Flink 窗口计算
Flink 窗口计算
一、概述
窗⼝计算是流计算的核⼼,窗⼝将流数据切分成有限⼤⼩的“buckets”,我们可以对这个“buckets”中的有限数据做运算。
在Flink中整体将窗⼝计算按分为两⼤类:keyedstream窗⼝、datastream窗⼝,以下是代码结构:
keyedStream
stream
.keyBy(…) <--------------- keyed versus non-keyed windows
.window(…) <---------------必须指定: “window assigner”
[.trigger(…)] <--------------- 可选: “trigger” (else default trigger) 决定了窗⼝何时触发计算
[.evictor(…)] <--------------- 可选: “evictor” (else no evictor) 剔除器,剔除窗⼝内的元素
[.allowedLateness(…)] <---------------可选: “lateness” (else zero) 是否允许有迟到
[.sideOutputLateData(…)] <--------------- 可选: “output tag” (else no side output for latedata)
.reduce/aggregate/fold/apply() <--------------- 必须: “Window Function” 对窗⼝的数据做运算
[.getSideOutput(…)] <---------------可选: “output tag” 获取迟到的数据
Non-Keyed Windows
stream
.windowAll(…) <--------------- 必须指定: “window assigner”
☆.Window Lifecycle
当有第⼀个元素落⼊到窗⼝中的时候窗⼝就被 创建,当时间(⽔位线)越过窗⼝的EndTime的时候,该窗⼝认定为是就绪状态,可以应⽤WindowFunction对窗⼝中的元素进⾏运算。当前的时间(⽔位线)越过了窗⼝的EndTime+allowed lateness时间,该窗⼝会被删除。
只有time-based windows 才有⽣命周期的概念,因为Flink还有⼀种类型的窗⼝global window不是基于时间的,因此没有⽣命周期的概念。- 每⼀种窗⼝都有⼀个Trigger和function与之绑定,function的作⽤是⽤于对窗⼝中的内容实现运算。⽽Trigger决定了窗⼝什么时候是就绪的,因为只有就绪的窗⼝才会运⽤function做运算。除了指定以上的策略以外,我们还可以指定 Evictor ,该 Evictor 可以在窗⼝就绪以后且在function运⾏之前或者之后删除窗⼝中的元素。
Keyed vs Non-Keyed Windows:
Keyed Windows:在某⼀个时刻,会触发多个window任务,取决于Key的种类。Non-Keyed Windows:因为没有key概念,所以任意时刻只有⼀个window任务执⾏。
二、Window Assigners
窗口分配器
Window Assigner定义了如何将元素分配给窗⼝,这是通过在 window(...) / windowAll() 指定⼀个Window Assigner实现。
Window Assigner负责将接收的数据分配给1~N窗⼝,Flink中预定义了⼀些Window Assigner分如下:
tumbling windows , sliding windows , session windows 和 global windows.- ⽤户可以同过实现WindowAssigner类⾃定义窗⼝。除了global windows 以外其它窗⼝都是基于时间TimeWindow.Timebased窗⼝都有 start timestamp (包含)和end timestamp (排除)属性描述⼀个窗⼝的⼤⼩。
①.Tumbling Windows
滚动窗口
package com.baizhi.window
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object Tumbling {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(0)
//设置一个滚动窗口 周期长度为 5秒
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce((y,z)=>(y._1,y._2+z._2))
.print()
env.execute("Tumbling Processing Time Window Word Count")
}
}
②.Sliding Windows
滑动窗口
package com.baizhi.window
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{SlidingProcessingTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object Sliding {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(0)
//设置一个滑动窗口
.window(SlidingProcessingTimeWindows.of(Time.seconds(4),Time.seconds(2)))
//自定义一个聚合规则
.aggregate(new MydefinedSlidingAggregateFunction)
.print()
env.execute("Sliding Processing Time Window Word Count")
}
}
//自定义一个聚合函数
class MydefinedSlidingAggregateFunction extends AggregateFunction[(String,Int),(String,Int),(String,Int)]{
override def createAccumulator(): (String, Int) = {
//创建一个累加器
("",0)
}
override def add(in: (String, Int), acc: (String, Int)): (String, Int) = {
//求和
(in._1,in._2+acc._2)
}
override def getResult(acc: (String, Int)): (String, Int) = {
acc
}
override def merge(acc: (String, Int), acc1: (String, Int)): (String, Int) = {
(acc._1,acc._2+acc1._2)
}
}
③.Session Windows
会话窗⼝分配器按活动会话对元素进⾏分组。与滚动窗⼝和滑动窗⼝相⽐,会话窗⼝不重叠且没有固定的开始和结束时间。相反,当会话窗⼝在⼀定时间段内未接收到元素时(即,发⽣不活动间隙时),它将关闭。
package com.baizhi.window
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.assigners.{ProcessingTimeSessionWindows, SlidingProcessingTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object Session {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(_._1)
//设置一个session,间隔时间为5S
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))
//自定义一个聚合规则 ,此算子不支持 位置的聚合
.apply(new MydefinedWindowsFunction)
.print()
env.execute("Session Processing Time Window Word Count")
}
}
//自定义一个聚合函数
class MydefinedWindowsFunction extends WindowFunction[(String,Int),(String,Int),String,TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//定义一个时间格式
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//解析时间格式
val stTime = sdf.format(window.getStart)
val edTime = sdf.format(window.getEnd)
//获取总值
val count = input.map(_._2).sum
//输出
out.collect(s"$key \t $stTime \t $edTime \t",count)
}
}
④.Global Windows
global window不是基于时间的
全局窗⼝分配器将具有相同键的所有元素分配给同⼀单个全局窗⼝。仅当您指定了触发器时,此窗⼝⽅案才有⽤。否则,将不会执⾏任何计算,因为全局窗⼝没有可以处理聚合元素的⾃然终点。
package com.baizhi.window
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.assigners.{GlobalWindows, SlidingProcessingTimeWindows, TumblingProcessingTimeWindows, WindowAssigner}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
import org.apache.flink.util.Collector
object Global {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(_._1)
//设置一个Global窗口
.window(GlobalWindows.create())
//定义一个触发器 触发数量为3
.trigger(CountTrigger.of(3))
//自定义一个聚合规则
.apply(new MydefinedGlobalFunction)
.print()
env.execute("Global Processing Time Window Word Count")
}
}
//自定义一个聚合函数
class MydefinedGlobalFunction extends WindowFunction[(String,Int),(String,Int),String,GlobalWindow]{
override def apply(key: String, window: GlobalWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
out.collect(key,input.map(_._2).sum)
}
}
三、Window Functions
定义窗⼝分配器后,我们需要指定要在每个窗⼝上执⾏的计算。这是Window Function的职责,⼀旦系统确定窗⼝已准备好进⾏处理,就可以处理每个窗⼝的元素。
窗⼝函数可以是ReduceFunction,AggregateFunction,FoldFunction、ProcessWindowFunction或WindowFunction(古董)之⼀。
- 其中ReduceFunction和AggregateFunction在运⾏效率上⽐ProcessWindowFunction要⾼,因为前俩个⽅法执⾏的是增量计算,只要有数据抵达窗⼝,系统就会调⽤ReduceFunction,AggregateFunction实现增量计算;
- ProcessWindowFunction在窗⼝触发之前会⼀直缓存接收数据,只有当窗⼝就绪的时候才会对窗⼝中的元素做批量计算,但是该⽅法可以获取窗⼝的元数据信息。但是可以通过将ProcessWindowFunction与ReduceFunction,AggregateFunction或FoldFunction结合使⽤来获得窗⼝元素的增量聚合以及ProcessWindowFunction接收的其他窗⼝元数据,从⽽减轻这种情况。
①.ReduceFunction
package com.baizhi.windowfunction
import org.apache.flink.api.common.functions.{AggregateFunction, ReduceFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{SlidingProcessingTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object ReduceFunction {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//测试使用
println("====STREAM START====")
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(0)
//设置一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
//自定义一个聚合规则
.reduce(new UserDefinedReduceFunction)
.print()
env.execute("Sliding Processing Time Window Word Count")
}
}
//自定义一个聚合函数
class UserDefinedReduceFunction extends ReduceFunction[(String,Int)]{
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
println("----执行一次reduce算子----")
(t._1,t._2+t1._2)
}
}
②.AggregateFunction
package com.baizhi.windowfunction
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object AggregateFunction {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//测试使用
println("====STREAM START====")
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(0)
//设置一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new UserDefinedAggregateFunction)
.print()
env.execute("Tumbling Processing Time Window Word Count")
}
}
//自定义一个类
class UserDefinedAggregateFunction extends AggregateFunction[(String,Int),(String,Int),(String,Int)]{
override def createAccumulator(): (String, Int) = {
("",0)
}
override def add(in: (String, Int), acc: (String, Int)): (String, Int) = {
println("合并一次")
(in._1,in._2+acc._2)
}
override def getResult(acc: (String, Int)): (String, Int) = {
//返回
acc
}
override def merge(acc: (String, Int), acc1: (String, Int)): (String, Int) = {
(acc._1,acc._2+acc1._2)
}
}
③.FoldFunction
FoldFunction不可以⽤在Session Window中
package com.baizhi.windowfunction
import org.apache.flink.api.common.functions.{AggregateFunction, FoldFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object FoldFunction {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//测试使用
println("====STREAM START====")
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(0)
//设置一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.fold(("",0),new UserDefinedFoldFunction)
.print()
env.execute("Tumbling Processing Time Window Word Count")
}
}
//自定义一个类
class UserDefinedFoldFunction extends FoldFunction[(String,Int),(String,Int)]{
//t 累加器 o输入
override def fold(t: (String, Int), o: (String, Int)): (String, Int) = {
println("调用一次")
(o._1,t._2+o._2)
}
}
④.ProcessWindowFunction
package com.baizhi.windowfunction
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.{AggregateFunction, FoldFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object ProcessWindowFunction {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//测试使用
println("====STREAM START====")
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(_._1) //对于process算子,不能使用位置
//设置一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new UserDefinedProcessFunction)
.print()
env.execute("Tumbling Processing Time Window Word Count")
}
}
//自定义一个类
//这种处理类型,会对数据进行缓存,直到窗口就绪才进行计算
class UserDefinedProcessFunction extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//从上下文中获取元数据信息
val mess = context.window
val sdf = new SimpleDateFormat("HH:mm:ss")
val start: Long = mess.getStart
val end: Long = mess.getEnd
val sum: Int = elements.map(_._2).sum
//从迭代器中获取当前值
println("调用一次")
//输出
out.collect(key+"\t OP:"+sdf.format(start)+"\t ED:"+sdf.format(end),sum)
}
}
⑤.混合使用
package com.baizhi.windowfunction
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.{AggregateFunction, FoldFunction, ReduceFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object ReduceAndProcessWindowFunction {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//测试使用
println("====STREAM START====")
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(_._1) //对于process算子,不能使用位置
//设置一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new UserDefinedReduceFunction2,new UserDefinedProcessFunction2)
.print()
env.execute("Tumbling Processing Time Window Word Count")
}
}
//自定义一个类
//这种处理类型,会对数据进行缓存,直到窗口就绪才进行计算
class UserDefinedProcessFunction2 extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//从上下文中获取元数据信息
val mess = context.window
val sdf = new SimpleDateFormat("HH:mm:ss")
val start: Long = mess.getStart
val end: Long = mess.getEnd
val sum: Int = elements.map(_._2).sum
//从迭代器中获取当前值
val list = elements.toList
println("PRO~~~"+list.mkString("|"))
//输出
out.collect(key+"\t OP:"+sdf.format(start)+"\t ED:"+sdf.format(end),sum)
}
}
//自定义一个聚合函数
class UserDefinedReduceFunction2 extends ReduceFunction[(String,Int)]{
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
println("----执行一次reduce算子----"+t._1)
(t._1,t._2+t1._2)
}
}
⑥.process 可以获取状态
package com.baizhi.windowfunction
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.{AggregateFunction, FoldFunction, ReduceFunction}
import org.apache.flink.api.common.state.ReducingStateDescriptor
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object AdvanceStateProcessWindowFunction {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//测试使用
println("====STREAM START====")
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(_._1) //对于process算子,不能使用位置
//设置一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new UserDefinedReduceFunction3,new UserDefinedProcessFunction3)
.print()
env.execute("Tumbling Processing Time Window Word Count")
}
}
//自定义一个类
//这种处理类型,会对数据进行缓存,直到窗口就绪才进行计算
class UserDefinedProcessFunction3 extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
//定义一全数据状态描述器
var stateDes:ReducingStateDescriptor[(String,Int)] = _
//定义一个当前状态的描述器
var stateDesOwn:ReducingStateDescriptor[(String,Int)]=_
//初始化一个状态描述器
override def open(parameters: Configuration): Unit = {
//创建两个状态描述器
this.stateDes = new ReducingStateDescriptor[(String, Int)]("setatDes", new ReduceFunction[(String, Int)] {
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
(t._1, t._2 + t1._2)
}
}, createTypeInformation[(String, Int)])
this.stateDesOwn = new ReducingStateDescriptor[(String, Int)]("stateDesOwn", new ReduceFunction[(String, Int)] {
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
(t._1, t._2 + t1._2)
}
}, createTypeInformation[(String, Int)])
}
override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//从上下文中获取元数据信息
val mess = context.window
val sdf = new SimpleDateFormat("HH:mm:ss")
val start: Long = mess.getStart
val end: Long = mess.getEnd
val sum: Int = elements.map(_._2).sum
//从迭代器中获取当前值
val list = elements.toList
println("PRO~~~"+list.mkString("|"))
//从状态描述器中获取状态
//总值状态
val account = context.globalState.getReducingState(stateDes)
//更新状态
account.add(key,sum)
//当前窗口状态
val acc = context.windowState.getReducingState(stateDesOwn)
acc.add(key,sum)
//测试展示状态
println("GLOBAL-----"+account.get()+"\t WINDOW-----"+acc.get())
//输出
out.collect(key+"\t OP:"+sdf.format(start)+"\t ED:"+sdf.format(end),sum)
}
}
//自定义一个聚合函数
class UserDefinedReduceFunction3 extends ReduceFunction[(String,Int)]{
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
println("----执行一次reduce算子----"+t._1)
(t._1,t._2+t1._2)
}
}
⑦.Legacy Function
过期的函数
package com.baizhi.windowfunction
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.{AggregateFunction, FoldFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{ProcessWindowFunction, WindowFunction}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object LegacyWindowFunction {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
//测试使用
println("====STREAM START====")
//处理
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(_._1) //对于process算子,不能使用位置
//设置一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new UserDefinedWindowFunctionx)
.print()
env.execute("Tumbling Processing Time Window Word Count")
}
}
//自定义一个类
//这种处理类型,会对数据进行缓存,直到窗口就绪才进行计算
class UserDefinedWindowFunctionx extends WindowFunction[(String,Int),(String,Int),String,TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//定义一个时间格式
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//解析时间格式
val stTime = sdf.format(window.getStart)
val edTime = sdf.format(window.getEnd)
//获取总值
val count = input.map(_._2).sum
println("调用~")
//输出
out.collect(s"$key \t $stTime \t $edTime \t",count)
}
}
四、触发器 Trigger
Trigger决定了什么时候窗⼝准备就绪了,⼀旦窗⼝准备就绪就可以使⽤WindowFunction进⾏计算。每⼀个 WindowAssigner 都会有⼀个默认的Trigger。如果默认的Trigger不满⾜⽤户的需求⽤户可以⾃定义Trigger。
- 触发器接⼝具有五种⽅法,这些⽅法允许触发器对不同事件做出反应:
public abstract TriggerResult onElement(…) --------------> 只要有元素落⼊到当前窗⼝, 就会调⽤该⽅法
public abstract TriggerResult onProcessingTime(…) --------------> processing-time 定时器回调函数 (基于处理时间)
public abstract TriggerResult onEventTime(…) --------------> event-time 定时器回调函数 (基于事件时间)
public void onMerge(…) --------------> 当多个窗⼝合并到⼀个窗⼝的时候,调⽤该⽅法,例 SessionWindow
public abstract void clear(…) --------------> 当窗⼝被删除后执⾏所需的任何操作
- 返回值:
CONTINUE --------------> 不触发,也不删除元素
FIRE_AND_PURGE --------------> 触发窗⼝,窗⼝出发后删除窗⼝中的元素
FIRE --------------> 触发窗⼝,但是保留窗⼝元素
PURGE --------------> 不触发窗⼝,丢弃窗⼝,并且删除窗⼝的元素
①.DeltaTrigger
增量触发器 最新的值 - 历史状态值之和 > 阈值 触发
package com.baizhi.trigger
import java.lang
import org.apache.flink.api.common.typeutils.{TypeSerializer, TypeSerializerSnapshot}
import org.apache.flink.core.memory.{DataInputView, DataOutputView}
import org.apache.flink.streaming.api.functions.windowing.delta.DeltaFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{ProcessAllWindowFunction, ProcessWindowFunction}
import org.apache.flink.streaming.api.windowing.assigners.{GlobalWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.triggers.{CountTrigger, DeltaTrigger}
import org.apache.flink.streaming.api.windowing.windows.{GlobalWindow, TimeWindow}
import org.apache.flink.util.Collector
object GlobalDetlaTrigger {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
println("====START====")
//处理 1 zs 3000.0
stream.map(_.split("\\s+")).
map(x=>(x(0)+":"+x(1),x(2).toDouble))
.keyBy(_._1)
//设置一个全局窗口
.window(GlobalWindows.create())
//设置一个触发器
.trigger(DeltaTrigger.of(500.0,new DeltaFunction[(String,Double)] {
override def getDelta(oldDataPoint: (String,Double), newDataPoint: (String,Double)): Double = {
//旧值减去新值
newDataPoint._2-oldDataPoint._2
}
},createTypeInformation[(String,Double)].createSerializer(env.getConfig)))
.process(new UserSuperProcessFunction)
.print()
env.execute("Global Processing Time Window Word Count")
}
}
class UserSuperProcessFunction extends ProcessWindowFunction[(String,Double),(String,Double),String,GlobalWindow]{
override def process(key: String, context: Context, elements: Iterable[(String, Double)], out: Collector[(String, Double)]): Unit = {
val list = elements.toList
println(list.mkString("|"))
out.collect(key,elements.map(_._2.toDouble).sum)
}
}
②.自定义触发器
package com.baizhi.trigger
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.streaming.api.windowing.triggers.{Trigger, TriggerResult}
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
import org.apache.flink.streaming.api.scala._
class UserDefinedCountTrigger(count:Int) extends Trigger[(String,Int),GlobalWindow]{
//定义一个状态描述器
private val valueDes = new ValueStateDescriptor[Int]("TestTrigger",createTypeInformation[Int])
override def onElement(element: (String,Int), timestamp: Long, window: GlobalWindow, ctx: Trigger.TriggerContext): TriggerResult = {
//获取当前数值状态
val countState = ctx.getPartitionedState(valueDes)
//更新状态
countState.update(countState.value()+1)
println("当前状态"+countState.value())
//如果当前状态的数值小于最大数量限制,则继续
if(countState.value()<count){
return TriggerResult.CONTINUE
}else{
//触发并清除状态 同时清空窗口元素
countState.clear()
TriggerResult.FIRE_AND_PURGE
}
}
override def onProcessingTime(time: Long, window: GlobalWindow, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
override def onEventTime(time: Long, window: GlobalWindow, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
override def clear(window: GlobalWindow, ctx: Trigger.TriggerContext): Unit = {
TriggerResult.PURGE
}
}
- 测试:
package com.baizhi.trigger
import java.lang
import org.apache.flink.api.common.typeutils.{TypeSerializer, TypeSerializerSnapshot}
import org.apache.flink.core.memory.{DataInputView, DataOutputView}
import org.apache.flink.streaming.api.functions.windowing.delta.DeltaFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{ProcessAllWindowFunction, ProcessWindowFunction}
import org.apache.flink.streaming.api.windowing.assigners.{GlobalWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.triggers.{CountTrigger, DeltaTrigger}
import org.apache.flink.streaming.api.windowing.windows.{GlobalWindow, TimeWindow}
import org.apache.flink.util.Collector
object GlobalCountTrigger {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取输入源
val stream: DataStream[String] = env.socketTextStream("hbase",9999)
println("====START====")
//处理 1 zs 3000.0
stream.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(_._1)
//设置一个滚动窗口
.window(GlobalWindows.create())
//设置一个触发器
.trigger(new UserDefinedCountTrigger(3))
.process(new UserSuperProcessFunctiona)
.print()
env.execute("Global Processing Time Window Word Count")
}
}
class UserSuperProcessFunctiona extends ProcessWindowFunction[(String,Int),(String,Int),String,GlobalWindow]{
override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
val list = elements.toList
println(list.mkString("|"))
out.collect(key,elements.map(_._2).sum)
}
}
五、剔除器 Evictor
Flink的窗⼝模型允许除了WindowAssigner和Trigger之外还指定⼀个可选的Evictor。可以使⽤evictor(…)⽅法来完成此操作。Evictors可以在触发器触发后,应⽤Window Function之前或之后从窗⼝中删除元素。
void evictBefore ----------> 在调⽤windowing function之前被调⽤
void evictAfter ----------> 在调⽤ windowing function之后调⽤
①.CountEvictor
package com.baizhi.evictor
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{AllWindowFunction, WindowFunction}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.evictors.CountEvictor
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object CountEvictorTest {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置程序并行度
env.setParallelism(1)
//获取输入
val stream = env.socketTextStream("hbase",9999)
//用于测试
println("=====·S·T·A·R·T·=====")
stream
.flatMap(_.split("\\s+"))
//指定窗口大小
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(2)))
//指定剔除内容
.evictor(CountEvictor.of(3))
.apply(new EvictorWindowFunction)
.print("拦截后元素")
env.execute("Evictor Test")
}
}
class EvictorWindowFunction extends AllWindowFunction[String,String,TimeWindow]{
override def apply(window: TimeWindow, input: Iterable[String], out: Collector[String]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
//获取前后时间
val start = window.getStart
val end = window.getEnd
val str = sdf.format(start)
val str1 = sdf.format(end)
val list = input.toList
println("前置时间:"+str+"当前元素:"+list.mkString("|")+"后方时间:"+str1)
out.collect(list.mkString("|"))
}
}
②.DeltaEvictor
采⽤DeltaFunction和阈值,计算窗⼝缓冲区中最后⼀个元素与其余每个元素之间的增量,并删除增量⼤于或等于阈值的元素
package com.baizhi.evictor
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.functions.windowing.delta.DeltaFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{AllWindowFunction, ProcessAllWindowFunction, ProcessWindowFunction, WindowFunction}
import org.apache.flink.streaming.api.windowing.assigners.{ProcessingTimeSessionWindows, TumblingProcessingTimeWindows, WindowAssigner}
import org.apache.flink.streaming.api.windowing.evictors.{CountEvictor, DeltaEvictor}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object DeltaEvictorTest {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置程序并行度
env.setParallelism(1)
//获取输入
val stream = env.socketTextStream("hbase",9999)
//用于测试
println("=====·S·T·A·R·T·=====")
stream
.map(_.split("\\s+"))
.map(x=>(x(0),x(1).toDouble))
.keyBy(_._1)
//指定窗口大小
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(3)))
//指定剔除内容
.evictor(DeltaEvictor.of(3,new DeltaFunction[(String,Double)]{
override def getDelta(oldDataPoint: (String,Double), newDataPoint: (String,Double)): Double = {
newDataPoint._2-oldDataPoint._2
}
}))
.process(new DeltaEvictorWindowFunction)
.print("拦截后元素")
env.execute("Evictor Test")
}
}
class DeltaEvictorWindowFunction extends ProcessWindowFunction[(String,Double),(String,Double),String,TimeWindow]{
override def process(key: String, context: Context, elements: Iterable[(String, Double)], out: Collector[(String, Double)]): Unit = {
var window = context.window
val sdf = new SimpleDateFormat("HH:mm:ss")
//获取前后时间
val start = window.getStart
val end = window.getEnd
val str = sdf.format(start)
val str1 = sdf.format(end)
println("前置时间:"+str+"当前元素:\t"+elements.toList.mkString("|")+"\t后方时间:"+str1)
}
}
③.TimeEvictor
以毫秒为单位的间隔作为参数,对于给定的窗⼝,它将在其元素中找到最⼤时间戳max_ts,并删除所有时间戳⼩于max_ts-interval的元素。
-
只要最新的⼀段时间间隔的数据
定义一个获取水位线和当前时间戳的方法
package com.baizhi.eventTime
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.watermark.Watermark
class UserDefinedAssignerTimeStampAndWaterMaker extends AssignerWithPeriodicWatermarks[(String,Long)]{
//定义参数 1.最大时间 2.允许乱序时间 单位毫秒
var maxSystemTimeStamp:Long = 0L
var allowOrderness:Long = 2000L
//获取当前水位线
override def getCurrentWatermark: Watermark = {
new Watermark(maxSystemTimeStamp-allowOrderness)
}
//获取时间戳,提取事件时间
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
val sdf = new SimpleDateFormat("HH:mm:ss")
maxSystemTimeStamp = Math.max(element._2,maxSystemTimeStamp)
println(element._1+"\t当前事件时间:"+sdf.format(element._2)+"\t"+"当前水位线"+sdf.format(maxSystemTimeStamp-allowOrderness))
element._2
}
}
- 测试
package com.baizhi.evictor
import java.text.SimpleDateFormat
import com.baizhi.eventTime.UserDefinedAssignerTimeStampAndWaterMaker
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.windowing.delta.DeltaFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{AllWindowFunction, ProcessAllWindowFunction, ProcessWindowFunction, WindowFunction}
import org.apache.flink.streaming.api.windowing.assigners.{GlobalWindows, ProcessingTimeSessionWindows, TumblingEventTimeWindows, TumblingProcessingTimeWindows, WindowAssigner}
import org.apache.flink.streaming.api.windowing.evictors.{CountEvictor, DeltaEvictor, TimeEvictor}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger
import org.apache.flink.streaming.api.windowing.windows.{GlobalWindow, TimeWindow}
import org.apache.flink.util.Collector
object TimeEvictorTest2 {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置程序并行度
env.setParallelism(1)
//设置流时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置自动水位线间隔
env.getConfig.setAutoWatermarkInterval(1000)
//获取输入
val stream = env.socketTextStream("hbase",9999)
//用于测试
println("=====·S·T·A·R·T·=====")
stream
.map(_.split("\\s+"))
.map(x=>(x(0),x(1).toLong))
.assignTimestampsAndWatermarks(new UserDefinedAssignerTimeStampAndWaterMaker)
.keyBy(_._1)
//指定窗口大小
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
//指定剔除内容
.evictor(TimeEvictor.of(Time.milliseconds(1000)))
.process(new TimeEvictorWindowFunction)
.print("拦截后元素")
env.execute("Evictor Test")
}
}
class TimeEvictorWindowFunction extends ProcessWindowFunction[(String,Long),(String,Long),String,TimeWindow]{
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[(String, Long)]): Unit = {
var window = context.window
val sdf = new SimpleDateFormat("HH:mm:ss")
//获取前后时间
val start = window.maxTimestamp()
val str = sdf.format(start)
println("前置时间:"+str+"当前元素:\t"+elements.toList.mkString("|")+"\t")
out.collect(key,elements.map(x=>x._2).toList.sum)
}
}
④.自定义剔除器
package com.baizhi.evictor;
import org.apache.flink.streaming.api.windowing.evictors.Evictor;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.runtime.operators.windowing.TimestampedValue;
import java.util.Iterator;
public class MyDefinedKeyWordEvictor implements Evictor<String, TimeWindow> {
//定义一个窗口前执行的参数
Boolean isBefore = true;
//定义一个参数接收关键字
String word = null;
//定义一个构造
public MyDefinedKeyWordEvictor(String word) {
this.word = word;
}
public MyDefinedKeyWordEvictor(Boolean isBefore, String word) {
this.isBefore = isBefore;
this.word = word;
}
@Override
public void evictBefore(Iterable<TimestampedValue<String>> elements, int size, TimeWindow window, EvictorContext evictorContext) {
if(isBefore){
evict(elements,size,evictorContext);
}
}
@Override
public void evictAfter(Iterable<TimestampedValue<String>> elements, int size, TimeWindow window, EvictorContext evictorContext) {
if(!isBefore){
evict(elements,size,evictorContext);
}
}
//定义一个执行的函数
private void evict(Iterable<TimestampedValue<String>> elements, int size,EvictorContext evictorContext){
if(word!=null){
//迭代遍历这个迭代器中的元素
for(Iterator<TimestampedValue<String>> iterator = elements.iterator();iterator.hasNext();){
//取元素
TimestampedValue<String> getWord = iterator.next();
//如果这个元素中包含此关键字,剔除
if(getWord.getValue().contains(word)){
iterator.remove();
}
}
}
}
}
- 测试
package com.baizhi.evictor
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.{AllWindowFunction, WindowFunction}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.evictors.CountEvictor
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object KeyWordEvictorTest {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置程序并行度
env.setParallelism(1)
//获取输入
val stream = env.socketTextStream("hbase",9999)
//用于测试
println("=====·S·T·A·R·T·=====")
stream
.flatMap(_.split("\\s+"))
//指定窗口大小
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(2)))
//指定剔除内容
.evictor(new MyDefinedKeyWordEvictor("zyl"))
.apply(new EvictorWindowFunction)
.print("拦截后元素")
env.execute("Evictor Test")
}
}
class EvictorWindowFunction extends AllWindowFunction[String,String,TimeWindow]{
override def apply(window: TimeWindow, input: Iterable[String], out: Collector[String]): Unit = {
val sdf = new SimpleDateFormat("HH:mm:ss")
//获取前后时间
val start = window.getStart
val end = window.getEnd
val str = sdf.format(start)
val str1 = sdf.format(end)
val list = input.toList
println("前置时间:"+str+"当前元素:"+list.mkString("|")+"后方时间:"+str1)
out.collect(list.mkString("|"))
}
}
六、Event-Time Window
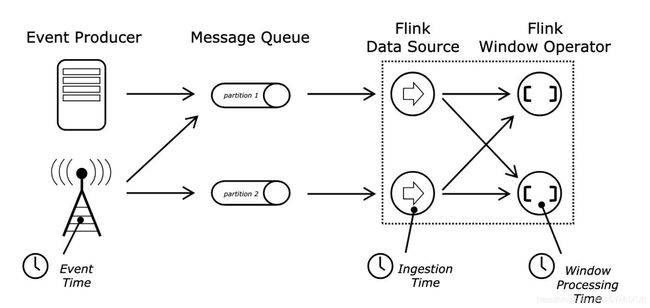
如果Flink⼦使⽤的时候不做特殊设定,默认使⽤的是ProcessingTime。其中和ProcessingTime类似IngestionTime都是由系统⾃动产⽣,不同的是IngestionTime是由DataSource源产⽣⽽ProcessingTime由计算算⼦产生。
- Flink中⽀持基于EventTime语义的窗⼝计算,Flink会使⽤Watermarker机制去衡量事件时间推进进度。Watermarker会在做为数据流的⼀部分随着数据⽽流动。Watermarker包含有⼀个时间t,这就表明流中不会再有事件时间
t'<=t的元素存在
Watermarker(t)= Max event time seen by Procee Node - MaxAllowOrderless(最大允许乱序时间)
定义一个计算时间戳和水位线的类
package com.baizhi.eventTime
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.watermark.Watermark
class UserDefinedAssignerTimeStampAndWaterMaker extends AssignerWithPeriodicWatermarks[(String,Long)]{
//定义参数 1.最大时间 2.允许乱序时间 单位毫秒
var maxSystemTimeStamp:Long = 0L
var allowOrderness:Long = 2000L
//获取当前水位线
override def getCurrentWatermark: Watermark = {
new Watermark(maxSystemTimeStamp-allowOrderness)
}
//获取时间戳,提取事件时间
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
val sdf = new SimpleDateFormat("HH:mm:ss")
maxSystemTimeStamp = Math.max(element._2,maxSystemTimeStamp)
println(element._1+"\t当前事件时间:"+sdf.format(element._2)+"\t"+"当前水位线"+sdf.format(maxSystemTimeStamp-allowOrderness))
element._2
}
}
- 测试
package com.baizhi.eventTime
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object EventTimeTest {
def main(args: Array[String]): Unit = {
//获取刘执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
//设置流时间的特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置事件处理频率
env.getConfig.setAutoWatermarkInterval(1000)
//获取输入流
val stream = env.socketTextStream("hbase",9999)
//测试提示
println("===·S·T·A·R·T·===")
//处理流
stream.map(_.split("\\s+"))
.map(x=>(x(0),x(1).toLong))
.assignTimestampsAndWatermarks(new UserDefinedAssignerTimeStampAndWaterMaker)
//设置事件窗口大小
.windowAll(TumblingEventTimeWindows.of(Time.seconds(2)))
.process(new EventTimePrcessAllWindowFunction)
.print("输出")
env.execute("Event Time")
}
}
class EventTimePrcessAllWindowFunction extends ProcessAllWindowFunction[(String,Long),(String,Long),TimeWindow]{
override def process(context: Context, elements: Iterable[(String, Long)], out: Collector[(String, Long)]): Unit = {
val start = context.window.getStart
val end = context.window.getEnd
val sdf = new SimpleDateFormat("HH:mm:ss")
val str = sdf.format(start)
val str1 = sdf.format(end)
println("这里是处理函数,窗口前置时间"+str+"\t窗口元素"+elements.mkString("|")+"\t窗口结束时间:"+str1)
}
}
注意当流中存在多个Watermarker的时候,取最⼩值作为⽔位线。
①.迟到数据
在Flink中,⽔位线⼀旦没过窗⼝的EndTime,这个时候如果还有数据落⼊到已经被⽔位线淹没的窗⼝,被定义该数据为迟到的数据。这些数据在Spark是没法进⾏任何处理的。在Flink中⽤户可以定义窗⼝元素的迟到时间t’。
如果Watermarker时间t < 窗⼝EndTime t'' + t' 则该数据还可以参与窗⼝计算。如果Watermarker时间t >= 窗⼝EndTime t'' + t' 则该数据默认情况下Flink会丢弃。当然⽤户可以将toolate数据通过side out输出获取
package com.baizhi.eventTime
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object LaterDataTest {
def main(args: Array[String]): Unit = {
//获取刘执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
//设置流时间的特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置事件处理频率
env.getConfig.setAutoWatermarkInterval(1000)
//获取输入流 a 1584196410000
val stream = env.socketTextStream("hbase",9999)
//测试提示
println("===·S·T·A·R·T·===")
val tag = new OutputTag[(String, Long)]("超级迟到数据")
//处理流
var result =stream.map(_.split("\\s+"))
.map(x=>(x(0),x(1).toLong))
.assignTimestampsAndWatermarks(new UserDefinedAssignerTimeStampAndWaterMaker)
//设置事件窗口大小
.windowAll(TumblingEventTimeWindows.of(Time.seconds(2)))
//设置迟到时间
.allowedLateness(Time.seconds(2))
//设置远超迟到时间数据的边输出
.sideOutputLateData(tag)
.process(new EventTimePrcessAllWindowFunctionb)
result.print("正常的数据")
result.getSideOutput(tag).printToErr("超级迟到的数据")
env.execute("Event Time")
}
}
class EventTimePrcessAllWindowFunctionb extends ProcessAllWindowFunction[(String,Long),String,TimeWindow]{
override def process(context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
val start = context.window.getStart
val end = context.window.getEnd
val sdf = new SimpleDateFormat("HH:mm:ss")
val str = sdf.format(start)
val str1 = sdf.format(end)
println("这里是处理函数,窗口前置时间"+str+"\t窗口元素"+elements.mkString("|")+"\t窗口结束时间:"+str1)
out.collect(elements.mkString("|"))
}
}
七、Join
Window Join
窗⼝join将共享相同key并位于同⼀窗⼝中的两个流的元素联接在⼀起。可以使⽤窗⼝分配器定义这些窗⼝,并根据两个流中的元素对其进⾏评估。然后将双⽅的元素传递到⽤户定义的JoinFunction或FlatJoinFunction,在此⽤户可以发出满⾜联接条件的结果。
stream.join(otherStream)
.where()
.equalTo()
.window()
.apply()
创建两个流的元素的成对组合的⾏为就像⼀个内部联接,这意味着如果⼀个流中的元素没有与另⼀流中要连接的元素对应的元素,则不会发出该元素。
那些确实加⼊的元素将以最⼤的时间戳(仍位于相应窗⼝中)作为时间戳。例如,以[5,10)为边界的窗⼝将导致连接的元素具有9作为其时间戳。
事先定义一个获取水位线与时间查戳的类
package com.baizhi.join
import java.text.SimpleDateFormat
import org.apache.flink.runtime.dispatcher.SessionDispatcherFactory
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.watermark.Watermark
class JoinEventTimeWater extends AssignerWithPeriodicWatermarks[(String,String,Long)]{
//设置当前时间戳
var maxSeenTimeStamp:Long = 0L
//设置最大允许乱序时间
var allowOrderness:Long = 2000L
//获取当前水位线
override def getCurrentWatermark: Watermark = {
new Watermark(maxSeenTimeStamp-allowOrderness)
}
//获取最大时间戳,并返回当前元素时间戳
override def extractTimestamp(element: (String, String, Long), previousElementTimestamp: Long): Long = {
val sdf = new SimpleDateFormat("HH:mm:ss")
//获取最大时间戳
maxSeenTimeStamp = Math.max(maxSeenTimeStamp,element._3)
println("当前元素:"+(element._1,element._2)+"当前事件时间:"+sdf.format(element._3)+"\t"+"当前水位线"+sdf.format(maxSeenTimeStamp-allowOrderness))
element._3
}
}
①.Tumbling Window Join
package com.baizhi.join
import org.apache.flink.api.common.functions.JoinFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object TumbingWindowJoin {
def main(args: Array[String]): Unit = {
//获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
//设置流时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置水位线创建自动频率
env.getConfig.setAutoWatermarkInterval(1000) //1s
//获取输入流
var stream1 = env.socketTextStream("hbase",9999)
var stream2 = env.socketTextStream("hbase",8888)
//用于测试
println("===·S·T·A·R·T·===")
//处理流1 1 zs 1584196410000
val storm1 = stream1.map(_.split("\\s+"))
.map(x => (x(0), x(1), x(2).toLong))
.assignTimestampsAndWatermarks(new JoinEventTimeWater)
//处理流2 1 4000 1584196410000
val storm2 = stream2.map(_.split("\\s+"))
.map(x=>(x(0),x(1),x(2).toLong))
.assignTimestampsAndWatermarks(new JoinEventTimeWater)
//连接流
storm1.join(storm2)
.where(x=>x._1)
.equalTo(y=>y._1)
.window(TumblingEventTimeWindows.of(Time.seconds(2)))
.apply(new JoinFunction[(String,String,Long),(String,String,Long),(String,String,String)] {
override def join(first: (String, String, Long), second: (String, String, Long)): (String, String, String) = {
(first._1,first._2,second._2)
}
})
.print("输出")
env.execute("Tumbling Event Time Window Join")
}
}
②.Sliding Window Join
package com.baizhi.join
import org.apache.flink.api.common.functions.JoinFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{SlidingEventTimeWindows, TumblingEventTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object SlidingWindowJoin {
def main(args: Array[String]): Unit = {
//获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
//设置流时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置水位线创建自动频率
env.getConfig.setAutoWatermarkInterval(1000) //1s
//获取输入流
var stream1 = env.socketTextStream("hbase",9999)
var stream2 = env.socketTextStream("hbase",8888)
//用于测试
println("===·S·T·A·R·T·===")
//处理流1 1 zs 1584196410000
val storm1 = stream1.map(_.split("\\s+"))
.map(x => (x(0), x(1), x(2).toLong))
.assignTimestampsAndWatermarks(new JoinEventTimeWater)
//处理流2 1 4000 1584196410000
val storm2 = stream2.map(_.split("\\s+"))
.map(x=>(x(0),x(1),x(2).toLong))
.assignTimestampsAndWatermarks(new JoinEventTimeWater)
//连接流
storm1.join(storm2)
.where(x=>x._1)
.equalTo(y=>y._1)
.window(SlidingEventTimeWindows.of(Time.seconds(4),Time.seconds(2)))
.apply(new JoinFunction[(String,String,Long),(String,String,Long),(String,String,String)] {
override def join(first: (String, String, Long), second: (String, String, Long)): (String, String, String) = {
(first._1,first._2,second._2)
}
})
.print("输出")
env.execute("Sliding Event Time Window Join")
}
}
③.Session Window Join
package com.baizhi.join
import org.apache.flink.api.common.functions.JoinFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{EventTimeSessionWindows, SlidingEventTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object SessionWindowJoin {
def main(args: Array[String]): Unit = {
//获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
//设置流时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置水位线创建自动频率
env.getConfig.setAutoWatermarkInterval(1000) //1s
//获取输入流
var stream1 = env.socketTextStream("hbase",9999)
var stream2 = env.socketTextStream("hbase",8888)
//用于测试
println("===·S·T·A·R·T·===")
//处理流1 1 zs 1584196410000
val storm1 = stream1.map(_.split("\\s+"))
.map(x => (x(0), x(1), x(2).toLong))
.assignTimestampsAndWatermarks(new JoinEventTimeWater)
//处理流2 1 4000 1584196410000
val storm2 = stream2.map(_.split("\\s+"))
.map(x=>(x(0),x(1),x(2).toLong))
.assignTimestampsAndWatermarks(new JoinEventTimeWater)
//连接流
storm1.join(storm2)
.where(x=>x._1)
.equalTo(y=>y._1)
.window(EventTimeSessionWindows.withGap(Time.seconds(2)))
.apply(new JoinFunction[(String,String,Long),(String,String,Long),(String,String,String)] {
override def join(first: (String, String, Long), second: (String, String, Long)): (String, String, String) = {
(first._1,first._2,second._2)
}
})
.print("输出")
env.execute("Session Event Time Window Join")
}
}
④.Interval Join(区间join)
间隔连接使⽤公共key连接两个流(现在将它们分别称为A和B)的元素,并且流B的元素时间位于流A的元素时间戳的间隔之中,则A和B的元素就可以join
b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound]
package com.baizhi.join
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.JoinFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
object IntervalWindowJoin {
def main(args: Array[String]): Unit = {
//获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
//设置流时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置水位线创建自动频率
env.getConfig.setAutoWatermarkInterval(1000) //1s
//获取输入流
var stream1 = env.socketTextStream("hbase",9999)
var stream2 = env.socketTextStream("hbase",8888)
//用于测试
println("===·S·T·A·R·T·===")
//处理流1 1 zs 1584196410000
val storm1 = stream1.map(_.split("\\s+"))
.map(x => (x(0), x(1), x(2).toLong))
.assignTimestampsAndWatermarks(new JoinEventTimeWater)
.keyBy(_._1)
//处理流2 1 apple 1584196410000
val storm2 = stream2.map(_.split("\\s+"))
.map(x=>(x(0),x(1),x(2).toLong))
.assignTimestampsAndWatermarks(new JoinEventTimeWater)
.keyBy(_._1)
//连接流
storm1.intervalJoin(storm2)
//设置边界
.between(Time.seconds(0),Time.seconds(2))
// .lowerBoundExclusive()//排除下边界
// .upperBoundExclusive()//排除上边界
.process(new ProcessJoinFunction[(String,String,Long),(String,String,Long),String]{
override def processElement(left: (String, String, Long), right: (String, String, Long), ctx: ProcessJoinFunction[(String, String, Long), (String, String, Long), String]#Context, out: Collector[String]): Unit = {
val lefte = ctx.getLeftTimestamp
val righte = ctx.getRightTimestamp
val timestamp = ctx.getTimestamp
val sdf = new SimpleDateFormat("HH:mm:ss")
println("左方元素时间戳是"+sdf.format(lefte)+"\t右边元素时间戳是"+sdf.format(righte)+"\t当前时间戳是"+sdf.format(timestamp))
out.collect(left._1+"\t"+left._2+"\t"+right._2+"\t")
}
})
.print("输出---->")
env.execute("Interval Event Time Window Join")
}
}