通过分析mpstat的iowait和iostat的util%,判断IO瓶颈
IO瓶颈往往是我们可能会忽略的地方(我们常会看top、free、netstat等等,但经常会忽略IO的负载情况),今天给大家详细分享一下如何确认一台服务器的IO负载是否到达了瓶颈,以及可能优化、定位的点。
mpstat中看CPU的iowait高了,难道IO就瓶颈了吗???
先来看一台典型的IO密集型服务器的cpu统计图:
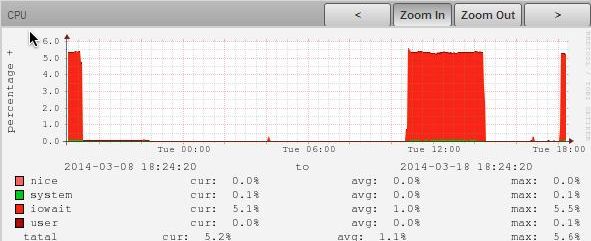
可以看到,CPU总使用率不高,平均1.3%,max到5.6%,虽然大部分都耗在了iowait上,但才百分之五左右,应该还没到瓶颈吧???
错了!这里要特别注意:iowait≠IO负载,要看真实的IO负载情况,一般使用iostat –x 命令:
你会发现iowait虽然只有5%,但是iostat中看到util% 却到达99%,说明磁盘就没有闲着!!!
$ iostat –x 1
avg-cpu: %user %nice %system %iowait %steal %idle
0.04 0.00 0.04 4.99 0.00 94.92 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.00 81.00 104.00 4.00 13760.00 680.00 133.70 2.08 19.29 9.25 99.90 sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda5 0.00 81.00 104.00 4.00 13760.00 680.00 133.70 2.08 19.29 9.25 99.90 这里重点指标是svctm和util这两列,man一下可以看到如下解释:
svctm
The average service time (in milliseconds) for I/O requests that were issued to the device.
%util
Percentage of CPU time during which I/O requests were issued to the device (bandwidth utilization for the device). Device saturation occurs when this value is close to 100%. svctm
可以看到,svctm指的是“平均每次设备I/O操作的服务时间 (毫秒)”,而util指的是“一秒中I/O 操作的利用率,或者说一秒中有多少时间 I/O 队列是非空的。”
util%
我们这里发现util已经接近100%,结合man的说明“Device saturation occurs when this value is close to 100%”可以知道其实目前这台服务器的IO已经到达瓶颈了。
那为什么最前面的cpu统计图的iowait项只有5.5%左右呢?因为这个iowait(也就是top里的wa%)指的是从整体来看,CPU等待IO的耗时占比:
wa -- iowait
Amount of time the CPU has been waiting for I/O to complete.
也就是说,CPU可能拿出一部分时间来等待IO完成(iowait),但从磁盘的角度看,磁盘的利用率已经满了(util%),这种情况下,CPU使用率可能不高,但是系统整体QPS已经上不去了,如果加大流量,会导致单次IO耗时的继续增加(因为IO请求都堵在队列里了),从而影响系统整体的处理性能。
确认了IO负载过高后,可以使用iotop工具具体查看IO负载主要是落在哪个进程上了。
那如何规避IO负载过高的问题呢?具体问题具体分析:
- 如果你的服务器用来做日志分析,要避免多个crontab交叠执行导致多进程随机IO(参考:随机IO vs 顺序IO),避免定期的压缩、解压大日志(这种任务会造成某段时间的IO抖动)。
- 如果是前端应用服务器,要避免程序频繁打本地日志、或者异常日志等。
- 如果是存储服务(mysql、nosql),尽量将服务部署在单独的节点上,不要和其它服务共用,甚至服务本身做读写分离以降低读写压力;调优一些buffer参数以降低IO写的频率等等。另外还可以参考LevelDB这种将随机IO变顺序IO的经典方式。
通过vmstat和iostat,判断IO瓶颈
oot@localhost ~]# vmstat -n 3 (每个3秒刷新一次)
procs-----------memory--------------------swap--- ---io---- --system---- ------cpu--------
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 144 186164 105252 2386848 0 0 18 166 83 2 48 21 31 0 2 0 144 189620 105252 2386848 0 0 0 177 1039 1210 34 10 56 0 0 0 144 214324 105252 2386848 0 0 0 10 1071 670 32 5 63 0 0 0 144 202212 105252 2386848 0 0 0 189 1035 558 20 3 77 0 2 0 144 158772 105252 2386848 0 0 0 203 1065 2832 70 14 15 IO
-bi:从块设备读入的数据总量(读磁盘)(KB/S)
-bo:写入到块设备的数据总量(写磁盘)(KB/S)
随机磁盘读写的时候,这2个值越大(如超出1M),能看到CPU在IO等待的值也会越大
iostat 实现
程序代码
iostat [ -c | -d ] [ -k ] [ -t ] [ -V ] [ -x [ device ] ] [ interval [ count ] ]
-c为汇报CPU的使用情况;
-d为汇报磁盘的使用情况;
-k表示每秒按kilobytes字节显示数据;
-t为打印汇报的时间;
-v表示打印出版本信息和用法;
-x device指定要统计的设备名称,默认为所有的设备;
interval指每次统计间隔的时间;
count指按照这个时间间隔统计的次数。
iostat在内核2.4和内核2.6中数据来源不太一样,对于kernel 2.4, iostat 的数据的主要来源是 /proc/partitions;在2.6中,数据来源主要是/proc/diskstats和/sys/block/sd*/stat这两个文件
#cat /proc/diskstats | grep sda
8 0 sda 17945521 1547188 466667211 174042714 15853874 42776252 469241932 2406054445 0 137655809 2580960422 8 1 sda1 936 1876 6 12 8 2 sda2 19489178 466659986 58655070 469240224 8 3 sda3 1270 1441 33 264 8 4 sda4 4 8 0 0 8 5 sda5 648 1442 0 0 8 6 sda6 648 1442 0 0第1列 : 磁盘主设备号(major)
第2列 : 磁盘次设备号(minor)
第3列 : 磁盘的设备名(name)
第4列 : 读请求总数(rio) 第5列 : 合并的读请求总数(rmerge) 第6列 : 读扇区总数(rsect) 第7列 : 读数据花费的时间,单位是ms.(从__make_request到 end_that_request_last)(ruse) 第8列 : 写请求总数(wio) 第9列 : 合并的写请求总数(wmerge) 第10列 : 写扇区总数(wsect) 第11列 : 写数据花费的时间,单位是ms. (从__make_request到 end_that_request_last)(wuse) 第12列 : 现在正在进行的I/O数(running),等于I/O队列中请求数 第13列 : 系统真正花费在I/O上的时间,除去重复等待时间(aveq) 第14列 : 系统在I/O上花费的时间(use)。#iostat -x 1
Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/27/2009 avg-cpu: %user %nice %system %iowait %steal %idle 30.72 0.00 5.00 5.72 0.00 58.56 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.79 21.81 9.15 8.08 237.99 239.29 27.69 1.32 76.31 4.07 7.02 sdb 0.69 19.13 3.26 2.99 153.08 176.92 52.85 0.43 68.80 5.96 3.72 sdc 3.47 89.30 10.95 7.30 213.30 772.94 54.04 1.32 72.43 4.18 7.63每项数据的含义如下,
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s wsec/s: 每秒写扇区数。即 wsect/s rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。 wkB/s: 每秒写K字节数。是 wsect/s 的一半。 avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。即 (rsect+wsect)/(rio+wio) avgqu-sz: 平均I/O队列长度。即 aveq/1000 (因为aveq的单位为毫秒)。 await: 平均每次设备I/O操作的等待时间 (毫秒)。即 (ruse+wuse)/(rio+wio) svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 use/(rio+wio) %util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O队列是非空的,即use/1000 (因为use的单位为毫秒), 如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),
svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多
也会间接导致 svctm 的增加。
await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
io/s = r/s +w/s
await=(ruse+wuse)/io(每个请求的等待时间)
awaitio/s=每秒内的I/O请求总共需要等待的ms
avgqu-sz=await(r/s+w/s)/1000 (队列长度)
以下数据其实与/proc/diskstats中除设备号与设备名外的其它数据是一一对应关系,只是统计的方法略有差别而已。
#cat /sys/block/sda/stat
17949157 1547772 466744707 174070520 15855905 42781288 469298468 2406092114 2 137680700 2581025934
命令:uptime
说明:查看机器分别在1分钟、5分钟、15分钟的平均负载情况,显示的数字表示等待cpu资源的进程和阻塞在不可中断io进程的数量,如果1分钟的平均负载很高,而15分钟的平均负载很低,说明服务器正处于高负载情况,需要进一步排查cpu资源都消耗在了哪里。反之,如果15分钟的平均负载很高,而1分钟的平均负载很低,则有可能是cpu资源紧张的时刻已经过去。
命令:dmesg|tail
说明:输出系统日志的最后10行。
命令:vmstat 1
说明:每行输出一些系统核心指标,1表示每1秒输出一次统计信息。
r:等待在cpu资源的进程数,如果超过了机器cpu核数,那么机器的cpu资源已经饱和。
free:系统可用内存数,单位:kb
si,so:交换区写入和读取的数量。如果大于0,说明系统已经在使用交换区(swap),机器的物理内存已经不足。
us,sy,id,wa,st:这些都代表了cpu时间的消耗,分别表示用户时间,系统内核时间,空闲时间,io等待时间和被偷走的时间(stolen,一般被其他虚拟机消耗)
一般情况下,如果用户时间和系统时间相加非常大,cpu处于忙于执行指令。如果io等待时间很长,那么系统的瓶颈可能在磁盘io。如果大量cpu时间消耗在用户态,
也就是用户应用程序消耗了cpu时间。这不一定是性能问题,需要结合r队列,一起分析。
命令: mpstat -P ALL 1
说明:显示每个cpu的占用情况
命令: pidstat 1(需要安装sysstat包)
说明:查看进程占用的cpu资源情况
命令:iostat -x 1
说明:查看机器磁盘io情况
命令:free -m
说明:查看系统内存的使用情况,m表示按照兆字节显示。
命令:sar -n DEV 1
说明:查看网络设备的吞吐率。可以判断网络设备是否已经饱和。硬件上限:1Gbit/sec
命令:sar -n TCP,ETCP 1 (需要安装sysstat包)
说明:查看TCP连接状态,
active/s:每秒本地发起的tcp连接数
passive/s:每秒远程端发起的TCP连接数
retrans/s:每秒TCP重传数量
命令:top
说明:全面的查看系统负载的来源。
以下内容来自转载和自己的初用体验。
vmstat
[root@master ~]# vmstat -n 3
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 115516 6043024 430340 8691840 0 0 2 22 1 1 1 0 99 0 0
0 0 115516 6043024 430340 8691840 0 0 0 0 1124 751 0 0 100 0 0
0 0 115516 6043148 430344 8691840 0 0 0 25 1070 762 0 0 100 0 0
PROC
如果在processes中运行的序列是连续的大于在系统中的CPU的个数表示系统现在运行比较慢,有多数的进程等待CPU。
如果r的输出数大于系统中可用CPU个数的4倍的话,则系统面临着CPU短缺的问题,或者是CPU的速率过低,系统中有多数的进程在等待CPU,造成系统中进程运行过慢。
SYSTEM
in: 每秒产生的中断次数
cs: 每秒产生的上下文切换次数
上面2个值越大,会看到由内核消耗的CPU时间会越大
CPU
us:用户进程消耗的CPU时间百分比,其中us值比较高时,说明用户进程消耗的CPU时间多;如果长期超50%的使用,那么我们该考虑优化程序算法或者进行加速
sy: 内核进程消耗的CPU时间百分比(sy的值高时,说明系统内核消耗的CPU资源多,并不是良性表现,我们应该检查原因)
wa:IO等待消耗的CPU时间百分比(值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也可能磁盘出现瓶颈,如块操作)
id: CPU处于空闲状态的百分比,如果空闲时间持续为0并且系统时间是用户时间的两倍,那么系统则面临CPU资源的短缺
解决方法:
当发生以上问题的时候请先调整应用程序对CPU的占用情况,使得应用程序能够更有效的使用CPU,同时可以考虑增加更多的CPU,关于CPU的使用情况还可以结合mpstat、ps aux 、top、mpstat -a等等一些相应的命令来综合考虑关于具体的CPU的使用情况,和那些进程在占用大量的CPU时间,一般情况下,应用程序的问题会比较大一些。
sar
Usage: sar [ options... ] [
Options are:
[ -A ] [ -b ] [ -B ] [ -c ] [ -d ] [ -i
[ -r ] [ -R ] [ -t ] [ -u ] [ -v ] [ -V ] [ -w ] [ -W ] [ -y ]
[ -I {
[ -n { DEV | EDEV | NFS | NFSD | SOCK | ALL } ]
[ -x {
[ -o [
[ -s [
在命令行中,n和t两个参数组合起来定义采样间隔和次数,t为采样间隔,是必须有的参数,n为采样次数,是可选的,默认值为1, -o file表示将命令的结果以二进制格式存放
在文件中,options为命令可选项:
-A:所有报告的总和。
-u:CPU利用率
-v:进程、I节点、文件和锁表状态。
-d:硬盘使用报告。
-r:内存和交换空间的使用统计。
-g:串口I/O的情况。
-b:缓冲区使用情况。
-a:文件读写情况。
-c:系统调用情况。
-q:报告队列长度和系统平均负载
-R:进程的活动情况。
-y:终端设备活动情况。
-w:系统交换活动。
-x { pid | SELF | ALL }:报告指定进程ID的统计信息,SELF关键字是sar进程本身的统计,ALL关键字是所有系统进程的统计。
用sar进行CPU利用率的分析
[root@master ~]# sar -u 2 10
Linux 2.6.18-194.el5 (master) 12/13/2012
06:50:01 PM CPU %user %nice %system %iowait %steal %idle
06:50:03 PM all 1.50 0.08 0.58 7.24 0.00 90.60
06:50:05 PM all 3.25 0.17 0.58 6.74 0.00 89.26
06:50:07 PM all 1.33 0.08 0.67 8.01 0.00 89.91
06:50:09 PM all 1.25 0.00 0.67 7.35 0.00 90.73
06:50:11 PM all 1.08 0.25 0.42 7.75 0.00 90.50
06:50:13 PM all 1.33 0.08 0.58 8.00 0.00 90.00
06:50:15 PM all 1.42 0.08 0.42 7.18 0.00 90.90
06:50:17 PM all 1.25 0.08 0.42 8.01 0.00 90.24
06:50:19 PM all 1.33 0.08 0.50 8.17 0.00 89.92
06:50:21 PM all 1.25 0.25 0.42 7.17 0.00 90.92
Average: all 1.50 0.12 0.53 7.56 0.00 90.30
在显示内容包括:
%user:CPU处在用户模式下的时间百分比
%nice:CPU处在带NICE值的用户模式下的时间百分比
%system:CPU处在系统模式下的时间百分比
%iowait:CPU等待输入输出完成时间的百分比
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比
%idle:CPU空闲时间百分比
在所有的显示中,我们应该主要注意%iowait和%idle,
%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲。
如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。反之如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
用sar进行运行进程队列长度分析:
[root@master ~]# sar -q 2 10
Linux 2.6.18-194.el5 (master) 12/13/2012
06:57:55 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
06:57:57 PM 0 1196 0.63 0.48 0.30
06:57:59 PM 0 1196 0.63 0.48 0.30
06:58:01 PM 0 1196 0.58 0.47 0.30
06:58:03 PM 0 1198 0.58 0.47 0.30
06:58:05 PM 0 1198 0.61 0.48 0.30
runq-sz:准备运行的进程运行队列
plist-sz:进程队列里的进程和线程的数量
ldavg-1:前一分钟的系统平均负载(load average)
ldavg-5:前五分钟的系统平均负载
ldavg-15:前15分钟的系统平均负载
顺便说一下load average的含义
load avarage可以理解为每秒钟CPU等待运行的进程个数。
在liunx系统中,有很多命令都会有系统平均负载load average的输出,那么什么是系统负载呢?
定义:在特定时间间隔内运行队列中的平均任务数。如果一个进程满足以下条件则其就会位于运行队列中:
1、它没有在等待I/O操作的结果
2、它没有主动进入等待状态(也就是wait)
3、没有被停止
例如:
[root@master ~]# uptime
09:34:05 up 69 days, 4:00, 1 user, load average: 0.08, 0.02, 0.01
命令输出的最后内容表示在过去的1、5、15分钟内运行队列中的平均进程数量。
一般来说只要每个CPU的当前活动进程数不大于3那么系统的性能就是良好的,如果每个CPU的任务数大于5,那么就表示这台机器的性能有严重问题。
对于上面的例子来说,假设系统有两个CPU,那么其每个CPU的当前任务数为:0.08/2=0.04,这表示该系统的性能是可以接受的。
这里有个思考问题,就是当CPU是支持超线程的时候,那么这时候是除以物理个数,还是逻辑个数?????
iostat
[root@master ~]# iostat -c 2 10
Linux 2.6.18-194.el5 (master) 12/14/2012
avg-cpu: %user %nice %system %iowait %steal %idle
1.08 0.15 0.14 0.05 0.00 98.58
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.42 0.25 0.00 0.00 0.00 99.33
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.08 0.08 0.00 0.00 99.83
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
mpstat
是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。
在多CPU系统里,其不但能查看看到所有CPU的平均状况信息,而且能够查看特定的CPU的信息。
mpstat语法如下:
Usage: mpstat [ options... ] [
Options are:
[ -P {
参数含义如下:
-P {
internal 相邻的两次采样的间隔时间
count 采样的次数,count只能和delay一起使用
当没有参数时,则显示系统启动以后所有信息的平均值。(参数解释从/proc/stat获得数据)
[root@master ~]# mpstat -P 1 2 3
Linux 2.6.18-194.el5 (master) 12/14/2012
09:56:35 AM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
09:56:37 AM 1 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.50 0.00
09:56:39 AM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
09:56:41 AM 1 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.50 0.00
Average: 1 0.00 0.33 0.00 0.00 0.00 0.00 0.00 99.67 0.00
补充说明下,nice值的含义
[root@master ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 29493 29491 0 75 0 - 16559 wait pts/1 00:00:00 bash
4 R 0 29871 29493 0 77 0 - 15887 - pts/1 00:00:00 ps
UID : 代表执行者的身份
PID : 代表这个进程的代号
PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
PRI :代表这个进程可被执行的优先级,其值越小越早被执行
NI :代表这个进程的nice值
这里的前面的三个信息,我们都是比较好容易理解的,但是后面的两个奇怪的信息,一个是PRI,一个是NI,这到底是什么东西?相对而言,PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值。如前面所说,PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice。这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行。
进程在创建时并不是平等的,他们被赋予不同的优先级值,例如有些对计算机本身的操作至关重要的程序必须比其他次要的程序具有更高的优先级(则其有更小的优先级值)。而如前面所说,nice的值是表示进程优先级值可被修正数据值,因此,每个进程都在其计划执行时被赋予一个系统nice值,这样系统就可以根据系统的资源以及具体进程的各类资源消耗情况,主动干预进程的优先级值。这个过程,用户也可手工干预其中,但是要被赋予相应的权限。
在UNIX系统或者LINUX系统中,使用从-20到+19的一个可变数值来表示这个nice值(LINUX和AIX是这种情况,HP-UX系统的值范围是从0到39),并且在通常情况下,子进程会继承父进程的系统nice值。具有最高优先级的程序,其nice值最低,所以在UNIX和LINUX系统中,值-20使得一项任务变得非常重要(HP-UX为0);与之相反,如果任务的 nice 为+19(HP-UX为39),则表示它是一个高尚的、无私的任务,允许所有其他任务比自己享有宝贵的 CPU 时间的更大使用份额,这也就是nice的名称的意会来意。
[root@master ~]# nice
0
root用户把nice加3.
[root@master ~]# nice -n 3 ls
123.txt Desktop install.log jrockit-jdk1.6.0_29-R28.1.5-4.0.1 MySQL-python-1.2.3.tar.gz Python-2.7.3.tgz setuptools-0.6c8.tar.gz vmtouch.c
anaconda-ks.cfg file1 install.log.syslog jrockit-jdk1.6.0_29.tar.gz part-00000.bz2 root soft yum_r.txt
cmake-2.8.7.tar.gz file2 integer.sh MySQL-python-1.2.3 Python-2.7.3 setuptools-0.6c8 vmtouch
而root用户就可以给其子进程赋予更小的nice值,如下:
0
[root@dbbak root]# nice -n -3 ls
anaconda-ks.cfg file1 install.log.syslog jrockit-jdk1.6.0_29.tar.gz part-00000.bz2 root soft yum_r.txt
cmake-2.8.7.tar.gz file2 integer.sh MySQL-python-1.2.3 Python-2.7.3 setuptools-0.6c8 vmtouch
对于后台进程,其nice会在其被显示赋予的值过后再加上4。如“nice 12 command &”命令执行时,则其会以nice=36值来运行程序(HP-UX系统)。这里有个问题,即如果用户设置的nice值超过了nice的边界值(LINUX和AIX为-20到19,HP-UX为0到39)会怎样,则系统就取nice的边界值作为进程的nice值。
与进程的nice相关的命令有2个,分别是nice和renice。
nice命令就是设置一个要执行command进程的nice值,其命令格式是 nice –n adjustment command command_option,这里就设置要执行的command的nice,如果这里不指定adjustment,则默认为10。
renice命令就是设置一个已经在运行的进程的nice值,如假设一运行进程本来nice值为0,renice为3后,则这个运行进程的nice值就为3了。renice的执行必须要有相应的权限方可执行。它可以根据用户、进程ID、进程组来设置进程的nice值。
对nice值一个形象比喻,假设在一个CPU轮转中,有2个runnable的进程A和B,如果他们的nice值都为0(如果是HP-UX则为20),加上内核会给他们每人分配1k个cpu时间片。但是假设进程A的为0,但是B的值为-10,那么此时CPU则会可能分别给A和B分配1k和1.5k的时间片。故可以形象的理解为,nice的值影响了内核分配给进程的cpu时间片的多少,时间片越多的进程,其优先级越高,其优先级值越低。
从使用top、ps等命令看到的nice值,就是进程所拥有的nice值,使用iostat等看到的%nice,就是用户进程空间中改变过优先级的进程的占用CPU的百分比,如上例中就说0.5k/2.5k=1/5=20%。
到目前为止,更需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。