论文笔记-NIMA-Neural Image Assessment, IEEE Transactions on Image Processing 2018
论文笔记-NIMA-Neural Image Assessment, IEEE Transactions on Image Processing 2018
- 摘要
- I.Introduction
- A.相关成果
- B.我们的贡献
- C.一个大规模的审美视觉分析数据库(AVA)[ava图片来自www.dpchallenge.com,这是一个业余摄影师在线社区。]
- D.坦佩雷图像数据库2013(tid2013)
- E.LIVE In the Wild Image Quality Challenge Database [26]
- II. 提出的方法
- A.损失函数
- III. 实验结果
- A.性能比较
- B.交叉数据集评估
- C.图片排序
- D.图片增强
- E.计算代价
- IV. 结论
论文引用:
Talebi H , Milanfar P . NIMA: Neural Image Assessment[J]. IEEE Transactions on Image Processing, 2017, PP(99):1-1.
论文代码:
摘要
自动学习图像质量近来成为一个热门话题。因为它有很广泛的应用;比如评估图像采集管道,存储技术和共享媒体。
尽管这一问题具有主观性,但大多数现有的方法只能预测AVA和TID2013等数据集提供的平均意见得分。
我们的方法不同于其他方法,因为我们使用卷积神经网络预测人类观点分数的分布。
我们的体系结构还具有显著的优势,比其他具有类似性能的方法简单。
我们提出的方法依赖于成熟的、最先进的深目标识别网络的成功(和再训练)。
我们的网络不仅可以可靠地对图像进行评分,而且与人类感知有很高的相关性,还可以帮助调整和优化摄影管线中的照片编辑/增强算法。
所有这些都是在不需要一个“黄金”参考图像的情况下完成的,因此允许单个图像、语义和感知感知,无参考质量评估。
I.Introduction
量化图像质量和美学评估已经是在图像处理和计算机视觉领域里一个长期存在的问题。
虽然技术质量评估涉及测量低层次的退化,如噪声、模糊、压缩伪影等,但美学评估量化了与图像中的情感和美相关的语义层次特征。
一般来说,图像质量评价可以分为完全参考和无参考两种。
虽然前者假设参考图像的可用性(如psnr、ssim[3]等指标),但通常情况下,盲(无参考)方法依靠失真的统计模型来预测图像质量。
这两个类别的主要目标都是预测一个与人类感知密切相关的质量分数。
然而,图像质量的主观本质仍然是根本问题。
最近,更复杂的模型,如深卷积神经网络(CNN)被用来解决这个问题[4]–[11]
人类评级中标记数据的出现鼓励了这些努力[1]、[2]、[12]–[14]
在典型的深度CNN方法中,通过对分类相关数据集(如ImageNet[15])的训练来初始化权重,然后针对感知质量评估任务对注释数据进行微调。
A.相关成果
机器学习已经在预测图像质量技术中表现出可观的成功。Kang et. al. 证明了:用卷积神经网络CNNs提取高等级特征能够得到前沿的盲质量评估性能。
它表明用端到端学习系统代替手工提取的特征是利用CNNs进行像素级别的质量评估任务的主要优势。
[5] :提出的方法是用小网络,这个网络由一个卷积层,两个全连接层和大小为32X32输入图像块组成。
[6] :Bosse等人使用12层的深度CNN来提高[5]的图像质量预测。
考虑到较小的输入大小(32×32补丁),两种方法都需要对整个图像进行分数聚合。
[7] :Bianco等人提出了一个基于==Alexnet[15]==的深度质量预测器
从227×227大小的图像作物中提取多个CNN特征,并回归到人类评分中。
CNN在物体识别任务中的成功应用,对美学评价的研究具有重要意义。
这似乎很自然,因为语义水平的质量与图像内容直接相关。
[1] :Murray等人是审美评价的基准。
他们介绍了AVA数据集,并提出了一种使用手动设计的特性进行样式分类的技术。
[8],[17] :表明深度CNN非常适合美学评估任务。
[17] :他们的双列CNN由四个卷积层和两个完全连接的层组成,其输入是尺寸为224×224的调整图像和裁剪窗口
这些全局和本地图像视图的预测通过完全连接的层聚合到总体分数。
与在[1]中一样,在[17]中图像还根据平均人类等级分为低美学和高美学。
[9] :使用回归损失和Alexnet启发的架构来预测平均分数。
[11] :Jin等人微调==VGG网络[18]==以了解AVA数据集的人工评分。他们使用回归框架来预测评级的柱状图。
[19] :Zeng等人的最新方法,对Alexnet和Resnet CNN进行再训练,以预测照片质量。
[10] :使用了一个自适应空间池,允许向CNN提供具有固定大小纵横比的多个输入图像比例。
本文提出了一种多网络(每个网络都是经过预先训练的VGG)方法,该方法可以在多个尺度上提取特征,并使用场景感知聚合层来组合子网络的预测。
[20] :Ma等人提出一个布局感知框架,其中使用显著性图来选择对预测美学得分影响最大的补丁。
总的来说,这些方法都没有报告它们的预测与真实等级的相关性。
[14] :最近,Kong等人提出了一种通过对ava进行基于排序的loss函数训练来对照片进行美学排序的方法,他们训练了一个基于AlexnetCNN的CNN,从两个输入图像中了解审美得分的差异,从而间接优化了等级相关性。据我们所知,[14]是针对AVA评级进行相关性评估的唯一工作。
| 序号 | 论文引用 |
|---|---|
| 5 | L. Kang, P. Ye, Y. Li, and D. Doermann, “Convolutional neural net-works for no-reference image quality assessment,” in Proc. IEEE Conf.Comput. Vis. Pattern Recognit., Jun. 2014, pp. 1733–1740. |
| 6 | S. Bosse, D. Maniry, T. Wiegand, and W. Samek, “A deep neural network for image quality assessment,” in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2016, pp. 3773–3777. |
| 7 | S. Bianco, L. Celona, P. Napoletano, and R. Schettini. (2016). “On the use of deep learning for blind image quality assessment.” [Online]. Available: https://arxiv.org/abs/1602.05531 |
| 1 | N. Murray, L. Marchesotti, and F. Perronnin, “AVA: A large-scale database for aesthetic visual analysis,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2012, pp. 2408–2415. |
| 8 | X. Lu, Z. Lin, X. Shen, R. Mech, and J. Z. Wang, “Deep multi-patch aggregation network for image style, aesthetics, and quality estimation,”in Proc. IEEE Int. Conf. Comput. Vis., Jun. 2015, pp. 990–998. |
| 17 | X. Lu, Z. L. Lin, H. Jin, J. Yang, and J. Z. Wang, “Rating image aesthetics using deep learning,” IEEE Trans. Multimedia, vol. 17, no. 11, pp. 2021–2034, Nov. 2015. |
| 9 | Y. Kao, C. Wang, and K. Huang, “Visual aesthetic quality assess-ment with a regression model,” in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2015, pp. 1583–1587. |
| 11 | B. Jin, M. V. O. Segovia, and S. Süsstrunk, “Image aesthetic pre-dictors based on weighted CNNs,” in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2016, pp. 2291–2295. |
| 19 | H. Zeng, L. Zhang, and A. C. Bovik. (2017). “A probabilistic quality rep-resentation approach to deep blind image quality prediction.” [Online].Available: https://arxiv.org/abs/1708.08190 |
| 10 | L. Mai, H. Jin, and F. Liu, “Composition-preserving deep photo aesthet-ics assessment,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2016, pp. 497–506. |
| 20 | S. Ma, J. Liu, and C. W. Chen, “A-lamp: Adaptive layout-aware multi-patch deep convolutional neural network for photo aesthetic assessment,”in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017,pp. 722–731. |
| 14 | S. Kong, X. Shen, Z. Lin, R. Mech, and C. Fowlkes, “Photo aesthetics ranking network with attributes and content adaptation,” in Proc. Eur. Conf. Comput. Vis., 2016, pp. 662–679. |
B.我们的贡献
在这项工作中,我们引入了一种新颖的方法来预测图像的技术和美学质量。我们展示了具有相同CNN架构的模型,在不同的数据集上进行训练,这两个任务的性能都达到了最先进水平。
由于我们的目标是预测与人类评分的相关性更高,而不是将图像分类为低/高分或回归到平均分,因此评分的分布被预测为一个柱状图。
为此,我们使用了[21] 中提出的平方EMD(地球移动器距离)损失,它显示了按顺序分类的性能提升。我们的实验表明,这种方法也能更准确地预测平均分。
此外,如美学评价案例[1]所示,图像的非常规性与评分标准偏差直接相关。我们提出的范例也允许预测这个指标。
最近的研究表明,感知质量预测器可以作为学习损失来训练图像增强模型[22],[23]。同样,图像质量预测器可用于调整增强技术的参数[24]。
在这项工作中,我们使用我们的质量评估技术来有效地调整图像去噪和色调增强操作的参数,以产生知觉上的优越结果。
本文首先回顾了三种广泛使用的质量评估数据集。然后,对所提出的方法进行了详细的说明。最后,对这项工作的绩效进行量化,并与现有的方法进行比较。
C.一个大规模的审美视觉分析数据库(AVA)[ava图片来自www.dpchallenge.com,这是一个业余摄影师在线社区。]
AVA数据集包含大约25.5万张图片,根据业余摄影师的审美素质进行评分。每张照片平均由200人对摄影比赛进行评分。每个图片都与一个单一的挑战主题相关,在AVA中有将近900个不同的比赛。图像等级从1到10,其中10是与图像相关的最高美学得分。AVA评级的柱状图如图1所示。

可以看出,平均等级主要集中在总平均分数( ≈ 5.5 \approx 5.5 ≈5.5)周围。
此外,AVA数据集中大约一半照片的评级标准偏差大于1.4。正如在[1]中指出的,可能具有高分方差的图像倾向于解释,而具有低分方差的图像似乎代表传统风格或主题。图2显示了一些与不同审美质量和非传统性水平相关的评级示例。

一张照片的审美品质似乎可以用平均分来表示,它的非规约性与分数的偏差密切相关
考虑到AVA分数的分布,通常情况下,在AVA数据上训练一个模型会导致在总体平均值(5.5)附近有小偏差的预测。
值得一提的是,图1中的联合柱状图显示了非常低/高评级的较高偏差(与总体平均值5.5和平均标准偏差1.43相比)。换言之,在具有极端审美品质的AVA图像中,意见分歧更为一致。如[1]所述,平均值在2到8之间的评级分布可以用高斯函数近似,高度倾斜的评级可以用gamma分布建模。
D.坦佩雷图像数据库2013(tid2013)
tid2013是为评估全参考感性图像质量而策划的。它包含3000个图像,来自25个参考(清晰)图像(柯达图像[25]),24种类型的失真,每种失真有5个级别。这会导致每个参考图像产生120个失真图像;包括不同类型的失真,如压缩伪影、噪声、模糊和颜色伪影。
人类对tid2013图像的评级是通过一个强制选择实验收集的,在这个实验中,观察者在两个扭曲的选择之间选择一个更好的图像。实验的设置允许评分者在做决定时查看参考图像。在每一个实验中,每一个失真的图像被用于9个随机的成对比较。所选图像得到一个点,其他图像得到零点。在实验结束时,将这些点的总和用作与图像相关的质量分数(这将导致分数范围从0到9)。为了获得总的平均分,共进行了985次实验。
tid2013额定值的平均值和标准偏差如图3所示。
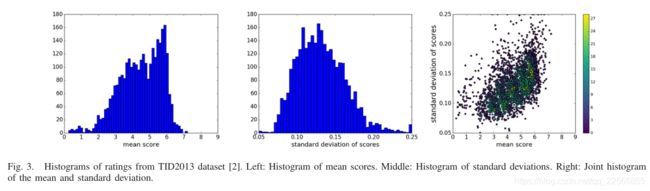
如图3(c)所示,平均值和得分偏差值之间的相关性较弱。图4和图5显示了一些tid2013的图像。所有五个级别的jpeg压缩伪影和相应的分级显示在图4中。

显然,较高的失真水平导致较低的平均分数。对比度压缩/拉伸变形对人体分级的影响如图5所示。有趣的是,对比度的拉伸(图5(c)和图5(e))导致相对较高的感知质量。

E.LIVE In the Wild Image Quality Challenge Database [26]
LIVE数据集包含由移动设备捕获的1162张照片。每幅图片的平均评分是175个独特的主题。活载额定值的平均值和标准偏差如图6所示。

在联合直方图中可以看到,评分接近总体平均分的图像显示较高的标准偏差。图7显示了一些来自实时数据集的图像。

值得注意的是,在本文中,实况分数被缩放到[1,10]。
不同于AVA它包括每个图像的评级分布,TID2013和Live只提供意见得分的平均值和标准偏差。由于我们提出的方法需要对分数概率进行训练,因此通过最大熵优化来近似分数分布[27]。
论文的其余部分组织如下。在第二节中,详细说明了所提出的方法。接下来,在第三节中,我们的算法在照片排序和图像增强中的应用举例说明。我们还提供了我们的实施细节。最后,本文将在第四部分进行总结。
II. 提出的方法
涉及到的网络结构
| 序号 | 网络名称 | 论文引用 |
|---|---|---|
| 18 | VGG16 | K. Simonyan and A. Zisserman. (2014). “Very deep convolutional networks for large-scale image recognition.” [Online]. Available: https://arxiv.org/abs/1409.1556 |
| 28 | Inception-v2 | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proc. IEEE Conf.Comput. Vis. Pattern Recognit., Jun. 2016, pp. 2818–2826. |
| 29 | MobileNet | A. G. Howard et al., (2017). “MobileNets: Efficient convolutional neural networks for mobile vision applications.” [Online]. Available:https://arxiv.org/abs/1704.04861 |
我们提出的质量预测,美学预测基于图像分类器架构。
更明确地说,我们为图像质量评估任务探索
我们将探索几种不同的分类器体系结构,比如VGG16[18],Inception-v2[28],MobileNet[29]。
VGG16由13个卷积层和3个全连接层组成。深VGG16结构中使用了3×3大小的小卷积滤波器[18]。
inception-v2[28]基于inception模块[30],该模块允许并行使用卷积和池操作。
此外,在Inception体系结构中,传统的完全连接层被平均池所取代,这导致了参数数量的显著减少。
Mobilenet[29]是一个高效的深度CNN,主要设计用于移动视觉应用。在这种结构中,密集卷积滤波器被可分离滤波器所取代。这种简化导致CNN模型更小、更快。
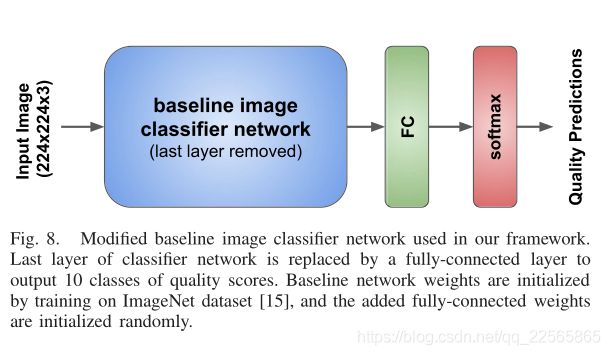
我们将基线CNN的最后一层替换为10个神经元的完全连接层,然后进行soft-max激活(如图8所示)。

基线CNN权重通过在ImageNet数据集[15]上的培训初始化,然后进行质量评估的端到端培训。本文讨论了该模型在不同基线CNN下的性能。
在训练中,将输入图像重新调整为256×256,然后随机抽取一个尺寸为224×224的裁剪。这降低了过度拟合问题的可能性,尤其是在相对较小的数据集(如tid2013)上进行训练时。值得注意的是,我们也尝试了通过随机裁剪而不重新调整来训练。然而,结果并不令人信服。这是由于图像构成中不可避免的变化。我们训练过程中的另一个随机数据增强是图像裁剪中的水平翻转。
我们的目的是对一个给定图片进行等级分布的预测。
一个给定的图片,它的人类等级的真实值分布可以被表达为一个经验概率质量函数
p = [ p s 1 … … p s N ] ( s 1 ≤ s i ≤ s N p=[{p_{s1}……p_{sN}}](s_1 \leq s_i \leq s_N p=[ps1……psN](s1≤si≤sN),
式中的 s i s_i si表示第i个分数区间,N表示分数区间的总数量。
在AVA和TID2013数据集中,N=10,在AVA中 s 1 = 1 , s N = 10 s_1=1,s_N=10 s1=1,sN=10, 在TID2013中, s 1 = 0 , s N = 9 s_1=0,s_N=9 s1=0,sN=9.
由于 ∑ i = 1 N p s i = 1 \sum_{i=1}^{N} p_{s_i}=1 ∑i=1Npsi=1, p s i p_{s_i} psi代表一个质量分数落在第i个分数区间中的概率。将等级的分布记作p,平均质量分数被定义为
μ = ∑ i = 1 N s i × p s i \mu =\sum_{i=1}^{N}s_i \times p_{s_i} μ=∑i=1Nsi×psi
分数的标准偏差被计算为
σ = ( ∑ i = 1 N ( s i − μ ) 2 × p s i ) 1 2 \sigma = (\sum_{i=1}^{N}(s_i-\mu)^2\times p_{s_i})^{\frac{1}{2}} σ=(∑i=1N(si−μ)2×psi)21
正如前面章节所讨论的,人们可以通过分数的平均值和标准差定性地比较图像。
数据集中的每个例子都由一幅图像及其真实值(用户)评级p组成。我们的目标是找到概率质量函数 p ^ \hat{p} p^,是对p的一个精确估计,接下来讨论了我们的训练损失函数。
A.损失函数
soft-max交叉熵在分类任务中被广泛用作训练损失函数。这个损失函数可以表示为:
∑ i = 1 N − p s i l o g ( p s i ^ ) \sum_{i=1}^{N}-p_{s_i}log(\hat{p_{s_i}}) ∑i=1N−psilog(psi^)
式中 p s i ^ \hat{p_{s_i}} psi^表示预估的第i个分数区间的概率,用于最大化正确标签的预测概率。然而,如果是有序类(比如美学和质量预估),交叉熵损失缺少分数区间之间的内部类关系。
有人可能会说,有序类可以用实数表示,因此可以通过回归框架来学习。
然而,研究表明,对于有序类,分类框架可以优于回归模型[21],[31]。
Hou等人[21]表明对具有类间内在排序的数据集的训练可以从基于EMD的损失中获益。这些损失函数根据类距离惩罚错误分类。
对于图像质量等级,类的固有等级顺序为 s 1 < … … < s N s_1<……<s_N s1<……<sN,类与类之间的第r范式距离定义为
∣ ∣ s i − s j ∣ ∣ r ||s_i-s_j||_r ∣∣si−sj∣∣r,其中 1 ≤ i , j ≤ N 1\leq i,j\leq N 1≤i,j≤N
EMD被定义为将一个分布的质量移动到另一个的最小代价。
给定真实值和预估概率质量函数 p 和 p ^ p和\hat{p} p和p^,和具有n个有序的距离类 ∣ ∣ s i − s j ∣ ∣ r ||s_i-s_j||_r ∣∣si−sj∣∣r,标准化的土方运距可以表示为:
E M D ( p , p ^ ) = ( 1 N ∑ k = 1 N ∣ C D F p ( k ) − C D F p ^ ( k ) ∣ ) 1 r EMD(p,\hat{p}) = (\frac{1}{N} \sum_{k=1}^{N} |CDF_p(k)-CDF_{\hat{p}}(k)| )^{\frac{1}{r}} EMD(p,p^)=(N1∑k=1N∣CDFp(k)−CDFp^(k)∣)r1
其中的 C D F p ( k ) CDF_p(k) CDFp(k)是累积分布函数 ∑ i = 1 k p s i \sum_{i=1}^{k}p_{s_i} ∑i=1kpsi.
值得注意的是,这种封闭形式的解要求两个分布具有相等的质量:
∑ i = 1 N p s i = ∑ i = 1 N p s i ^ \sum_{i=1}^{N} p_{s_i}= \sum_{i=1}^{N} \hat{p_{s_i}} ∑i=1Npsi=∑i=1Npsi^
正如图8所示,我们预测的质量概率被输入一个soft-max函数来保证 ∑ i = 1 N p s i ^ = 1 \sum_{i=1}^{N}\hat{p_{s_i}}=1 ∑i=1Npsi^=1
与[21]类似,在我们的训练框架中,r设置为2,以惩罚CDFs之间的欧几里得距离。r=2允许在使用梯度下降时进行更简单的优化。
III. 实验结果
我们针对AVA、TID2013和LIVE训练了两个独立的美学和技术质量评估模型。对于每一种情况,我们将每个数据集分解为训练集和测试集,其中20%的数据用于测试。在本节中,将讨论所提出的模型在测试集上的性能,并与现有的方法进行比较。然后,探讨了该技术在照片排序和图像增强中的应用。在继续之前,我们将解释我们的实现细节。
本文介绍的CNN是使用TensorFlow[33]、[34]实现的。基线cnn权重通过在imagenet上的训练来初始化[15],最后一个完全连接的层是随机初始化的。权重和偏差矩设置为0.9,在基线网络的最后一层应用0.75的dropout率。基线CNN层和最后一个完全连接层的学习率分别设置为 3 × 1 0 − 7 和 3 × 1 0 − 6 3×10^{-7}和3×10^{−6} 3×10−7和3×10−6。我们观察到,当使用随机梯度下降时,在基线CNN层上设置较低的学习率会导致更容易和更快的优化。此外,在每10个训练阶段之后,衰减系数为0.95的指数衰减应用于所有学习率。
A.性能比较
对AVA美学评价模型的正确性、相关性和EMD值呈现在表1中。

表一中的大多数方法都是为了对美学评分进行二元分类,因此只报告了两类质量分类的准确度评估。在这个二元分类中,预测平均分与5分作为分数线进行比较。
预测分数高于截止分数的图像被归类为高质量图像。在两类美学分类任务中,来自[20]和NIMA(Inception-V2)的结果显示出最高的准确性。此外,在等级相关性方面,NIMA(vgg16)和NIMA(inception-v2)表现出色[14]。NIMA要便宜得多:[20]在图像补丁上应用多个VGG16网络来生成一个质量分数,而NIMA(Inception-V2)的计算复杂性大约是Inception-V2的一个过程(见表五)。

我们对tid2013的技术质量评估模型与表二中的其他现有方法进行了比较。虽然这些方法中的大多数回归到平均意见得分,我们提出的技术预测评级的分布,以及平均意见得分。NIMA(vgg16)的真实值与结果之间的相关性接近于[35]和[7]中最先进的结果。值得强调的是,Bianco等人[7]向深度CNN输入多个裁剪的图像,而我们的方法仅采用重新缩放的图像。

AVA分数的预测分布如图9所示。我们使用NIMA(Inception-V2)模型来预测我们的AVA测试集的地面实况分数。如图所示,NIMA对基础真值均值的分布进行了严密的预测。然而,预测真实值标准偏差的分布是一项更具挑战性的任务。正如我们前面所讨论的,主题或风格的非常规性直接影响评分标准偏差。

B.交叉数据集评估
作为交叉验证测试,我们训练的模型的性能在其他数据集上进行测量。这些结果在表三和表四中给出。我们测试了在AVA、TID2013[2]和Live[26]上训练的NIMA(初始-V2)模型,所有三个测试集都进行了测试。可以看出,平均而言,对AVA数据集的训练显示出最佳的性能。
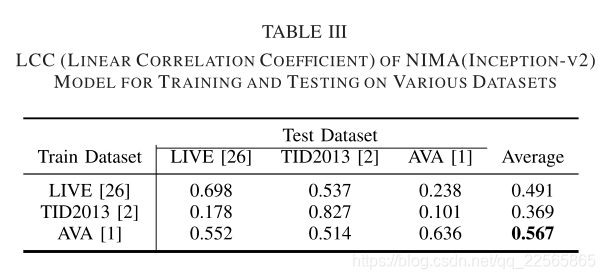

比如,在AVA上训练并在LIVE中测试,分别得到0.552和0.543的线性相关和等级相关。然而,在LIVE上训练,在AVA上进行测试会导致0.238和0.2线性和等级相关系数。我们相信这一观察结果表明,在AVA上训练的NIMA模型可以更有效地推广到其他测试示例,而在TID2013上训练会导致LIVE和AVA测试集的性能较差。值得一提的是,AVA数据集包含大约250倍以上的示例(与LIVE数据集相比),这使得训练NIMA模型时不存在任何明显的过度拟合。
C.图片排序
预测平均分可以用来对照片进行美学排序。一些来自AVA数据集的测试照片如图10和图11所示。
预测的NIMA分数和地面实况AVA分数显示在每个图像下面。图10中的结果表明,除了图像内容外,其他因素如色调、对比度和照片构图也是重要的美学特征。此外,如图11所示,除了图像语义之外,框架和调色板也是这些照片的关键品质。这些美学属性是由我们在AVA上训练的模型紧密预测的。

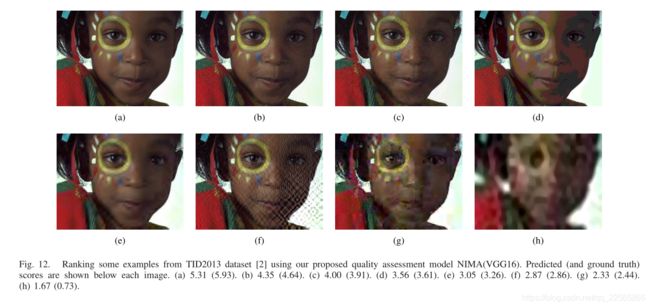
预测平均分用于定性地对图12中的照片进行排序。这些图像是我们的tid2013测试集的一部分,其中包含各种类型和级别的失真。对比地面真实性和预测分数表明,我们在tid2013上训练的模型能够准确地对测试图像进行排序。
D.图片增强
质量和美感评分可用于感知调整图像增强操作。
换言之,预先最大化NIMA分数可以增加增强一个图片感知质量的可能性。
通常,在不同的摄影条件下,通过大量的实验选择诸如图像去噪和对比度增强等增强操作参数。感知调谐可能非常昂贵和耗时,特别是当需要人类意见时。在本节中,我们提出的模型用于调整音调增强方法[43]和图像去噪器[44]。更详细的改进方法见[23]。
多层拉普拉斯技术[43]增强了图像的局部和全局对比度。此方法的参数控制图像的细节、阴影和亮度。图13显示了具有不同参数集的多层拉普拉斯函数的几个例子。我们观察到,通过对比度调整,可以提高对AVA数据集的训练的预测美学评分。因此,我们的模型能够指导多层拉普拉斯滤波器找到其参数的美学上接近最佳的设置。

这种类型的图像编辑示例如图14所示,其中细节、阴影和亮度变化的组合应用于每个图像。在每个例子中,6个细节级别的提升、11个阴影级别的变化和11个亮度级别的变化总共导致726个变化。

美感评估模型倾向于使用高对比度的图像和增强的细节。这与图10所示的AVA的基本事实结果一致。
涡轮去噪[44]是一种使用域变换[45]作为核心滤波器的技术。涡轮去噪的性能取决于空间和距离平滑参数,因此,适当调整这些参数可以有效地提高去噪器的性能。我们观察到,改变空间平滑参数会产生最显著的感知差异,因此,我们使用在tid2013数据集上训练的质量评估模型来调整该去噪器。将我们的无参考质量度量作为先验度量在图像去噪中的应用类似于朱和米兰法尔的工作[46],[47]。我们的结果如图15所示。
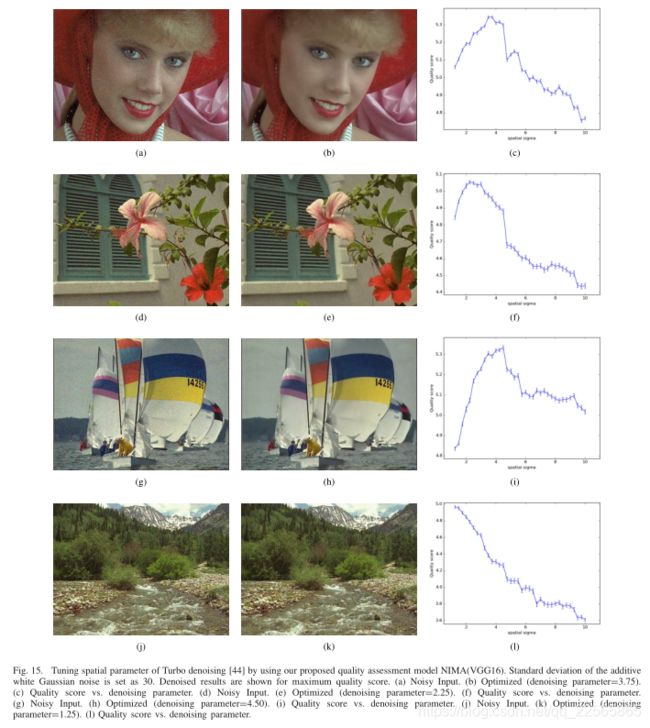
将标准差为30的加性高斯白噪声加入到清晰图像中,采用不同空间参数的涡轮去噪方法对噪声图像进行去噪。为了减少得分偏差,从去噪图像中提取50个随机裁剪图片。
平均这些分数以获得图15所示的图。可以看出,尽管每个图像添加的噪声量相同,但最大质量分数对应于每个示例中不同的去噪参数。对于(a)和(g)等相对平滑的图像,涡轮去噪的最佳空间参数比(j)中的纹理图像更高(这意味着平滑度更强)。这可能是因为(j)的信噪比相对较高。换句话说,质量评估模型倾向于尊重纹理,避免细节过于平滑。去噪参数的影响可以在图16中进行目视检查。当图16(a)中的去噪结果欠平滑时,(c)、(e)和(f)显示出不希望的过度平滑效果。预测的质量分数验证了这种感知观察。

E.计算代价
表五比较了NIMA模型的计算复杂性。
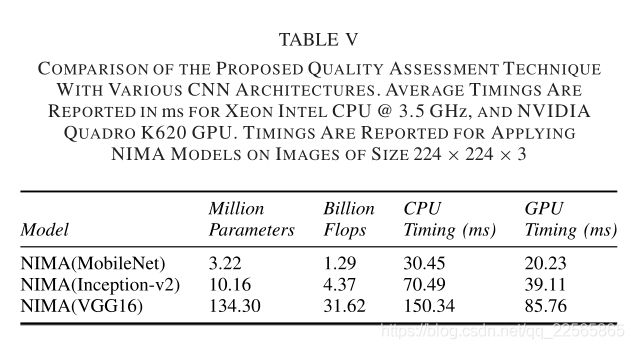
我们的相关tensorflow实现在Intel Xeon [email protected] GHz、32 GB内存和12核以及Nvidia Quadro K620 GPU上进行了测试。表五报告了224×224×3尺寸图像上一次NIMA模型的计时。显然,NIMA(Mobilenet)比其他模型更轻更快。这是以性能略有下降为代价的(如表一和表二所示)。


IV. 结论
在这项工作中,我们介绍了一种基于CNN的图像评估方法,它可以在美学和像素级质量数据集上进行训练。我们的模型有效地预测了质量评分的分布,而不仅仅是平均分。这将获得更准确的质量预测,并与真实值,等级有更高的相关性。我们对两个模型进行了高水平美学和低水平技术素质的训练,并利用它们来指导一些图像增强操作的参数。我们的实验表明,这些模型能够指导去噪和音调增强,以产生知觉上的优越结果。
作为我们未来工作的一部分,我们将在其他图像增强应用程序上利用经过训练的模型。我们当前的实验设置要求对增强运算符进行多次评估。这限制了该方法的实时应用。有人可能会说,对于具有定义良好的导数的增强算子,使用NIMA作为损失函数是一种更有效的方法。