深度学习训练已经停止了,可GPU内存还在占用着,怎么办?
该情况通常发生在非正常中断GPU下发生,如手动暂停了训练。然后发现,再一次训练的时候出现错误:
RuntimeError: CUDA out of memory. Tried to allocate 736.00 MiB (GPU 0; 10.92 GiB total capacity; 2.26 GiB already allocated; 412.38 MiB free; 2.27 GiB reserved in total by PyTorch)
在终端查看GPU使用情况:

哎,GPU真的一直在占用着,必须关掉它
-----------------------------方法---------------------------
1. 查看GPU进程ID
1.1 通过nvidia-smi查看, PID号就是进程号,我这里是1297

1.2 如果上述办法看不到PID,输入 fuser -v /dev/nvidia* 查看

2. 杀死进程 kill -9 PID

就恢复了。
使用 kill -9 PID 进程杀不死,怎么办,如下图
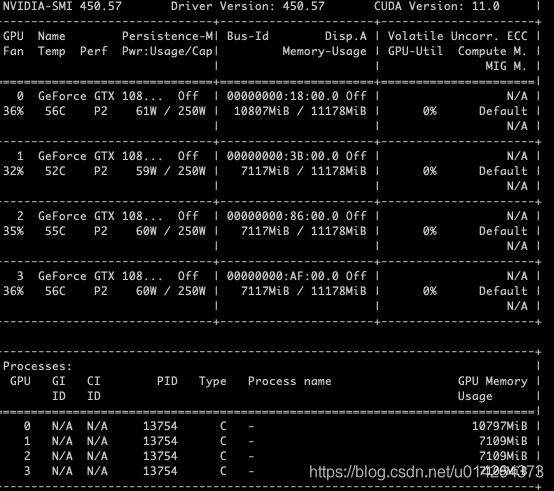
如果遇到这种情况,肯定还有隐藏进程
终端输入: ps -A -ostat,ppid,pid,cmd | grep -e '^[Zz]'
![]()
发现:不仅有13754, 还有13728.
于是 把13728 kill 掉: kill -9 13728
再次运行 nvidia-smi 发现进程被杀死了。