论文翻译:Skeleton Based Human Action Recognition with Global Context-Aware Attention LSTM Networks
摘要三维骨骼序列中的人体动作识别已经引起了人们的广泛关注。最近,由于长短期记忆(LSTM)网络在序列数据的依赖性和动态性建模方面的优势,在这方面表现出了良好的性能。并不是所有的骨骼关节都具有动作识别的信息性,而不相关的关节往往会带来噪声,从而降低动作识别的性能,因此需要对具有信息性的关节给予更多的关注。然而,原有的LSTM网络并没有明确的注意能力。在本文中,针对基于骨架的动作识别,我们提出了一种新的基于骨架的动作识别网络——全局上下文感知注意网络(GCA-LSTM),该网络能够利用全局上下文记忆单元有选择地聚焦于每一帧中的信息节点。为了进一步提高网络的注意能力,我们还引入了一种反复注意机制,通过这种机制,网络的注意性能可以逐步提高。此外,还介绍了利用粗粒度关注和细粒度关注的两流框架。所提出的方法达到了最佳水平。
索引词-动作识别,长短期记忆,全局上下文记忆,注意,骨架序列。
由于动作识别具有广泛的应用,如视频监控、患者监护、机器人技术、人机交互等,因此它是一个非常重要的研究问题。随着RealSense和Kinect[4]、[5]等深度传感器的发展,[6],基于3D骨架的人体动作识别得到了人们的广泛关注,在过去的几年里提出了很多先进的方法[7],[8],[9],[10]人体动作可以通过骨骼关节在三维空间[11]、[12]中的运动组合来表示。然而,这并不意味着骨骼序列中的所有关节都能提供动作识别的信息。例如,手关节的运动对拍手的动作很有帮助,而脚关节的运动则不然。不同的动作序列往往具有不同的信息关节,在相同的序列中,身体关节的信息程度也会随着帧的变化而变化。因此,有选择地关注信息节点i是有益的并尽量忽略不相关的特征,因为后者对动作识别的贡献很小,甚至会带来噪声,影响[13]的性能。这种选择性聚焦方案也被称为注意力,它已经被证明在各种任务中非常有用,如语音识别[14],图像标题的生成[15],机器翻译[16],等等。
长短期存储(LSTM)网络在处理连续数据[17]方面具有强大的能力。已成功应用于语言建模[18],基于RGB的视频分析[19],[20],[21],[22],[23],[24],[25],[26],[27],以及基于骨架的动作识别[18]2,[18]0,[18]1。但是,原有的LSTM对动作识别的注意能力不强。这主要是由于LSTM在感知视频序列的全局上下文信息方面的限制,而这对于全局分类问题sk来说往往是非常重要的为了对骨骼关节进行可靠的关注,我们需要根据整体动作序列对每一帧中每个关节的信息量进行评估。这表明我们首先需要拥有全局上下文知识。但是,在LSTM的每个演化步骤中,可用的上下文信息都是相对局部的。在LSTM中,顺序数据作为输入逐步输入到网络中。相应地,每个步骤的上下文信息(隐藏的表示)被提供给下一个步骤。这意味着每一步中可用的上下文是隐藏的代表在此基础上,提出了一种具有较强注意能力的全局上下文感知注意网络,用于基于骨架的动作识别。在我们的方法中,全局上下文信息被提供给GCALSTM的所有进化步骤。因此,网络可以使用它来测量新输入在所有步骤的信息分值,并相应地调整它们的注意权重,即。,如果一个新的输入是关于全球行动的信息,则网络在这一步利用更多的信息。

基于骨架的人类动作识别与全球上下文感知注意力LSTM网络。第一个LSTM层对骨架序列进行编码,并为动作序列生成一个初始全局上下文表示。第二层通过使用全局上下文记忆单元对输入执行注意,以实现序列的注意表示。然后利用注意力表示来优化全局上下文。通过多次注意迭代,逐步优化全局上下文记忆。最后,精炼的全局上下文信息。
我们提出的基于骨架的动作识别的GCA-LSTM网络包括一个全局上下文记忆单元和两个LSTM层,如图1所示。第一个LSTM层用于编码骨架序列和初始化全局上下文内存单元。然后将全局上下文记忆的表示反馈给第二层LSTM,以帮助网络选择性地聚焦于每一帧的信息节点,进而生成动作序列的注意表示。然后将注意力表征反馈到全局上下文记忆单元中由于在注意过程后产生了一个精炼的全局上下文存储器,因此可以将全局上下文存储器再次输入到第二层LSTM中,以更可靠地执行注意。通过多次注意迭代,逐步优化全局上下文记忆。最后,将精炼后的全局上下文输入到softmax分类器中,对动作类进行预测。此外,我们还扩展了上述设计我们的本文在GCA-LSTM网络中,进一步提出了一种双流GCA-LSTM,该双流GCA-LSTM结合了细粒度(关节级)注意和粗粒度(身体部分级)注意,以获得更准确的动作识别结果。
本文的贡献总结如下:
•提出了一种GCA-LSTM模型,该模型保留了原LSTM的顺序建模能力,同时通过引入全局上下文记忆单元来提高其选择性注意能力。
•提出了一种反复注意机制,通过这种机制,我们的网络的注意性能可以逐步提高。
•为了更有效地训练网络,提出了一种逐步训练方案。
•我们进一步扩展了GCA-LSTM模型的设计,提出了更强大的双流GCA-LSTM网络。
•提议的端到端网络在评估基准数据集上产生最先进的性能。这项工作是我们的初步会议文件[31]的扩展。在此基础上,我们进一步提出了一种逐步训练方案,以提高网络的训练效率。此外,我们扩展了GCA-LSTM模型,并利用细粒度注意和粗粒度注意进一步提出了双流GCA-LSTM。此外,我们在更多的基准数据集上对我们的方法进行了广泛的评价。文中还提供了对所提方法的更多实证分析。
本文的其余部分组织如下。节
第二,回顾了基于骨架的动作识别的相关研究。在第三节中,我们介绍了所提出的GCALSTM网络。在第四部分,我们介绍了两流注意框架。文中给出了实验结果
最后,我们在第六节中对全文进行总结。
2相关工作
在本节中,我们首先简要回顾了基于骨架的动作识别方法,主要集中在提取手工特征。然后介绍了基于RNN和LSTM的方法。最后,我们回顾了近年来关于注意机制的研究。
.基于骨架的动作识别与手工制作的特征
在过去的几年里,针对基于骨架的动作识别提出了不同的特征提取器和分类器学习方法[32],[33],[34],[35],[36],[37],[38],[39],
[40][41][42][44]。
Chaudhry等人[45]提出将骨架序列编码为时空层次模型,然后使用线性动力系统(LDSs)学习动态结构。Vemulapalli等人[46]将每个操作表示为
然后利用支持向量机(SVM)对动作进行分类。Xia等人[47]提出用隐马尔可夫模型(HMMs)来建模动作序列的时间动力学。Wang等人[48],[49]引入了一个actionlet集合表示来对动作建模,同时捕获类内方差。Chen等[50]设计了一种基于零件的5D特征向量,用于探索骨骼序列中人体部位的相关关节。Koniusz等人[51]引入了张量表示来捕捉体关节之间的高阶关系。设计了一种基于零件的5D特征向量,用于挖掘骨骼序列中人体部位的相关关节。Koniusz等人[51]引入了张量表示来捕捉体关节之间的高阶关系。Wang等人[52]提出了一种基于图形的运动表示,并结合sppg -kernel SVM进行基于骨架的活动识别。Zanfir等[53]开发了一种用于低延迟动作识别的移动位姿框架和改进的k-NN分类器。
基于骨架的动作识别的RNN和LSTM
模型最近,基于深度学习,特别是递归神经网络(RNN)的方法在基于骨架的动作识别中显示出了它们的优势。我们所提出的GCA-LSTM网络是基于RNN的扩展LSTM模型。在本部分中,我们将回顾以下基于RNN和LSTM的方法,因为它们与我们的方法相关。
Du等[12]引入了一种层次RNN模型来表示人体结构和关节的时间动态。Veeriah等[54]提出了一种差分门控方案,使LSTM网络更加注重信息的变化。Zhu等人[28]对LSTM网络提出了一种混合范数正则化方法,以推动模型学习骨骼关节的共现特征。他们还设计了一个深入的退出机制来有效地训练这个网络。Shahroudy等人[55]引入了部分感知的LSTM模型,Du等[12]引入了一种层次RNN模型来表示人体结构和关节的时间动态。Veeriah等[54]提出了一种差分门控方案,使LSTM网络更加注重信息的变化。Zhu等人[28]对LSTM网络提出了一种混合范数正则化方法,以推动模型学习骨骼关节的共现特征。他们还设计了一个深入的退出机制来有效地训练这个网络。Shahroudy等人[55]引入了部分感知的LSTM模型,不同于上述基于RNN / LSTM方法,不显式地考虑每个骨骼关节的信息量与关于全球行动序列,我们提议GCA-LSTM网络利用全局上下文信息来执行注意所有的进化步骤LSTM选择性地强调信息在每一帧的关节,从而生成一个关注表示序列,可用于提高分类性能。在此基础上,提出了一种循环注意机制来迭代优化注意力。
注意机制
我们的方法也与注意机制有关
[14],[16],[59],[60],[61],[62],[63]这使得网络有选择地聚焦于特定的信息。Luong等人[62]提出了一种具有注意机制的神经机器翻译网络。Stollenga等人[64]设计了一种用于图像分类的深度注意选择网络。Xu等[15]提出在图像标题生成中结合硬注意和软注意。Yao等人[65]引入了一种用于视频字幕生成的时间注意力模型虽然已有的文献[66]、[67]提出了一系列基于深度学习的视频分析模型,但大多未考虑注意机制。有几部作品探讨了注意事项,如在[60],[68],[69]。但是,我们的方法与他们的方法有以下几个明显的不同:这些作品使用LSTM的前一个时间步长的隐藏状态来测量下一个时间步的注意分数,而LSTM的上下文信息是非常局部的。对于全局分类问题——行动识别,得到全局信息获得可靠的关注。因此,我们为LSTM提出了一个全局上下文记忆单元,用来衡量每一步输入的信息量。然后,在LSTM单元内将信息性评分作为一个门(信息性门,类似于输入门和遗忘门)来调整每一步输入数据的贡献,用于更新记忆单元。据我们所知,我们是第一个为LSTM网络引入全局存储单元来处理全局分类问题的。此外,还提出了一种反复注意机制网络来处理全局分类问题。此外,我们提出了一种反复注意机制来迭代地提升我们的网络的注意能力,而[60],[68],[69]中的方法只执行一次注意。此外,还介绍了一个包含细粒度注意和粗粒度注意的双流注意框架。由于这些新的贡献,我们提出的网络在评估的基准数据集上产生了最先进的性能。
GCA-LSTM网络
在本节中,我们首先简要回顾作为基础网络的2D时空LSTM (ST-LSTM)。然后介绍了我们提出的全局上下文感知注意力LSTM
(GCA-LSTM)网络,该网络能够利用全局上下文信息,有选择地聚焦于骨架序列中每一帧的信息关节。最后,我们描述了有效训练我们的网络的方法时空LSTM在基于骨架的人体动作识别问题中,给出了每一帧人体主要关节的三维坐标。同一框架内不同关节的空间依赖性和不同框架间相同关节的时间依赖性都是基于骨架的动作分析的重要线索。最近,Liu et al.[29]提出了a
二维ST-LSTM网络用于基于骨架的动作识别,能够对动作的依赖结构和依赖关系进行建模
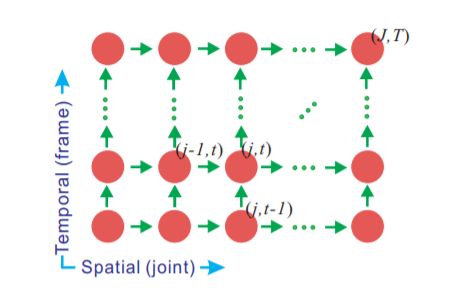
图2:ST-LSTM网络[29]示意图。在空间方向上,每个框架中的身体关节被布置成链条,并以序列的方式馈入网络。在时间维度上,身体关节被输入到框架上。
同时在空间和时间域的上下文信息。如图2所示,在ST-LSTM模型中,将框架中的骨骼关节排列成链条(空间方向),并将不同框架上对应的关节按顺序(时间方向)进行喂食。具体地说,每个ST-LSTM单元都有一个新的输入(xj,t,关节j在坐标系t中的三维位置),同一关节在前一时间步的隐藏表示(hj,t−1),以及前一事物的隐藏表示节点在同一坐标系内(hj−1,t),其中j∈{1,…, J}, t∈{1,…, T}分别为节点和框架的指标。ST-LSTM单元有一个输入门(ij,t),两个遗忘门对应于两个上下文信息源(f(T) j, T为时间维度,f(S) j,t为空间域),连同输出门(oj,t)。ST-LSTM的转移方程如[29]所示:
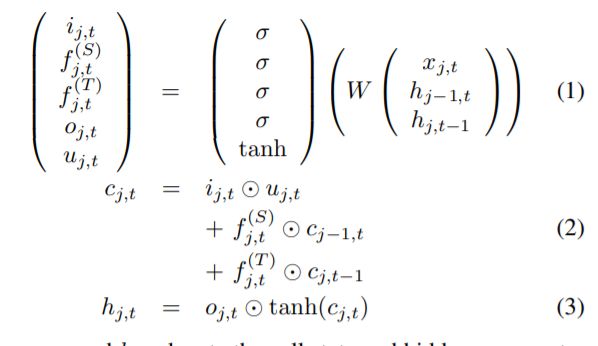
其中cj,t, hj,t分别表示单元在时空步长(j, t)处的状态和隐藏表示,uj,t为调制输入表示各元素间的乘积,W是由模型参数组成的仿射变换。有关ST-LSTM机制的更多细节,请参阅[29]。
全局上下文感知注意力LSTM一些之前的工作[13],[50]已经表明,在每个动作序列中,通常有一个信息节点子集是重要的,因为它们对动作分析贡献更多,而其余的可能是不相关的(甚至是不相关的)

图3:我们的GCA-LSTM网络示意图。为了清楚起见,省略了一些箭头
吵闹)为这个行动。因此,为了获得较高的动作识别精度,我们需要识别含有信息的骨关节,更多地关注它们的特征,同时尽量忽略不相关的骨关节的特征,即。在这种情况下,有选择地将注意力集中在有信息的关节上对人类动作识别是有用的。人类的动作可以由骨骼关节的运动组合来表示。为了可靠地识别动作实例中的信息关节,我们可以对In进行评估对于全局动作序列,各框架中各关节的形式化评分。为了达到这个目的,我们需要首先获取全局上下文信息。但是,LSTM的每个演化步骤中的可用上下文是前一步的隐藏表示,与全局操作相比,它是相对局部的。为了减轻上述限制,我们建议为LSTM模型引入全局上下文内存单元
其中保存了动作序列的全局上下文信息,可以输入到LSTM的每一步来辅助注意过程,如图3所示。我们称之为新LSTM架构作为全局上下文感知注意LSTM(GCA-LSTM)。1) GCA-LSTM网络概述:我们在图3中演示了基于骨架动作识别的GCA-LSTM网络。我们的GCA-LSTM网络包括三个主要模块。全局上下文存储单元维护整个动作序列的总体表示。第一个ST-LSTM层编码骨架序列,并初始化全局上下文内存单元。第二层ST-LSTM在所有时空步骤的输入上执行注意,以生成动作序列的注意表示,然后使用它来细化全局上下文记忆。第一STLSTM层在时空步长(j, t)处的输入为坐标系t中关节j的三维坐标。第二层的输入是来自第一层的隐藏表示。在第一步(j, t)处表示隐藏的表示ST-LSTM层,而第三- a节定义的符号hj、t、cj、t、ij、t、oj、t仅用于表示第二层的组件。
2)初始化全局上下文存储单元格:我们的GCALSTM网络通过全局上下文信息来进行关注,因此我们需要首先获得一个初始的全局上下文存储单元格。一个可行的方案是利用第一层的输出来生成全局上下文表示。我们可以对隐藏表示求平均:

我们还可以将第一层的隐藏表示连接起来,并将它们馈给前馈神经网络,然后使用由此产生的激活,就像(0)。我们从经验上观察到这两种初始化方案的执行情况相似。3)在第二层ST-LSTM层进行关注:利用全局上下文信息,我们在第二层ST-LSTM中评估输入在每个时空步长的信息量。在第n次注意迭代中,我们的网络学习了一个信息量评分(r(n) j,t)为每个输入(hj,t)通过馈送输入本身,一起在第n次注意迭代中,我们的网络学习了一个信息量评分(r(n) j,t)为每个输入(hj,t)提供输入本身,以及全局上下文存储单元(如果(n−1))由之前对网络的注意迭代生成,如下:
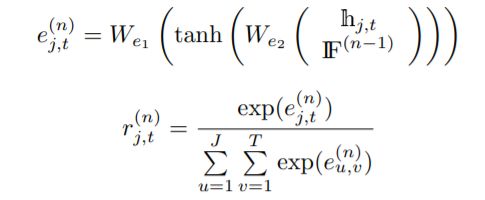
在r(n) j,t∈(0,1)表示第n次注意迭代中输入在第(j, t)步处的标准化信息量得分,对于全局上下文信息。信息性得分为r(n) j,t然后被用作一个门的ST-LSTM单元,我们叫它信息门。借助所学的信息门,可以更新第二ST-LSTM层单元的单元状态a
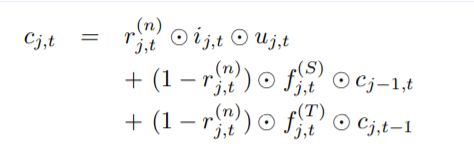
Eq.(7)中的单元格状态更新方案可以解释为:(1)对于全局上下文表示,如果输入(hj,t)具有信息性(重要),那么我们让学习算法更新第二个单元格的状态通过导入ST-LSTM层的更多信息;(2)相反,如果输入是无关的,那么在这一步我们需要阻塞输入门,同时更多的依赖cell状态的历史信息。4)精炼全局上下文记忆单元:我们采用Eq.(7)中的单元状态更新方案进行注意,从而得到动作序列的注意表示。具体地说,第二层中最后一个时空步长的输出作为注意表示(F(n))为行动。最后,注意表示F(n)被提供给全局上下文记忆单元来精炼它,如图3所示。具体细化如下:

其中IF(n)是IF(n−1)的改进版本。请注意,W(n)F在不同的迭代中不被共享。在GCA-LSTM网络中进行了多次注意迭代(经常性注意)。我们的动机是,在得到一个精炼的全局上下文记忆单元后,我们可以使用它来再次执行注意,以更可靠地识别信息节点,从而获得更好的注意表征,然后利用注意表征进一步精炼全局上下文。在多次迭代之后,全局上下文对于动作分类可以有更大的区别。
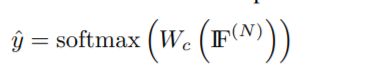
负对数似损失函数[70]采用测量的区别真正的类标签y, yˆ预测结果。采用反向传播算法来最小化损失函数。第III-C节描述了反向传播过程的细节。
培训网络
在这一部分中,我们首先简单描述了直接优化整个网络参数的基本训练方法,然后针对我们的GCA-LSTM网络提出了一种更先进的逐步训练方案。1)直接火车整个网络:由于分类是由使用最后精制全局上下文,训练这样一个网络,它是自然和直观的给action标签作为训练输出迭代,最后关注和逆向传播错误的最后一步,也就是说。,直接优化整个网络,如图所示。2)逐步训练:由于反复注意机制,我们的网络中不同模块(两个ST-LSTM层和全局上下文记忆单元,如图3所示)之间存在频繁的相互作用。此外,在多次注意迭代过程中,还引入了新的参数。因此,如上所述,很难直接对整个网络的所有参数和所有注意力迭代进行简单的优化。为此,我们提出了一种逐步训练方案GCA-LSTM网络,优化了模型参数所提出的逐步训练方案在优化参数和保证GCA-LSTM网络收敛方面是有效的。具体来说,在每个
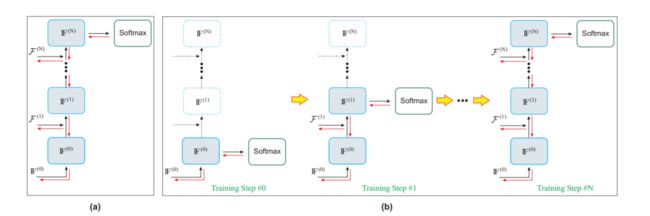
图4两种网络训练方法示意图(a)直接培训整个网络。(b)逐步优化网络参数。在该图中,全局上下文记忆单元IF(n)在注意迭代中展开。训练步骤#n对应第n次注意力迭代。黑色和红色箭头分别表示向前和向后通过。为了清晰起见,省略了一些通道,比如两个ST-LSTM层之间的通道。用彩色看效果更好。

训练第n步时,我们只需要优化从0到n的注意力迭代所使用的参数和模块的子集。2训练这个缩小的网络比直接训练整个网络更有效果和效率。在第n+ 1步,需要优化更大规模的网络。然而,第n + 1步的训练也是非常有效的,因为大多数参数和通过已经被它的前几个训练步骤优化(预先训练好的)。
二束GCA-LSTM网络
在上述设计(第三节)中,GCA-LSTM网络通过有选择地聚焦于每一帧的信息关节进行动作识别,即,注意是在关节级进行的(细粒度注意)。除了细粒度的注意之外,粗粒度的注意也有助于操作分析。这是因为有些动作通常是在身体部位水平进行的。对于这些动作,来自同一提供信息的身体部位的所有关节往往具有相似的重要程度。例如,所有joi的姿势和动作。
、身体部位是“右手”。这意味着粗粒度(身体部分级别)的注意对于动作识别也很有用。根据Du等人[12]的建议,人体骨骼根据人体的物理结构可以分为躯干、左手、右手、左腿和右腿五个身体部位。这五个部分如图5的右侧所示。因此,我们可以测量身体各个部位对于动作序列的信息量,然后进行粗粒度注意。具体地说,我们扩展了我们的GCA-LSTM模型的设计,引入了一个双流的GCA-LSTM网络,它联合利用了细粒度(联合级)的注意流和粗粒度(身体部分级)的注意流。双流GCA-LSTM的体系结构如图5所示。在每个注意流中,都有一个全局上下文记忆单元来维护动作序列的全局注意表示,还有第二个STLSTM层来执行注意。这表明在整个体系结构中有两个分离的全局上下文内存单元分别为细粒度注意存储单元(IF(n))(F))和粗粒度的注意记忆单元(IF(n),(C))。第一层ST-LSTM用于编码骨架序列和初始化全局上下文记忆单元,由两个注意流共享。细粒度注意流中的流程流(包括初始化、注意和细化)与第三节中介绍的GCA-LSTM模型相同。粗粒度注意流中的操作也类似。主要区别是,具体地说,在注意迭代n中,网络学习了一个信息性得分(r)(n)P,t)对于每个车身部件P (P∈{1, 2, 3, 4, 5})
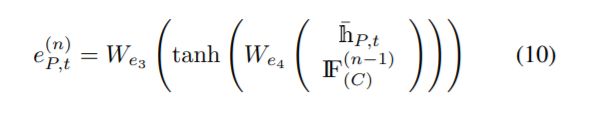
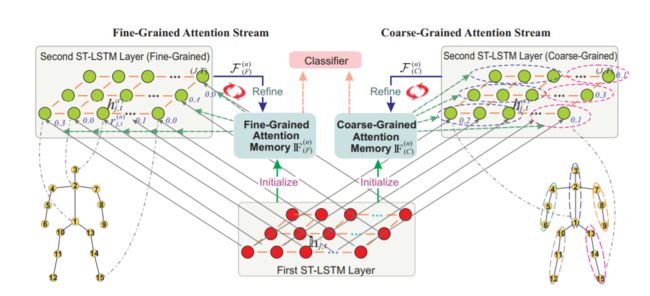
图5:双流GCA-LSTM网络的图示,该网络包含了细粒度(联合级)注意和粗粒度(身体部分级)注意。为了进行粗粒度注意,将骨骼中的关节划分为5个身体部位,来自同一身体部位的所有关节具有相同的信息性分数。在用于粗粒度注意的第二层ST-LSTM层中,我们在每一帧中只显示两个主体部分,为了清晰起见,省略了其他主体部分
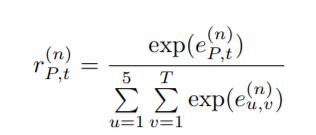
在h¯P,t是在t帧处体部分P的表示,根据所有属于P的关节的隐藏表示计算,平均pooling为:
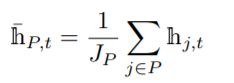
式中JP为身体部分P的关节数。为了进行粗粒度注意,我们让身体部分P中的每个关节j共享P的信息量,即。,在坐标系t, P中所有关节的信息量都相同,得分为r(n)P,t,如图5所示。因此,在粗粒度的注意流中,如果j∈P,则为第2个单元格状态ST-LSTM层在时空步长(j, t)处更新为:
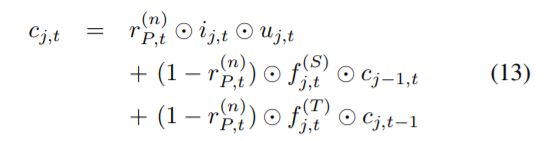
在双流GCA-LSTM网络中也进行了多次注意迭代。最后,精细细粒度注意记忆如果(N)(F)和粗粒度注意记忆如果(N)(C)均送入softmax分类器,取这两个流的预测分数的平均值进行动作识别。
所提出的步进训练方案同样适用于双流GCA-LSTM网络,在训练第n步,我们同时优化了两个注意力流,这两个注意力流都对应于第n次注意力迭代。
实验
我们在NTU RGB+D[55]上评估我们提出的方法,SYSU-3D [71], UT-Kinect [47], SBU-Kinect Interaction [72]和Berkeley MHAD[73]数据集。为了调查我们的方法的有效性,我们对以下不同的网络结构进行了广泛的实验:
" ST-LSTM +全局变量(1)"。这种网络结构类似于原来的两层ST-LSTM网络[29],但隐藏的表现时空的步骤的第二层连接和美联储单层前馈网络骨架的生成一个全球表示序列,并进行分类对全球表示;而在[29]中,分类是在每个时空步长上对单个隐藏表示(局部表示)进行的。" ST-LSTM + Global(2) "。这种网络结构类似于上面的ST-LSTM +全局(1),只是全局表示是通过对所有时空步长的隐藏表示进行平均得到的。
•“GCA-LSTM”。这就是提出的全局上下文关注LSTM网络。该网络进行了两次注意力迭代。分类是在最后一个精炼的全局上下文存储单元上执行的。在第三- c节中描述的两种训练方法(直接训练和逐步训练)也对这个网络结构进行了评估。
此外,我们还采用大规模的NTU RGB+D和具有挑战性的SYSU-3D作为两个主要的基准数据集来评估提出的“双流GCA-LSTM”网络。
我们使用Torch7框架[74]进行实验。采用随机梯度下降(SGD)算法训练端到端网络。我们将学习速率、衰减速率和动量设置为1.5×10−3,分别为0.95和0.9。在我们的网络中应用的退出概率[75]被设置为0.5。ST-LSTM的全局上下文内存表示和单元状态的维度都是128。
在NTU RGB+D数据集上的实验使用Kinect采集NTU RGB+D数据集[55](V2)。它包含了超过56000个视频样本。总共有60个动作班由40个不同的受试者表演。据我们所知,这是基于RGB+D的人类动作识别的最大的公开可用数据集。主题和视点的巨大变化使这个数据集非常具有挑战性。该数据集有两种标准的评估方案:(1)Cross subject (CS):20名受试者用于培训,其余受试者用于测试;(我们将提出的GCA-LSTM网络与最新的方法进行比较,如表i所示。我们可以看到,我们提出的GCA-LSTM模型优于其他基于骨架的方法。具体来说,我们的GCA-LSTM网络在[29]中比原来的ST-LSTM网络性能好了1倍交叉研究方法为6.9%,交叉研究方法为6.3%。这说明我们的网络中的注意机制带来了显著的性能改进。“ST-LSTM + Global(1)”和“ST-LSTM + Global”(2)“对全局表示进行分类,这样它们会得到轻微的效果表I中的结果也表明,与直接训练方法相比,使用逐步训练方法可以提高我们的网络的性能。

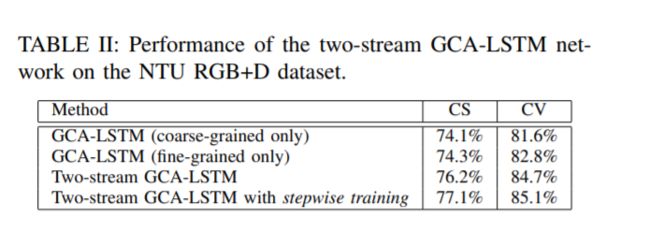
我们也评估了两流GCALSTM网络的性能,并在表II中报告了结果。结果表明,在加入细粒度注意和粗粒度注意的情况下,双流GCA-LSTM网络的性能优于仅加入细粒度注意的GCA-LSTM网络。我们还观察到,采用逐步训练的方法可以提高双流GCA-LSTM的性能。
在SYSU-3D数据集上的实验使用Kinect采集SYSU-3D数据集[71],其中包含480个骨骼序列。这个数据集包括
12节动作课,由40名受试者完成。的SYSU-3D数据集具有很大的挑战性,因为不同的动作类之间的运动模式非常相似,并且在这个数据集中有很多视点变化。我们对该数据集遵循[71]中标准的交叉验证协议,其中20名受试者用于训练网络,其余受试者保留用于测试。我们报告了实验结果