值服从N(0,1)的标准正态分布
如果需要服从N(μ,σ2)的正态分布,只需要在randn上每个生成的值x上做变换σx+μ即可
3.randint(low[, high, size]),生成随机大小为size的数据,size可以为整数、矩阵维数,张量维数。
值位于半开区间 [low, high)。
例如:np.random.randint(3, size=[2,3,4])返回维数维2x3x4的数据。取值范围为最大值为3的整数
4.random_integers(low[, high, size]),与randint类似,区别在与取值范围是闭区间[low, high]
5.random_sample([size]), 返回随机的浮点数,在半开区间 [0.0, 1.0)。
如果是其他区间[a,b),可以加以转换(b - a) * random_sample([size]) + a
例如: (5-2)*np.random.random_sample(3)+2 返回[2,5)之间的3个随机数。
(2). scikit-learn随机数据生成API介绍
和numpy比起来,可以用来生成适合特定机器学习模型的数据。常用的API有:
1) 用make_regression 生成回归模型的数据
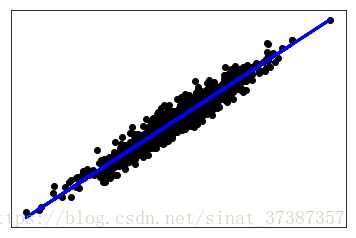
2) 用make_hastie_10_2,make_classification或make_multilabel_classification生成分类模型 数据

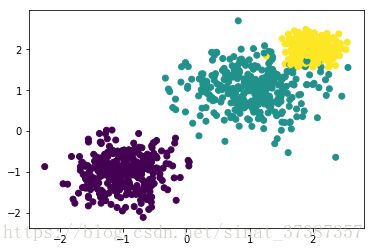
3) 用make_blobs生成聚类模型数据
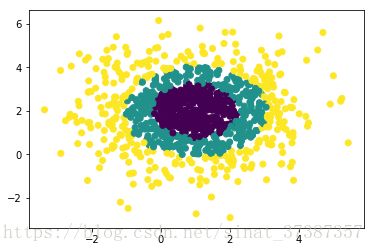
4) 用make_gaussian_quantiles生成分组多维正态分布的数据
参考链接:http://www.cnblogs.com/pinard/p/6047802.html
3.gridsearchcv(网格搜索)