Python爬虫之网易云音乐数据爬取(十五)
原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
一、 前言
网易云音乐是一款由网易开发的音乐产品,是网易杭州研究院的成果 ,依托专业音乐人、DJ、好友推荐及社交功能,在线音乐服务主打歌单、社交、大牌推荐和音乐指纹,以歌单、DJ节目、社交、地理位置为核心要素,主打发现和分享。
网易云音乐上面的评论数据具有很重要的作用。通过获取这些评论数据,包括:评论用户ID,评论用户昵称,评论用户位置,评论用户评论内容,该评论被点赞人数,用户头像地址,评论时间等信息。通过用户相关的数据,可以分析用户的组成成分,从而进行更具有针对性的用户推荐,通过评论数据集可以进一步做中文分词、命名实体识别、关键词提取、句法分析、文本向量化、情感分析、舆情分析等进一步的数据处理和应用。本篇博文通过网易云的API接口,来获取数据。Enough Talk,Let’s start it。!!!!!!

二、思路过程
这次选取的单曲是爱尔兰斯莱戈郡的男子组合Westlife的最新单曲《Hello My Love》(Westlife的歌迷朋友们,在此抱拳了,幸会幸会!!!!!)。

既然要获取歌曲的评论,那么通过开发者工具来看看,这些评论在哪里?根据我们的经验,显然可以看出这个是通过AJAX方式加载数据的,接下来就是在XHR中找到了这些动态加载的评论.
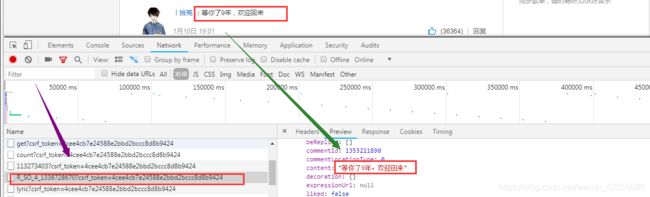
可以看到,在 R_SO_4_26075485?csrf_token=中,包含了comments以及hotComments,这两个分别对应的是最新评论以及热门评论,而这些评论是通过向https://music.163.com/weapi/v1/resource/comments/R_SO_4_26075485?csrf_token=
发起post请求得到的,期间还传入两个参数,params 和 encSecKey,对于post请求会有个form表单需要提交去请求,而这个form表单就是Form Data,其中两个参数params和encSecKey的值会因为刷新页面而改变的,这种改变时采用了 AES,rsa 加密算法,对数据进行了两次 AES 加密等等,所以需要解密至于如何解密,以后有时间再学习讨论。本篇文章采用API接口的方式,获得数据。

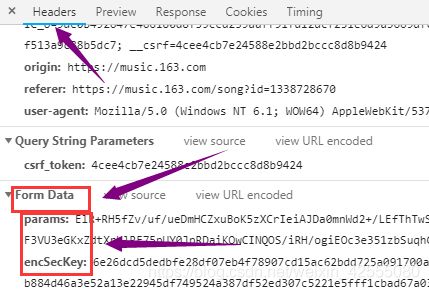
通过API接口获取精彩评论,这里使用是最简单的表单提交的方法请求的。
三、代码及结果分析展示
表单提交的方法请求,需要获取评论是根据链接 http://music.163.com/api/v1/resource/comments/R_SO_4_1338728670?limit=20&offset=39
写的循环代入limit和offset两个参数,其实这个并没有完全实现自动化的原则。后面都是同样的方式将请求的json内容转成常用的字典形式获取相应的内容。上面的那个链接需要解释一下:
- 其中固定部分(也就是说,无论你爬取的是哪个歌曲的评论信息,这些内容都是固定的):http://music.163.com/api/v1/resource/comments/
- 接着R_SO_4_1338728670?这个相当于每首歌曲的身份证,它是唯一标识单曲的身份。找到它很容易,如下图,首先找到R_SO_*.xhr文件,然后在Request URL截取需要的内容就可以了。

- 最后是传入的参数param,一个是limit一个是offset. 其中limit就是指评论数量,比如这首《Hello MY LOVE》它的评论数量就是33372,如下图:
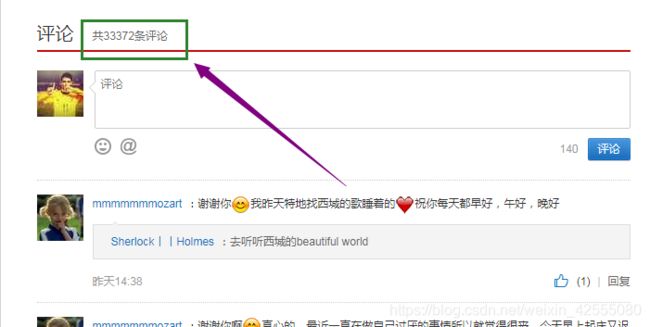
所以它最大的limit就是33372-20(为啥-20,请往后看).
offset是偏移量,因为每个分页页面是有20条热评,所以它的偏移量就是20为单位。
这里需要注意,limit和offset是变动的。 在爬取网易云音乐评论数据时,limit初始值是0,offset是19,(19-0+1=20符合偏移量为20的要求),然后接着就是limit=20,offset=39,直到最后offset的最大值达到33372为止,此时的limit是33372-20。
明白这些,接下来,依然选取上面那个接口链接,看看接口里面都有哪些数据,截取其中一个片段,看看这个字典型结构里面的数据:
[{"user":{"locationInfo":null,
"authStatus":0,
"avatarUrl":"http://p1.music.126.net/hg2hVX5NK-6dOsslemXO9Q==/109951164027599764.jpg",
"vipRights":{"associator"{"vipCode":100,"rights":true},
"musicPackage":null,"redVipAnnualCount":-1},
"expertTags":null,
"experts":null,
"userType":0,
"remarkName":null,
"userId":330529878,
"nickname":"快乐的李小狼",
"vipType":11},
"beRepliedCommentId":1483778420,
"content":"顶我一下,我买了一张澳门站的westlife.的演唱会的门票500多的那个,由于有事儿去不了了,可以协商转让蟹蟹啦,私信我,我绝对不是骗子,实在没办法了,准备去马来西亚看吉隆坡那场了?",
"status":0,
"expressionUrl":null}],
"pendantData":null,
"showFloorComment":null,
"status":0,"commentLocationType":0,
"parentCommentId":1483778420,
"decoration":{},
"repliedMark":false,
"expressionUrl":null,
"time":1557397780169,
"liked":false,
"likedCount":0,
"commentId":1483840099,
"content":"吉隆坡那场是什么时候呀"}
如上的数据还真不少,只要你可视的内容,都有涉及。总共可分为几大类:评论用户信息、评论信息、用户权限信息、评论回复信息等。
具体的代码如下:
# -*- coding:utf-8 -*-
import requests
import json
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36",
}
# 获得接口,解析评论接口
def parse_comments_json(comments_list, path):
for hotComments in comments_list:
print("==============================================")
user_icon = hotComments.get('user').get('avatarUrl')
print("user_icon: ", user_icon)
userId = hotComments.get('user').get('userId')
print("userId: ", userId)
user_nickname = hotComments.get('user').get('nickname')
print("user_nickname: ", user_nickname)
comment_time = hotComments.get('time')
print("comment_time: ", comment_time)
comment_time = time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime(float(comment_time) / 1000))
print(comment_time)
zan_count = hotComments.get('likedCount')
print("zan_count: ", zan_count)
comment_content = hotComments.get('content')
print("comment_content: ", comment_content)
try:
# 读写文件
with open(path, 'a+', encoding='utf-8') as f:
f.write(str(userId) + ";" + user_nickname + ";" + comment_content + ";" + str(
zan_count) + ";" + user_icon + "; " + comment_time + "\n")
except Exception as e:
pass
# 获取全部评论
def get_wangyiyu_comments(url, path):
header = {
'Accept': "*/*",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Host': "music.163.com",
'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36"
}
n = 1
for i in range(0, 150, 20):
param = {
'limit': str(i),
'offset': str(n * 20 - 1)
}
n += 1
response = requests.post(url, headers=header, params=param)
comments_dict = json.loads(response.text)
comments_list = comments_dict.get('comments')
print(comments_list)
parse_comments_json(comments_list, path=path)
# 制作评论词云
def draw_wordcloud(path):
from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
bg_mask = np.array(Image.open('0042137115.jpg'))
text = open(path, encoding='utf-8').read()
wordContent = []
print(text)
for word in text:
#print(word+"**********************")
if word >= u'\u4e00' and word <= u'\u9fa5':#判断是否为汉字
wordContent.append(word)
my_wordcloud = WordCloud(background_color='white', # 设置背景颜色
mask=bg_mask, # 设置背景图片
max_words=2000, # 设置最大显示的字数
font_path=r'C:\Windows\Fonts\STZHONGS.TTF', # 设置中文字体,使的词云可以显示
max_font_size=250, # 设置最大字体大小
random_state=30, # 设置有多少种随机生成状态, 即有多少种配色方案
)
myword = my_wordcloud.generate(str(wordContent))
plt.imshow(myword)
plt.axis('off')
plt.show()
if __name__ == '__main__':
path = 'HelloMyLove.txt'
start_time = time.time()
comments_url = "http://music.163.com/api/v1/resource/comments/R_SO_4_1338728670" # 小宇
get_wangyiyu_comments(comments_url, path)
end_time = time.time()
print("程序耗时%f秒." % (end_time - start_time))
draw_wordcloud(path)
结果如下图所示,分别是控制台输出、生成的HelloMyLove.txt文件内容、词云可视化结果:


当然,还可以用其他的数据,来做进一步分析,在此就不在举例了。
四、总结
这篇文章是网易云音乐评论数据的爬取,采取的方式是通过API接口做的,API接口将数据以字典的形式给出,里面的数据比较全面,大块可分为:评论用户信息、评论信息、用户权限信息、评论回复信息等。本文爬去的数据有,评论人昵称、评论时间、评论内容、点赞数、用户ID、评论人头像地址。这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。
