关于Transformer的个人理解
主要内容
- 动态的词嵌入
- 传统的词向量模型
- 基于上下文的词向量模型
- Transformer
- 模型结构
- 数据的流动
- 单向Transformer
- 关于decoder部分的一些见解
动态的词嵌入
传统的词向量模型
这类模型是早些年的主流。其中最具代表性的就是Word2Vec模型了。在一个大语料库上进行训练后,每个单词的向量就固定下来,在不同的语境中的表示是完全一样的。
我们每天使用语言,应该知道同样的词在不同的情况下属性能够体现出相当程度的不同。
举个英文的例子:
He’s a bad guy!
I love you so bad!
这里可以看出,同样的bad,一个体现负面的意义,另一个却可以起到增强情感的作用。
因此,不能很好捕捉单词的多义信息,是这类模型的缺点,单词的语义很大程度上依赖于训练时的语料。
基于上下文的词向量模型
基于上下文的词向量是一种动态的词嵌入,其动态就体现在,同样的单词,其表示在不同的语境中是不一样的,是随着我们输入的语句动态产生的。这样,可以更好地捕捉单词的多义性。在ELMo的原文中,作者针对这一特点做了实验:

第一行是利用GloVe训练的词向量,第二行是ELMo的主体—一个双向语言模型所产生的动态词向量。
可以看到GloVe的词向量,在空间中与其最接近的词有许多,但被其捕捉到的大部分语义仍然是围绕单词play在运动这一方面的语义。
而在ELMo模型中的词向量能够随句子上下文信息的不同而相应调整。可以看到第一句中play有动作/表现之意,其空间中最接近的词向量在对应上下文中也是同样的意思。
第二句则是表演的意思,在邻近的句子中也能够对应得上。
这也是动态的词向量的好处,能够更好捕捉基于上下文的单词真正语义。
Transformer产生的也是这样的动态词表示。
Transformer
Transformer在论文:Attention is All You Need中提出,目前已经可以说是最强特征提取器。其后又出现了许多基于此的变种Transformer,在这里可以了解:传送门
一般我们用Transformer做特征提取指的是原文中的Encoder部分。
模型结构

这是原文中的模型架构,左半部分是stack形式的Encoder,右边则是stack形式的decoder。
该模型可以分为两部分来说,一是嵌入层部分,二是真正进入 Encoder的部分。
首先是嵌入层的部分:
首先,将输入的序列Token通过一个线性层,变换成对应的词向量。
其次,在正式进入模型前,还需要经过一个position embedding。正如论文名字attention is all you need,该模型中抛弃了传统的RNN结构,也不含有卷积结构。因此在捕捉序列信息方面会有所欠缺。position embedding正是为了弥补这一缺点而进行的。
文中,作者使用的是正余弦编码,编码针对输入序列中每个位置的每一个维度,因此position embedding与词向量的维度是一致的,可以直接相加。
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}\;=\;\sin\left(pos/10000^{2i/d_{model}}\right) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i+1)}\;=\;\cos\left(pos/10000^{2i/d_{model}}\right) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 p o s pos pos代表序列中的位置, i ∈ ( 0 , 1 , 2 , 3...... , d m o d e l / / 2 ) i \in(0,1,2,3......, d_{model}//2) i∈(0,1,2,3......,dmodel//2)代表向量的每一维度, d m o d e l d_{model} dmodel 代表词向量的维度。可以看到,针对序列的奇/偶数维度,transformer分别采用余弦/正弦进行编码。
关于这么做的目的,这个答案:传送门给出了一些解释,但我个人还是有些不明白的。
大体解释如下:
我们知道,一个单词的稠密表示中,其每一维我们可以简单地认为是该单词不同语义的表征。那么,同样的单词若是在不同的上下文中体现出不同的语意的话,其对应维度应当有变化。对比上文的公式。可以看到,首先是同样的单词若是在不同的 p o s pos pos其对应维度的编码会呈周期性的变化。
其次,利用三角函数的性质:
{ sin ( α + β ) = sin ( α ) cos ( β ) + sin ( β ) cos ( α ) cos ( α + β ) = cos ( α ) cos ( β ) − sin ( α ) sin ( β ) \left\{\begin{array}{l}\sin\left(\alpha+\beta\right)\;=\;\sin(\alpha)\cos(\beta)+\sin(\beta)\cos(\alpha)\\\cos(\alpha+\beta)\;=\;\cos(\alpha)\cos(\beta)\;-\;\sin(\alpha)\sin(\beta)\end{array}\right. {sin(α+β)=sin(α)cos(β)+sin(β)cos(α)cos(α+β)=cos(α)cos(β)−sin(α)sin(β)
可以有如下的结论:
{ P E ( p o s + k , 2 i ) = P E ( p o s , 2 i ) × P E ( k , 2 i + 1 ) + P E ( p o s , 2 i + 1 ) × P E ( k , 2 i ) P E ( p o s + k , 2 i + 1 ) = P E ( p o s , 2 i + 1 ) × P E ( k , 2 i + 1 ) − P E ( p o s , 2 i ) × P E ( k , 2 i ) \left\{\begin{array}{l}PE_{(pos+k,2i)}\;=\;PE_{(pos,2i)}\times PE_{(k,2i+1)}\;+\;PE_{(pos,2i+1)}\times PE_{(k,2i)}\\PE_{(pos+k,2i+1)}\;=\;PE_{(pos,2i+1)}\times PE_{(k,2i+1)}\;-\;PE_{(pos,2i)}\times PE_{(k,2i)}\end{array}\right. {PE(pos+k,2i)=PE(pos,2i)×PE(k,2i+1)+PE(pos,2i+1)×PE(k,2i)PE(pos+k,2i+1)=PE(pos,2i+1)×PE(k,2i+1)−PE(pos,2i)×PE(k,2i)
也就是说,在 p o s + k pos+k pos+k位置的编码,是由在 p o s pos pos, k k k位置的位置编码的线性组合构成的。这在某种程度上为模型引入了序列的信息。
得到位置编码后,将其与词向量相加,送入Encoder。
Encoder可以视作由两个子层构成,分别是FFN层以及Self-attention层,并且每个子层输出前后存在残差连接以及LayerNormalization。这也意味着数据在流入子层以及流出子层时具有相同的形状。
首先,经过 Multi-head self-attention层,这也是该模型最大的特点所在。
先忽略Multi-head,说单个self-attention的计算:
原文中使用的是Scaled Dot-Product attention。基于点积计算每个位置的 s c o r e score score。
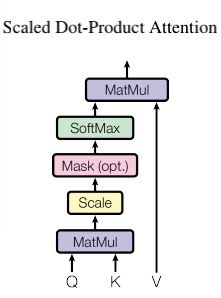
对于序列中的每一个单词,我们计算一个向量的三元组 ( k , q , v ) (k,q,v) (k,q,v)其中 k k k是 k e y key key, q q q是 q u e r y query query, v v v是 v a l u e value value。
具体计算时,利用三个参数矩阵 W K , W Q , W V W_K,W_Q,W_V WK,WQ,WV进行,其中三个矩阵的维度为:
W K ∈ R d m o d e l × d k W_K \in \mathbb{R}^{d_{model}\times d_k} WK∈Rdmodel×dk
W Q ∈ R d m o d e l × d k W_Q\in\mathbb{R}^{d_{model}\times d_k} WQ∈Rdmodel×dk
W V ∈ R d m o d e l × d v W_V\in\mathbb{R}^{d_{model}\times d_v} WV∈Rdmodel×dv
通过矩阵变换后, k e y key key与 q u e r y query query有相同的维度 d k d_k dk,而 v a l u e value value有不同的维度 d v d_v dv。
我们知道attention中最重要的就是计算序列中每个位置的权重,在self-attention中,对于序列中的一个单词我们这样计算分数:
s c o r e ( i , j ) = q i ⋅ k j score_(i,j)=q_i\cdot k_j score(i,j)=qi⋅kj
则对于位置 i i i的单词来说,某一个位置的权重为:
a j = e x p ( q i ⋅ k j ) ∑ j ∈ C e x p ( q i ⋅ k j ) a_j = \frac{exp(q_i\cdot k_j)}{{\displaystyle\sum_{j\in C}}exp(q_i\cdot k_j)} aj=j∈C∑exp(qi⋅kj)exp(qi⋅kj)
最终该位置单词的输出表示为:
z i = ∑ j ∈ C a j ⋅ v j d k z_i\;=\;\frac{{\displaystyle\sum_{j\in C}}a_j\cdot v_j}{\sqrt{d_k}} zi=dkj∈C∑aj⋅vj
对于一个单词,我们用它的 q u e r y query query与每一个位置(包括自己)的 k e y key key得到每个位置的 s c o r e score score然后归一化得到每一个位置的权重,然后对应位置的权重与对应位置的 v a l u e value value求加权和得到该单词的输出 z i z_i zi,此处加入规格化因子 1 d k \frac{1}{\sqrt{d_k}} dk1是因为过大的 d k d_k dk会导致每个位置的点积迅速扩大。这样会将softmax的值趋于一个梯度较小的区域。
注意到图中结构有一个optional的部分 M a s k ( o p t . ) Mask(opt.) Mask(opt.),关于这部分,原文的描述如下:
Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
加粗部分阐述了这个 M a s k Mask Mask 的目的,是为了让decoder保持自回归的性质,因此我们要阻止来自未来的信息流向左移动。所以,在当前位置之后的所有单词decoder应该是看不见的,因此此处只对序列开始到当前位置的单词计算dot-product attention。
以上是单头注意力的计算。但在transformer中,使用的是多头注意力:
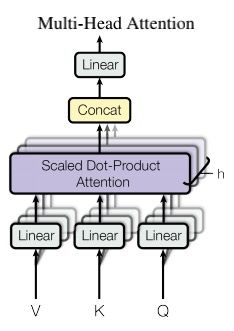
应用多头注意力之后,同一个位置能够捕捉到不同层面的语义,计算如上图所示。
如果有 h h h个头,我们就有 h h h套矩阵 W Q , W V , W K W_Q,W_V,W_K WQ,WV,WK因此,同个单词有 h h h个三元组 ( k , q , v ) (k,q,v) (k,q,v),同一位置我们就得到了 h h h个表示 z i z_i zi , i ∈ 1 , 2 , 3 , . . . . . . . , h i \in {1,2,3,.......,h} i∈1,2,3,.......,h。
之后,将 h h h个表示拼接在一起,得到一个 h ∗ d v h*d_v h∗dv的表示。但这样维度就增大了,记得我们还有残差连接,所以需要将维度对齐。
将拼接后的表示再送入一个线性层,通过矩阵 W O W_O WO将其维度变为 d v d_v dv,随后与残差连接的向量相加,完成 self-attention层的数据变换。
之后就是送入FNN子层,完成一个Transformer block的数据变换。无论叠加多少个Encoder,最终在顶层加上softmax即可得到我们想要的结果。
数据的流动
列出模型中张量的形状变换
T o k e n : [ b a t c h _ s i z e , s e q _ l e n ] Token: [batch\_size,seq\_len] Token:[batch_size,seq_len]
⬇️
I n p u t e m b e d d i n g : [ b a t c h _ s i z e , s e q _ l e n , e m b e d d i n g _ s i z e ] Input\;embedding:[batch\_size,seq\_len,embedding\_size] Inputembedding:[batch_size,seq_len,embedding_size]
⬇️
P o s i t i o n a l e m b e d d i n g : [ b a t c h _ s i z e , s e q _ l e n , e m b e d d i n g _ s i z e ] Positional\;embedding:[batch\_size,seq\_len,embedding\_size] Positionalembedding:[batch_size,seq_len,embedding_size]
⬇️
S e l f A t t e n t i o n S u b L a y e r : [ b a t c h _ s i z e , s e q _ l e n , d v ] Self\;Attention\;SubLayer:[batch\_size,seq\_len,d_v] SelfAttentionSubLayer:[batch_size,seq_len,dv]
⬇️
F e e d F o w a r d S u b l a y e r : [ b a t c h _ s i z e , s e q _ l e n , v o c a b _ s i z e ] FeedFoward\;Sublayer:[batch\_size,seq\_len,vocab\_size] FeedFowardSublayer:[batch_size,seq_len,vocab_size]
单向Transformer
在OpenAI的GPT模型中使用的就是单向transformer。单向的 transformer也就是允许模型捕捉来自一侧的信息。对于使用 self-attention机制的transformer来说,也就是使用了带有 M a s k Mask Mask的self-attention子层,从而使模型只接受来自一侧的信息。该结构就如上文所述,仅计算合法位置的权重。
关于decoder部分的一些见解
原文中Attention有三处应用,前文已经提到了两种,分别是捕捉全句信息的self-attention以及仅允许单侧信息的Mask self-attention。
第三种应用同样出现在decoder当中。我们知道,在传统的Seq2Seq结构中,decoder需要在解码的时候得到来自encoder的编码信息。在Transformer中这一点也不例外,我们仍然使用三元组 ( k , q , v ) (k,q,v) (k,q,v)计算权重,但不同的是,此处不再是针对decoder中的单词进行计算,现在将attention放在encoder身上。我们希望得到它的编码信息,这里 ( k , v ) (k,v) (k,v)由encoder的输出提供,原文称之为memory keys/values。 q q q则来自上一个子层的输出。