进程控制:状态、调度和优先级
目录
进程的状态
可运行状态
可中断睡眠状态和不可中断睡眠状态
睡眠进程和等待队列
TASK_KILLABLE 状态
TASK_STOPPED 状态和 TASK_TRACED 状态
EXIT_ZOMBIE 状态和 EXIT_DEAD 状态
进程调度概述
普通进程的优先级
完全公平调度的实现
普通进程的组调度
实时进程
CPU 的亲和力
进程的状态
进程是无法始终占有 CPU 资源的,原因是:
- 进程可能需要等待某种外部条件的满足,在条件满足之前,进程是无法继续执行的。这种情况下,该进程继续占有 CPU 就是对 CPU 资源的浪费
- Linux 是多用户多任务的操作系统,可能同时存在多个可以运行的进程,进程的个数可能远远多于 CPU 的个数。一个进程始终占有 CPU 对其他进程来说是不公平的,进程调度器会在合适的时机,选择合适的进程使用 CPU
- Linux 进程支持软实时,实时进程的优先级高于普通进程,实时进程进程之间也有优先级的差别。软实时进程进入可运行状态的时候,可能会发生抢占,抢占当前运行的进程
Linux 下传统的进程 7 状态:前一项时 procfs 文件系统中的值,后一项是进程状态
- R(running) TASK_RUNNING
- S(sleeping) TASK_INTERRUPTIBLE
- D(disk sleep) TASK_UNINTERRUPTIBLE
- T(stopped) TASK_STOPPED
- t(tracing stop) TASK_TRACED
- Z(zombie) TASK_ZOMBIE
- X(dead) TASK_DEAD
可运行状态
该状态的名称为 TASK_RUNNING。有人说 Linux 进程有八种状态,这种说法也是对的。因为 TASK_RUNNING 状态可以根据是否在 CPU 上运行,进一步细分成 RUNNING 和 READY 两种状态。处于 READY 状态的进程,随时可以投入运行,只是由于 CPU 资源有限,调度器暂时未被选中它运行。
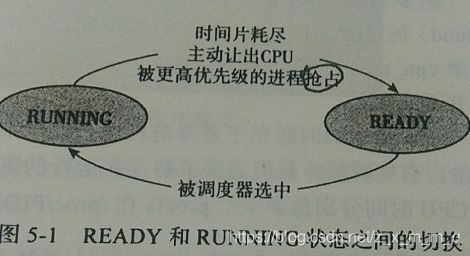
处于可运行状态的进程是进程调度的对象。如果进程并不处于可运行状态,进程调度器不会选择它投入运行。在 Linux 中每一个 CPU 都有自己的运行队列,事实上还不止一个,根据进程调度类别的不同,可运行状态的进程也会位于不同的队列中:如果是实时进程(属于事实调度类),则根据优先级的情况,落在相应的优先级队列中;如果是普通进程(属于完全公平调度类),则根据虚拟运行时间的大小,落在红黑树的相应结点上。这样进程调度器可以根据一定的算法从运行队列上挑选合适的进程来使用 CPU 资源。
处于 RUNNING 状态的进程,可能正在执行用户态代码,也可能正在执行内核态代码,内核提供了进一步的区分和统计。Linux 提供的 time 命令可以统计进程在用户态和内核态消耗的 CPU 时间:

time 命令统计了三个时间:
- 实际时间 :日常生活中的时间,即进程从开始到结束一共执行了多久
- 用户 CPU 时间 :进程执行用户态代码消耗的 CPU 时间
- 系统 CPU 时间 :进程在内核态运行所消耗的 CPU 时间
如何区分用户态 CPU 时间和内核态 CPU 时间呢?如果进程在执行加减乘除或排序等操作时,尽管这些操作正在消耗 CPU 资源,但是和内核并没有太多的关系,CPU 大部分时间都在执行用户态指令。这种场景下我们称 CPU 时间消耗在用户态。如果进程频繁的执行进程创建、进程销毁、分配内存、操作文件等,那么进程不得不频繁的陷入内核执行系统调用,这些时间都累加在进程的内核态 CPU 时间中。
在单核系统上 real time 总是不小于 user time 和 sys time 的总和。但是在多核系统上,user time 和 sys time 的总和可以大于 real time。利用这三个时间我们可以算出程序的 CPU 使用率:
cpu_usage = (user time + sys time) / real time
在多核处理器的情况下,如果 cpu_usage 大于 1,则表示该进程是计算密集型的进程,且 cpu_usage 的值越大,表示越充分的利用了多处理器的并行运行优势;如果 cpu_usage 的值小于 1,则表示进成为 I/O 密集型的进程,多核并行的优势并不明显。
time 命令的问题在于要等进程运行完毕后,才能获取到进程的统计信息。有些时候我们需要了解正在运行的进程,他运行了多久、用户态 CPU 时间和内核态 CPU 时间分别是多少?procfc文件系统在 /proc/PID/stat 中提供了相关信息:
![]()
每个字段都有自己独特的含义。如果从 0 开始计数,那么字段 13 对应的是进程消耗的用户态 CPU 时间,字段 14 对应的是进程消耗的内核态 CPU 时间。两者的单位是始终滴答。
系统提供了 pidstat 命令,通过该命令可以获取到各个进程的 CPU 使用情况:

pidstat 命令可以通过 -p 参数指定观察的进程,从而获取到该进程的 CPU 使用时间,包括用户态 CPU 时间和内核态 CPU 时间。
可中断睡眠状态和不可中断睡眠状态
进程并不总是处于可运行的状态。有些进程需要和慢速设备打交道。比如进程和磁盘进行交互,相关的系统调用消耗的时间是非常长的(可能在毫秒数量级甚至更久),进程需要等待这些操作完成才可以执行接下来的指令。有些进程需要等待某种特定条件(比如父进程等待子进程退出、等待 socket 连接、尝试获取锁、等待信号量等)得到满足后方可执行,而等待的时间往往是不可预估的。在这种情况下,进程依然占有 CPU 资源就不合适了,对 CPU 资源而言,这是一种极大的浪费。内核会将该进程的状态改变成其他状态,将其从 CPU 的运行队列中移除,同时调度器选择其它的进程来使用 CPU。
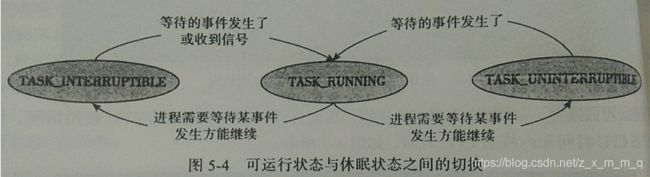
Linux 下存在两种睡眠状态:可中断睡眠状态和不可中断睡眠状态,这两种睡眠状态是很类似的。两者的区别就在于能否响应收到的信号。
处于可中断睡眠状态的进程,返回到可运行的状态有以下两种可能性:
- 等待的事件发生了,继续运行的条件满足了
- 收到未被屏蔽的信号
当处于可运行状态的进程收到信号时,会返回 EINTR 给用户进程。程序员需要检测返回值,并做出正确的处理。
但是对于不可中断睡眠状态的进程,只有一种可能性使其返回到可运行的状态,即等待的事件发生了,继续运行的条件满足了。
睡眠进程和等待队列
进程无论是处于可中断睡眠状态还是不可中断睡眠状态,有一个数据结构是绕不开的:等待队列(wait queue)。进程但凡需要休眠,必然是等待某种资源或等待某个事件,内核必须想办法将进程和它等待的资源(或事件)关联起来,当等待的资源可用或等待的事件发生时,可以及时地唤醒进程。内核采用的方法是等待队列。
等待队列作为 Linux 内核中基础数据结构和进程调度密切地结合在一起。当进程需要等待特定事件时,就将其放置在合适的等待队列上,因此等待队列对应的是一组进入休眠状态的进程,当等待的事件发生(或者说等待的条件满足)时,这组进程会被唤醒,这类事件通常包括:中断(I/O 完成)、进程同步、休眠事件到等。
内核使用双链表来实现等待队列,每个等待队列都可以用等待队列头来标识,等待队列头的定义如下:
struct __wait_queue_head{
spinlock_t lock;
struct list_head task_lisk;
};
trpedef struct __wait_queue_head wait_queue_head_t;进程需要休眠的时候,需要定义一个等待队列元素,将该元素插入合适的等待队列,等待队列元素的定义如下:
struct __wait_queue{
unsigned int flags;
#define WQ_FLAG_EXCLUSIVE 0x01
void *private;
wait_queue_func_t func;
struct list_head task_list;
};
typedef struct __wait_queue wait_queue_t;等待队列上的每个元素,都对应一个处于睡眠状态的进程:
内核如何使用等待队列完成睡眠,以及条件满足之后如何唤醒对应的进程内?
首先要定义和初始化等待队列头部。 内核提供了 init_waitqueue_head 和 DECLARE_WAITQUEUE_HEAD 两个宏,用来初始化等待队列头部。
其次,当进程需要睡眠时,需要定义等待队列元素。内核提供了 init_waitqueue_entry 函数和 init_waitqueue_func_entry 函数来完成等待队列元素的初始化:
static inline void init_waitqueue_entry(wait_queue_t *q,struct task_struct *p){
q->flags = 0;
q->private = p;
q->func = default_wake_function; //通用的唤醒回调函数
}
static inline void init_waitqueue_func_entry(wait_queue_t *q,wait_queue_func_t func){
q->flags = 0;
q->private = NULL;
q->func = func;
}从等待队列元素的初始化函数可以看出,等待队列的 private 成员变量指向了进程的描述符 task_struct,因此就有了等待队列元素,就可以将进程挂入对应的等待队列了。
第三步是将睡眠进程(即等待队列元素)放入合适的等待队列中。内核同时提供了 add_wait_queue 和 add_wait_queue_exclusive 两个函数来把等待队列元素添加到等待队列头部指向的双向链表中,代码如下:
void add_wait_queue(wait_queue_head_t *q,wait_queue_t *wait){
unsigned long flags;
wait->flag &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock,flags);
__add_wait_queue(q,wait);
spin_unlock_irqrestore(&q->lock,flags);
}
void add_wait_queue_exclusive(wait_queue_head_t *q,wait_queue_t *wait){
unsigned long flags;
wait->flag |= WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock,flags);
__add_wait_queue(q,wait);
spin_unlock_irqrestore(&q->lock,flags);
}这两个函数的区别在于:
- 一个等待队列元素设置了 WQ_FLAG_EXCLUSIVE 标志位,而另一个则没有
- 一个等待队列元素放到了等待队列的队尾,而另一个则放到了等待队列的队头
同样是添加到等待队列,为何同时提供两个函数,WQ_FLAG_EXCLUSIVE 标志位到底有什么作用?
有这样的场景:如果存在多个进程(既在等待队列上有多个等待队列元素)在等待同一个条件满足或同一件事情发生,那么当条件满足时,应该唤醒一个或某几个进程还是所有进程一并唤醒。
有时候需要唤醒等待队列上的所有进程,但有时候唤醒操作需要具有排他性(EXCLUSIVE)。比如多个进程等待临界区资源,当锁的持有者释放锁时,如果内核将所有等待在该锁上的进程一并唤醒,那么最终只能是某一个进程竞争到锁,其他进程不过是从休眠中醒来,然后继续休眠,这会浪费 CPU 资源,如果等待队列中的进程数目很大,还会严重影响性能。这就是所谓的惊群效应。因此内核提供了 WQ_FLAG_EXCLUSIVE 标志位来实现互斥等待,add_wait_queue_exclusive 函数会将带有该标志位的等待队列元素添加到等待队列的尾部。当内核唤醒等待队列上的进程时,等待队列元素上的 WQ_FLAG_EXCLUSIVE 标志位会影响唤醒行为,比如 wake_up 宏,它唤醒第一个带有 WQ_FLAG_EXCLUSIVE 标志位的进城后就会停止。
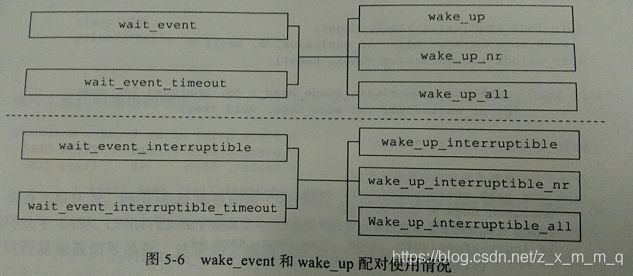
事实上,当进程需要等待某个条件满足而不得不休眠时,内核封装了一些宏来完成前面提到的流程,这些宏包括:
wait_event(wq,condition) //进程状态是不可中断的睡眠状态
wait_event_timeout(wq,condition,timeout) //超时时间
wait_event_interruptible(wq,condition) //进程状态是可中断睡眠状态
wait_event_interruptible_timeout(wq,condition,timeout) //超时时间第一个参数指向的是等待队列的头部,表示进程会睡眠在该等待队列上。进程醒来时,condition 需要得到满足,否则继续阻塞。
有睡眠就要有唤醒,唤醒系列宏包括:
wake_up(x)
wake_up_nr(x,nr)
wake_up_all(x)
wake_up_interruptible(x)
wake_up_interruptible_nr(x,nr)
wake_up_interruptible_all(x)其中该系列宏中,名字中带 _interruptible 的宏只能唤醒处于可中断休眠状态的进程,名字中不带 _interruptible 的宏,既可以唤醒可中断状态的进程,也可以唤醒不可中断休眠状态的进程。
wake_up 系列函数中为什么有些函数后面有 _nr 或 _all 这样的后缀?不带后缀的表示只能唤醒一个带有 WQ_FLAG_EXCLUSIVE 标志位的进程,带 _nr 的表示可以唤醒 nr 个带有 WQ_FLAG_EXCLUSIVE 标志位的进程,带 _all 后缀的表示可以唤醒等待队列上所有的进程。
这些宏和前面 wait_event 系列宏的配对使用情况如下:
这些 wake_up 系列的宏,其实现部分最终是通过 __wake_up 函数的简单封装来实现的。
注意,遍历等待队列上的所有等待队列元素时,对于每一个需要唤醒的进程,执行的是等待队列元素中定义的 func。
在初始化等待队列元素的时候,需要注册回调函数 func。当内核唤醒该进程时,就会执行等待队列元素中的回调函数。这里最常用的回调函数是 default_wake_function,这是默认的回调函数。而 default_wake_function 函数仅仅是 try_to_wake_up 函数的简单封装。
try_to_wake_up 是进程调度里非常重要的一个函数,它负责将睡眠的进程唤醒,并将醒来的进程放置到 CPU 的运行队列中,并设置进程的状态为 TASK_RUNNING。
TASK_KILLABLE 状态
#include
#include
#include
#include
int main()
{
if(!vfork()){
sleep(100);
printf("666\n");
}
return 0;
}
很多文章认为,调用 vfork 函数创建子进程时,子进程在调用 exec 系列函数或退出之前,父进程始终处于 TASK_UNINTERRUPTIBLE 状态。
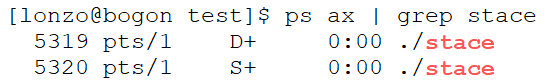
其实这种说法是错误的。因为父进程可以轻易的被信号杀死,这证明父进程并不处于 不可中断睡眠状态。

父进程的状态显示的是 D+,按 ps 命令的说法应该是处于不可中断睡眠状态,可为什么仍然会被信号杀死呢?
事实上,ps 命令输出的 D 状态不能简单的理解成 TASK_UNINTERRUPTIBLE 状态。内核自 2.6.25 版本起引入了一种新的状态即 TASK_KILLABLE 状态。可中断睡眠状态的信号太容易被信号打断,不可中断睡眠状态完全不可以被信号打断,容易失控,两者都失之极端。TASK_KILLABLE 状态则介于两者之间,是一种调和状态。该状态行为上类似于 TASK_UNINTERRUPTIBLE 状态,但是处于该状态的进程收到致命信号时,进程会被唤醒。
上面例子中 vfork 创建子进程后,ps 显示父进程处于 D 状态,却依然被杀死的原因是进程并不是处于不可中断睡眠状态,而是处于 TASK_KILLABLE 状态,是可以响应致命信号的。
有了该状态,wait_event 系列宏也增加了 killable 的变体,即 wait_event_killable。该宏会将进程设置为 TASK_KILLABLE 状态,同时睡眠在等待队列上。致命信号 SIGKILL 可以将其唤醒。
TASK_STOPPED 状态和 TASK_TRACED 状态
TASK_STOPPED 状态是一种比较特殊的状态。SIGSTOP、SIGTSYP、SIGTTIN、SIGTTOU 等信号会将进程暂时停止,停止后的进程就会进入到该状态。其中 SIGSTOP 具有和 SIGKILL 类似的属性,即不能忽略、不能安装新的信号处理函数、不能屏蔽等。当处于 TASK_STOPPED 状态的进程收到 SIGCONT 信号后,可以恢复到 TASK_RUNNING 状态。
TASK_TRACED 状态是被跟踪的状态,进程会停下来等待跟踪它的进程对它进行进一步的操作。如何才能制造出处于 TASK_TRACED 状态的信号呢?最简单的例子是用 gdb 调试程序,当进程在端点处停下来时,此时进程处于该状态。
处于这两种状态的进程类似之处是都处于暂停状态,不同之处是 TASK_TRACED 状态的进程不会被 SIGCONT 信号唤醒。只有调试进程通过 ptrace 系统调用下达 PTRACE_CONT、PTRACE_DETACH 等指令,或者调试进程退出,被调试的进程才能恢复 TASK_RUNNING 状态。
EXIT_ZOMBIE 状态和 EXIT_DEAD 状态
是两种退出状态,严格来说,他们并不是运行状态。当进程处于这两种状态中的任何一种时,它其实已经死去了。内核会将这两种状态记录在进程描述符的 exit_state 中。
两种状态的区别在于,如果父进程没有将 SIGCHLD 信号的处理函数设置为 SIG_IGN,或者没有为 SIGCHLD 信号设置 SA_NOCLDWAIT 标志位,那么子进程退出后,会进入僵尸状态等待父进程或 init 进程来收尸,否则直接进入 EXIT_DEAD 状态。如果不停留在僵尸状态,进程的退出是非常快的,因此很难观察到一个进程是否处于 EXIT_DEAD 状态。
进程调度概述
进程调度是任何一个现代操作系统都要解决的问题,它是操作系统相当重要的一个组成部分。首先需要了解的一点是,进程调度是对处于可运行状态的进程进行调度,如果进程并非处于 TASK_RUNNING 状态,那么该进程和进程调度是没有关系的。
Linux 是多任务操作系统,所谓多任务是指系统能够同时并发的执行多个进程,哪怕是单处理器系统。在单处理器上处理多任务,会给用户多个进程同时跑的幻觉,事实上多个进程仅仅是轮流使用 CPU 资源。只有在多处理器上,多个进程才能做到同时、并行执行。
多任务系统可以根据是否支持抢占分为两类:非抢占式多任务和抢占式多任务。在非抢占式多任务系统中,下一个任务被调度的前提是当前进程主动让出 CPU 的使用权,因此,非抢占式多任务又称为合作型多任务。而抢占式多任务系统中由操作系统来决定进程调度。毫无疑问,Linux 属于抢占式多任务系统。事实上,大多数的现代操作系统都是抢占式多任务系统。
CPU 是一种关键的系统资源。在普通 PC 上 CPU 的核数(cpu 内核数量)是 4 核、8 核等,在服务器上可能有 16 核、32 核甚至更多。在系统负载始终比较轻的情况下,进程调度算法的重要性并不大。但是如果系统的负载很高,有几百上千的进程处于可运行状态,那么一套合理高效的调度算法就非常重要了。
此外,不同的进程之间,其行为模式可能存在着巨大的差异。进程的行为模式可以粗略的分为两类:CPU 消耗型和 I/O 消耗型。所谓 CPU 消耗型指进程没有太多的 I/O 请求,始终处于可运行的状态,始终在执行指令。而 I/O 消耗型是指进程会有大量的 I/O 请求,它处于可执行状态的时间不多,而是将更多的时间耗费在等待上。当然这种划分方式并非绝对的,有可能有些进程某段时间表现出 CPU 消耗型的特征,另一段时间又表现出 I/O 消耗型的特征。
还有另外一种进程的分类方法:
- 交互式进程:这种类型的进程有很多的人机交互,进程会不断地陷入休眠状态,等待键盘和鼠标的输入。这种进程对系统的响应时间要求非常高,用户输入之后,进程必须被及时唤醒,否则用户就会觉得系统反应迟钝。比较典型的例子是文本编辑程序和图形处理程序
- 批处理型进程:这类进程和交互式进程相反,它不需要和用户交互,通常在后台执行。这样的进程不需要及时地响应。比较典型的例子是编译、大规模的科学计算等
- 实时进程:这类进程优先级比较高,不应该被普通进程和优先级比它低的进程阻塞,一般需要比较短的响应时间
系统之中,有很多性格各异的进程,这就增加了设计调度器算法的难度。设计一个优秀的进程调度器算法绝不是一件容易的事,需要很多要素被考虑:
- 公平:每一个进程都可以获得调度的机会,不会出现“饿死”现象
- 良好的调度延迟:经量确保进程在一定的时间范围内,总能够获得调度的机会
- 差异化:允许重要的进程获得更多的执行时间
- 支持软实时进程:软实时进程比普通进程有更高的优先级
- 负载均衡:多个 CPU 之间的负载要均衡,不能出现一些 CPU 很忙,一些 CPU 很闲的情况
- 高吞吐量:单位时间内完成调度的进程个数尽可能多
- 简单高效:调度算法要高效,不能在调度上花费太长的时间
- 低耗电量:在系统并不繁忙的情况下,降低系统的耗电量
在对称多处理器(SMP)的系统上,存在着多个处理器,那么所有处于可运行状态的进程应该位于一个队列上,还是每个处理器应该有自己的队列?这大概是进程调度首先要解决的问题。
目前 Linux 采用的是每个 CPU 都要有自己的运行队列。每个 CPU 去自己的运行队列里选择进程,这样就降低了竞争。这种方案还有一个好处:缓存重用。某个进程位于这个 CPU 的调度队列里,经过多次调度之后,内核趋于相同的进程选择该 CPU 执行该进程。这种情况下,上下次运行的变量很可能仍然在 CPU 的缓存中,这样就提升了效率。所有的 CPU 共用一个运行队列这种方案的弊端是显而易见的,尤其是在 CPU 数量很多的情况下。
Linux 选择了每一个 CPU 都有自己的运行队列的方案。也带来了一些问题:CPU 之间负载不均衡,可能会出现一些 CPU 闲着而另外一些 CPU 忙不过来的情况。为了解决这个问题,load_balence 就闪亮登场啦。它的任务是在一定时机下,通过将任务从一个 CPU 的运行队列迁移到另一个 CPU 的运行队列中,来保持 CPU 之间的负载均衡。
进程调度具体要做哪些事情呢?概括地说,进程调度的职责是挑选下一个执行地进程,如果下一个被调到的进程和调度前运行的进程不是同一个,则执行上下文切换,将新选择的进程投入运行。