Tensorflow:深度学习入门详解Mnist案例
简介
本文以MNIST数据集为基础,搭建一个分类网络。使用的深度学习框架为tensorflow。在搭建神经网络时,分别基础API和tf.contrib.slim高级API两个方面编写代码。前者,能较好的理解神经网络计算细节,后者能够快速利用API搭建神经网络,方便实现。
主要内容
一、MNIST数据介绍及读取
1. MNIST下载
2. MNIST的读入
二、 MNIST训练及检测、模型参数保存、模型的加载
1.使用tf基础的API搭建神经网络
2. 使用tf中的tf.contrib.slim搭建神经网络
3. 模型的加载
三. 结语
完整代码(github):https://github.com/zjjzjj123/Mnist_example
一、MNIST数据介绍及读取
1. MNIST下载
在链接https://pan.baidu.com/s/1d3XvQk4ZUTXSW0FJ10aQOw下载MNIST数据集的压缩文件,也可不下载直接执行程序,会自动下载到程序所在的文件夹下面。将压缩文件解压后放入到对应的文件夹里即可。
- MNIST数据集是一个数字图片分类的数据集。从0-9一共分为10类,里面有55000训练样本、5000验证样本、10000测试样本。
2. MNIST的读入
- 在tensorflow中已经集成好相应的代码读取MNIST,能够轻松读取,需要的训练图片和训练标签。以下有关数据读去的代码。
from tensorflow.examples.tutorials.mnist import input_data #从tf中导入读入MNIST数据的API
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #实例化对象,参数one_hot一定要有,路径根据情况修改
print(mnist.train.images.shape) #训练图片的数量(55000,784) #mnist的图片格式是[None,784],28*28
image1 = mnist.train.images[0,:] #读取第一张图片
label1 = mnist.train.labels[0,:] #读取第一张图片的标签
print(label1)
image1 = np.reshape(image1,[28,28]) #由于mnist是[None,784]->[28,28]进行显示,训练时也是
cv2.imshow('image1',image1)
cv2.waitKey(1000)
image1如下:
![]()
输出:labels: [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] 因为读取的数值是7,因此7对应的位置为1其余为0,这也就是one-hot结构的label的特点。
二、 MNIST训练及检测、模型参数保存、模型的加载
1.使用tf基础的API搭建神经网络
- 使用基础的tf函数去搭建一个神经网络,其中包括全连接层、卷积层。其中为了方便构架神经网络,定义了权重初始化、偏置初始化函数。具体代码如下:
def WeightVariable(shape): #均值为0 方差为0.01的正态分布作为W的初始化
init = tf.Variable(tf.truncated_normal(shape,mean=0,stddev=0.01))
return init
def BiasVariable(shape):
init = tf.constant(0.1,shape=shape) #使用常数初始化
return tf.Variable(init)
def conv2d_(x,w):
#x:图片[batch,h,w,channels] w:卷积核[fh,fw,in,out] 前两个代表卷积核大小in代表输入通道 out代表输出通道
#strides:步长,且strides[0]=[3] 必须是1 只有中间两个参数才决定步长 下同
# padding='SAME'表示考虑边界 'VALD表示不考虑'
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME')
def max_pool2d_(x):
#x: 图片[batch,w,h,channels] ksize:中间两个代表卷积核大小 strides:代表卷积核步长
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
def basic_inference():
mnist_path = 'E:/code_now/Mnist_example/MNIST_data' #MNIST_data路径
mnist = input_data.read_data_sets(mnist_path,one_hot=True) #实例化 读取
x = tf.placeholder(tf.float32,[None,784]) #输入维度 None就代表batch自适应,根据输入的batch决定
y_hat = tf.placeholder(tf.float32,[None,10]) #输出类别
x_input = tf.reshape(x,[-1,28,28,1]) #格式为[Batch,h,w,C]
#形式类似y = x*w1 + b
#conv1
w1 = WeightVariable([5,5,1,32]) #卷积核的维度和输入输出通道的多少
b1 = BiasVariable([32]) #b的维度于w的输出通道一致
net = tf.nn.relu(conv2d_(x_input,w1) + b1)
net = max_pool2d_(net)
#conv2
w2 = WeightVariable([5,5,32,64])
b2 = BiasVariable([64])
net = tf.nn.relu(conv2d_(net,w2)+b2)
net = max_pool2d_(net)
net = tf.reshape(net,[-1,7*7*64]) #扁平化 以便送入到全连接层
#fc1
w3 = WeightVariable([7*7*64,1024]) #全连接层的w维度有所变化不是卷积核
b3 = BiasVariable([1024])
net = tf.nn.relu(tf.matmul(net,w3)+b3)
keep_drop = tf.placeholder(tf.float32) #drop out 参数占位符
net = tf.nn.dropout(net,keep_prob=keep_drop)
w4 = WeightVariable([1024,10])
b4 = BiasVariable([10])
y_conv = tf.nn.softmax(tf.matmul(net,w4)+b4)
cross_entrop = tf.reduce_mean(-y_hat * tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entrop)
correct = tf.equal(tf.argmax(y_hat,1),tf.argmax(y_conv,1))
acc = tf.reduce_mean(tf.cast(correct,tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver() #保存模型 实例化
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
data = mnist.train.next_batch(50)
train_acc = sess.run(acc,feed_dict={x:data[0],y_hat:data[1],keep_drop:0.5})
if i%50 == 0:
print('step: %d train_acc: %g'%(i,train_acc))
sess.run(train_step,feed_dict={x:data[0],y_hat:data[1],keep_drop:0.5})
if not tf.gfile.Exists('model/'):
tf.gfile.MakeDirs('model/')
saver.save(sess,'model/my_model.ckpt')
print('test acc: %g'%acc.eval(feed_dict={x:mnist.test.images,y_hat:mnist.test.labels,keep_drop:1.0}))
结果如图: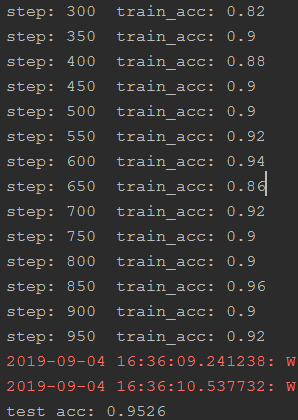
2. 使用tf中的tf.contrib.slim搭建神经网络
- tf.contrib.slim具有更高层的函数API。因为,在搭建多层神经网络时,需要设置的参数很多,代码看起来复杂且不直观。所以,使用tf.contrib.slim能更好的管理代码,使得代码变得整洁。在搭建网络时也更加方便,阅读时也跟容易抓住重点。
def slim_inference(): #推理过程
mnist_path = 'E:/code_now/Mnist_example/MNIST_data' #MNIST_data路径 根据自己路径修改
mnist = input_data.read_data_sets(mnist_path,one_hot=True) #实例化 读取
#定义占位符
x = tf.placeholder(tf.float32,[None,784]) #输入占位符
y_hat = tf.placeholder(tf.float32,[None,10]) #输出占位符
x_input = tf.reshape(x,[-1,28,28,1]) #将[None,784]reshape成[-1,28,28,1] 以便送到网络中进行训练
with slim.arg_scope([slim.conv2d], #类似slim的作用范围 只要是slim.conv2d都能进行一下初始化
weights_initializer=tf.truncated_normal_initializer(mean=0,stddev=0.01), #权重W初始化
biases_initializer=tf.constant_initializer(0.1), #偏置初始化
padding='SAME', #卷积时 是否考虑边界
activation_fn=tf.nn.relu): #卷积层后的激活函数
#x_input:输入图片[batch,w,h,channels] 32:输出通道 [5,5]:卷积核大小 [1,1]:步长 scope:层名称
net = slim.conv2d(x_input,32,[5,5],stride=[1,1],scope='conv1')
#net:卷积层输出 [2,2]:卷积核大小 [2,2]:步长 scope:层名称
net = slim.max_pool2d(net,[2,2],stride=[2,2],scope='pool1')
net = slim.conv2d(net,64,[5,5],stride=[1,1],scope='conv2')
net = slim.max_pool2d(net,[2,2],stride=[2,2],scope='pool2')
net = slim.flatten(net) #将卷积层输出的多维度矩阵,扁平化成全连接层能够使用的[x,w]的维度
net = slim.fully_connected(net,1024,scope='fc1')
net = slim.dropout(net,keep_prob=0.5)
y_conv= slim.fully_connected(net,10,activation_fn=None,scope='fc2') #最后输出[None,10] 也就是对应10个类别的预测结果
# use tf optimizer function
cross_entrop = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_hat,logits=y_conv)) #loss的定义 使用交叉熵
# cross_entrop = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_hat, logits=out))
train_step = tf.train.AdamOptimizer(0.0001).minimize(cross_entrop) #loss的优化
correct = tf.equal(tf.argmax(y_hat,1),tf.argmax(y_conv,1)) #对每个样本判断是否预测正确
acc = tf.reduce_mean(tf.cast(correct,tf.float32)) #求出准确率
init = tf.global_variables_initializer() #初始化tf变量
# sess = tf.InteractiveSession()
saver = tf.train.Saver() #实例化,保存模型
with tf.Session() as sess:
sess.run(init)
for i in range(1000): #训练1000次
data = mnist.train.next_batch(50) #每个batch的图片样本是50
train_acc = acc.eval(feed_dict={x:data[0],y_hat:data[1]})
if i%50 == 0: #没50次输出一次准确率
print("step %d,training acc %g"%(i,train_acc))
sess.run(train_step,feed_dict={x:data[0],y_hat:data[1]}) #运行训练
# cross_entrop = slim.losses.softmax_cross_entropy(logits=out,onehot_labels=y_hat)
if not tf.gfile.Exists('model/'):
tf.gfile.MakeDirs('model/')
saver.save(sess,'model/my_model.ckpt') #保存模型
print('test acc %g:'%acc.eval(feed_dict = {x:mnist.test.images,y_hat:mnist.test.labels})) #训练完之后进行测试
结果和上面例子结果类似,直接运行,然后等待即可。
3. 模型的加载
- 经过上面代码的训练后,保存模型到mode文件夹中,保存格式为ckpt形式如下图所示:

- checkpoint:保存模型断点的路径(我没弄明白啥意思)
- my_model.ckpt.data-00000-of-00001:保存了所有变量的值,即网络的权重值
- my_model.ckpt.index:为数据访问提供索引,存储的核心内容是以tensor name为键以BundleEntry为值的表格entries;
- my_model.ckpt.meta:MetaGraphDef序列化的二进制文件,保存了网络结构相关的数据,包括graph_def和saver_def等;
值得注意的是,当前tf训练时,可以将模型保存为ckpt或pb文件,其中ckpt文件是结构和权重分离的文件,便于训练,保存的文件的checkpoint里面就说明了。而pb文件是graph_def文件,便于发布和离线预测。tf官方提供了将ckpt文件转换成pb文件的脚本。(暂时没尝试过)
下面是加载模型的代码,注意使用的slim搭建的模型进行训练的模型参数。因此,在恢复权重参数到网络中,这个网络也需要是slim搭建的并且相应的网络节点也要一致。
#就算是用已经训练好的模型也应该构建模型 只是不用训练了
#因为使用的是slim训练的模型 因此也是用slim构架网络 将参数直接加在到网络中
def restore_interence():
mnist = input_data.read_data_sets('E:/code_now/Mnist_example/MNIST_data',one_hot=True)
x = tf.placeholder(tf.float32,[None,784])
y_hat = tf.placeholder(tf.float32,[None,10])
x_input = tf.reshape(x,[-1,28,28,1])
#struct model
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
with slim.arg_scope([slim.conv2d],
weights_initializer=tf.truncated_normal_initializer(mean=0, stddev=0.1),
biases_initializer=tf.constant_initializer(0.1),
activation_fn=tf.nn.relu):
net = slim.conv2d(x_input, 32, kernel_size=[5, 5], stride=[1, 1], padding='SAME', scope='conv1')
net = slim.max_pool2d(net, kernel_size=[2, 2], stride=[2, 2], scope='pool1')
net = slim.conv2d(net, 64, kernel_size=[5, 5], stride=[1, 1], padding='SAME', scope='conv2')
net = slim.max_pool2d(net, kernel_size=[2, 2], stride=[2, 2], padding='SAME', scope='pool2')
net = slim.flatten(net)
net = slim.fully_connected(net, 1024, scope='fc1')
net = slim.dropout(net, 0.5)
pred = slim.fully_connected(net, 10, activation_fn=None, scope='fc2')
saver = tf.train.Saver()
saver.restore(sess,'E:/code_now/Mnist_example/source/model/my_model.ckpt')
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_hat, logits=pred))
correct = tf.equal(tf.argmax(y_hat, 1), tf.argmax(pred, 1))
acc = tf.reduce_mean(tf.cast(correct, tf.float32))
print(acc.eval(feed_dict={y_hat:mnist.test.labels,x:mnist.test.images}))
结果和上面例子结果类似,直接运行,然后等待即可。
三. 结语
本文主要是入门级别的深度学习分类实例。对硬件要求不高、结构相对简单的。但却帮助我更好的入门深度学习。文中有很多不足之处,对于参数的调节,优化函数的选择等等都没能涉及到。如有错误恳请各位大佬斧正。
参考:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-c1ov28so.html