【神经网络和深度学习】吴恩达(Andrew Ng)- 第一课第二周课程编程作业
考完试了,总算有时间开始接触深度学习这块内容,最近听完了吴恩达老师在网易云课堂的第一、二周的课程,及时在此做出总结。(PS:第一周是概念性的东西,不理解的话多次回看就好了,总结从第二周的课程开始)
一、综述
首先,这篇博客是学完第二周的课程之后的总结,是以第二周的编程作业的逻辑顺序来写的,并非课程辅助教程之类的文章,内容可能与课程内容顺序不符,希望本着课程辅导教程的读者谅解。
因此本篇文章行文顺序如下图:
二、准备工作
2.1 分析问题
本次实验要做的是简单基于logistic regression的二分类,判断:猫或不是猫。即使用训练集和优化器得出最优的w和b,以此最优的w和b来测试(这段似乎就是上图的意思……看不看都行)。
2.2 处理数据
注意我们首先需要下载到本次实验的数据以及读取数据方法,并且将数据放在项目目录下新建的datasets文件夹内。其中pythonIr_utils.py文件内的方法是用来读取数据集的。
# 读取数据
# train_set_x_orig :训练集里的图片(本训练集有209张64x64的图像)。
# train_set_y_orig :训练集的图像对应的分类值(0表示不是猫,1表示是猫)。
# test_set_x_orig :测试集里面的图像数据(本训练集有50张64x64的图像)。
# test_set_y_orig : 测试集的图像对应的分类值(0表示不是猫,1表示是猫)。
# classes : 保存的是以bytes类型保存的两个字符串数据,数据为:[b’non-cat’ b’cat’]。
def load_dataset():
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
根据以上的load_dataset()的返回值,我们可以得到本次实验所需的相关数据,我们可以测试输出相关数据的信息。
# 处理数据 测试数据格式
train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes = load_dataset()
# 训练集图片数量,train_set_y_orig (1,209)
num_train = train_set_y_orig.shape[1]
# 测试集图片数量,test_set_y_orig (1,50)
num_test = test_set_y_orig.shape[1]
# 训练集图片维度 64,64,3
num_px = train_set_x_orig.shape[1]
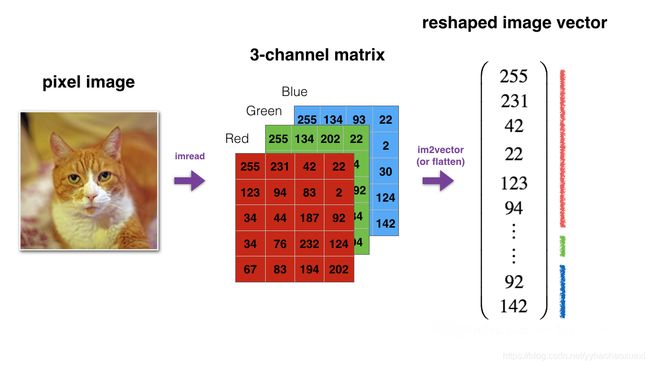
训练集和测试集的输入数据均为64 * 64 * 3的图片,即长64px、宽64px、三通道(RGB)的图片。
# 处理数据 降维处理
# 训练集 测试集 输入数据降维并转置
# .reshape(,-1)代表我也不知道是多少列,你自己算
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T # (64 * 64 * 3, 209)
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T # (64 * 64 * 3, 50)
# 标签
train_set_y_label = train_set_y_orig.reshape(train_set_y_orig.shape[0], -1) # (1, 209)
test_set_y_label = test_set_y_orig.reshape(test_set_y_orig.shape[0], -1) # (1, 50)
为了方便处理,对于输入数据,每一个图片使用一列进行表示;对于标签,每一个图片对应的标签使用一列进行记录,因此我们对输入数据和标签进行了降维处理。
# 处理数据 居中和标准化
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255
对输入数据进行居中和标准化,因为RGB数据中不存在比255大的数据,因此对于每个数据除以255,使得标准化的数据位于[0, 1]之间。
处理数据过程如图:
三、分析网络
我们需要建立一个Logistic Pregression,全部实验的过程如下图: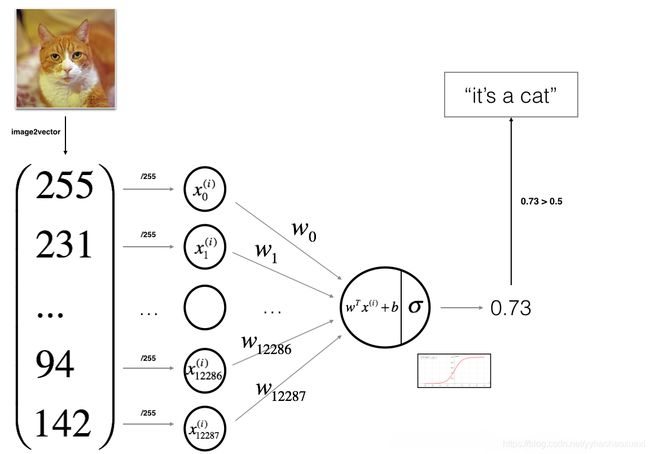
3.1 公式及含义
本实验中所需要的数学公式:
(1) z ( i ) = w T x ( i ) + b z^{(i)} = w^T x^{(i)} + b \tag{1} z(i)=wTx(i)+b(1)
(2) y ^ ( i ) = a ( i ) = s i g m o i d ( z ( i ) ) = σ ( z ( i ) ) = 1 1 + e − z ( i ) \hat{y}^{(i)} = a^{(i)} = sigmoid(z^{(i)}) = \sigma(z^{(i)}) = \frac{1}{1+e^{-z^{(i)}}} \tag{2} y^(i)=a(i)=sigmoid(z(i))=σ(z(i))=1+e−z(i)1(2)
(3) L ( a ( i ) , y i ) = − ( y ( i ) l o g ( a ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − a ( i ) ) ) L(a^{(i)},y^{i}) = -\Big(y^{(i)}log(a^{(i)}) + (1-y^{(i)})log(1-a^{(i)})\Big) \tag{3} L(a(i),yi)=−(y(i)log(a(i))+(1−y(i))log(1−a(i)))(3)
(4) J ( w , b ) = 1 m ∑ i = 1 m L ( a ( i ) , y ( i ) ) J(w,b) = \frac{1}{m}\sum_{i=1}^mL(a^{(i)},y^{(i)}) \tag{4} J(w,b)=m1i=1∑mL(a(i),y(i))(4)
由以上公式可以推得:
(5) ∂ J ( w , b ) ∂ w = 1 m ( X ⋅ ( A − Y ) T ) \frac{\partial J(w,b)}{\partial w} = \frac{1}{m}(X ·(A - Y)^{T}) \tag{5} ∂w∂J(w,b)=m1(X⋅(A−Y)T)(5)
(6) ∂ J ( w , b ) ∂ b = 1 m ∑ i = 1 m ( A − Y ) \frac{\partial J(w,b)}{\partial b} = \frac{1}{m}\sum_{i=1}^m(A - Y) \tag{6} ∂b∂J(w,b)=m1i=1∑m(A−Y)(6)
其中 w w w是权重, b b b是偏置值 ; y = s i g m o i d ( x ) y = sigmoid(x) y=sigmoid(x)是激励函数; z ( i ) z^{(i)} z(i)是没有被激活的; y ^ ( i ) \hat y^{(i)} y^(i)是激活后的预测值; y i y^{i} yi是标签,也就是真实值; L ( a ( i ) , y i ) L(a^{(i)},y^{i}) L(a(i),yi)是损失函数; J ( w , b ) J(w,b) J(w,b)是代价函数。
激励函数(Activation Function)
确保我们需要的预测值在 [ 0 , 1 ] [0,1] [0,1]之间
损失函数(Loss Function)
定义在单个训练样本上的,也就是就算一个样本的误差。比如我们想要分类,就是预测的类别和实际类别的区别,是一个样本的,用 L L L表示。
代价函数(Cost Function)
定义在整个训练集上面的,也就是所有样本的误差的总和的平均,也就是损失函数的总和的平均,有没有这个平均其实不会影响最后的参数的求解结果,用 J J J表示。
四、构建网络
做了那么多准备,终于到了激动人心的构建网络的过程了。(从这里开始是实际的代码部分)
在此之前先定义一些需要用到的函数:
# 构建神经网络
# 激励函数,确保我们需要的预测值在[0, 1]
def sigmoid(z):
s = 1 / (1 + np.exp(-z))
return s
4.1 初始化 w , b w,b w,b
# 构建神经网络
# 为w创建一个维度为(dim,1)的0向量,并将b初始化为0,dim 是特征的维度(数量)
def initialize_with_zeros(dim):
# 返回w和b,w为(dim,1) b是标量
w = np.zeros(shape=(dim, 1))
b = 0
# 吴恩达老师再三强调过,要确保数据的正确性
assert(w.shape == (dim, 1))
assert(isinstance(b, float) or isinstance(b, int))
return w, b
4.2 正向传播、后向传播
# 正向传播、后向传播
# w - 权重
# b - 偏置值
# X - 输入
# Y - 标签 [是猫: 1,非猫:0]
# 根据调用,我们可以看到通过X传入的值就是train_set_x,也就是居中和标准化之后的训练集输入;
# 通过Y传入的值就是train_set_y_orig,也就是训练集图像对应的标签(分类值),0表示不是猫,1表示是猫
def propagate(w, b, X, Y):
m = X.shape[1]
# 正向传播
A = sigmoid(np.dot(w.T, X) + b)
# 用来衡量算法运行情况
# loss function 通常用L表示
# 损失函数(Loss function)是定义在单个训练样本上的,也就是就算一个样本的误差。
# 比如我们想要分类,就是预测的类别和实际类别的区别,是一个样本的,用L表示
# cost function 通常用J表示
# 代价函数(Cost function)是定义在整个训练集上面的,
# 也就是所有样本的误差的总和的平均,也就是损失函数的总和的平均。
# 有没有这个平均其实不会影响最后的参数的求解结果。
# logistic regression 中使用 cost function 即J(w,b)
cost = (-1 / m) * np.sum(Y * np.log(A) + (1 - Y) * (np.log(1 - A))) # 成本函数
# 反向传播
# 根据损失函数,反向的计算每一层的z,a,w,b的偏导数,从而更新参数
# z = w.T * x + b
# a = sigmoid(z)
# L(a,y) = -(ylog(a) + (1-y)log(1-a))
# dL/dw = dL/da * da/dz * dz/ dw
# dL/db = dL/da * da/dz * dz/ db
dw = (1 / m) * np.dot(X, (A - Y).T)
db = (1 / m) * np.sum(A - Y)
# 确保数据正确
assert(dw.shape == w.shape)
assert(db.dtype == float)
# 保存 dw db
grads = {
'dw': dw,
'db': db
}
return grads, cost
4.3 梯度下降优化 w , b w,b w,b
# 通过运行梯度下降算法来优化w和b
# 根据后边的调用,我们可以看到通过X传入的值就是train_set_x,也就是居中和标准化之后的训练集输入;
# 通过Y传入的值就是train_set_y_orig,也就是训练集图像对应的标签(分类值),0表示不是猫,1表示是猫
def optimize(w, b, X, Y, num_literations, learning_rate, print_cost = False):
costs = []
for i in range(num_literations):
grads, cost = propagate(w, b, X, Y)
dw = grads['dw']
db = grads['db']
# 梯度下降算法来优化w和b
w = w - learning_rate * dw
b = b - learning_rate * db
if i % 100 == 0:
costs.append(cost)
if print_cost and (i % 100 == 0):
print("迭代次数:%i, 误差值:%f" % (i, cost))
params = {
'w': w,
'b': b
}
grads = {
'dw': dw,
'db': db
}
return params, grads, costs
4.4 预测
# 预测
# 使用优化好的w,b来预测训练集或测试集数据的正确性
# 根据调用,我们可以看到输入的X可以是train_set_x、test_set_x,即居中和标准化之后的训练/测试集输入
def predict(w, b, X):
m = X.shape[1] # 图片数量
Y_prediction = np.zeros((1, m))
w = w.reshape(X.shape[0], 1)
# 预测猫在图片中出现的概率
A = sigmoid(np.dot(w.T, X) + b)
for i in range(A.shape[1]):
if A[0, i] > 0.5:
Y_prediction[0, i] = 1
else:
Y_prediction[0, i] = 0
assert(Y_prediction.shape == (1, m))
return Y_prediction
4.5 整合与调用
#整合
def model(X_train, Y_train, X_test, Y_test, num_iterations = 2000, learning_rate = 0.5, print_cost = False):
# 初始化
w, b = initialize_with_zeros(X_train.shape[0])
# 优化
parameters, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
# 从字典中检索参数 w 和 b
w, b = parameters['w'], parameters['b']
# 预测测试/训练集
Y_prediction_test = predict(w, b, X_test)
Y_prediction_train = predict(w, b, X_train)
# 打印训练后的准确性
print("训练集准确性:", format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100), "%")
print("测试集准确性:", format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100), "%")
d = {
"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediciton_train": Y_prediction_train,
"w": w,
"b": b,
"learning_rate": learning_rate,
"num_iterations": num_iterations}
return d
# 调用
d = model(train_set_x, train_set_y_orig, test_set_x, test_set_y_orig, num_iterations=2000, learning_rate=0.01, print_cost=True)
# print(d)
五、运行结果
迭代次数:0, 误差值:0.693147
迭代次数:100, 误差值:0.823921
迭代次数:200, 误差值:0.418944
迭代次数:300, 误差值:0.617350
迭代次数:400, 误差值:0.522116
迭代次数:500, 误差值:0.387709
迭代次数:600, 误差值:0.236254
迭代次数:700, 误差值:0.154222
迭代次数:800, 误差值:0.135328
迭代次数:900, 误差值:0.124971
迭代次数:1000, 误差值:0.116478
迭代次数:1100, 误差值:0.109193
迭代次数:1200, 误差值:0.102804
迭代次数:1300, 误差值:0.097130
迭代次数:1400, 误差值:0.092043
迭代次数:1500, 误差值:0.087453
迭代次数:1600, 误差值:0.083286
迭代次数:1700, 误差值:0.079487
迭代次数:1800, 误差值:0.076007
迭代次数:1900, 误差值:0.072809
训练集准确性: 99.52153110047847 %
测试集准确性: 70.0 %
5.1 分析结果
对于训练集近乎100%的准确性,学姐说是因为过拟合了,由于作者暂时水平有限,不做过多分析,现挖此坑,以后再填。
六、学习率-成本曲线图
#绘制图
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(d["learning_rate"]))
plt.show()
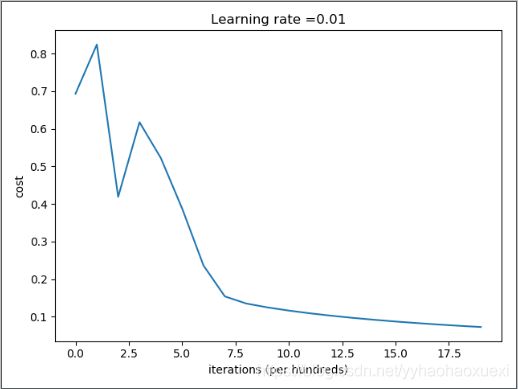
根据做出的图像,能够更直观的看到学习率变化引起的成本的变化。
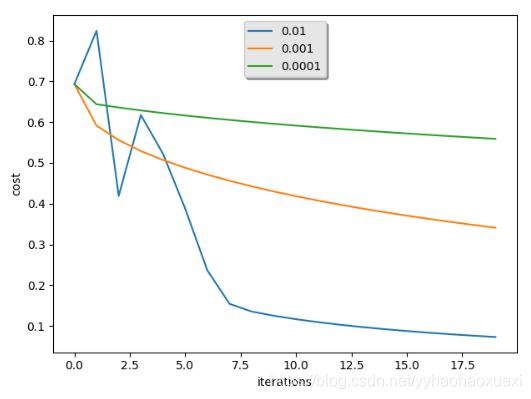
# 绘制多个学习率的图像做对比
learning_rates = [0.01, 0.001, 0.0001]
models = {}
for i in learning_rates:
print("learning rate is: " + str(i))
models[str(i)] = model(train_set_x, train_set_y_orig, test_set_x, test_set_y_orig, num_iterations=2000, learning_rate=i, print_cost=False)
print('\n' + "-------------------------------------------------------" + '\n')
for i in learning_rates:
plt.plot(np.squeeze(models[str(i)]["costs"]), label=str(models[str(i)]["learning_rate"]))
plt.ylabel('cost')
plt.xlabel('iterations')
legend = plt.legend(loc='upper center', shadow=True)
frame = legend.get_frame()
frame.set_facecolor('0.90')
plt.show()
七、参考资料
- 【中文】【吴恩达课后编程作业】Course 1 - 神经网络和深度学习 - 第二周作业
- Markdown中Latex 数学公式基本语法