Hive学习笔记
Hive
大数据课程Hive编程
给notepad++加一个插件远程操作Linux
将一个Hadoop高可用集群的一个节点修改为伪分布式集群
-
克隆
-
修改网卡
#修改静态IP vi /etc/sysconfig/network-scripts/ifcfg-ens33 #重启 systemctl restart network -
修改服务器的主机名(简化连接服务器操作)
#添加自定义主机名(hive1) [root@node1 ~]# vi /etc/hostname #重启 [root@node1 ~]# reboot -
配置主机名和ip地址的映射(简化日后操作集群,写主机名,自动翻译成主机地址)
#域名映射的配置文件,域名背后都对应一个IP地址 [root@hive1 ~]# vi /etc/hosts 192.168.108.120 hive1 测试是否配置成功 ping 主机名(hive1) -
修改C:\Windows\System32\drivers\etc
192.168.108.120 hive1 -
修改core-site.xml配置文件
#/usr/hadoop-2.6.0/hadoop-root/下存放NameNode和DateNode文件(每次重启会记录集群版本号,防止对新集群的干扰简单粗暴地删掉) [root@hive1 current]# cd /usr/hadoop-2.6.0/ [root@hive1 hadoop-2.6.0]# rm -rf hadoop-root/ [root@hive1 hadoop-2.6.0]# cd /usr/hadoop-2.6.0/ [root@hive1 hadoop-2.6.0]# vi etc/hadoop/core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hive1:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop-2.6.0/data/tmp</value> </property> </configuration> #创建新的临时文件夹存放DataNode和NameNode文件 [root@hive1 hadoop-2.6.0]# mkdir -p data/tmp -
修改hdfs-site.xml(/usr/hadoop-2.6.0/etc/hadoop/hdfs-site.xml)配置文件
<configuration> <property> <name>dfs.replicationname> <value>1value> property> configuration> -
修改mapred-site.xml
<configuration> <property> <name>mapreduce.framework.namename> <value>yarnvalue> property> configuration> -
修改yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> configuration> -
修改
#查看jdk安装目录 shell命令(里面也有变量,流程控制,函数。。。) #echo相当于java中的sout 输出此变量的值 [root@hive1 hadoop-2.6.0]# echo $JAVA_HOME -
格式化NameNode
[root@hive1 hadoop-2.6.0]# hdfs namenode -format -
启动hdfs和yarn相关进程
#启动NameNode DataNode resourcesmanager nodemanager [root@hive1 hadoop-2.6.0]# sbin/hadoop-daemon.sh start namenode [root@hive1 hadoop-2.6.0]# sbin/hadoop-daemon.sh start datanode [root@hive1 hadoop-2.6.0]# sbin/yarn-daemon.sh start resourcemanager [root@hive1 hadoop-2.6.0]# sbin/yarn-daemon.sh start nodemanager #---前提 要配免密---------------------------------------------------------- start-dfs.sh start-yarn.sh -
可视化页面
http://hive1:50070 http://hive1:8088(yarn MapReduce)
1. 引言
-
什么是Hive
1. Hive是apache组织提供的一个基于Hadoop的数据仓库产品 数据库 DataBase OLTP 数据量级小 数据价值高 数据仓库 DataWarehouse OLAP 数据量级大 数据价值低 2. Hive基于Hadoop 底层数据存储 HDFS 运算方式 MR -
原有MapReduce处理相关操作时,存在的问题|
mapreduce处理相关操作时,繁琐
mapReduce的作用:没有统计,没有分组合并,只做数据清洗,是可以没有reduce
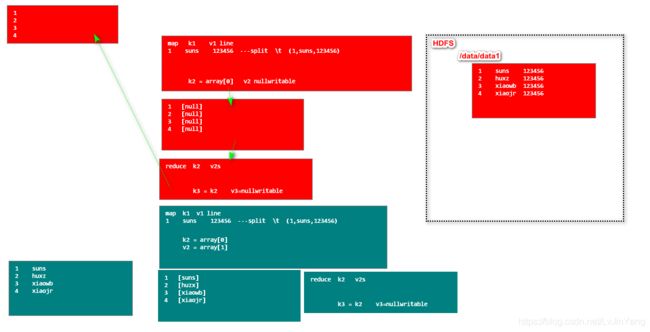
3. Hive核心设计思想
- metastore (rdb) 文件 — 数据库 相关概念的对应关系 (映射 Mapping)
- SQL —> 复杂的过程( 语法检查 语义检查 生成语法树 优化sql的执行顺序 )----> MapReduce
- 类SQL ( HQL Hive Query Language
HQL Hibernate Query Language )
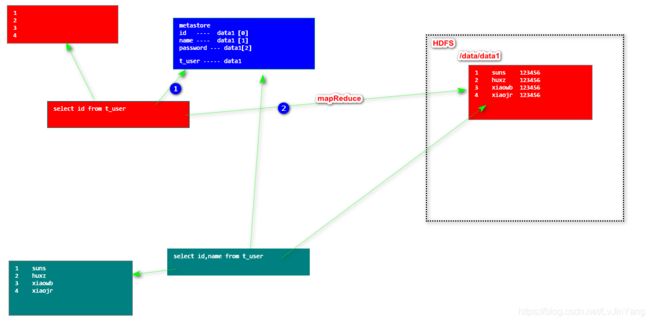
2. Hive的环境搭建和基本使用
-
hive安装
1. hadoop安装完成 2. 解压缩hive.tar 到 /opt/install 【Linux中默认安装 /usr 自己安装 /opt】 [root@hive1 ~]# cd /opt #创建放安装包的文件夹 [root@hive1 opt]# mkdir models #创建解压缩的文件夹 [root@hive1 opt]# mkdir install [root@hive1 opt]# cd models/ [root@hive1 models]# tar -zxvf apache-hive-0.13.1-bin.tar.gz -C /opt/install/ 3. 修改hive_home/conf/hive-env.sh # Set HADOOP_HOME to point to a specific hadoop install directory HADOOP_HOME=/usr/hadoop-2.6.0 #(hive配置文件目录) Hive Configuration Directory can be controlled by: export HIVE_CONF_DIR=/opt/install/apache-hive-0.13.1-bin/conf 4. (人家要求) 在hdfs 创建 /tmp /user/hive/warehouse [root@hive1 models]# hdfs dfs -mkdir /tmp [root@hive1 models]# hdfs dfs -mkdir -p /user/hive/warehouse 5. 启动hive进程 [root@hive1 apache-hive-0.13.1-bin]# cd /opt/install/apache-hive-0.13.1-bin/ [root@hive1 apache-hive-0.13.1-bin]# bin/hive 验证是否启动成功 jps --- runjar进程 -
hive基本使用
1. 查看hive中的所有数据库 hive> show databases; 2. 创建用户自己的库 create database baizhi_158; hive> create database if not exists baizhi_158; 3. 使用用户自定义的数据库 use db_name hive> use baizhi_158; # 所谓hive中的数据库,本质就是hdfs上的一级目录 默认: /user/hive/warehouse/${db_name}.db 4. 建表语句 hive> create table if not exists t_user( id int, name string )row format delimited fields terminated by '\t'; 5. 查看当前数据库中所有的表 hive> show tables; # 所谓hive中的表,本质就是hdfs上的一级目录 默认: /user/hive/warehouse/${db_name}.db/${table_name} /user/hive/warehouse/baizhi_158.db/t_user 6. hive中导入数据命令 创建要导入的数据 [root@hive1 ~]# mkdir -p hive/data [root@hive1 ~]# cd hive/data/ [root@hive1 data]# vi data1 插入测试数据 1 suns 2 xiaohei 3 huxz 4 xiaojr 5 gaozy load data local inpath '' into table table_name; 导入是追加 hive> load data local inpath '/root/hive/data/data1' into table t_user; # 所谓hive导入数据,本质就是hdfs中目录的数据文件 # 细节: 1. hive中的数据导入,本质上就是hdfs文件上传,删除表中的数据,本质上就是hdfs中文件的删除 hive load data local inpath '/root/hive/data/data1' into table t_user; hdfs bin/hdfs dfs -put /root/hive/data/data1 /user/hive/warehouse/baizhi_158.db/t_user 2. hive命令的数据导入,如果出现文件名相同的情况下,自动改名 3. hive中表的数据,只的是这个目录下,所有文件数据之和 4. hive 执行sql select * 的操作 不启动mr select column 启动mr
3. 切换MetaStore从derby到mysql
hive的metastore默认使用的derby数据库,进行映射存储
问题:derby作为metastore使用,只能让客户开启一个client进行访问
-
安装MySQL
0. [root@hive1 data]# yum install wget 1. wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm (25K) 2. yum -y install mysql57-community-release-el7-10.noarch.rpm 3. yum -y install mysql-community-server 4. systemctl start mysqld.service 5. mysql管理员密码 5.1 [root@hive1 ~]# grep "password" /var/log/mysqld.log 查看临时密码 A temporary password is generated for root@localhost: AcV=e )i#p1xe 5.2 [root@hive1 ~]# mysql -uroot -pAcV=e\)i#p1xe 5.3 修改密码 mysql> set global validate_password_policy=0; mysql> set global validate_password_length=1; mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '123456'; mysql> exit; 5.4 systemctl restart mysqld.service 5.5 mysql -uroot -p123456 6. 打开mysql远端访问权限 6.1 mysql> set global validate_password_policy=0; 6.2 mysql> set global validate_password_length=1; 6.3 mysql> GRANT ALL PRIVILEGES ON *.* TO root@"%" IDENTIFIED BY "123456"; 6.4 mysql> flush privileges; 6.5 [root@hive1 ~]# systemctl stop firewalld -
hive相关的设置
hive_home/conf/hive-site.xmljavax.jdo.option.ConnectionURL jdbc:mysql://hive1:3306/hive_mysql?createDatabaseIfNotExist=true&useSSL=false JDBC connect string fora JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for aJDBC metastore javax.jdo.option.ConnectionUserName root username to use againstmetastore database javax.jdo.option.ConnectionPassword 123456 password to use againstmetastore database -
mysql驱动jar 上传 hive/lib
4. yum加速
1. mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2. 下载 centos7文件 并且上传 /etc/yum.repos.d/
3. yum clean all
4. yum makecache
1、备份之前的仓库文件
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.back
2、下载阿里云的仓库文件
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3、清除缓存
yum clean all
yum makecache
5. Hive相关的配置参数
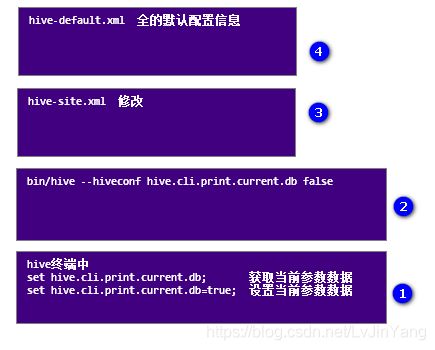
① set key; 查看当前设置值的情况
set key=value; 为key设置新的值
② bin/hive --hiveconf key value 测试时常使用在开启窗口的时候配置相关参数
③ *.site.xml 对*.default进行覆盖
core-site.xml commmons
hdfs-site.xml hdfs
副本数
FsImage
Editslog
yarn-site.xml yarn
mapred-site.xml MapReduce
④ *.default.xml 最全的默认配置
6. Hive的命令行启动参数
1. hive终端基本的形式
[root@hive1 apache-hive-0.13.1-bin]# cd /opt/install/apache-hive-0.13.1-bin/
[root@hive1 apache-hive-0.13.1-bin]# bin/hive
2. 启动hive的同时,设置hive的相关参数
[root@hive1 apache-hive-0.13.1-bin]# bin/hive --hiveconf hive.cli.print.current.db true
3. 启动hive的同时,指定数据库(一般配合2使用)
bin/hive --database db_name
[root@hive1 apache-hive-0.13.1-bin]# bin/hive --hiveconf hive.cli.print.current.db true --database baizhi_158
[root@hive1 apache-hive-0.13.1-bin]# bin/hive --database baizhi_158 --hiveconf hive.cli.print.current.db true
4. 启动hive的同时,运行sql语句(运行完会退出 很有价值 可以定时任务,晚上12点一个shell脚本定时启动任务)
[root@hive1 apache-hive-0.13.1-bin]# bin/hive --database baizhi_158 -e 'select * from t_user'
不用创建文件hive_file 覆盖
[root@hive1 apache-hive-0.13.1-bin]# bin/hive --database baizhi_158 -e 'select * from t_user' > /root/hive_file
查看内容
[root@hive1 apache-hive-0.13.1-bin]# more /root/hive_file
追加
[root@hive1 apache-hive-0.13.1-bin]# bin/hive --database baizhi_158 -e 'select * from t_user' >> /root/hive_file
5. 启动hive的同时,运行sql文件中的sql语句
bin/hive --database baizhi_158 -f /root/hive_sql
7. (重点)Hive相关SQL命令的详解
-
数据库相关
1. 创建数据库 create database if not exists db_name; // /user/hive/warehouse/db_name.db 自定义文件夹 hive> create database if not exists db_name location '/suns'; // 2. 显示所有数据库 hive> show databases; 3. 使用数据库 hive> use db_name; 4. 删除数据库 hive> drop database db_name; //删除空数据库 hive> drop database baizhi_158 cascade; //删除非空库 -
表的相关操作
-
管理表建表
0. 查看表的结构 1. 查看基本结构 desc table_name; hive> desc t_user; hive> describe t_user; 2. 查看表的扩展信息 hive> desc extended table_name; hive> desc extended t_user; 3. 格式化查看表的扩展信息 hive> desc formatted table_name; hive> desc formatted t_user; 1. 基本建表语句 create table if not exists table_name( id int, name string )row format delimited fields terminated by '\t'; 2. 指定表的存储位置 [root@hive1 ~]# hdfs dfs -mkdir /test create table test_1( id int, name string )row format delimited fields terminated by '\t' location '/test1'; 3. as 关键字建表 (洗数据) create table if not exists test2 as select name from t_user; 4. like 关键字建表 (只有表 没有数据) create table if not exists table_name like t_user; -
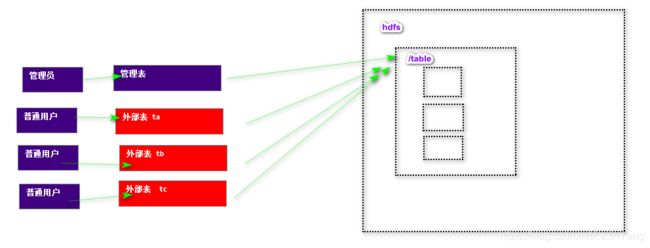
外部表
- 语法
1. 基本建表语句 create external table if not exists table_name( id int, name string )row format delimited fields terminated by '\t'; 2. 指定表的存储位置 create external table if not exists name( id int, name string )row format delimited fields terminated by '\t' location '/hdfs_path'; 3. as 关键字建表 (洗数据) CREATE-TABLE-AS-SELECT cannot create external table create external table if not exists test2 as select name from table_name; 4. like 关键字建表 create external table if not exists name2 like t_user;-
管理表与外部表的区别
删除表 hive (baizhi_158)> drop table test2; 1. 管理表删除后,在hive中表将被删除,同时hdfs上目录也会被删除 2. 外部表删除后,在hive中表将被删除,同时hdfs上目录不会被删除 (删除metastore中的信息)
-
-
分区表
分区表一般是用于对hive查询进行优化使用,为了提高查询效率
-
桶表(了解)
-
临时表(了解)
8.(重点) 数据的导入
1. 本地数据的导入(linux) 【重点】
load data local inpath '' into table table_name
2. hdfs中导入数据
load data inpath '' into table table_name
本质:目录中的数据移动
3. hdfs相关shell完成文件导入
bin/hdfs dfs -put 'local_path' '/user/hive/warehouse/db_name.db/table_name'
4. as关键字 【重点】
创建表的同时,通过查询导入数据
create table t_xxx as select id,name from t_yyy;
5. insert关键字 【重点】
表已经存在,通过查询导入数据
insert into table xxxx select id,name from t_user;
9.(重点)数据的导出
1. insert导出 【重点】
导出的数据 mr 自动生成
insert overwrite local directory '/root/xiaohei' select name from t_user;
2. hdfs的shell 【了解】
bin/hdfs dfs -get 'user/hive/warehouse/db_name.db/table' '/root/xxx'
3. hive启动的命令行参数 【了解】
bin/hive --database 'baizhi129' -f /root/hive.sql > /root/result
4. sqoop方式 【重点】
5. Hive导入 导出命令【了解】
1. export 导出
export table tb_name to 'hdfs_path'
2. import 导入
import table tb_name from 'hdfs_path'
10. Hive中HQL (类SQL)
1. 基本查询
select * from t_user; 不启动mr
select id from t_user; 启动mr
2. where
select * from t_user where id = xxx;
3. 常见谓词 in between and
4. 逻辑运算 and or not
5. 分组函数 count() avg() sum() max() min()
6. 分组 group by
7. 排序 order by
8. 分页 limit
不支持 limit 2,3
9. 多表联合查询
select e.id,e.name,d.dname
from t_emp e
inner join t_dept d
on e.dept_id = d.id;
10. 内置函数(窗口函数)
select length(name) from t_user_like;
select length('suns')
to_date
year
select substring('suns',1,2)
11. hive不支持子查询
11. Hive中与MapReduce相关的参数设置
1. mapreduce中map个数?
textInputFormat --- > block ----> split ----> map
dbInputFormat ----> 1 row ----> 1 split ----> 1 map
2. mapreduce中reduce个数?
默认 1 个
mapred-default.xml
mapreduce.job.reduces
1
job中应用过程中reduce 0---n
job.setReduceNumTasks()
3.Hive中MapReduce相关参数的设置
hive-site.xml
hive.exec.reducers.bytes.per.reducer
1000000000
hive.exec.reducers.max
999
12. Hive中特殊参数设置
hive-site.xml
hive.fetch.task.conversion
minimal
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only 不启动MR,非上述3种情况,会启动MR
2. more : SELECT, FILTER, LIMIT only (TABLESAMPLE, virtual columns) 所有select,where,limit 都不起MR
13.Hive没有集群
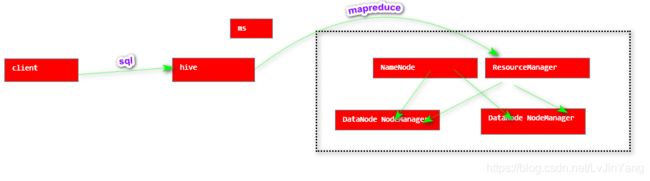
14.实战中如何使用Hive?
总结:hive是一种离线处理的大数据技术,不需要实时产生处理结果,所以在hive中所做的相关操作,最终通过Sqoop导入RDB,通过Java程序直接访问RDB获得相应的结果。
15.Sqoop (CDH)
Hadoop 各种发行版本
1. apache开源版 : 免费 难用
2. Cloudera (CDH) Doug Cutting首席架构师 $4000 1个
3. Hortonworks $12000 10个
-
搭建CDH版Hadoop及其Hive
1. 解压缩hadoop 1.1将 cdh5.3.6-snappy-lib-natirve.tar.gz hadoop-2.5.0-cdh5.3.6.tar.gz hive-0.13.1-cdh5.3.6.tar.gz sqoop-1.4.5-cdh5.3.6.tar.gz 上传到/opt/models/里 1.2解压缩到/opt/install/下 [root@hive1 models]# tar -zxvf hadoop-2.5.0-cdh5.3.6.tar.gz -C /opt/install/ 2. 创建临时目录的位置 hadoop_home/data/tmp [root@hive1 ~]# cd /opt/install/hadoop-2.5.0-cdh5.3.6/ [root@hive1 hadoop-2.5.0-cdh5.3.6]# mkdir -p data/tmp 3. 修改配置文件 hadoop_home/etc/hadoop hadoop-env.sh yarn-env.sh mapred-env.sh core-site.xmlfs.defaultFS hdfs://hive1:8020 hadoop.tmp.dir /opt/install/hadoop-2.5.0-cdh5.3.6/data/tmp dfs.replication 1 dfs.permissions.enabled false mapreduce.framework.name yarn yarn.nodemanager.aux-services mapreduce_shuffle javax.jdo.option.ConnectionURL jdbc:mysql://hive1:3306/cdhhive_mysql?createDatabaseIfNotExist=true&useSSL=false JDBC connect string fora JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for aJDBC metastore javax.jdo.option.ConnectionUserName root username to use againstmetastore database javax.jdo.option.ConnectionPassword 123456 password to use againstmetastore database hive.cli.print.current.db true Whether to include the current database in the Hive prompt. hive.cli.print.header true Whether to print the names of the columns in query output. -
安装Sqoop
1. 解压缩Sqoop [root@hive1 models]# tar -zxvf sqoop-1.4.5-cdh5.3.6.tar.gz -C /opt/install/ 2. 修改配置 sqoop_home/conf 修改conf/sqoop-env.sh export HADOOP_COMMON_HOME=/opt/install/hadoop-2.5.0-cdh5.3.6 export HADOOP_MAPRED_HOME=/opt/install/hadoop-2.5.0-cdh5.3.6 export HIVE_HOME=/opt/install/hive-0.13.1-cdh5.3.6 3. mysql-connect.jar copy sqoop_home/lib 4. 测试sqoop是否正常使用 bin/sqoop list-databases -connect jdbc:mysql://hive1:3306 -username root -password 123456 information_schema cdhhive_mysql hive_mysql mysql performance_schema sys-
sqoop命令的书写规范
1. 一行写 bin/sqoop list-databases -connect jdbc:mysql://hive1:3306 -username root -password 123456 2. 每一个关键字一行 bin/sqoop list-databases \ --connect \ jdbc:mysql://hive1:3306 \ --username root \ --password 123456 -
mysql的准备工作
[root@hive1 ~]# mysql -uroot -p123456 #mysql 创建数据库 创建表 mysql> create database sqoop; mysql> use sqoop; create table mysql_user( id int primary key, name varchar(12) ); insert into mysql_user values (1,'suns1'); insert into mysql_user values (2,'suns2'); insert into mysql_user values (3,'suns3'); insert into mysql_user values (4,'suns4'); insert into mysql_user values (5,'suns5'); insert into mysql_user values (6,'suns6'); insert into mysql_user values (7,'suns7'); insert into mysql_user values (8,'suns8'); -
Sqoop的Import(导入)
bin/sqoop import \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table mysql_user # Sqoop 进行的数据导入和导出,本质上也是运行的MapReduce # 如果不指定hdfs的导入路径,那么sqoop生成默认值 /user/root/${table_name} # mapReduce的目标是数据库,所以Map的数量,由数据库的行数决定 # 导出文件的列分割符,是,# 指定sqoop导入位置 bin/sqoop import \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table mysql_user \ --target-dir /sqoop# 删除已存在的目标目录 bin/sqoop import \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table mysql_user \ --target-dir /sqoop \ --delete-target-dir# 设置map的个数 bin/sqoop import \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table mysql_user \ --target-dir /sqoop \ --delete-target-dir \ --num-mappers 1 # 查看内容存入的内容 [root@hive1 hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -text /sqoop/part-m-00000# 设置列分隔符 bin/sqoop import \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table mysql_user \ --target-dir /sqoop \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by '\t'# 快速导入 使用mysql 导出工具 dump bin/sqoop import \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table mysql_user \ --target-dir /sqoop \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by '\t' \ --direct #细节: sqoop 需要和 mysql 安装在同一个节点 如果没有安装在同一个节点,需要把mysql/bin下的内容 复制到sqoop机器# 增量导入 --check-columnSource column to check for incremental id --last-value Last imported value in the incremental 5 --incremental Define an incremental import of type append 'append' or 'lastmodified' --delete-target-dir \ 不需要加 bin/sqoop import \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table mysql_user \ --target-dir /sqoop \ --num-mappers 1 \ --fields-terminated-by '\t' \ --direct \ --check-column id \ --last-value 5 \ --incremental append # 导入到hive表 #--hive-import \ #--hive-database baizhi_158 \ #--hive-table t_user \ bin/sqoop import \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table mysql_user \ --delete-target-dir \ --hive-import \ --hive-database baizhi_158 \ --hive-table t_user \ --num-mappers 1 \ --fields-terminated-by '\t' -
Sqoop的Export (HDFS/Hive ----> MySQL )
bin/sqoop export \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table to_mysql \ --export-dir /sqoop \ --num-mappers 1 \ --input-fields-terminated-by '\t' -
Sqoop脚本化编程
-
sqoop文件
create table filetomysql( id int, name varchar(12) ); 1. 创建一个Sqoop文件 普通文件 sqoop.file export --connect jdbc:mysql://hive1:3306/sqoop --username root --password 123456 --table filetomysql --export-dir /sqoop --num-mappers 1 --input-fields-terminated-by '\t' 2. 执行文件 bin/sqoop --options-file /root/sqoop.file -
job作业
1. 创建作业 bin/sqoop job \ --create test_job1 \ -- \ export \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password 123456 \ --table filetomysql \ --export-dir /sqoop \ --num-mappers 1 \ --input-fields-terminated-by '\t' 2. 执行job作业 bin/sqoop job --exec test_job1(job_id) 3. 解决job作业执行过程中的密码输入问题 echo -n "123456" >> /root/password bin/sqoop job \ --create test_job2 \ -- \ export \ --connect \ jdbc:mysql://hive1:3306/sqoop \ --username root \ --password-file file:///root/password \ --table filetomysql \ --export-dir /sqoop \ --num-mappers 1 \ --input-fields-terminated-by '\t' bin/sqoop job -exec test_job2
-
-
思考Sqoop实战,主要的应用方式
1. 安装crontab (centos7 默认安装) yum -y install vixie-cron yum -y install crontabs 2. 启动服务 systemctl start crond.service systemctl stop crond.service systemctl restart crond.service /sbin/service crond start /sbin/service crond stop ps -ef | grep crond 3. 编辑定时计划 crontab -e minute hour day month week command */5 * * * * command */1 * * * * echo 'suns' >> /root/sunshuai */1 * * * * /opt/install/sqoop-1.4.5-cdh5.3.6/test_job2.sh 0 0 * * * /opt/install/sqoop-1.4.5-cdh5.3.6/test_job2.sh 【https://www.cnblogs.com/tiandi/p/7147031.html】
-
oop
–username root
–password-file file:///root/password
–table filetomysql
–export-dir /sqoop
–num-mappers 1
–input-fields-terminated-by ‘\t’
bin/sqoop job -exec test_job2
```
-
思考Sqoop实战,主要的应用方式
1. 安装crontab (centos7 默认安装) yum -y install vixie-cron yum -y install crontabs 2. 启动服务 systemctl start crond.service systemctl stop crond.service systemctl restart crond.service /sbin/service crond start /sbin/service crond stop ps -ef | grep crond 3. 编辑定时计划 crontab -e minute hour day month week command */5 * * * * command */1 * * * * echo 'suns' >> /root/sunshuai */1 * * * * /opt/install/sqoop-1.4.5-cdh5.3.6/test_job2.sh 0 0 * * * /opt/install/sqoop-1.4.5-cdh5.3.6/test_job2.sh 【https://www.cnblogs.com/tiandi/p/7147031.html】