原问题出处: http://blog.csdn.net/wyhuan1030/article/details/5100372
我在此仅作回答
字符串
学习时间:1.5W(“W”周,下同)
知识点checklist
问:
1. strlen()函数的返回值是什么类型的?
2. 字符串strlen()的值,是否和他占据的内存空间相同?
3. 你是否知道strcpy函数存在的潜在风险?如何避免?
4. 如果一个字符串没有字符串结束符,而调用str开头的库函数,会发生什么?
5. Strcpy(),strcat(),strcmp(),strncpy(),strncat(),strncmp()内部到底是如何运行的?这些函数到底对源字符串和目标字符串做了些什么?你是否观察过它们运行时两个字符串内存的变化?
6. 上面这些函数使用时,各有哪些需要注意的地方?
7. 你会几种字符串查找操作?
8. c语言中有字符串这个数据类型吗?
9. 对字符串进行操作的时候,是否为字符串结尾符预留存储位置?不然的话容易造成非常访问内存。
答:
1. size_t. 这是一种不同体系结构上长度不一致的类型. 代表的是 cpu 一次能处理的 bit 数量. x86 下是 32-bit, x64 下是 64-bit. 这个类型是编译器编译期间就定好的.
2. strlen 的值是 "返回值" 还是 "参数值"? 如果是返回值, 那么是在栈中, 如果是参数值, 则根据调用者而定了. 这个问题无法解答.
3. strlen 存在风险. 如果你传入一个没有 '\0' 结尾的内存地址, 或者是一个非法地址(通常是 NULL/nullptr), 则函数会发生越界访问.
4. str 一族的函数都有上述 3 所述的问题.
5. 不同编译器实现可能不同. 我看 vs 2012 的代码, 是一次读取 32-bit, 分成 4 次比较, 直到遇到 '\0' 为止.
6. 首先不要传 NULL/nullptr 作为参数. 第二就是调用函数之前, 要保证所传的参数有 '\0' 做结尾.
7. 各种 c/c++ 函数, windows/linux 函数, 以及自己写 for/while/memcpy 之类的.
8. 没有. 只有指向字符的指针, 即 char *.
9. 是的.
数组
学习时间:2W
知识点checklist
问:
1. 你肯定知道,定义“int a[10];”,a[10]这个元素是无效的。
2. 你知道几种数组初始化的方法?
3. 数组和指针有千丝万缕的联系而又不同,你是否对他们在不同情况下的使用进行过详细的总结?
4. “int calendar[10][20];”,这是一个什么样的数组?它拥有10数组类型的元素,还是20个?
5. “int a[10];”,数组名a在本质上是一个什么?你是否打印过a的值?
6. 你知道几种获取数组某元素的方法?
7. 指针和数组相同吗?什么时候相同?什么时候不同?
8. 用指针和下标访问数组元素,那种方式更快?
答:
1. int a[10]; 一共有 10 个元素, 分别是 a[0], a[1] ... a[9].
2. 数组初始化的标准做法: int arr[3] = {1, 2, 3}; 也可以是 int arr[3] = {1}, 这样后两个元素就是 0; 也可以是 int arr[3] = {}, 这样全部元素都是 0; 也可以是 int arr[] = {1, 2, 3}, 这样不指定元素个数, 编译器就根据花括号中的元素个数决定数组的元素个数. 此外, 对于数组, 也可以是用 memset/fill 等函数, 进行初始化.
3. 数组是一个常量, 是一个内存地址, 表示数组从该地址起始. 而指针是一个变量, 只有 32/64-bit 长, 它也表示一个内存地址, 这个地址就是数组的起始地址. 两者在数值上相同, 但前者是常量, 编译后没有实际的内存空间, 后者是一个内存中实实在在的变量, 只不过它的值比较特殊, 等于一个数组的起始地址而已. 前者长度是根据数组的元素个数, 以及每个元素的长度决定的(元素个数 * 每个元素的长度), 而后者是固定的一个 32/64-bit 的变量, 在使用 sizeof 的时候要特别注意. 另外, 数组被当作参数传递给函数的时候, 会退化为指针, 这在 C 语言中很容易出错, 但是在 C++ 中, 因为引入了 "引用" 这个概念, 导致可以传入一个定长的数组, 所以在 C++ 中, 传入数组的引用就不会导致数组退化为指针, 这一点需要注意, 此问题并不复杂, 请 google 一下 "C 语言数组退化" 以及 "C++ 数组引用" 即可区分两者.
4. 这是一个二维数组, 即 calendar 是一个 10 个元素的数组, 每个元素又是一个 20 个元素的数组. 你可以理解为由 x-y 组成的二维坐标系.
5. a 本质就是一个编译器内部的结构, 如果你打印它的值, 那么就是一个数字, 如果你对它进行 sizeof, 就是数组所占的内存大小.
6. 使用 '[]' 和 '*'.
7. 指针和数组本质就不相同, 只不过在某些语法上比较相似而已. 在获取元素的时候语法相同, 当作指针参数传递给函数时相同. 在输出数组和指针的地址时, 以及 sizeof 的时候不同, 以及当作引用传递给参数时不同.
8. 如果不考虑编译器优化, 则下表访问更快, 因为下标会被编译为一个常量地址, 而指针需要先从内存取这个指针的值, 再根据这个指针的值去内存取数组中该元素的值. 所以下标只需要一次取内存, 而指针需要两次.
结构体
学习时间:1W
知识点checklist
问:
1. 你知道什么是位域结构体吗?如何定义它?如何使用它?
2. 你知道字节对齐对结构体占用内存空间大小的影响吗?如何计算结构体占用内存的大小?
答:
1. 位域就是对一个基本类型拆分. 比如, 一个 int 本应该是 32-bit, 但是我们可以将其拆分为多个变量, 每个变量需要小于 32-bit. 如果总和超过 32-bit, 则多开辟一个 int 空间. 定义方法如下, 使用方法同一般的结构体.
uint32_t m_0 : 4, \ m_1 : 1, - 这三个域在一个 int 之中. m_2 : 2, /
- 这中间有一段填充, 不被任何域所拥有. m_3 : 30; - 这个域在第二个 int 中.
2. 结构体中, a) 每一个成员, 起始地址是其长度的整数倍. b) 结构体总大小满足其中最大的基本类型的整数倍.
struct S { char a; // [0]. // [1-3]. 填充. int b; // [4-7]. int 必须从 4 字节的整数倍地址开始, 因此从 0x04 地址开始, 导致 [0x01 - 0x03] 都是填充. char c; // [8]. // [9-15]. 填充. double d; // [16-24]. 1: double 必须从 8 字节的整数倍地址开始. 2: 这是最大的类型, 整个结构体长度必须是它的整数倍. char e[14]; // [25-38]. 数组也只不过是基本类型的聚合, 按照基本类型算大小. // [39]. 填充. int f; // [40-43]. // [44-47]. 填充. 由于 double 是最大类型, 所以结构体必须填满 8 的整数倍, 即 48. }; // 'sizeof(S) == 48'.
宏
学习时间:1W
知识点checklist
问:
1. 你知道宏的本质是什么吗?函数?语句?类型定义?或者其他?
2. 你知道语言设计者为什么设计宏吗?这些原因目前是否仍然成立?
3. 你会设计带有参数的宏吗?
4. 你知道使用宏的参数的的时候的注意事项吗?
5. 你会设计带有可变参数的宏吗?
6. 你知道使用宏有什么劣势吗?
7. 你有没有更好的替代方案?
答:
1. 宏的本质是一条编译器使用的指令.
2. 当初设计宏, 是为了方便批量产生和控制类似的语句. 某些情况还是必要的(比如控制编译选项).
3. 会.
4. 知道. 宏会被无条件的, 机械的替换. 因此其参数也会机械的被代入. 因此在某些情况下会发生错误, 如:
#define MUL(x) x*x MUL(1+2) // 1+2*1+2 => 1 + (2*1) + 2. bug!
5. #define debug(...) printf(__VA_ARGS__). 这里有详细的解释: http://blog.csdn.net/c395565746c/article/details/6612341
6. 优势是: 没有空间/计算等消耗, 可以直接生成相似的代码, 可以通过编译器传入. 劣势: 直接替换的工作模式, 过于死板, 容易引发隐晦的 bug (如问题 5 所述).
7. 使用 static cosnt 或者 constexpr 代替常量定义. 使用 inline 消灭性能损失.
枚举
学习时间:0.5W
知识点checklist
问:
1. 是否可以指定枚举中各项的值?
2. 如果不指定值,枚举的第一个值是多少?
3. 枚举的值是否可以是负数?
4. 定义枚举的时候,你是否专门定义了枚举的最小值和最大值?
答:
1. 可以.
2. 在 C++11 之前, enum 是默认 int 类型的, 所以第一个值是 0. 但是 C++11 引入了 enum class, 使枚举可以有类型, 所以第一个值是什么就取决于类型的默认构造函数了.
3. 可以.
4. 我不认为枚举有最值. 说枚举有最值是因为数据类型的限制, 不是枚举的限制.
Switch
学习时间:0.5W
知识点checklist
问:
1. switch(c)中的c的数据类型有哪些?
2. 你是否在所有的switch中都加了default语句?
3. 是否在所有的case中都加了break语句(一般情况的做法)?如果你不加break,将会发生什么?
答:
1. 任何一个可转换为整数值的类型都可以.
2. 是.
3. 如果没有 break, 就导致后面的语句还将会执行. break 是每个 case 都应该有的, 除非你故意让几个 case 都执行一个结果, 如果是这种情况, 应该写注释说明. 否则给后续的维护人员留下隐患.
Static
学习时间:1W
知识点checklist
问:
1. static的三个主要作用是什么?
2. static的修饰的局部变量是保存在什么地方的?全局变量哪?
3. static修饰的全局变量和函数,在其他的文件中是否可以访问?如何访问?
4. 你知道static是c语言中实现封装和隐藏的利器吗?你是否经常使用?
5. 定义在不同源文件中的static全局变量,编译器是否允许他们的变量名称相同?他们在内存中的地址是否相同?函数那?
答:
1. 将变量声明为静态的. 将函数的可见性收敛到模块内. 声明静态成员函数.
2. 未初始化数据区. 初始化数据区.
3. 不可以, 不经常. 定义全局变量是不可扩展, 不可复用, 不可重入的技术.
4. 知道. 经常将不需要向外暴露的函数声明为 static.
5. 允许. 不同. 函数与变量一样.
const
学习时间:1W
知识点checklist
问:
1. 你是否经常使用const来表明不能够被更改的变量?
2. 你是否经常使用const常量来代替宏?
3. 下面四种情况,你知道是各表示什么意思吗?
a) int i_value= 10;
b) const int* pvalue = &i_value
c) int const *pvalue = &i_valueint* const pvalue= &i_value
d) const int* const pvalue = &i_value
4. 你知道const常量如何初始化吗?
答:
1. 是的. 函数参数中尤其应该声明 const, 这是给调用者一个契约.
2. 是的.
3. a) 普通变量. b) 常指针 (所指向的值不可变). c) 同 b. d) 指针常量 (指针不可变, 指向的值可变)
4. 如 const i = 1234; RAII(Resource Acquisition Is Initialization).
对于 const, 还有好多要说的, 尤其是和 typedef 在一起, 能引发很很隐晦的问题, 请见: http://www.dansaks.com/articles/1996-12%20Mixing%20const%20with%20Type%20Names.pdf
Sizeof
学习时间:1W
知识点checklist
问:
1. 对于字符数组,strlen和sizeof的值是否相同?
2. Sizeof本质上是函数还是宏?
3. Sizeof的返回值是什么类型?
答:
1. 基本不同. strlen 是数组中第一个 '\0' 的位置(这个值代表字符串的长度), 如果字符串没有 '\0' 结尾, 还会导致访问越界. sizeof 返回的是数组本身的长度. 不受数组内存放的内容所影响.
2. 这是一个关键字, 就像 switch 和 const 一样. 不是函数, 也不是宏.
3. sizeof 返回值是 size_t. 在 C++11 中, sizeof 还作为变数模板的模板个数.
指针
学习时间:3W
知识点checklist
问:
1. “int *p;”&p,p,*p他们的值分别表示什么含义?
2. 你定义的指针初始化了没?
3. 你理解指针的指针的概念吗?你会使用吗?
4. “int *pi_value; pi_value = 0x100000;” pi_value + 1的值是是多少?
5. 你会定义函数指针吗?
6. 你会使用函数指针调用函数吗?
7. 关于指针和数组,请参见知识点数组。
答:
1. 分别是: 声明/定义一个指向 int 的指针 p. 取指针 p 的地址. p 指针自身. p 所指向的内容.
2. int *p = NULL; // 'nullptr' in c++ 11. 还是 RAII 问题.
3. 理解. 会.
4. 0x100004. 指针的 +/- 运算是根据指针自身的长度. 在 32 位代码下, 所有的指针都是 4 字节, 无论什么指针做 ++/-- 运算, 幅度都是 4. 在 64 位下幅度都是 8.
5. 会. void (*pfn)() => pfn 是一个指针, 这个指针指向一个函数, 这个函数没有参数, 也没有返回值. 对于 C 语言声明的理解, 请看这里 (最后解释部分): http://www.cnblogs.com/walfud/archive/2011/07/29/2121482.html
6. 会. pfn() 即可. (*pfn)() 也可.
7. 略.
动态分配内存
学习时间:1W
知识点checklist
问:
1. 动态分配的内存是保存在什么地方的?
2. 什么情况下使用动态分配内存?
3. 动态申请内存一定要释放,否则会内存泄露。你是否使用过内存检测工具?
答:
1. 堆中.
2. 在编译期间不能确定要分配多大内存时(可以通过分配一个固定的, 一定够用的内存解决). 把内存当作返回值传递的时候(可以返回对象, 以便摆脱内存分配与释放问题).
3. Visual Leak Detector.
函数
学习时间:1W
知识点checklist
问:
1. 如何查看函数在内存中的地址?
2. 如何给一个函数指针赋值?
3. 你是否会定义可变入参函数
4. 你是否可以区分函数的形参与实参?
5. 如何定义函数名,以准确的表达函数的用途?
6. 你是否使用const来修饰函数入参和返回值,以表的特定的含义?
7. 递归如何使用?
答:
1. reinterpret_cast
2. 如同普通变量一样.
3. 如 'void foo(int argc, ...);'. 其中 "..." 就是可变数目的参数. 这种函数都使用 __cdelc 调用约定.
4. 形参是函数声明和定义的时候, 指定这个函数需要接收的参数类型的参数, 这种参数只是一种说明, 说明了函数的规格. 实参指的是, 实际调用函数时, 填写的参数, 这个参数可能是表达式, 值等元素.
5. 有很多命名约定, 就像书法风格一样, 没有绝对的准则或者谁好谁坏. 具体请 google.
6. 递归需要两点: 退出的条件; 递归的流程. 具体的一两句话说不清, 请 google 后自行理解. (我曾经想这个问题, 从 10 点到家, 想到了夜里 2 点, 终于想透了, 以后再遇到递归, 轻车熟路)
void foo(char arr[], unsigned beg, unsigned end) { static unsigned s_cnt = 0; if (beg == end) { // 退出条件. cout <<++s_cnt <<": " <endl; } else { // 递归的流程. for (unsigned i = beg; i < end; ++i) { swap(arr[beg], arr[i]); foo(arr, beg + 1, end); swap(arr[beg], arr[i]); } } } int _tmain(int argc, _TCHAR* argv[]) { char arr[] = "1234"; foo(arr, 0, 4); return 0; }
变量
学习时间:1W
知识点checklist
问:
1. 全局变量,局部变量,常量分别保存在内存中的什么地方?
2. 不同类型的变量,你是否知道其作用域?
3. 全局变量和局部变量是否可以重名?你是否在这样做?
4. 局部变量在函数退出后是否有效,为什么?
5. 全局变量为什么不允许定义在头文件中?有何危害?
答:
1. 全局 => 已初始化数据段. 局部 => 栈. 常量 => 静态区. 还有一种变量, 叫做静态变量, 位于未初始化数据段.
2. 全局的是所有地方都可以引用, 不同模块需要先声明, 后引用. 局部变量以及静态变量是它所在的 {} 之内. 常量是从该常量声明的地方到模块文件的末尾.
3. 可以. 这样做不好, 虽然在 {} 内表示局部变量, 在外表是全局变量, 但是名字相同, 容易搞错. 此外, 在 C 语言中, 没有命名空间的概念, 所以在重名的情况下, 无法对全局变量操作(只能操作同名的局部变量).
4. 无效了. 局部变量分配在栈上, 函数结束, 栈销毁, 变量也就不存在了.
5. 因为不同模块包含该头文件后, 都会有这个全局变量的实体, 导致 redefinition 编译错误.
链接(linux)
学习时间:1W
知识点checklist
问:
1. 链接位于编译过程的那个阶段?
2. 动态链接库和静态链接库使用时有何区别?
3. 如何对动态链接库进行动态加载(不用重启程序而加载链接库)?
4. 动态链接有何优点?
5. 动态链接库中是否定义了非static的全局变量?你是否知道这是一个非常危险的动作?
6. 动态库中的全局变量(非static)和函数(非static)是否可以和上层全局变量和函数重名?重名后会发生什么事情?
答:
1. 编译和链接就不是一回事. 我们书写的代码, 先经过编译 => 二进制的, 可执行的代码片段; 然后经过链接 => 可被操作系统装载并执行的二进制文件, 也是编译阶段可执行片段的集合与重组.
2. 动态连接库可以在程序运行的时候动态的装载/卸载. 静态链接库在编译期间就装载好了, 运行阶段不能动态的装载/卸载.
3. windows 下可使用 LoadLibrary 装载, 使用 FreeLibrary 卸载. linux 不知道.
4. 主要有两点有点: a) 可以再运行时期, 不用重启程序就能更换可执行代码, 改变程序行为. b) 一个动态链接文件, 可以被很多程序装载, 并且只在内存中存在一份实例. 避免了同样的代码占用内存, 这些同样的代码在内存中是毫无意义的.
5. 知道. 如果程序员的本意是通过动态链接共享数据, 那么他将不会得到正确结果. 因为内存中, 对所有没有修改的动态链接库使用同一份代码, 但是一旦进程企图修改这片 "公共区域"(A), 那么系统就会单独给这个进程拷贝一份 "公共区域"(B), 然后这个进程就使用这个拷贝后的副本, 然而其它进程依然使用原先的公共区域(A). 这就导致这个进程貌似修改了 "公共区域"(A) 的数据, 然而实际上是修改了 A 的副本. 别的进程访问的仍然是 A. 没有达到目的.
6. 可以. 不会发生什么. 所谓函数名称, 只不过是函数地址的一个助记符. 可执行文件被编译后, 就没有助记符存在了, 都被链接程序替换为实际的函数地址. 而动态库是程序执行后才被加载到进程的, 动态库所有的名称都是地址, 被进程加载时被重定位, 地址上不会有任何冲突.
运行时的数据结构(linux)
学习时间:1W
知识点checklist
问:
1. 你知道什么是段的概念吗?
2. 可执行程序可以分为几个段?每个段保存的是什么内容?
3. 如何查看可执行程序各个段的大小?
4. 当函数被调用时发生了什么?
5. 你有没有试过程序的栈空间最大有多大?程序超过此大小会发生什么?
6. 你使用的系统的栈是向下生长的,还是向上生长的?
答:
1. 知道.
2. 不同编译器不一样. 不同系统也不一样. 但是都有: 已初始化数据段, 未初始化数据段, 静态数据段, 代码段, 栈段.
3. windows 下课通过 dumpbin 查看
4. 从汇编的角度看, 对 cs, ip, 返回值, 参数进行压栈. 顺序依不同调用约定而不同.
5. windows 下默认 1mb. 具体参见: http://wenku.baidu.com/view/64f3bd0303d8ce2f00662379.html
6. 我的是 intel 平台, windows 操作系统, 栈是向下增长的.
Include
学习时间:0.5W
知识点checklist
问:
1、如何避免对同一头文件的多次include?
答:
1. 标准的方法是: 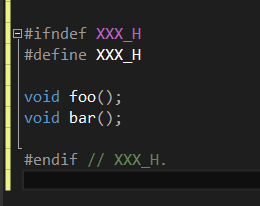
声明
学习时间:1W
知识点checklist
问:
1. 什么是声明,什么是定义?
2. 你是否会运用c语言声明的优先级规则?
答:
1. 声明是向编译器说明有这么一个变量/函数, 而定义是告诉编译器, 我要分配实际内存以存放变量/函数. 这里边概念很多, 但都非常重要. 搞不清楚的话则很多其它问题也会迷惑.
2. http://www.cnblogs.com/walfud/articles/2050522.html