【图文教程】监控系统命令
监控系统命令
- 1. w命令
- 2. vmstat命令
- 3. top命令
- 4. sar命令
- 5. nload命令
- 6. 监控io性能
- iostat命令
- iotop命令
- 7. free命令
- 8. ps命令
- 9. netstat命令
- tshark命令
- 11. Linux网络相关命令
- 12. 扩展
1. w命令
w含义:用于显示已经登陆系统的用户列表,并显示用户正在执行的指令。执行这个命令可得知目前登入系统的用户有那些人,以及他们正在执行的程序。单独执行w命令会显示所有的用户,您也可指定用户名称,仅显示某位用户的相关信息。
学习如何监控系统状态,是因为作为一个运维工程师需要了解 Linux 系统运行时的各种信息和状态,当出现问题的时候就能够查找出问题的所在,这样才能对症下药的去解决。
- w 命令可以查看当前系统的负载
相信所有的 linux 管理员最常用的命令就是这个 w 了,该命令显示的信息还是蛮丰富的。我们最应该关注的应该是第一行中的 load average :后面的三个数值,第一个数值表示 1 分钟内系统的平均负载值;第二个数值表示 5 分钟内系统的平均负载值;第三个数值表示 15 分钟系统的平均负载值。

[root@sc ~]# w
12:45:05 up 1:50, 2 users, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 10:56 1:48m 0.05s 0.05s -bash
root pts/0 192.168.94.1 10:57 1.00s 0.10s 0.00s w
第一行显示系统的汇总信息,字段分别表示系统当前时间、系统运行时间、登陆系统用户总数及系统平均负载信息。对于如上图显示的字段意义为:
12:45:05 #表示执行 w 的时间是在下午12点45分05秒。
up 1:50 #表示系统运行1小时50分。
2 users #表示当前系统登陆用户总数为 2。
load average: 0.00, 0.01, 0.05 #与后面的数字一起表示系统在过去 1,5,10 分钟内的负载程度,数值越小,系统负载越轻。
从第二行开始构成一个登录用户信息列表,共有8个栏目,分别显示各个用户正在做的事情及该用户所占用的系统资源:
USER #显示登陆用户帐号名。用户重复登陆,该帐号也会重复出现。
TTY #用户登陆所用的终端。
FROM #显示用户在何处登陆系统。
LOGIN@ #是 LOGIN AT 的意思,表示登陆进入系统的时间。
IDLE #用户空闲时间,从用户上一次任务结束后,开始记时。
JCPU #以终端代号来区分,表示在这段时间内,所有与该终端相关的进程任务所耗费的 CPU 时间。
PCPU #指 WHAT 域的任务执行后耗费的 CPU 时间。
WHAT #表示当前执行的任务。
查看某用户是否登陆系统用户很多的时候,可以在 w 后面加上某个用户名,则会查看该用户执行任务的情况。

- 使用 cat /proc/cpuinfo 此命令可查看系统的 CPU 数量,显示的是逻辑 CPU 数量,不是物理 CPU 数量
如果CPU 数量为 0 那么数值不超过 1 是最理想,也就是说负载数值不超过 CPU 的数量是最好的,如果负载数值大于 CPU 数量的话,那么就会有进程需要进行等待。

- lscpu命令 查看 cpu 汇总详细信息
[root@master proc]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 1
On-line CPU(s) list: 0
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 61
Model name: Intel(R) Core(TM) i5-5257U CPU @ 2.70GHz
Stepping: 4
CPU MHz: 2699.797
BogoMIPS: 5399.59
Hypervisor vendor: VMware
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 3072K
NUMA node0 CPU(s): 0
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap xsaveopt arat spec_ctrl intel_stibp flush_l1d arch_capabilities
- uptime 命令也能够查看系统负载情况,不过查看不了用户的登录信息,所以大部分情况下都是用 w 命令

2. vmstat命令
vmstat介绍:可对操作系统的虚拟内存、进程、CPU活动进行监控。是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析(综合工具,断定瓶颈点)。
- 当系统负载值偏高的时候,CPU 不够用了,想要知道是哪些进程在使用着 CPU,可以使用 vmstat 命令查看

- 一般使用 vmstat 命令的时候会加个数字 1 ,表示每一秒显示一次,动态的显示信息也可以
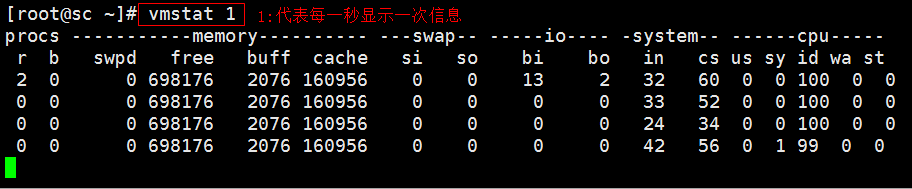
- 也可以再加一个数字定义显示几次就结束,例如我只需要显示 5 次就结束

[root@sc ~]# vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 698288 2076 160956 0 0 13 2 32 60 0 0 100 0 0
0 0 0 698288 2076 160956 0 0 0 0 55 74 0 0 100 0 0
0 0 0 698288 2076 160956 0 0 0 0 37 53 0 1 99 0 0
0 0 0 698288 2076 160956 0 0 0 0 30 34 0 0 100 0 0
0 0 0 698288 2076 160956 0 0 0 0 31 47 0 0 100 0 0
Procs(进程):
r:(run,运行) 表示运行或等待 CPU 时间片的进程数。
b:(block,块)表示等待资源的进程数,这个资源指的是 I/O、内存等。
Memory(内存):
swpd:当内存不够时,系统可以拿出内存总的一部分数据临时放到 swap 交换分区里去。如果 swpd 值一直交换时,说明交换分区和内存在频繁的交换数据,代表内存不够了。
free:表示当前空闲的内存数量,单位为 KB。
buff:表示(即将写入磁盘的)缓冲大小,单位为 KB。
cache:表示(从磁盘中读取的)缓存大小,单位为 KB。
swap(虚拟磁盘交换分区):
si:有多少 k 的块数据,从 swap 进入到内存中。
so:有多少 k 的块数据,从内存中进到 swap。
注意:如果 swpd 在频繁变换时,这两个值肯定也会变动。
IO(磁盘):
bi:有多少 k 的数据,从磁盘进入到内存中。
bo:有多少 k 的数据,从内存吸入到磁盘。
注意:随机磁盘读写的时候,这 2 个值越大(如超出1024k),能看到 CPU 在 IO 等待的值也会越大。
system(系统):
in:表示在某一时间间隔内观测到的每秒设备的中断次数。
cs:表示每秒产生的上下文切换数。
注意:这两个数值很大时,说明磁盘再频繁的读写。跟 CPU 和内存比,磁盘是很慢的,如果很频繁的读些数据会导致 b 列的增加。因为有很多进程在等待磁盘。
CPU(以百分比表示):
us:用户级别的,数字不会超过 100,百分比表示用户的资源占用 CPU 的百分比,
如果数字大于 50,说明系统肯定资源不够。
sy:系统本身的一些进程、服务、占用资源的百分比。
id:表示 CPU 处于空闲状态的时间百分比,us+sy+id+wa=st=100。
wa:wait 有多少进程在等待 CPU 的百分比。
st:表示被偷走的 CPU 所占百分比(一般都为0,不用关注)。
3. top命令
top含义:是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
- top 命令可以具体查看进程使用资源情况,top 命令是三秒钟更新一次信息,是动态显示的

[root@sc ~]# top
top - 14:56:20 up 1:28, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 99 total, 1 running, 98 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1005628 total, 706416 free, 138456 used, 160756 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 695476 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
第一行:top - 14:56:20 up 1:28, 3 users, load average: 0.00, 0.01, 0.05
14:56:20:当前时间。
up 1:28:系统已运行的时间。
3 users:当前登录用户的数量。
load average: 0.00, 0.01, 0.05:相应最近1、5和15分钟内的平均负载。
第二行:Tasks: 99 total, 1 running, 98 sleeping, 0 stopped, 0 zombie
系统现在total(共计)99个进程。
其中处于running(运行)中的有1个。
98个在休眠(sleep)。
stoped状态的有0个。
zombie状态(僵尸)的有0个。
第三行:%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
us #user,运行(未调整优先级的) 用户进程的CPU时间
sy #system,运行内核进程的CPU时间
ni #niced,运行已调整优先级的用户进程的CPU时间
wa #IO wait,用于等待IO完成的CPU时间
hi #处理硬件中断的CPU时间
si #处理软件中断的CPU时间
st #这个虚拟机被hypervisor偷去的CPU时间
(译注:如果当前处于一个 hypervisor 下的 vm ,实际上 hypervisor 也是要消耗一部分 CPU 处理时间的)。
第四行:KiB Mem : 1005628 total, 706416 free, 138456 used, 160756 buff/cache
Men物理内存:
1005628k total — 物理内存总量(1005M)
706416k free — 空闲内存总量(706M)
138456k used — 使用中的内存总量(138M)
160756k buff/cache — 缓存的内存量 (106M)
第五行:KiB Swap: 2097148 total, 2097148 free, 0 used. 695476 avail Mem
Swap交换分区:
2097148k total — 交换区总量(2097M)
2097148k free — 空闲交换区总量(2097M)
0k used — 使用的交换区总量(0)
695476k avail Mem — 可用内存(69M)
第六行:PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
PID:进程 ID,进程的唯一标识符
USER:进程所有者的实际用户名。
PR:进程的调度优先级,这个字段的一些值是 'rt' ,这意味这这些进程运行在实时态。
NI:进程的 nice 值(优先级)。越小的值意味着越高的优先级。负值表示高优先级,正值表示低优先级
VIRT:进程使用的虚拟内存。进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES:驻留内存大小,驻留内存是任务使用的非交换物理内存大小,进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR:SHR 是进程使用的共享内存。共享内存大小,单位 kb
S:这个是进程的状态。它有以下不同的值:
D - 不可中断的睡眠态。
R – 运行态
S – 睡眠态
T – 被跟踪或已停止
Z – 僵尸态
%CPU:自从上一次更新时到现在任务所使用的 CPU 时间百分比。
%MEM:进程使用的可用物理内存百分比。
TIME+:任务启动后到现在所使用的全部 CPU 时间,精确到百分之一秒。
COMMAND:运行进程所使用的命令。进程名称(命令名/命令行)
还有许多在默认情况下不会显示的输出,它们可以显示进程的页错误、有效组和组 ID 和其他更多的信息。
- top 里按 Shift+m 使用内存使用率来排序,同样的是由高到低
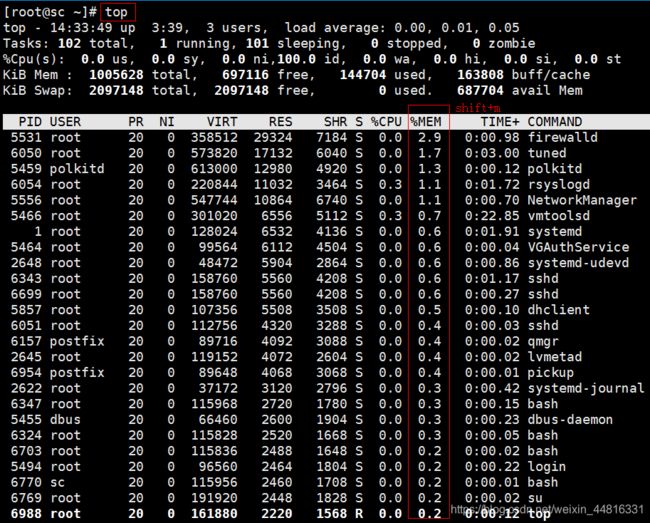
- top 里按 Shift+p 切换回按CPU排序

- top 里按数字 1,会列出所有的逻辑 CPU 使用情况

再按 1 则切换回平均值的查看方式:

- top -c 可以看到具体的进程、命令、全局的路径

- top -bn1 可以静态地显示,会一次性地把所有的进程信息都列出来,一般适合在写脚本的时候使用

4. sar命令
sar介绍:监控系统状态(外号:瑞士军刀)。
- sar 是一个非常全面的分析系统状态的命令,sar 被称做 Linux 系统里的“瑞士军刀”,也即是说这个命令的功能非常的复杂和丰富,如果你的系统里没有这个命令,则需要安装 sysstat 包
[root@sc ~]# yum install -y sysstat
下载完使用这个命令可能会出现无法打开文件的情况,这是因为 sar 命令不加任何选项的话,会默认调用它在系统中保留的历史文件。
/var/log/sa/ 路径是 sar 命令生成历史文件的目录,sar 有一个特性会每 10 分钟把系统的状态保存到文件里,而这个文件就会放在这个路径下。

现在再直接执行 sar 命令就不会报错了:

因为在 /var/log/sa/ 路径下已经生成了历史文件,sa12 文件和 sar12 文件有一些区别,sa12 文件是二进制文件不能直接 cat,sar12 文件则是可以直接 cat 查看的:
[root@sc ~]# ls /var/log/sa/sar12
- sar -n DEV 查看网卡流量,用法和 vmstat 类似,后面跟1 2 表示每隔 1 秒显示一次,显示 2 次

[root@sc ~]# sar -n DEV 1 2
Linux 3.10.0-957.el7.x86_64 (sc) 2019年04月12日 _x86_64_ (1 CPU)
17时23分06秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
17时23分07秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时23分07秒 ens33 2.02 2.02 0.12 0.24 0.00 0.00 0.00
17时23分07秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
17时23分08秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时23分08秒 ens33 2.00 2.00 0.16 0.46 0.00 0.00 0.00
平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
平均时间: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: ens33 2.01 2.01 0.14 0.35 0.00 0.00 0.00
第一列 #时间。
第二列 #IFCE 网卡名字。
第三列 #rxpck/s 接受到的数据包,单位个数,几千正常,上万就不正常了。
第四列 #txpck/s 发送出去的数据包。
第五列 #rxkB/s 接收的数据量,单位 KB。
第六列 #txkB/s 发送的数据量。
第七列 #rxcmp/s 不需要关注。
第八列 #txcmp/s 不需要关注。
第九列 #rxmcst/s 不需要关注。
- sar -n DEV 命令加 -f 选项就可以选择查看 /var/log/sa/ 路径下的历史文件,这个历史文件的命令是有规律的,文件名称的结尾是当天的日期,所以可以利用历史文件来查看历史网卡流量数据,有一点要注意的是这个目录下的文件最多保留一个月就会被自动清除

- sar -q 查看系统负载

如果需要查看 11 号的历史系统负载情况:
[root@sc ~]# sar -q -f /var/log/sa/sa11
- sar -b 查看磁盘负载

5. nload命令
nload含义:查看网卡流量。
- nload 命令能够更加直观的查看网卡流量,nload 命令默认是没有安装的,需要安装 nload 包,但是安装 nload 包之前要安装 epel-release 包,因为我之前已经安装过 epel-release 包了,所以我就直接安装 nload 包
[root@sc ~]# yum install epel-release #安装扩展包
[root@sc ~]# yum install -y nload

第一行显示网卡名字、IP、网卡其中之一,可以按右方向键切换网卡,按q退出。
Incoming #进来带宽。
Outgoing #出去带宽。
curr #当前值。
Avg #平均值。
Min #最小值。
Max #最大值。
Ttl #总和。
6. 监控io性能
iostat命令
iostat含义:被用于监视系统输入输出设备和CPU的使用情况。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。
磁盘的 io 是一个非常重要的指标,所以要更详细的查看磁盘状态,需要用到 iostat 命令,如果之前已经安装了 sysstat 包的话,在安装 sysstat 包时 iostat 命令就已经被安装了。
- 在安装 sysstat 包时,默认会安装iostat 包,和 sar 在同一个包里,iostat 直接回车可以查看到当前磁盘的信息

[root@sc ~]# iostat
Linux 3.10.0-957.el7.x86_64 (sc) 2019年04月12日 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.09 0.00 0.21 0.06 0.00 99.64
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
scd0 0.00 0.03 0.00 1028 0
sda 0.35 7.53 3.06 243701 99062
sdb 0.01 0.29 0.00 9304 0
[root@sc ~]#
Device #那列则是磁盘名称。
kB_read/s #表示每秒的读取速度。
kB_wrtn/s #表示每秒的写入速度。
- 加上数字 1 则可以动态的每秒更新一次信息

- iostat 重要的是 -x 选项,重要指标:%util 表示磁盘的使用百分比,如果这个数字很大,比如长期超过90%,说明磁盘非常忙,读写肯定也会很大,如果读写不大,但该列值很大,就说明硬盘有问题

iotop命令
iotop含义:是一个用来监视磁盘I/O使用状况的top类工具。
- iotop 命令可以看到哪个进程在频繁读写磁盘,这个命令默认是没有的,需要安装
[root@sc ~]# yum install -y iotop
- iotop 和 top 命令类似,也是动态显示的界面,只不过 iotop 是用来查看进程对磁盘的使用率的,而 top 则是用来查看进程对 CPU 的使用率的

7. free命令
free介绍:显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
- free 是直接查看内存使用情况的命令,CentOS7 和 CentOS6 的显示信息不一样,CentOS7 要更直观一些

第一行是说明。 (红色)
第二行是内存的使用情况。 (绿色)
第三行是Swap交换分区的使用情况。 (蓝色)
total #内存总大小,单位KB。
used #真正使用的实际内存大小。
free #剩余物理内存大小(没有被分配,纯剩余)。
shared #共享内存大小,不用关注它。
buff/cache #分配给 buffer(缓冲)和 cache(缓存)的内存总共有多大。
available #系统可使用内存有多大,它包含了free 和 buffer/cache 剩余部分。
- free -m 把内存大小单位以 MB 来表示

- free -g 把内存大小单位以 G 来表示

- free -h 更直观的查看大小单位

- 从显示的信息可以看到一个现象,使用大小和剩余大小的值加起来不等于内存的总大小,这是因为 Linux 操作系统会把内存分配一些出来分给 buff/cache。buff 是缓冲,CPU 计算完的数据要想存到磁盘里,会先进入到内存中,最后通过内存缓冲再存储到磁盘里。cache 是缓存,磁盘的数据进入到 CPU 之前会先经过内存最后才到 CPU,通过内存到 CPU 这一段就是缓存。
示意图:缓存和缓冲的区别就是数据的流向不一样,前者是从磁盘通过内存到CPU,后者是从CPU通过内存到磁盘。
因为内存担任一个这么重要的角色,所以Linux操作系统才预留出一些内存空间分给 buff/cache。
所以计算 total 的值的公式是:total=used+free+buff/cache
available列的值是free列加上buff/cache列的大小,表示剩余部分的内存,所以 available 才是内存真正的剩余大小。

8. ps命令
ps含义:查看系统进程。
- ps aux 是静态的,一次性把系统当前所有进程列出来

[root@sc ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.6 128024 6660 ? Ss 4月12 0:03 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 4月12 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 4月12 0:01 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 4月12 0:00 [kworker/0:0H]
root 7 0.0 0.0 0 0 ? S 4月12 0:00 [migration/0]
root 8 0.0 0.0 0 0 ? S 4月12 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? R 4月12 0:01 [rcu_sched]
root 10 0.0 0.0 0 0 ? S< 4月12 0:00 [lru-add-drain]
第一列: #(USER)是进程的用户名称
第二列: #(PID)是进程的PID,在杀进程或者系统被黑了,发现有个恶意进程,这时可以通过这个进程的PID找到这个进程的所在目录,例如我要找一个PID为912的进程所在目录:
第三列: #(%CPU)是CPU占用率,
第四列: #(%MEM)是内存占用率,
第五列: #(VSZ)是虚拟内存,
第六列: #(RSS)是物理内存,
第七列: #(TTY)表示进程在哪一个TTY上,
第八列: #(STAT)是需要关注的一列,表示的是进程的状态,
第九列: #(START)是进程的启动时间,
第十列: #(TIME)表示进程运行了多长时间,
第十一列: #(COMMAND)是命令名称,和top的最后一列是一样的。
STAT进程状态说明:
D 表示不能中断的进程,如果此状态的进程很多那么系统负载就会比较高。
R 表示run(运行中)状态的进程,在某一段时间内在使用着CPU的进程。
S 表示sleep状态的进程,使用完CPU会暂停、休息一下,过一会就会激活,激活后就会继续使用CPU。
T 表示暂停的进程,使用Ctrl+z暂停的进程。
Z 表示僵尸进程,系统运行过程中残留的一些无用的子进程。
< 表示高优先级进程,就是能够优先使用CPU的进程。
N 表示低优先级进程,与高优先级进程相反。
L 表示内存中被锁了内存分页。
s 表示主进程。
l 表示多线程进程,线程和进程不一样,一个进程里可以有多个线程,并且线程之间的内存是可以共享的,而进程之间则是互相独立的内存不可以共享。
+ 表示前台进程,会显示到终端上的进程,例如 grep、cat、less 等。
- ps aux |grep 进程名称,检查某一个进程有没有运行

- ps -elf 类似于 ps aux,把系统进程列出来

- kill 是杀死一个进程命令,配合 ps aux |grep 进程名称查看是否执行

- 查看进程所在目录 ls -l /proc/ 进程的 PID

9. netstat命令
netstat含义:查看网络状态。
netstat 命令是用来查看网络状态的,Linux 系统我们通常把它作为服务器的操作系统,服务器里有很多服务与客户端进行交互通信,也就意味着也要有监听端口、通信端口。那么 netstat 命令查看到的就是 tcp/ip 通信的一个状态。
没有端口监听就无法和其他机器通信,要想让其他人能够访问你服务器、网站,就需要有一个监听端口。
- netstat -lnp 命令可以查看监听端口

- netstat -an 可以查看系统所有的网络连接状况

- netstat -lntp 只查看 tcp 的

- 只查看 udp 的就加上 u

- 结合 awk 命令可以查看所有状态的数量
netstat -an | awk '/^tcp/ {++sta[$NF]} END {for(key in sta) print key,"\t",sta[key]}'
```ss

- ss -an 也能够显示 tcp/ip 的连接状态和 netstat 是类似的命令

- 如果想查看指定的连接状态使用 grep 过滤即可
> 注意:ss有一个缺点是不能显示进程的名字, netsta 则可以显示进程的名字。

# 10. tcpdump命令
- tcpdump 这个命令是用来抓包的,默认情况下这个命令是没有的,需要安装一下
```javascript
[root@sc ~]# yum install -y tcpdump
- 使用这个命令的时候最好是加上你网卡的名称,不然可能使用不了
在命令的选选项中,加上 -nn 选项是表示显示 IP 地址和端口号,如果不加则会显示主机名和进程名,第一列显示的是当前时间,后面会有两个 IP 地址,第一个 IP 地址是源 IP 第二个则是目标 IP, IP 地址后面跟的是数据包的相关信息,所以 tcpdump 这个命令主要就是看网络数据的流向。
[root@sc ~]# tcpdump -nn -i ens33 #网卡的名称可以使用 ifconfig 来查看

- 使用 port 抓取指定端口的包,例如我要抓 22 端口的包
[root@sc ~]# tcpdump -nn -i ens33 port 22
- 还可以使用 not port 过滤掉某个端口的包,例如我过滤掉 22 端口的
[root@sc ~]# tcpdump -nn -i ens33 not port 22
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
01:51:14.821867 ARP, Request who-has 192.168.94.128 (00:0c:29:88:e3:ff) tell 192.168.94.1, length 46
01:51:14.821903 ARP, Reply 192.168.94.128 is-at 00:0c:29:88:e3:ff, length 28
01:51:26.826767 ARP, Request who-has 192.168.94.129 (00:0c:29:f3:bc:79) tell 192.168.94.1, length 46
01:51:26.828268 ARP, Reply 192.168.94.129 is-at 00:0c:29:f3:bc:79, length 46
01:52:24.679295 ARP, Request who-has 192.168.94.128 tell 192.168.94.1, length 46
01:52:24.679335 ARP, Reply 192.168.94.128 is-at 00:0c:29:88:e3:ff, length 28
01:52:27.319695 ARP, Request who-has 192.168.94.129 (00:0c:29:f3:bc:79) tell 192.168.94.1, length 46
01:52:27.320462 ARP, Reply 192.168.94.129 is-at 00:0c:29:f3:bc:79, length 46
- 还可以加个条件,指定抓取某个 IP 的包
[root@sc ~]# tcpdump -nn -i ens33 not port 22 and host 192.168.94.129
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
01:56:27.321877 ARP, Request who-has 192.168.94.129 (00:0c:29:f3:bc:79) tell 192.168.94.1, length 46
01:56:27.322976 ARP, Reply 192.168.94.129 is-at 00:0c:29:f3:bc:79, length 46
- 加上 -c 选项可以指定抓取数据包的数量,例如指定只抓取 20 个数据包
[root@sc ~]# tcpdump -nn -i ens33 -c 20
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
01:57:42.476368 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 1451598397:1451598609, ack 669952694, win 294, length 212
01:57:42.477253 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 212:408, ack 1, win 294, length 196
01:57:42.477835 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 408:572, ack 1, win 294, length 164
01:57:42.478271 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 572:736, ack 1, win 294, length 164
01:57:42.478629 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 736:900, ack 1, win 294, length 164
01:57:42.478997 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 900:1064, ack 1, win 294, length 164
01:57:42.480093 IP 192.168.94.1.65183 > 192.168.94.128.22: Flags [.], ack 1064, win 16425, length 0
01:57:42.480409 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 1064:1340, ack 1, win 294, length 276
01:57:42.480793 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 1340:1504, ack 1, win 294, length 164
01:57:42.481203 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 1504:1668, ack 1, win 294, length 164
01:57:42.481556 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 1668:1832, ack 1, win 294, length 164
01:57:42.482006 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 1832:1996, ack 1, win 294, length 164
01:57:42.482373 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 1996:2160, ack 1, win 294, length 164
01:57:42.482769 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 2160:2324, ack 1, win 294, length 164
01:57:42.483271 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 2324:2488, ack 1, win 294, length 164
01:57:42.483671 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 2488:2652, ack 1, win 294, length 164
01:57:42.484081 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 2652:2816, ack 1, win 294, length 164
01:57:42.484444 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 2816:2980, ack 1, win 294, length 164
01:57:42.484803 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 2980:3144, ack 1, win 294, length 164
01:57:42.485214 IP 192.168.94.128.22 > 192.168.94.1.65183: Flags [P.], seq 3144:3308, ack 1, win 294, length 164
20 packets captured
20 packets received by filter
0 packets dropped by kernel
[root@sc ~]#
- 加上 -w 还可以指定抓取出来的数据包存放到哪里去,例如我要放到 tmp 目录下的 1.cap 文件中
[root@sc ~]# tcpdump -nn -i ens33 -c 20 -w /tmp/1.cap
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
20 packets captured
20 packets received by filter
0 packets dropped by kernel
[root@sc ~]#
- 可以使用 file 命令查看这个文件的相关信息,不能使用 cat 直接查看,因为里面都是数据
[root@sc ~]# file /tmp/1.cap
/tmp/1.cap: tcpdump capture file (little-endian) - version 2.4 (Ethernet, capture length 262144)
[root@sc ~]#
- 不过使用 tcpdump -r 可以看到这个文件里的数据流信息
[root@sc ~]# tcpdump -r /tmp/1.cap
reading from file /tmp/1.cap, link-type EN10MB (Ethernet)
02:01:37.118015 IP bogon.ssh > bogon.65183: Flags [P.], seq 1451606265:1451606413, ack 669956430, win 294, length 148
02:01:37.118590 IP bogon.65183 > bogon.ssh: Flags [.], ack 148, win 16254, length 0
02:01:40.827557 IP6 fe80::51f6:8258:2957:5e96.dhcpv6-client > ff02::1:2.dhcpv6-server: dhcp6 solicit
02:01:48.828244 IP6 fe80::51f6:8258:2957:5e96.dhcpv6-client > ff02::1:2.dhcpv6-server: dhcp6 solicit
02:02:04.831689 IP6 fe80::51f6:8258:2957:5e96.dhcpv6-client > ff02::1:2.dhcpv6-server: dhcp6 solicit
02:02:22.469200 IP bogon.65182 > bogon.ssh: Flags [P.], seq 947772629:947772681, ack 3245656069, win 16322, length 52
02:02:22.470343 IP bogon.ssh > bogon.65182: Flags [.], ack 52, win 251, length 0
02:02:24.809284 ARP, Request who-has bogon tell bogon, length 46
02:02:24.809320 ARP, Reply bogon is-at 00:0c:29:88:e3:ff (oui Unknown), length 28
02:02:24.810123 IP bogon.65183 > bogon.ssh: Flags [P.], seq 1:53, ack 148, win 16254, length 52
02:02:24.858609 IP bogon.ssh > bogon.65183: Flags [.], ack 53, win 294, length 0
02:02:27.318646 ARP, Request who-has bogon (00:0c:29:f3:bc:79 (oui Unknown)) tell bogon, length 46
02:02:27.319130 ARP, Reply bogon is-at 00:0c:29:f3:bc:79 (oui Unknown), length 46
02:02:29.868627 ARP, Request who-has bogon tell bogon, length 28
02:02:29.869735 ARP, Reply bogon is-at 00:50:56:c0:00:08 (oui Unknown), length 46
02:02:30.040511 IP bogon.bootpc > bogon.bootps: BOOTP/DHCP, Request from 00:0c:29:88:e3:ff (oui Unknown), length 300
02:02:30.046275 IP bogon.bootps > bogon.bootpc: BOOTP/DHCP, Reply, length 300
02:02:35.049728 ARP, Request who-has bogon tell bogon, length 28
02:02:35.050078 ARP, Reply bogon is-at 00:50:56:e9:43:b8 (oui Unknown), length 46
02:02:36.832315 IP6 fe80::51f6:8258:2957:5e96.dhcpv6-client > ff02::1:2.dhcpv6-server: dhcp6 solicit
[root@sc ~]#
tshark命令
- tshark 命令默认情况下这个命令是没有的,需要安装一个 wireshark 包, tshark 和 tcpdump 是类似的工具,也是用来抓包的
使用这个命令可以抓取监听的 80 端口的数据包,类似于 web 的访问日志
[root@sc ~]# yum install -y wireshark #安装包
[root@sc ~]# tshark -n -t a -R http.request -T fields -e "frame.time" -e "ip.src" -e "http.host" -e "http.request.method" -e "http.request.uri"
11. Linux网络相关命令
- ifconfig 命令在 CentOS6 是自带有的,但是在 CentOS7 默认是没有的,需要安装 net-tools 这个包。
[root@sc ~]# yum install -y net-tools
- ifconfig 命令比起 ipadd 命令显示的信息更加直观一些
[root@sc network-scripts]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.94.128 netmask 255.255.255.0 broadcast 192.168.94.255
inet6 fe80::724d:7b85:a037:156d prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:88:e3:ff txqueuelen 1000 (Ethernet)
RX packets 7157 bytes 600196 (586.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10404 bytes 11558090 (11.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 4 bytes 416 (416.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 416 (416.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- ifconfig 命令加上 -a 选项可以在网卡断掉或者没有分配 ip 的时候能够显示出来
[root@sc network-scripts]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.94.128 netmask 255.255.255.0 broadcast 192.168.94.255
inet6 fe80::724d:7b85:a037:156d prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:88:e3:ff txqueuelen 1000 (Ethernet)
RX packets 7157 bytes 600196 (586.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10404 bytes 11558090 (11.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 4 bytes 416 (416.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 416 (416.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- ifdown 命令会将网卡断掉,将网卡断掉之后使用 ifconfig 命令就查看不到 ip 了,远程连接的终端也会断开。
[root@sc network-scripts]# ifdown ens33
- ifup 则可以将断掉的网卡 up 回来,当针对一个网卡去进行更改的时候,需要重新启动网卡,但是不想全部网卡都重新启动,就需要使用到这些命令
[root@sc network-scripts]# ifup ens33
- 如果正在使用远程终端的情况下,不要单独使用 ifdown 命令,因为网卡被断掉了,远程就无法连接了,要同时使用 ifdown 和 ifup 才行
[root@sc network-scripts]# ifdown ens33 && ifup ens33
- 给网卡设定虚拟的网卡
1.使用命令:cd /etc/sysconfig/network-scripts/ 进入到 /network-scripts 目录下,然后拷贝网卡配置文件:

2.编辑拷贝的网卡配置文件:
[root@sc network-scripts]# cp ifcfg-ens33 ifcfg-ens33\:0

3.重启网卡,并使用 ifconfig 命令查看信息:
[root@sc network-scripts]# ifdown ens33 && ifup ens33
成功断开设备 'ens33'。
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/9)
[root@sc network-scripts]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.94.128 netmask 255.255.255.0 broadcast 192.168.94.255
inet6 fe80::724d:7b85:a037:156d prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:88:e3:ff txqueuelen 1000 (Ethernet)
RX packets 7739 bytes 654852 (639.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10870 bytes 11622244 (11.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.94.150 netmask 255.255.255.0 broadcast 192.168.94.255
ether 00:0c:29:88:e3:ff txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 4 bytes 416 (416.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 416 (416.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@sc network-scripts]#
- 我们可以打开windows里 cmd 来 ping 一下这个虚拟网卡的地址,看看是否能 ping 通

- mii-tool 命令可以查看网卡是否在连接状态
是 link ok 则表示是连接状态
[root@sc ~]# mii-tool ens33
ens33: negotiated 1000baseT-FD flow-control, link ok
[root@sc ~]#
- 如果 mii-tool 命令不支持的话,还可以使用 ethtool 命令查看

- hostnamectl 是 CentOS7 的命令,CentOS6 不支持,这个命令可以更改主机名,主机名的配置文件在 /etc/hostname 中
[root@sc ~]# hostnamectl set-hostname aminglinux #退出重新登录就改变过来了
[root@sc ~]# hostname
aminglinux
- DNS 配置文件在 /etc/resolv.conf 中,nameserver 行的 ip 地址来自于网卡配置文件,可以在 /resolv.conf 文件里临时更改 DNS
[root@sc ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 119.29.29.29
[root@sc network-scripts]# vi /etc/sysconfig/network-scripts/ifcfg-ens33

- 可以编辑 /etc/resolv.conf 这个文件来添加新的 DNS ,但是一旦重启网卡,配置文件里的 DNS 会覆盖临时添加的 DNS
[root@sc ~]# vim /etc/resolv.conf #也可以在这个配置文件里添加临时 DNS 使用

- /etc/hosts 文件是 Linux、Windows 都有的,用于指定域名访问的 IP 地址,例如我修改 hosts 文件指定一个域名的 ip,ping 这个域名时就会访问 192.168.85.150 IP地址,这个只在本机生效
[root@sc ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@sc ~]# ping www.baidu.com
PING www.a.shifen.com (61.135.169.121) 56(84) bytes of data.
64 bytes from 61.135.169.121 (61.135.169.121): icmp_seq=1 ttl=128 time=5.42 ms
64 bytes from 61.135.169.121 (61.135.169.121): icmp_seq=2 ttl=128 time=5.49 ms
64 bytes from 61.135.169.121 (61.135.169.121): icmp_seq=3 ttl=128 time=5.09 ms
64 bytes from 61.135.169.121 (61.135.169.121): icmp_seq=4 ttl=128 time=6.14 ms
64 bytes from 61.135.169.121 (61.135.169.121): icmp_seq=5 ttl=128 time=5.29 ms
[root@sc ~]# vim /etc/hosts

[root@sc ~]# ping www.sc.com
PING www.sc.com (192.168.85.150) 56(84) bytes of data.
64 bytes from www.sc.com (192.168.85.150): icmp_seq=1 ttl=64 time=0.359 ms
64 bytes from www.sc.com (192.168.85.150): icmp_seq=2 ttl=64 time=0.087 ms
64 bytes from www.sc.com (192.168.85.150): icmp_seq=3 ttl=64 time=0.086 ms
64 bytes from www.sc.com (192.168.85.150): icmp_seq=4 ttl=64 time=0.087 ms
64 bytes from www.sc.com (192.168.85.150): icmp_seq=5 ttl=64 time=0.094 ms
- 一个 IP 可以指定多个域名,如果有两个同样的域名指定了不同的 IP,以后面的那个 IP 为准

[root@sc ~]# ping www.szt.com
PING www.sc.com (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.360 ms
64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=0.281 ms
64 bytes from localhost (127.0.0.1): icmp_seq=3 ttl=64 time=0.084 ms
64 bytes from localhost (127.0.0.1): icmp_seq=4 ttl=64 time=0.084 ms
64 bytes from localhost (127.0.0.1): icmp_seq=5 ttl=64 time=0.153 ms
64 bytes from localhost (127.0.0.1): icmp_seq=6 ttl=64 time=0.088 ms
64 bytes from localhost (127.0.0.1): icmp_seq=7 ttl=64 time=0.090 ms
64 bytes from localhost (127.0.0.1): icmp_seq=8 ttl=64 time=0.083 ms
12. 扩展
tcp三次握手四次挥手(重点) http://www.doc88.com/p-9913773324388.html
tshark几个用法:http://www.aminglinux.com/bbs/thread-995-1-1.html