阿里云云盾抗下全球最大DDoS攻击(5亿次请求,95万QPS HTTPS CC攻击)
摘要: 本文讲的是阿里云云盾抗下全球最大DDoS攻击(5亿次请求,95万QPS HTTPS CC攻击), 报告披露,去年11月,阿里云安全团队成功防御了黑客对阿里云平台上某互联网金融用户发起的超大规模HTTPS/SSL CC流量攻击,此次攻击也是迄今为止全球有统计数据最大的HTTPS SSL/CC攻击。 作为国内最大的公共云计算服务提
报告披露,去年11月,阿里云安全团队成功防御了黑客对阿里云平台上某互联网金融用户发起的超大规模HTTPS/SSL CC流量攻击,此次攻击也是迄今为止全球有统计数据最大的HTTPS SSL/CC攻击。
作为国内最大的公共云计算服务提供商,大量网站选择阿里云的安全防护,也因此为国内客户防御了当前互联网上主要的攻击行为。
攻击者从11月5日下午14点开始针对网站开始发起攻击,出现两次波峰分别在14点10和晚上7点30左右,总攻击量达到了5亿次请求。
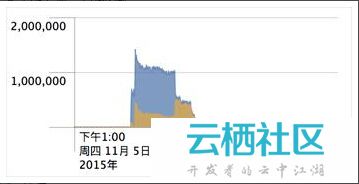
攻击请求QPS变化
通过日志数据分析,攻击特征如下:
(1)攻击聚焦首页;
(2)攻击IP在攻击的过程中,为了接近真实主机,攻击者伪造了UA和Referer字段以及Cookie;
此次攻击者攻击的目标网站是HTTPS类型,其对资源的性能消耗原本就比HTTP要高出许多,攻击者希望通过CC这类资源消耗型攻击,达到击穿网站性能瓶颈,从而使网站服务瘫痪。目前如此巨大的峰值为95万QPS 的HTTPS/SSL CC攻击,已远远超过国内大部分防护厂商系统的性能瓶颈。
最终,阿里云云盾高防系统成功防御了黑客攻击,保存了大量有效的攻击证据,为用户事后溯源追踪提供了资料。阿里云安全团队预测,随着越来越多的网站追求数据的安全性采用HTTPS协议进行流量传输,网站遭受到HTTPS CC攻击的可能性随之上升。由于对HTTPS协议的处理相对HTTP会消耗更多的资源,因此无论是网站运营者还是安全服务商在面对HTTPS CC资源消耗型攻击时,防护能力会面临巨大挑战。
事实上,进入2016年后,包括HTTPS CC攻击在内的DDoS攻击事件层出不穷。2月份,国外黑客组织对全球最大在线游戏对战平台之一的XBOX发起了大流量DDoS攻击,对业务造成了长达24小时的影响。3月初,国内游戏厂商亦遭到大流量DDoS攻击。这似乎宣告着2016年注定是不平凡的一年。

XBOX团队在长达24小时的对抗后,宣布业务恢复正常
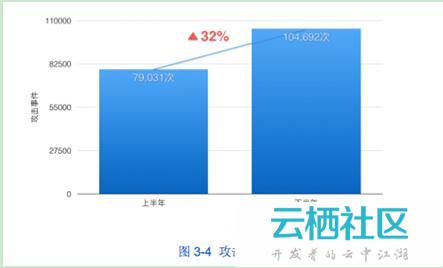
然而,这一切都只是已经过去的2015年不平凡的延续——2015年是DDoS攻击非常活跃的一年。根据阿里云安全团队发布的《2015下半年云盾互联网DDoS状态和趋势报告》,2015年共监测到近20万起DDoS攻击事件。对比上下半年的DDoS攻击事件数量,呈现下半年明显多于上半年的趋势(+32%)。
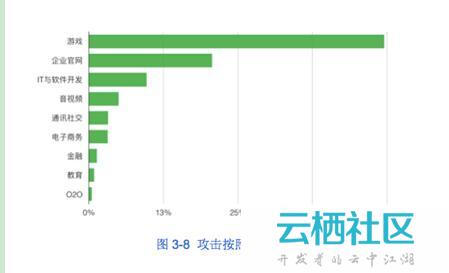
从被DDoS攻击骚扰的行业来看,游戏行业遭受的威胁最大,占到被攻击行业的近一半。游戏行业已经成为DDoS攻击最严重的重灾区。
阿里云云盾产品(http://click.aliyun.com/m/4232/)负责人吴翰清称,“我们预测在2016年整个互联网可能会发生流量在800Gbps-1TGbps之间的攻击事件。以商业竞争或敲诈勒索为背景的DdoS攻击威胁形势仍将严峻。游戏仍旧是DDoS事件高发行业。来自移动终端APP的应用层的DDoS攻击将迅速崛起。”
阿里云云盾从2015年Q3开始发布互联网DDoS状态和趋势报告。据云盾负责人介绍,云盾Anti-DDoS服务具备的Tb级别的防御带宽和攻击检测能力,以及阿里云大数据分析系统带来的PB级日数据处理和万亿量级会话分析能力。当前,阿里云云盾在全国已经部署了几十个清洗集群,保护了中国30%的网站。
完整下载《2015下半年云盾互联网DDoS状态和趋势报告》,请访问:
http://yundunddos-help.oss-cn-hangzhou.aliyuncs.com/%E4%BA%91%E7%9B%BE%E4%BA%92%E8%81%94%E7%BD%91DDoS%E7%8A%B6%E6%80%81%E5%92%8C%E8%B6%8B%E5%8A%BF%E6%8A%A5%E5%91%8A-2015H2-Final%20Version.pdf
技术如何秒懂你?阿里百万级QPS资源调度系统揭秘
阿里妹导读:TPP(Taobao Personalization Platform, 也称阿里推荐平台 ) 平台承接了阿里集团300+重要个性化推荐场景,包括手淘首页猜你喜欢、首图个性化、购物链路等。除了提供应用层面的支持和封装,还肩负着机器分配和维护各场景运行稳定的重任。
理想情况下,TPP平台上的场景owner不需要关注底层的资源分配情况,平台尽可能的提高CPU利用率,同时保证平台上场景的稳定。QPS(每秒查询率)增加的时候扩容,QPS减少的时候缩容,未来这些在夜间被拿掉的机器可以用来混部离线任务等;另外,在2016年双11的时候,总的机器数目不足以维持所有的场景以最高性能运行,需要有经验的算法同学判断场景的优先级,从低优先级的场景上拿出来机器,补充到高优先级的场景中保证成交额。这些平台稳定性工作都是需要繁琐的人工调度,会有如下的缺点:
-
人力成本巨大:人肉无法监控和处理所有的场景;
-
反应时间较长:从发现场景出问题,找出可以匀出机器的不重要场景,到加到重要场景所需要的时间相对过长,而程序天然的有反应时间短的优势;
-
人力无法全局高效的调度资源, 而程序可以更敏感的发现场景的问题,更全面的搜索可以拿出来机器的场景,并可以准确计算拿出机器的数目,有更好的全局观。
基于如上的两点:日常的时候提高资源利用率,大促的时候解放人力,TPP智能调度系统就产生了。TPP智能调度系统以每个集群(一组机器,承载一个或多个场景)的CPU利用率,LOAD,降级QPS,当前场景QPS,压测所得的单机QPS为输入,综合判断每个集群是否需要增加或者减少机器,并计算每个场景需要增减机器的确切数目,输出到执行模块自动增减容器。 TPP智能调度系统有如下的贡献点:
-
日常运行期间,保证服务质量的情况下最大化资源利用率;
-
大促运行期间,能够更快速、更准确的完成集群之间的错峰资源调度;
-
支持定时活动事件的录入,如红包雨、手淘首页定时的Push,程序自动提前扩容,活动结束自动收回;
-
对重要场景提前预热,完成秒级扩容。
该系统由TPP工程团队和猜你喜欢算同学联合搭建而成,从2017年9月开始规划,到10月1日小批量场景上线,到10月13日三机房全量上线;经过一个月的磨合,参加了2017年双11当天从 00:15 %到 23:59的调度,峰值QPS达到百万级别。在日常运行中,集群平均CPU利用率提高3.37 倍, 从原来平均8%到27%;在大促期间,完成造势场景,导购场景和购后场景的错峰资源调度,重要服务资源利用率保持在 30% ,非重要服务资源利用率保持在50%, 99%的重要场景降级率低于2%。同时TPP智能调度系统的"时间录入"功能支持定时活动,如首页红包的提前录入,提前扩容,活动结束收回机器,改变了以前每天需要定时手动分机器的情况。
问题定义与挑战
TPP智能调度系统要解决的问题为: 如何在机器总数有限的前提下,根据每一个场景上核心服务指标KPI(异常QPS等)和场景所在集群物理层指标KPI(CPU,IO等),最优化每一个场景机器数目,从而使得总体资源利用率最高。
更加直白一点,就是回答如下的问题:
-
怎么判断一个集群需要扩容?扩多少的机器
简单的CPU超过一定的水位并不能解决问题。不同的场景的瓶颈并不完全一致,有IO密集型的(如大量访问igraph),有CPU密集型的,一个场景可能在cpu不超过30%的情况下,就已经出现了大量的异常QPS,Load很高,需要增加机器。
-
如何给不同的场景自适应的判断水位?
有的场景30% CPU运行的很好,但是有的场景10%可能就出问题了。
-
如何防止某些实现有问题的场景,不停的出现异常,不断触发扩容,从而掏空整个集群,而实现效率较高的场景反而得不到机器,引发不公平。
-
如何用一套算法同时解决日常运行和大促运行的需求
当总的机器数目有限的情况下,如何分配不同场景之间的机器,最大化收益(有效pv)。如何用程序实现从某些场景拿机器去补充重要场景的运行。
-
对于运行JVM的容器,当一个新加容器在到达100%服务能力之前需要充分预热,预热过程会有异常QPS的产生。算法一方面要尽可能少的减少扩缩容的次数,另外一个方面,要尽可能快的发现扩容的需求,实现较高的扩容recall。如何在这两者之间做tradeoff?
系统架构
TPP智能调度涉及TPP的各方各面,其架构图如下所示,包括数据输入、算法决策和决策执行三个方面,但是为了更灵敏的、更及时的发现超载的场景并进行扩容,需要自动降级、秒级扩容、单机压测qps预估功能的保证。另外还有一些功能性的开发,如业务算法配置参数分离、调度大盘监控、烽火台规则运行平台等的支持。最底层的更加离不开容器化的全量部署 ,使得加减机器,快速部署环境成为了可能。
一般的服务器qps多少?
QPS
QPS即每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
每秒查询率
因特网上,经常用每秒查询率来衡量域名系统服务器的机器的性能,其即为QPS。
对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
计算关系:
QPS = 并发量 / 平均响应时间
并发量 = QPS * 平均响应时间
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 。
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器 。
案例分析:
每天300w PV 的在单台机器上,这台机器需要多少QPS?
( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)。
一般需要达到139QPS,因为是峰值。
如果一台机器的QPS是58,需要几台机器来支持?
139 / 58 = 3
我的淘宝之路17:TPS和QPS(转)
(2012-04-21 11:37:29) 转载▼
转载▼
标签: it |
分类: 淘宝数据库浅析 |
一、TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
TPS是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
二、QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
三、在DBA界,TPS和QPS是衡量数据库性能的2个重要参数。计算方法如下:
TPS(每秒事务处理量) INNODB 引擎
(com_commit+com_rollback)/uptime
QPS(每秒查询处理量)MyISAM 引擎
Questions/uptime
附:
TPS(Transaction per second) (每秒事务量,如果是InnoDB会显示,没有InnoDB就不会显示)
Read/Writes Ratio(数据库读写比率,对是否使用MySQL Replication还是使用MySQL Cluster很有参考价值。)
MyISAM Key buffer read ratio
MyISAM Key buffer write ratio
Slow queries per minute (平均一分钟多少慢查询)
Slow full join queries per minute(慢查询的比率)
Temp tables to Disk ratio (写到硬盘的临时表与所有临时表的比率,对性能有较大影响,说明有SQL使用了大量临时表)
系统吞吐量、TPS(QPS)、用户并发量、性能测试概念和公式
PS:下面是性能测试的主要概念和计算公式,记录下:
一.系统吞度量要素:
一个系统的吞度量(承压能力)与request对CPU的消耗、外部接口、IO等等紧密关联。单个reqeust 对CPU消耗越高,外部系统接口、IO影响速度越慢,系统吞吐能力越低,反之越高。
系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间
QPS(TPS):每秒钟request/事务 数量
并发数: 系统同时处理的request/事务数
响应时间: 一般取平均响应时间
(很多人经常会把并发数和TPS理解混淆)
理解了上面三个要素的意义之后,就能推算出它们之间的关系:
QPS(TPS)= 并发数/平均响应时间 或者 并发数 = QPS*平均响应时间
一个典型的上班签到系统,早上8点上班,7点半到8点的30分钟的时间里用户会登录签到系统进行签到。公司员工为1000人,平均每个员上登录签到系统的时长为5分钟。可以用下面的方法计算。
QPS = 1000/(30*60) 事务/秒
平均响应时间为 = 5*60 秒
并发数= QPS*平均响应时间 = 1000/(30*60) *(5*60)=166.7
一个系统吞吐量通常由QPS(TPS)、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下降。
决定系统响应时间要素
我们做项目要排计划,可以多人同时并发做多项任务,也可以一个人或者多个人串行工作,始终会有一条关键路径,这条路径就是项目的工期。
系统一次调用的响应时间跟项目计划一样,也有一条关键路径,这个关键路径是就是系统影响时间;
关键路径是有CPU运算、IO、外部系统响应等等组成。
二.系统吞吐量评估:
我们在做系统设计的时候就需要考虑CPU运算、IO、外部系统响应因素造成的影响以及对系统性能的初步预估。
而通常境况下,我们面对需求,我们评估出来的出来QPS、并发数之外,还有另外一个维度:日PV。
通过观察系统的访问日志发现,在用户量很大的情况下,各个时间周期内的同一时间段的访问流量几乎一样。比如工作日的每天早上。只要能拿到日流量图和QPS我们就可以推算日流量。
通常的技术方法:
1. 找出系统的最高TPS和日PV,这两个要素有相对比较稳定的关系(除了放假、季节性因素影响之外)
2. 通过压力测试或者经验预估,得出最高TPS,然后跟进1的关系,计算出系统最高的日吞吐量。B2B中文和淘宝面对的客户群不一样,这两个客户群的网络行为不应用,他们之间的TPS和PV关系比例也不一样。
A)淘宝
淘宝流量图:

淘宝的TPS和PV之间的关系通常为 最高TPS:PV大约为 1 : 11*3600 (相当于按最高TPS访问11个小时,这个是商品详情的场景,不同的应用场景会有一些不同)
B) B2B中文站
B2B的TPS和PV之间的关系不同的系统不同的应用场景比例变化比较大,粗略估计在1 : 8个小时左右的关系(09年对offerdetail的流量分析数据)。旺铺和offerdetail这两个比例相差很大,可能是因为爬虫暂的比例较高的原因导致。
在淘宝环境下,假设我们压力测试出的TPS为100,那么这个系统的日吞吐量=100*11*3600=396万
这个是在简单(单一url)的情况下,有些页面,一个页面有多个request,系统的实际吞吐量还要小。
无论有无思考时间(T_think),测试所得的TPS值和并发虚拟用户数(U_concurrent)、Loadrunner读取的交易响应时间(T_response)之间有以下关系(稳定运行情况下):
TPS=U_concurrent / (T_response+T_think)。
并发数、QPS、平均响应时间三者之间关系

上图横坐标是并发用户数。绿线是CPU使用率;紫线是吞吐量,即QPS;蓝线是时延。
开始,系统只有一个用户,CPU工作肯定是不饱合的。一方面该服务器可能有多个cpu,但是只处理单个进程,另一方面,在处理一个进程中,有些阶段可能是IO阶段,这个时候会造成CPU等待,但是有没有其他请 求进程可以被处理)。随着并发用户数的增加,CPU利用率上升,QPS相应也增加(公式为QPS=并发用户数/平均响应时间。)随着并发用户数的增加,平均响应时间也在增加,而且平均响应时间的增加是一个指数增加曲线。而当并发数增加到很大时,每秒钟都会有很多请求需要处理,会造成进程(线程)频繁切换,反正真正用于处理请求的时间变少,每秒能够处 理的请求数反而变少,同时用户的请求等待时间也会变大,甚至超过用户的心理底线。
来源:http://www.cnblogs.com/jackei/
软件性能测试的基本概念和计算公式
一、软件性能的关注点
对一个软件做性能测试时需要关注那些性能呢?
我们想想在软件设计、部署、使用、维护中一共有哪些角色的参与,然后再考虑这些角色各自关注的性能点是什么,作为一个软件性能测试工程师,我们又该关注什么?
首先,开发软件的目的是为了让用户使用,我们先站在用户的角度分析一下,用户需要关注哪些性能。
对于用户来说,当点击一个按钮、链接或发出一条指令开始,到系统把结果已用户感知的形式展现出来为止,这个过程所消耗的时间是用户对这个软件性能的直观印象。也就是我们所说的响应时间,当相应时间较小时,用户体验是很好的,当然用户体验的响应时间包括个人主观因素和客观响应时间,在设计软件时,我们就需要考虑到如何更好地结合这两部分达到用户最佳的体验。如:用户在大数据量查询时,我们可以将先提取出来的数据展示给用户,在用户看的过程中继续进行数据检索,这时用户并不知道我们后台在做什么。
用户关注的是用户操作的相应时间。
其次,我们站在管理员的角度考虑需要关注的性能点。
1、 相应时间
2、 服务器资源使用情况是否合理
3、 应用服务器和数据库资源使用是否合理
4、 系统能否实现扩展
5、 系统最多支持多少用户访问、系统最大业务处理量是多少
6、 系统性能可能存在的瓶颈在哪里
7、 更换那些设备可以提高性能
8、 系统能否支持7×24小时的业务访问
再次,站在开发(设计)人员角度去考虑。
1、 架构设计是否合理
2、 数据库设计是否合理
3、 代码是否存在性能方面的问题
4、 系统中是否有不合理的内存使用方式
5、 系统中是否存在不合理的线程同步方式
6、 系统中是否存在不合理的资源竞争
那么站在性能测试工程师的角度,我们要关注什么呢?
一句话,我们要关注以上所有的性能点。
二、软件性能的几个主要术语
1、响应时间:对请求作出响应所需要的时间
网络传输时间:N1+N2+N3+N4
应用服务器处理时间:A1+A3
数据库服务器处理时间:A2
响应时间=N1+N2+N3+N4+A1+A3+A2
2、并发用户数的计算公式
系统用户数:系统额定的用户数量,如一个OA系统,可能使用该系统的用户总数是5000个,那么这个数量,就是系统用户数。
同时在线用户数:在一定的时间范围内,最大的同时在线用户数量。
同时在线用户数=每秒请求数RPS(吞吐量)+并发连接数+平均用户思考时间
平均并发用户数的计算:C=nL / T
其中C是平均的并发用户数,n是平均每天访问用户数(login session),L是一天内用户从登录到退出的平均时间(login session的平均时间),T是考察时间长度(一天内多长时间有用户使用系统)
并发用户数峰值计算:C^约等于C + 3*根号C
其中C^是并发用户峰值,C是平均并发用户数,该公式遵循泊松分布理论。
3、吞吐量的计算公式
指单位时间内系统处理用户的请求数
从业务角度看,吞吐量可以用:请求数/秒、页面数/秒、人数/天或处理业务数/小时等单位来衡量
从网络角度看,吞吐量可以用:字节/秒来衡量
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力
以不同方式表达的吞吐量可以说明不同层次的问题,例如,以字节数/秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈;已请求数/秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈。
当没有遇到性能瓶颈的时候,吞吐量与虚拟用户数之间存在一定的联系,可以采用以下公式计算:F=VU * R /
其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间
4、性能计数器
是描述服务器或操作系统性能的一些数据指标,如使用内存数、进程时间,在性能测试中发挥着“监控和分析”的作用,尤其是在分析统统可扩展性、进行新能瓶颈定位时有着非常关键的作用。
资源利用率:指系统各种资源的使用情况,如cpu占用率为68%,内存占用率为55%,一般使用“资源实际使用/总的资源可用量”形成资源利用率。
5、思考时间的计算公式
Think Time,从业务角度来看,这个时间指用户进行操作时每个请求之间的时间间隔,而在做新能测试时,为了模拟这样的时间间隔,引入了思考时间这个概念,来更加真实的模拟用户的操作。
在吞吐量这个公式中F=VU * R / T说明吞吐量F是VU数量、每个用户发出的请求数R和时间T的函数,而其中的R又可以用时间T和用户思考时间TS来计算:R = T / TS
下面给出一个计算思考时间的一般步骤:
A、首先计算出系统的并发用户数
C=nL / T F=R×C
B、统计出系统平均的吞吐量
F=VU * R / T R×C = VU * R / T
C、统计出平均每个用户发出的请求数量
R=u*C*T/VU
D、根据公式计算出思考时间
TS=T/R
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 。
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器 。
每天300w PV 的在单台机器上,这台机器需要多少QPS?
( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)。
一般需要达到139QPS,因为是峰值。
聊聊QPS/TPS/并发量/系统吞吐量的概念
我们在日常工作中经常会听到QPS/TPS这些名词,也会经常被别人问起说你的系统吞吐量有多大。这个问题从业务上来讲,可以理解为应用系统每秒钟最大能接受的用户访问量。或者每秒钟最大能处理的请求数;
QPS: 每秒钟处理完请求的次数;注意这里是处理完。具体是指发出请求到服务器处理完成功返回结果。可以理解在server中有个counter,每处理一个请求加1,1秒后counter=QPS。
TPS:每秒钟处理完的事务次数,一般TPS是对整个系统来讲的。一个应用系统1s能完成多少事务处理,一个事务在分布式处理中,可能会对应多个请求,对于衡量单个接口服务的处理能力,用QPS比较多。
并发量:系统能同时处理的请求数
RT:响应时间,处理一次请求所需要的平均处理时间
计算关系:
QPS = 并发量 / 平均响应时间
并发量 = QPS * 平均响应时间