视频动作识别——TLE模型解读
Deep Temporal Linear Encoding Networks
这是CVPR2017的文章,主要提出了一种时序线性编码层(Temporal Linear Encoding, TLE)来对视频分段提取后的特征图进行融合编码,最后得到的效果相对来说已经很不错了。搜索的时候发现没有什么对它解读的文章,于是就自己看完来大概写一下。
TLE这篇文章认为,在一段视频中,连续帧之间的移动通常很微小,然后参考到IDT算法中对特征点密集采样并且使用光流来跟踪它们能够得到比较好的video representation,因此提出需要有一个对所有的帧进行综合编码而得到的video representation,从而才能够捕捉到长时间的动态过程。
TLE层的具体操作如下:

也就是说,TLE首先对一段视频,切割成K段,然后对每一段,让它通过一个CNN提取到CNN features,当然这K个CNN是权值共享的,然后对这K段的CNN features,首先用一个融合操作把它们糅合成一个features,然后对这融合后的features进行编码从而得到最终的video representation。
融合方法有:
- 逐元素平均:
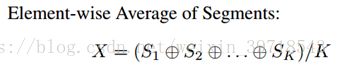
- 逐元素最大:

- 逐元素相乘:

然后通过实验发现,逐元素相乘的效果最好,因此选用它来作为融合的方法。
编码的方法有:
- 双线性模型:
双线性模型是对两张feature map做外积,如下:
![]()
其中,![]() 是输入的两张feature maps,在TLE中,X=X’。
是输入的两张feature maps,在TLE中,X=X’。![]() 表示做外积,W是模型的参数,是需要通过学习得到的,这里使用的参数是线性的,最后得到的
表示做外积,W是模型的参数,是需要通过学习得到的,这里使用的参数是线性的,最后得到的![]() 就是双线性特征。
就是双线性特征。
双线性特征能够捕捉所有空间位置上的特征间的相互作用,因此能够得到一个高维的特征表示。为了简化运算、减少参数量,作者使用了一个Tensor Sketch algorithm来对这个高维特征进行降维,从而避免了对外积的直接计算。模型的参数W是通过端对端的反向传播来学习的。
- 全连接池化层:
使用全连接层来连接融合后的feature maps和最后的分类器。
实验发现,相对于全连接池化层,双线性模型参数更少,同时还能够取得更好的分类效果。作者提出其实还可以使用deep fisher coding或者VLAD来进行编码。还有一个细节,当使用双线性模型时,特征是取的平方根,符号由y本身的符号来决定,并且还做了L2-normalization,使用softmax层作为分类器。
选取K=3,训练时的forward和backward过程如下:

其中backward的解释如下:
![]()
即在对Sk求导时将其表示成了![]() ,因此得到了如上的计算式。
,因此得到了如上的计算式。
在训练过程中,使用的是SGD的优化方法,模型参数是利用整段视频进行训练学习得到。
接下来是实现对比结果,一些算法的具体实现细节以及参数就不说了,都是一些比较常规的操作,包括图片的随机裁剪和去均值,学习率decay,模型预训练再微调等等,我们直接看实验的结果:
- 第一组对比实验是看三个融合函数的结果比较,这里统一使用的是BN-Inception来作为前面提取特征的CNN网络,使用双线性模型作为编码方式,仅仅是融合方式的不同:
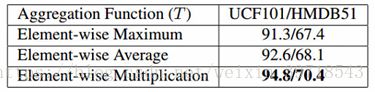
可以看到,使用逐元素相乘的融合方式的话效果最好。作者认为这是因为逐元素相乘的方式能够更加精确地融合appearance和motion的信息。
- 第二组对比实验是看使用不同的CNN结构来提取特征的结果比较,其他的结构保持一致:

可以看到,BN-Iception的效果最好,可能是因为这时候模型的深度更甚。
- 上述两组实验都是使用的双流网络,接下来使用C3D网络结构来直接提取特征再过TLE层,看三种融合方式的比较:

和之前一样,还是逐元素相乘的效果最好。
- 将使用BN-Inception+逐元素相乘融合的TLE模型与其他的视频动作识别算法结果进行比较如下:

其中倒数第二行的TS是指tensor sketch algorithm,也就是之前提到过的数据降维的方法。从上表可以看到,TLE的模型取得了当时state-of-art的结果,同时使用双线性模型的TLE的参数比起其它模型会少很多,训练起来更高效,并且效果也更好。
- 接下来作者做了一个验证实验,就是使用C3D+TLE层的模型来和其它使用3D卷积以及经典方法进行比较,目的是为了证明TLE层对于识别效果提升的有效性:

作者认为加入TLE后的C3D效果提升是因为能够使用视频数据里的长时间的多方面的时序信息来对动态的appearance和motion进行编码,从而能够得到更为准确的描述。
- 最后有一个额外的实验,在使用VGG-16+TLE结构进行视频动作识别时,添加一个在Places365数据集上预训练过的场景识别模块,即加入额外的信息来辅助识别,结果的确有些许的改进:

但是我觉得可能改进并不大或者会使得效果更差,因为作者也只列举了VGG情况下的结果,我相信他肯定做了其他网络结构的实验,但是估计效果并不是很好所以才没放出来哈哈哈~
最后总结一下,TLE的优点有一下三点:
- 将整个视频编码成一种压缩的特征表示,学习了语义信息和一种容易区分的特征空间;
- 可以灵活地添加到各种2D和3D的视频分类CNN中;
- 能无损地将特征间的相互关系用一种更有表现力的方式表达出来。
上面三点是文章自己总结的优点,我的感觉就是这种融合以及编码的方式能够更好地将视频段与段之间的关联性,特征与特征之间的相关性体现出来,因此比起纯粹的average score和fully connected能够取得更好的效果。最后一点感想,文章本身提出来的原创内容比较简单,一小part就说完了,然后靠讲了一两页纸的实验参数细节水起来的哈哈哈哈,好像get了一种凑字数的方法呢hiahia~