Transformer-XL框架
引入
Transformer-XL超长上下文的注意力模型,出自CMU和Google Brain在2019年1月发表的论文:《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》。其中XL是extra long的缩写,意为额外长度。论文地址:https://arxiv.org/pdf/1901.02860.pdf 先简单举例Transformer XL与Transformer 的区别。比如有以下数据:
“小说是以刻画人物形象为中心,通过完整的故事情节和环境描写来反映社会生活的文学体裁。”
如果把序列长度设为十个字,代入模型时数据被切分为:
“小说是以刻画人物形象”(序列一)
“为中心,通过完整的故”(序列二)
……
在训练第二个序列时,它的意思是不完整的,Transformer计算第二个序列中的第三字“心”时只能通过前两个字“为中”作为输入计算,而Transformer-XL可以把序列一中的十个字同时作为输入。
切分,尤其当英文中使用字符作为序列中的元素时,如果一个单词被切成两部分,分别位于前后两个序列中,必然影响模型效果。Transformer-XL让之前的序列也能参与到当前序列的预测中来,由此解决了长序列依赖问题,以及序列切断问题。
Transformer-XL既不像GPT-2一样使用海量数据训练,也没像ERNIE加入自然语言相关领域的知识,它主要通过改进模型的架构提高性能。它在字符级和词的级别上表现都很好(第一个在这两方面都超过RNN的自注意力模型),该方案不仅能应用于自然语言处理,在其它序列问题中也能发挥很好的效果。测试证明其在小数据集上也表现优异。
原理
Transformer模型用Self-Attention自注意力机制替换了循环网络RNN,而Transformer-XL再次使用RNN,处理序列之间的连续性。Transformer XL有两点重要创新:循环机制(Recurrence Mechanism)和相对位置编码(Relative Positional Encoding)。
循环机制
尽管Transformer模型可以处理较长的上下文关系,但仍需要在训练时将文章切分成固定长度的序列,再代入模型。而模型学到的也是各序列内部的规律。
- 若不切分,字串太长,尤其是以字符为单位时,计算注意力过于复杂。
- 按标点或按段切分,使程序效率下降。
- 按固定长度切分后,前后的语义被切断。
Transformer XL在输入数据的每个段上仍使用自注意力方法,并使用循环机制来学习连续段之间的依赖关系。

图片摘自论文
Transformer模型的依赖关系如上图(a)中的灰色线条所示,在每个序列中,当前层的输入取决于前一层的输出;Transformer-XL模型的依赖关系又加入了绿色连线,使当前层的输入取决于本序列和前一序列前一层的输出。具体公式如下:
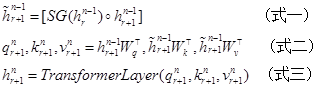
其中h为隐藏层,n为层数,r为序列数,W为模型参数。
式一计算当前第n-1隐藏层时,考虑了当前序列r上一个序列r-1的隐藏层值,其中SG意为stands for stop-gradient停止计算梯度,这样即运用了前一序列生成的数据,又不对其反向传播调参,节省了算力;中括号里的圆圈为连接两个隐藏层。
式二计算注意力所需的q,k,v,q用于查询当前位置,k用于提供相关位置信息,v用于提供相关位置的值。其中k和v使用了包括上个序列信息的隐藏层,而查询q只与当前序列相关。另外,第n个层是通过前一个序列和当前序列的n-1层算出来的,这和基础的循环网络RNN有所不同。
式三将q,k,v代入Transformer算法,计算隐藏层n。
上述方法在计算过程中保留了前一个序列的隐藏层输出h,使得评价过程中不需要每次从头计算,也节约了算力。
相对位置编码
每个序列有其各自的位置编码,当使用多个序列作为输入时,则会出现位置冲突的问题。解决方法是将序列内部的绝对位置编码变为相对位置编码,并把在一开始计算位置编码,移到注意力打分时做计算。直觉上看,相对位置比绝对位置更重要,比如上例中“整”的前一个位置是“完”,一定比“整”在位置八时第七位置是“完”更合理。
具体方法是修改计算Attention的算法:

上式中E表示词嵌入,U表示绝对位置信息,R为相对位置信息,W为模型参数,i是查询元素,j是相关元素。
式四使用绝对位置计算,先将词嵌入E和绝对位置U相加后,与参数相乘计算重要性权重,第二行将其展开。
式五使用相对位置计算,首先用相对位置R代替绝对位置U;由于不需要绝对位置Ui, 引入了u,v参数,取代UiTWqT;另外将参数Wk拆分成了Wk,E和Wk,R。式五又可分为四部分,含义分别是:
(a) j的内容相对于i的影响
(b) i与j的距离对于i的影响
(c) j的内容相对于整体的影响
(d) i与j的距离对于整体的影响
相对编码和循环网络二者结合后才能提升模型效果。如果只加循环网络,则前一序列的位置编码可能与当前序列的位置编码混淆;如果只使用相对位置编码,那么无法解决句子的截断问题。
代码
Git代码地址:
https://github.com/kimiyoung/transformer-xl
作者提供了Tensorflow、PyTorch两种代码实现,以Pytorch为例,其模型实现在pytorch/mem_transformer.py代码中,其模型的代码几乎是transformer代码量的两倍,但命令名规则一致。
层结构、注意力、位置编码与基本的Transformer模型大同小异,改进的核心在:保存之前隐藏层数据的mems和计算相对位置的Rel*LearnableMultiHeadAttn部分。