MyBatis-日志、分页、缓存
日志
如果一个数据库的操作出现了异常,这时候我们需要排错,日志就是最好的助手。
之前使用的是输出语句或者debug。现在使用的是日志工厂。
在MyBatis中具体使用哪一个日志实现,在设置中进行设定即可。在设定的时候注意区分大小写。
STDOUT_LOGGING
STDOUT_LOGGING标准日志输出。
在MyBatis核心配置文件中,配置日志。
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
settings>
Log4j
Log4j 是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件。
我们可以控制每一条日志的输出格式。
通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
1、导入log4j的包
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
2、编写 log4j.properties
#将等级为DEBUG的日志信息输出到console和file这两个目的地,console和file的定义在下面的代码
log4j.rootLogger=DEBUG,console,file
#控制台输出的相关设置
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n
#文件输出的相关设置
log4j.appender.file = org.apache.log4j.RollingFileAppender
log4j.appender.file.File=./log/llx.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=DEBUG
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c]%m%n
#日志输出级别
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
3、在核心配置文件中配置log4j为日志的实现
<settings>
<setting name="logImpl" value="LOG4J"/>
settings>
4、测试代码,可以看到日志的输出结果
log4j的使用:
-
在要使用Log4j 的类中,导入包 import org.apache.log4j.Logger;
-
日志对象,参数为当前类的class
static Logger logger = Logger.getLogger(UserDaoTest.class); -
日志级别
logger.info("info:进入了testLog4j"); logger.debug("debug:进入了testLog4j"); logger.error("error:进入了testLog4j");
分页
使用分页可以减少数据的处理量。
limit分页
limit语法:
SELECT * from user limit startIndex,pageSize;
SELECT * from user limit 3; #[0,n]
使用Mybatis实现分页:
1、编写接口方法
List<User> getUserByLimit(Map<String,Integer> map);
2、编写Mapper.xml文件
<select id="getUserByLimit" parameterType="map" resultMap="UserMap">
select * from mybatis.user limit #{startIndex},#{pageSize}
select>
3、测试
@Test
public void getUserByLimit(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("startIndex",1);
map.put("pageSize",2);
List<User> userList = mapper.getUserByLimit(map);
for (User user : userList) {
System.out.println(user);
}
sqlSession.close();
}
RowBounds分页
不使用SQL实现分页,使用RowBounds进行分页。
1、编写接口方法
List<User> getUserByRowBounds();
2、编写Mapper.xml文件
<select id="getUserByRowBounds" resultMap="UserMap">
select * from mybatis.user
select>
3、测试
@Test
public void getUserByRowBounds(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
//RowBounds实现
RowBounds rowBounds = new RowBounds(1, 2);
//通过Java代码层面实现分页
List<User> userList = sqlSession.selectList("com.llx.dao.UserMapper.getUserByRowBounds",null,rowBounds);
for (User user : userList) {
System.out.println(user);
}
sqlSession.close();
}
lombok
lombok是java的一个库,它会自动插入编辑器和构建工具中。在实体类上加上注解后,我们可以不用编写get和set方法,以及构造方法和toString方法等。
使用步骤:
-
在IDEA中安装lombok插件
-
在项目中导入lombok的包
<dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> <version>1.18.10version> dependency> -
在实体类上加上注解即可
@Data @AllArgsConstructor @NoArgsConstructor
lombok中的注解:
@Getter and @Setter
@FieldNameConstants
@ToString
@EqualsAndHashCode
@AllArgsConstructor, @RequiredArgsConstructor and @NoArgsConstructor
@Log, @Log4j, @Log4j2, @Slf4j, @XSlf4j, @CommonsLog, @JBossLog, @Flogger
@Data
@Builder
@Singular
@Delegate
@Value
@Accessors
@Wither
@SneakyThrows
@Data :无参构造,get、set、tostring、hashcode,equals
@AllArgsConstructor:有参构造
@NoArgsConstructor:无参构造
@EqualsAndHashCode:equals方法和hashCode方法
@ToString:toString方法
@Getter:get方法
@Setter:set方法
缓存
查询数据库是比较消耗资源的。我们可以将查询的结果放在内存(缓存)中,当再次查询相同的数据时,直接走缓存,不用走数据库。
缓存:存在内存中的临时数据。
将用户经常查询的数据放在缓存(内存)中,用户查询数据不用从磁盘上查询,从缓存中查询。从而提高查询的效率,解决了高并发系统的性能问题。
使用缓存可以减少和数据库的交互次数,减少系统开销,提高系统的效率。
经常查询且不经常改变的数据可以使用缓存。
MyBatis缓存
MyBatis包含一个非常强大的查询缓存特性,它可以非常方便地定制和配置缓存。使用缓存可以极大的提升查询效率。
MyBatis系统中默认定义了两级缓存:一级缓存和二级缓存。
- 默认情况下,只有一级缓存开启。(SqlSession级别的缓存,也称为本地缓存)
- 二级缓存需要手动开启和配置,他是基于namespace级别的缓存。
- 为了提高扩展性,MyBatis定义了缓存接口Cache。我们可以通过实现Cache接口来自定义二级缓存。
一级缓存
一级缓存也叫本地缓存: SqlSession。
- 与数据库同一次会话期间查询到的数据会放在本地缓存中。
- 以后如果需要获取相同的数据,直接从缓存中拿,没必须再去查询数据库。
测试在一个Sesion中查询两次相同记录:

缓存失效的情况:
-
查询不同的东西
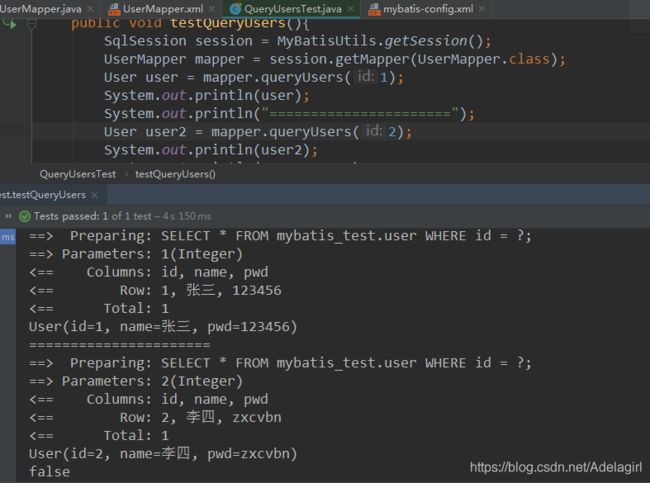
-
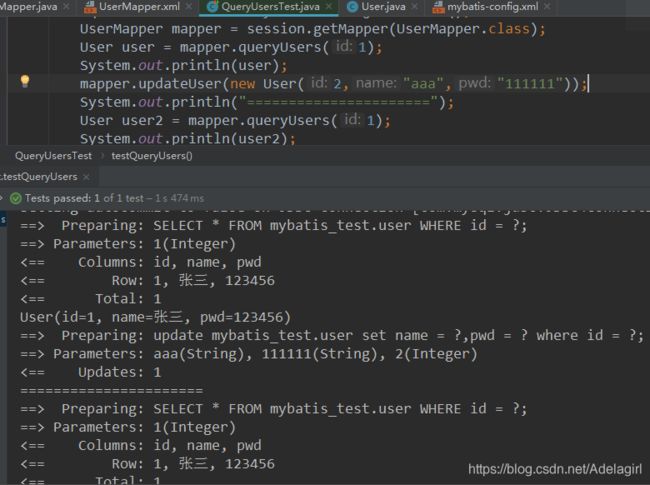
增删改操作,可能会改变原来的数据,所以必定会刷新缓存!
-
查询不同的Mapper.xml
-
手动清理缓存!
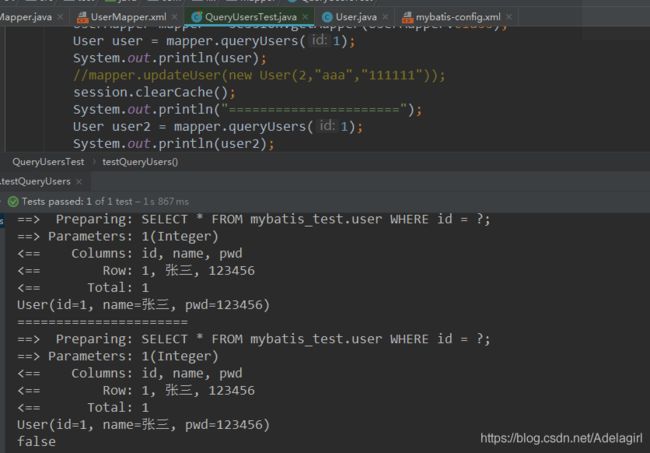
一级缓存默认是开启的,只在一次SqlSession中有效,也就是拿到连接到关闭连接这个区间段!
一级缓存就是一个Map。
二级缓存
二级缓存也叫全局缓存,一级缓存作用域太低了,所以诞生了二级缓存。
基于namespace级别的缓存,一个名称空间,对应一个二级缓存。
工作机制:
- 一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中
- 如果当前会话关闭了,这个会话对应的一级缓存就没了;但是我们想要的是,会话关闭了,一级缓存中的数据被保存到二级缓存中
- 新的会话查询信息,就可以从二级缓存中获取内容
- 不同的mapper查出的数据会放在自己对应的缓存(map)中
步骤:
-
开启全局缓存
<setting name="cacheEnabled" value="true"/> -
在要使用二级缓存的Mapper中开启
<cache/>也可以自定义参数
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/> -
测试
我们需要将实体类序列化,否则就会报错:
Caused by: java.io.NotSerializableException: com.kuang.pojo.User
总结:
- 只要开启了二级缓存,在同一个Mapper下就有效
- 所有的数据都会先放在一级缓存中;
- 只有当会话提交,或者关闭的时候,才会提交到二级缓冲中!
缓存原理
当用户查询数据的时候,程序会现在二级缓存中查找,若有则返回,若没有则在一级缓存中找;一级缓存中若有则返回,若没有则在数据库中找。
自定义缓存-ehcache
Ehcache是一种广泛使用的开源Java分布式缓存,主要面向通用缓存。
要在程序中使用ehcache,先要导包:
<dependency>
<groupId>org.mybatis.cachesgroupId>
<artifactId>mybatis-ehcacheartifactId>
<version>1.1.0version>
dependency>
在mapper中指定使用我们的ehcache缓存实现:
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
编写ehcache.xml:
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<diskStore path="./tmpdir/Tmp_EhCache"/>
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
<cache
name="cloud_user"
eternal="false"
maxElementsInMemory="5000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LRU"/>
ehcache>
Redis数据库来做缓存! K-V