模型融合---Stacking&Blending
模型融合是指通过分层对模型进行集成,比如以两层为例,第一层为基学习器,使用原始训练集训练基学习器,每个基学习器的输出生成新的特征,作为第二层模型的输入,这样就生成了新的训练集;第二层模型在新的训练集上再进行训练,从而得到融合的模型。
Stacking
Stacking是模型融合的常用方法,重点是在第一层中,如何用基学习器生成新特征,包含训练数据集的新特征和测试数据集的新特征。
1、训练数据集新特征的生成
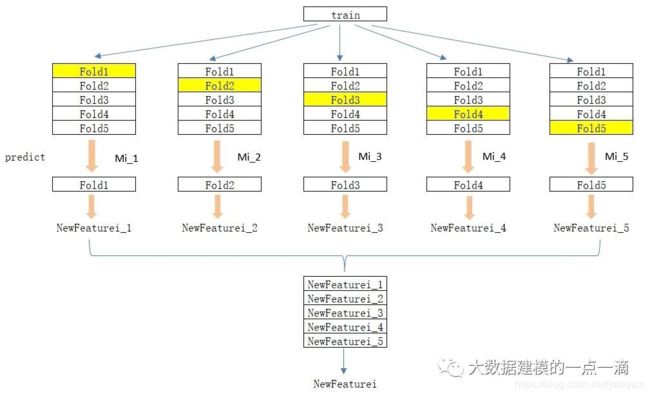
如果直接在训练数据集中对基学习器进行训练,然后用输出作为新特征,容易造成过拟合。所以为了减少过拟合的影响,可以采取K-Folds的方式生成新特征。如下图,以5-Folds为例,Mi为第i个基学习器。
(1)将训练数据集train随机等分为5份,分别为Fold1~Fold5;
(2)对i=1, 2, ...,N:
在{Fold2, Fold3, Fold4, Fold5}上对Mi进行训练,得到学习器Mi_1,然后对Fold1进行预测,得到新特征在Fold1上的值NewFeaturei_1,以此类推,依次得到NewFeaturei_2~NewFeaturei_5,最后将NewFeaturei_1~NewFeaturei_5合并在一起,得到新特征NewFeaturei;
(3)新特征组成了新的训练数据集newtrain={NewFeature1, NewFeature2,...,NewFeatureN},作为下一层的训练数据集。
2、测试数据集新特征的生成
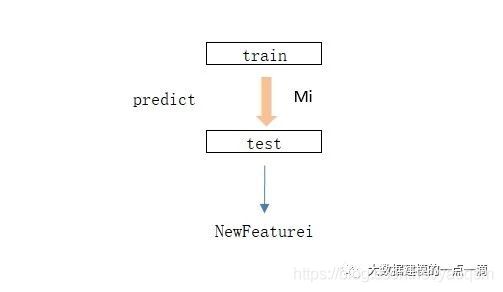
在上面的K-Folds方法中,每一次在训练集上得到基学习器后,就对测试数据集test进行预测,然后对K次的预测结果求平均,就得到了test上的新特征,如下图。

除了上面的K-Folds方法,还可以对全部训练集进行训练得到Mi,然后用Mi对测试集预测得到新特征,如下图。
采用上述方法,得到新的训练集和测试集后,就可以进行第二层的模型训练了。
Blending
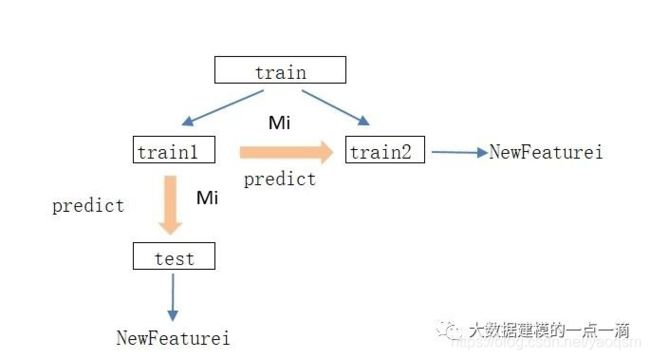
Blending和Stacking比较相似,但相对简单。只需将训练集train分成2部分,train1训练基学习器,train2的预测值作为训练集的新特征,test的预测值作为测试集的新特征。
Stacking和Blending比较
1、Stacking更复杂,需要进行经过K-Fold生成新特征,而Blending相对简单;
2、Stacking通过K-Fold会更稳定,而Blending使用的数据更少,更容易过拟合。
heamy模块实现模型融合
除了自己动手实现Stacking和Blending,Python中的heamy模块很好地实现了Stacking和Blending,可以直接使用。简单列一下该模块的使用方法。
1、heamy.dataset.Dataset(X_train=None, y_train=None, X_test=None, y_test=None, preprocessor=None, use_cache=True)用于构建数据集合,将训练集的X、训练集的y、测试集的X、测试集的y集合在一起。其中y_test可为None。如下构建数据集合model_dataset:
from heamy.dataset import Datasetmodel_dataset = Dataset(X_train=Xtrain, y_train=ytrain, X_test=Xtest)
2、heamy.estimator.Classifier(dataset, estimator=None, parameters=None, name=None, use_cache=True, probability=True)用于构建基学习器,如下构建model_xgb和model_lgb:
from heamy.estimator import Classifierimport lightgbm as lgbimport xgboost as xgbdef xgb_model(X_train, y_train, X_test, y_test=None):# 模型参数params = {'booster': 'gbtree','objective':'binary:logistic','eval_metric' : 'auc','eta': 0.01,'max_depth': 5,'colsample_bytree': 0.7,'subsample': 0.7,'min_child_weight': 1,'seed': 1,'silent':1}dtrain = xgb.DMatrix(X_train, label=y_train)dtest = xgb.DMatrix(X_test)model = xgb.train(params, dtrain, num_boost_round=300)predict = model.predict(dtest)return predictdef lgb_model(X_train, y_train, X_test, y_test=None):lgb_train = lgb.Dataset(X_train, y_train)params = {'task': 'train','boosting_type': 'gbdt','objective': 'binary','metric':'auc','num_leaves': 25,'learning_rate': 0.01,'feature_fraction': 0.7,'bagging_fraction': 0.7,'bagging_freq': 5,'min_data_in_leaf':5,'max_bin':200,'verbose': 0,}model = lgb.train(params, lgb_train, num_boost_round=300)predict = model.predict(X_test)return predictmodel_xgb = Classifier(dataset=model_dataset, estimator=xgb_model,name='xgb',use_cache=False)model_lgb = Classifier(dataset=model_dataset, estimator=lgb_model,name='lgb',use_cache=False)
3、heamy.pipeline.ModelsPipeline(*args)将基学习器组合在一起:
from heamy.pipeline import ModelsPipelinepipeline = ModelsPipeline(model_xgb, model_lgb)
pipeline.stack()用于stacking# 构建第一层新特征,其中full_test=True,对全部训练集进行训练得到基学习器,然后用基学习器对测试集预测得到新特征stack_ds = pipeline.stack(k=5, seed=111, full_test=True)# 第二层使用逻辑回归进行stackstacker = Classifier(dataset=stack_ds, estimator=LogisticRegression, parameters={'fit_intercept': True})# 测试集的预测结果predict_stack = stacker.predict()
pipeline.blend()用于模型blending# 构建第一层新特征,将训练集切分成8:2,其中80%用于训练基学习器,20%用于构建新特征blend_ds = pipeline.blend(proportion=0.2,seed=111)# 第二层使用逻辑回归进行blendblender = Classifier(dataset=blend_ds, estimator=LogisticRegression, parameters={'fit_intercept': True})# 测试集的预测结果predict_blend = blender.predict()