【论文笔记】Zero-Shot Open Entity Typing as Type-Compatible Grounding
Zero-Shot Open Entity Typing as Type-Compatible Grounding
文章目录
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Zero-Shot Open Entity Typing
- Definition 1:Weak Type compatibility.
- Definiton 2 (Context Consistency)
- 假设 1: 定义2是定义1的强有力推断
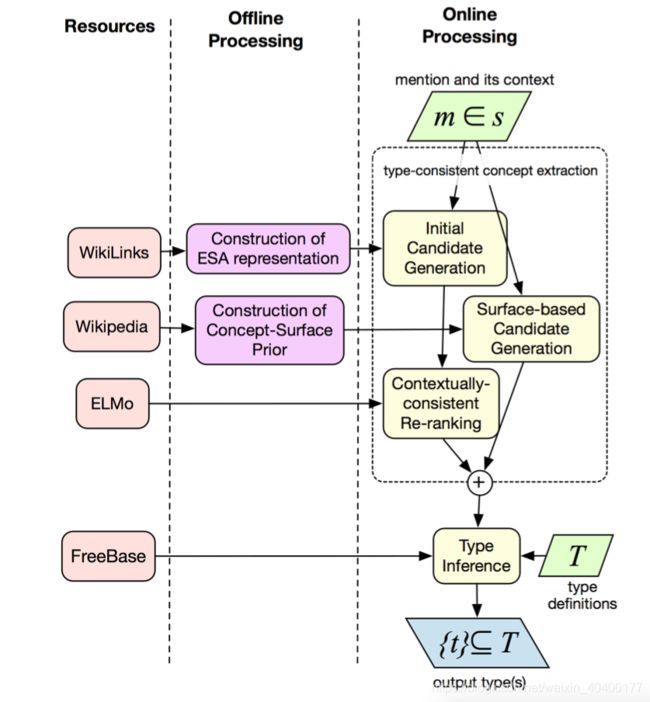
- 3.1 Initial Concept Candidate Generation
- Offline computation
- Online computation
- 3.2 Context-Consistent Re-Ranking
- 3.3 Surface-Based Concept Generation
- 3.4 Type Inference
感觉这篇文章和我们的setting是已有的文章里面非常接近的一篇。zero-shot确实比较接近open的情形。在这里仔细的阅读一下吧,今天读了5篇了,人有点晕了,半翻译半读,还可以坚持一下。
Abstract
Entity typing 这个问题广泛地研究,大部分情况是在监督的场景下,有着固定粒度的分类。比如细粒度的,比如粗粒度的。一些方法在数据集上表现不错,但是缺乏迁移能力,不能应对到新的taxonomy上。
—就是不能够很好的应对新的types。重新训练肯定是费时费力的。
因此提出zero-shot entity typing方法:
- 不需要标注的数据
- 灵活地标记新发现的关系类型
Setting基本如下:
给定一个type taxonomy,首先将一个给定的mention去寻找到一堆的type-compatible的维基百科上的entities。通过这些entities来进行推断这个mention所属于的一些type。
结果:
-
在细粒度和粗粒度的entity typing数据集上都表现的很好
-
和有监督学习的效果也差不多,在out-of-domain的数据集上取得比监督学校更好的效果
-
比其他的zero-shot细粒度typing方法效果好了非常多。
其实看到这里我有一个问题奥,如果只是根据type-compatible去匹配相似的entities,那么已有entities的一些type。如何制造出新的open的entities呢?
我自己现在的理解是,这里的open,并不是说真的open,只是说unlimited 的type inventory。不需要重新训练这样
1 Introduction
模型是ZOE
- open type definition

核心想法就是把mention匹配到一堆的type-compatible的entities。
原则是:type-compatible的entities是经常出现在相似的上下文之中。
为每一个mention找到有效的entity并不容易(entity linking)而且entity可能不存在于数据库之中
但是会每一个mention找到相似的entity。那还是非常有可能的。作者的假设是,每一个英文的entity,都能找到类似的entity types。
注意这里,不是需要匹配一个完全匹配的entity。完全匹配或者说一摸一样的entity,那就是entity linking了。
entity linking任务主要依赖于句子的表达和表述。此处的系统主要依赖context。
系统可以用于夸type taxonomy的
2 Related Work
zero-shot是2015年才用于entity-typing的。
Zero-shot的输出空间的定义是非常重要的,经常是高维空间的表征。 OTYPER
3 Zero-Shot Open Entity Typing
Definition 1:Weak Type compatibility.
两个entity在一个type taxonomy上,并且出现在同一个上下文中,共享至少一种类型。那么这两个entity是type-compatible的
为了去寻找type-compatible的entities,使用context of mention。
Definiton 2 (Context Consistency)
一个mention m m m与另一个mention m ′ m' m′是 上下文一致的,如果这二者可以在上下文中互相替代。并且句子仍然有逻辑
假设 1: 定义2是定义1的强有力推断
那么基于假设1,我们可以把mention m m m 链接到wiki相关的语料库,因为这些语料库可以和wikipedia相连接,所以可以通过wikipedia的entities types来进行标注。
意思就是 m m m 可以和wiki相关的语料库的context进行对比,对比完了可以通过wikipedia来获取type。
实际中,使用FREEBASE的类型来作为labels set。数据集是在7个数据集之上。

输出是一个type集合 { t T a r g e t } ⊆ T \{t_{Target}\} \subseteq T {tTarget}⊆T ,值得一提的是这边 T T T实际上是一个映射,从FREEBASE类型到目标类型的集合
T : { T F B } → { T T a r g e t } T: \{T_{FB}\} \rightarrow \{T_{Target}\} T:{TFB}→{TTarget} 举例来说,可以把location定义为FREEBASE中的location和geology两种类型的合集。
所以这个数据集的类型定义反映了对其的理解,把原本数据集中的类型进行处理。
如果将这个系统用于不同的数据集,不同的类型定义的时候。
t ∈ T t \in T t∈T代表是一个目标的类别。
3.1 Initial Concept Candidate Generation
这个方法主要的思路就是快速生成type-compatible的entities,所以用vector来代表维基百科上的concept/entities。这样retrieval更快。
WIKILINKS的每一个mention斗鱼wikipedia的concept相连接,这样可以通过wikilinks来选取 context。
Offline computation
为了加快运算,有一些计算是可以离线就可以预先处理好的
S : w → { c , s c o r e ( c ∣ w ) } S: w \rightarrow \{c, score(c|w)\} S:w→{c,score(c∣w)}
具体计算方法如下:
score ( c ∣ w ) ≜ ∑ s ∈ sent ( c ) ∑ w ∈ s tf-idf ( w , s ) \operatorname{score}(c \mid w) \triangleq \sum_{s \in \operatorname{sent}(c)} \sum_{w \in s} \operatorname{tf-idf}(w, s) score(c∣w)≜s∈sent(c)∑w∈s∑tf-idf(w,s)
tf-idf不介绍了,所以 w w w和 c c c的分数为:
concept c c c每一个例句中的单词 w w w的和
Online computation
对于一个mention和他的context,用offline的方式计算之后,可以集合起来变成加权的concepts。结果的concepts被排序,然后结果送往下一步。
3.2 Context-Consistent Re-Ranking
目前做了一些初步筛选,得到了一些与input mention相关的在wikilinks上的 concept mention。
这一步要通过句子上下文的信息,来encode mention的信息,而不是简单的通过上下文的格式匹配。这样信息会更丰富一下。
所以这里
C o n s i s t e n c y ( c , s , m ) = c o s i n e ( S e n t R e p ( s ∣ m ) , C o n c e p t R e p ( c ) ) Consistency (c, s, m)=\quad cosine ( SentRep (s \mid m), ConceptRep (c)) Consistency(c,s,m)=cosine(SentRep(s∣m),ConceptRep(c))
其中的 C o n c e p t R e p ( c ) ConceptRep(c) ConceptRep(c)是通过每一个 S e n t R e p ( s ∣ c ) SentRep(s|c) SentRep(s∣c)平均而来,那么就是希望这个mention与concept在的句子的平均encode信息接近。
这里encode使用的是ELMo
3.3 Surface-Based Concept Generation
至此考虑了context的word,语义,这边考虑mention的表面形式。如果mention本身表达或者包含出了一个entity,也许可以通过简单的概率先验公式就能准确匹配。(这个之前文章解读过)
3.4 Type Inference
inference算法先选择concept,然后推断粗粒度和细粒度的类型。
由于之前我们根据surface筛选了一些concepts,根据context也筛选了一些。
原则是如果 c s u r f c_{surf} csurf的confidence低于某个阈值,我们忽略掉。
否则, c s u r f c_{surf} csurf就从context选择的concept C E L M o C_{ELMo} CELMo中选择,只有粗和细粒度的类型。
为了映射这些选取的concept至目标entity类型。
使用每一个concept的FREEBASE-types,并采用类型定义 T T T
看到这里主要的问题就在与那个type definiton了。