Springboot 入门超简单小项目(看一点点视频课就可以上手)
在自己学springboot的过程中发现,现在网上的开源项目用的都是比较完整的技术栈,对于刚学了一点点springboot的知识,却又想搞个小项目练练手的同学非常不友好,于是自己搞了个阶段性的小项目,只用到了一些简单的数据库和模板技术,适合新手入门巩固知识
git链接
用到的知识:springboot整合mysql(数据库配置总要会写把),整合mybatis(差不多知道就行),模板知识,jsoup(爬虫,不会也没事)
首先先说一下项目的整体思路,这是一个小说网站的爬取工具,输入一本小说的第一章,能返回整本小说的txt文件。(是不是比什么学生管理系统有趣一点!当然为了避免给网站带来过大的访问压力,只爬取前五章)
首页大概是这样:
可以在首页加入推荐,从数据库里得到下载量最大的几个小说名称放在首页,练练模板的渲染(本文未加入)
先写依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.0.RELEASEversion>
<relativePath/>
parent>
<groupId>DataTestgroupId>
<artifactId>demoartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>demoname>
<description>Demo project for Spring Bootdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
<version>2.2.7.RELEASEversion>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.18version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
<version>2.3.0.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-beansartifactId>
<version>5.2.6.RELEASEversion>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.12.1version>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.1version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
然后是我的项目的层次
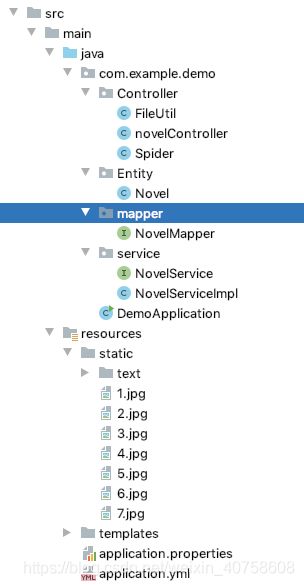
如果感觉有点复杂可以先看一下这篇:
springboot整合Mybatis
我的mapper层和service层都是按这里写的
yml文件:
spring:
datasource:
username: root
password: 31284679
url: jdbc:mysql://localhost:3306/czh?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:
type-aliases-package: com.example.demo.Entity
然后先看Controller层
package com.example.demo.Controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.activation.MimetypesFileTypeMap;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.sql.SQLException;
@org.springframework.stereotype.Controller
public class novelController {
//爬虫类
@Autowired
private Spider spider;
//首页
@RequestMapping("/")
public String index(){
return "index";
}
//下载页
@RequestMapping("/download")
public String data(String url,Model model) throws SQLException, IOException, ClassNotFoundException {
//调用爬虫类的启动方法
spider.start(url);
//在model中加入属性
model.addAttribute("name",spider.novleName);
//返回download.html
return "download";
}
//对应下载请求
//这部分是我找的网上的下载代码 链接是 https://blog.csdn.net/weixin_38168947/article/details/88082442
@RequestMapping("/file")
@RestController
public class FileDealController {
@RequestMapping(value = "filename")
public void download(
@RequestParam("fileName") String filename
) throws IOException {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletResponse response = requestAttributes.getResponse();
// 设置信息给客户端不解析
String type = new MimetypesFileTypeMap().getContentType(filename);
// 设置contenttype,即告诉客户端所发送的数据属于什么类型
response.setHeader("Content-type",type);
// 设置编码
String hehe = new String(filename.getBytes("utf-8"), "iso-8859-1");
// 设置扩展头,当Content-Type 的类型为要下载的类型时 , 这个信息头会告诉浏览器这个文件的名字和类型。
response.setHeader("Content-Disposition", "attachment;filename=" + hehe);
FileUtil.download(filename, response);
}
}
}
这里总共有三个对应的请求,分别是首页,下载页和下载请求
下载的部分
首页没啥好说的,然后爬虫类中完成了主要的爬取任务
爬虫类的代码:
package com.example.demo.Controller;
import com.example.demo.Entity.Novel;
import com.example.demo.service.NovelServiceImpl;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.sql.SQLException;
@Component
public class Spider {
@Autowired
private NovelServiceImpl novelService;
//小说名称
String novleName;
//启动方法
public void start(String url) throws IOException, SQLException, ClassNotFoundException {
//(不用看)findHref方法是找到小说的部分超链接 只爬取前五章的话用不到这个
String constent = findHref("章节目录", url);
//findName方法是找到小说的名称
String name=findname(url,constent);
novleName=name;
//不需要看这个 是用来找到这本小说什么时候结束
String end = "http://www.yuetutu.com" + constent;
//是否已经在数据库里
if (!ifInDB(name)){
//没有的话就爬一下
String text=FindNovle(name,url,end);
//把内容插入数据库
insertToDatabase(name,text);
}
else {
//如果已经爬过了就创造出txt文件
createTXT(name);
}
}
public void createTXT(String name) throws IOException {
//txt文件的路径
String pathname=System.getProperty("user.dir")+"/src/main/resources/static/text/"+name+".txt";
File file = new File(pathname);
FileWriter fwriter = null;
System.out.println(file);
if (!file.exists()) {
file.createNewFile();
String text=novelService.queryContent(name);
fwriter = new FileWriter(pathname);
fwriter.write(text);
fwriter.flush();
fwriter.close();
}
else {
return;
}
}
//查询是否已经在数据库里面了
public boolean ifInDB(String name){
try {
Novel novel=novelService.queryOne(name);
int times=novel.getDownloadtimes();
novelService.update(name);
System.out.println("haha");
return true;
}
catch (Exception e){
return false;
}
}
//插入数据库中
public boolean insertToDatabase(String name,String content){
Novel novel=new Novel();
novel.setName(name);
novel.setContent(content);
novel.setDownloadtimes(1);
novelService.insertNovel(novel);
return true;
}
/************************爬取主方法开始**************************/
public String FindNovle(String name,String url,String end) throws IOException, SQLException, ClassNotFoundException {
String Textcontent="";
String pathname=System.getProperty("user.dir")+"/src/main/resources/static/text/"+name+".txt";
File file = new File(pathname);
System.out.println(file);
file.createNewFile();
Writer out = new FileWriter(file);
int over=0;
while (over<5) {
Document document = Jsoup.connect(url).get();
String title = document.title();
Elements elements = document.select("div[id=content]");
for (Element element : elements) {
String rawText = element.text() + "\n" + "\n";
String text = rawText.replace(" ", "\n");
out.write(title);
out.write(text);
Textcontent=Textcontent+text;
}
String next = "http://www.yuetutu.com" + findHref("下一章", url);
over++;
url=next;
// if (next.equals(end)) {
//
// out.close();
// break;
// } else {
// url = next;
// }
}
out.close();
//setDatabase(name, pathname);
return Textcontent;
//}
//catch (Exception e){
/*System.out.println("爬取出现了问题");
return "错误";*/
}
/*********************************爬取辅助方法****************************/
public static String findname(String starturl, String constent) throws IOException {
Document test = Jsoup.connect(starturl).get();
Elements xx=test.select("a[href="+constent+"]");
String end="";
for( Element element : xx ){//拿到小说名字
end=element.text();
break;
}
return end;
}
public static String findHref(String name,String starturl) throws IOException {
Document test = Jsoup.connect(starturl).get();
Elements xx=test.select("a[href~=^/cbook]");
String end="";
for( Element element : xx ){//拿到章节目录的超链接
if (element.text().equals(name)){
end=element.attr("href");
break;
}
}
return end;
}
}
然后写一下模板吧
index:
<head>
<meta charset="UTF-8">
<title>czh的第一个项目title>
head>
<style th:inline="text">
body{
background-image: url("/static/3.jpg");
background-size:100% 100% ;
}
h1{
font-size:54px;
color:#ffff;
}
h2{
font-size:30px;
color: #ff0000;
}
h6{
font-size:24px;
color:#ffff;
}
h5{
font-size:55px;
color:transparent
}
style>
<body >
<div style="text-align: center;">
<table width="100%" border="0">
<tr>
<h5>占位符h5>
tr>
<tr>
tr>
<tr>
<td align="center" width="90%"><h1>欢迎使用在线阅读网站小说爬取工具h1>td>
tr>
<tr>
<td align="center" width="90%"><h6>本站可提供小说的txt格式下载h6>td>
tr>
<tr>
<td width="50%" align="center">
<h2>
在使用前请复制小说网站某一本小说的第一章的链接,粘贴到下面的文本框中并点击确定
h2>
td>
tr>
<tr>
<td width="100%" align="center">
<form name="form1" action="download" method="get" >
<input name="url" type="text" style="width:600px; height:40px;" /><br>
<input type="button" width="200" align="center" value="确定" style="width:90px;height:50px" onclick="check()">
form>td>
<script language="JavaScript">
function check(){
if(form1.url.value==""){
alert("请输入链接!")
}
else{
form1.submit()
alert("正在爬取........请勿关闭页面")
}
}
script>
tr>
<tr>
<td height="200" width="100" align="center"><h6>跳转页面后点击下载链接下载h6>td>
tr>
<tr>
<td height="200" width="100" align="center"><a href="">a> <h5>h5>td>
tr>
table>
div>
body>
html>
download:
这里用到了th的超链接拼接和取出model里的字典对
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<title>下载地址title>
head>
<style>
h1{
font-size:54px;
color:#FFF;
}
h2{
font-size:45px;
color:#FFF;
}
style>
<body style=" background-repeat:no-repeat;background-image: url(static/3.jpg);background-size:cover">
<div style="text-align: center;">
<h1>请点击下面的链接下载h1>
<a th:href="@{'/file/filename?fileName='+${name}+'.txt'}" >
<h2 >
<span th:text="${name}">span>.txt
h2>
a>
div>
body>
html>