Python 字符串与十进制的转换
写在前面
我真是要气死了!每次都记不住python字符串和十进制之间的转换!每次用到还要各种查资料问别人,结果都要花好久的时间……这种情况不下3次!!这次一定要记下来!
python2.7
字符串转为十进制:首先要将字符串转为16进制,再转为十进制
十进制转为字符串:首先要将十进制转为16进制,再转为字符串
import binascii
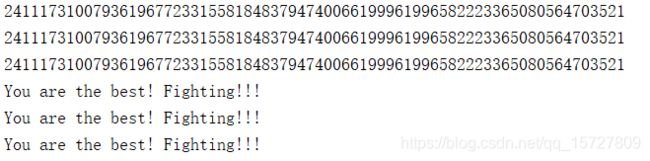
string = 'You are the best! Fighting!!!'
string_int1 = int(binascii.hexlify(string),16)
string_int2 = int(binascii.b2a_hex(string),16)
string_int3 = int(string.encode('hex'),16)
print string_int1
print string_int2
print string_int3
int_string1 = binascii.unhexlify(hex(string_int1)[2:-1])
int_string2 = binascii.a2b_hex(hex(string_int1)[2:-1])
int_string3 = hex(string_int1)[2:-1].decode('hex')
print int_string1
print int_string2
print int_string3
结果:
官方解释:

binascii.b2a_hex(data)意思是将二进制流data转为十六进制,data的每一个比特都被转为对应十六进制的2位,因此返回结果是data长度的二倍。
binascii.b2a_hex(data)意思是将十六进制串转为二进制流data,其中十六进制串长度必须是偶数,否则返回类型错误。
备注:Python2环境下,字符串默认存储是二进制流,即str=bytes,因此可以这样转换。Python3二者有区分,因此需要将str转为bytes
Python3.6
# -*-coding:utf-8-*-
import binascii
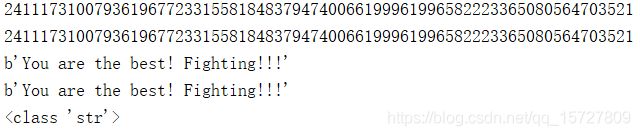
string = 'You are the best! Fighting!!!'
# 先将str转为bytes,3种方法
string1= b'You are the best! Fighting!!!'
string2 = bytes(string,encoding='utf-8')
string3 = string.encode('utf-8')
string_int1 = int(binascii.hexlify(string1),16)
string_int2 = int(binascii.b2a_hex(string2),16)
print (string_int1)
print (string_int2)
# LookupError: 'hex' is not a text encoding; use codecs.encode() to handle arbitrary codecs
# 意思是字符串的没有'hex'编码形式,因此错误
#print (string.encode('hex'))
#string_int3 = int(string.encode('hex'),16)
int_string1 = binascii.unhexlify(hex(string_int1)[2:])
int_string2 = binascii.a2b_hex(hex(string_int1)[2:])
print (int_string1)
print (int_string2)
a = hex(string_int1)
print (type(a)) # 由于str没有decode属性,因此下面这个方法不能用
#int_string3 = hex(string_int1)[2:-1].decode('hex')
结果:
参考:Python3环境下 str与bytes详解
https://blog.csdn.net/lyb3b3b/article/details/74993327
第一种方法:
使用str.encode()和bytes.decode()
(1)str转为bytes:

即某种编码方式的字符串转为bytes类型,这里的编码可以指
>>> s = 'helloworld'
>>> type(s)
<class 'str'>
>>> s.encode('utf-8')
b'helloworld'
>>> s.encode('ascii')
b'helloworld'
>>> a = '中文'
>>> a.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> a.encode('gbk')
b'\xd6\xd0\xce\xc4'
>>> a.encode('gb2312')
b'\xd6\xd0\xce\xc4'
>>> a.encode('big5')
b'\xa4\xa4\xa4\xe5'
>>>
(2)bytes转为str:
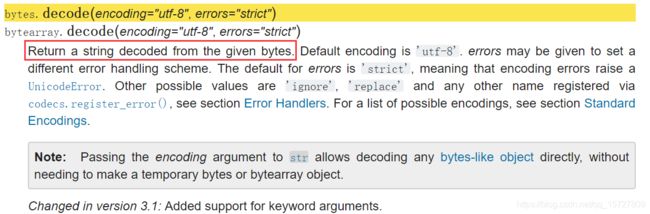
即bytes类型以转化为某种编码方式的字符串,与str.encode()相反即可
>>> b2s = b.decode('utf-8')
>>> type(b2s)
<class 'str'>
>>> b2s
'hello world'
>>>
第二种方法:
使用内置函数bytes()和str()
(1)str转为bytes
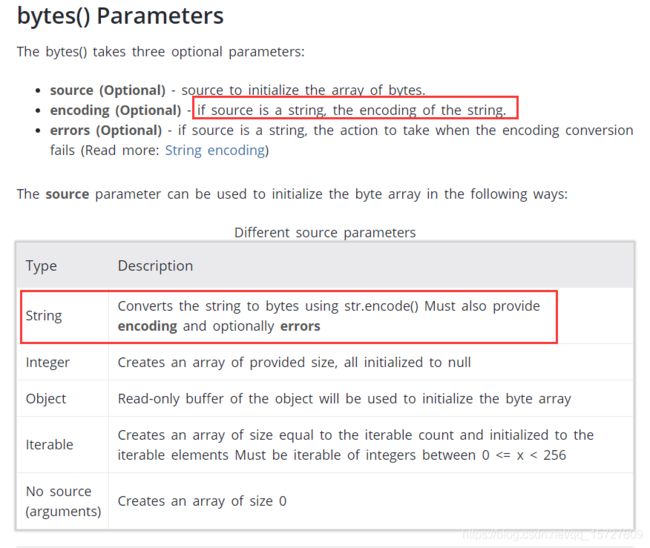
也就是说使用bytes()时必须指定字符串的编码方式,不然会报错
>>> a = '中文'
>>> type(a)
<class 'str'>
>>> bytes(a,encoding='utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> bytes(a,encoding='gbk')
b'\xd6\xd0\xce\xc4'
>>> bytes(a)
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: string argument without an encoding
>>>
(2)bytes转为str
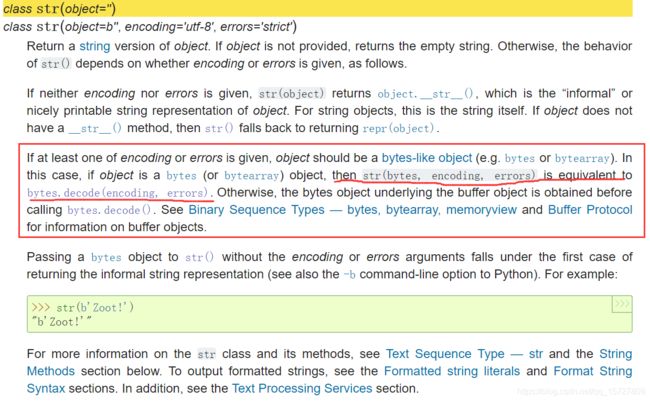
也就是说str()也要指定编码形式,这样就相当于bytes.decode(),将某种编码的字符串转为bytes类型。否则返回的是一个str对象
>>> b = bytes(a,encoding='utf-8')
>>> b
b'\xe4\xb8\xad\xe6\x96\x87'
>>> str(b)
"b'\\xe4\\xb8\\xad\\xe6\\x96\\x87'"
>>> type(str(b))
<class 'str'>
>>> str(b,encoding='utf-8')
'中文'
>>>