A Unified MRC Framework for Named Entity Recognition | ACL2020
论文地址: https://arxiv.org/pdf/1910.11476.pdf
1.论文目的
该论文主要解决 ""嵌套型"的NER(Nested NER) 的问题.往常的工作中主要是针对非嵌套型”的NER(Flat NER),但是在当遇到嵌套型NER就会有问题.
2.论文tricks
如下图所示的两个例子所示
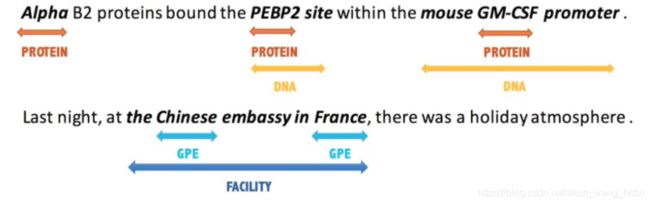
论文创造性的引入 MRC(Machine Reading Comprehensio) 的思想来解决嵌套型NER的问题.

如上图所示:我们可以对某些实体引入相对应的问题,使模型更明白我们要提取什么实体.这些问题是人为设计的.
(1)模型输入
那么具体的模型输入以bert为例子:
[CLS]question[SEQ]text[SEQ]
(2)loss function
模型的loss function:
- 关于实体start index的loss function

sequence_output, pooled_output, _ = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
sequence_heatmap = sequence_output # batch x seq_len x hidden
start_logits = self.start_outputs(sequence_heatmap) # batch x seq_len x 2
start_loss = loss_fct(start_logits.view(-1, 2), start_positions.view(-1))
![]()
sequence_output, pooled_output, _ = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
sequence_heatmap = sequence_output # batch x seq_len x hidden
end_logits = self.end_outputs(sequence_heatmap) # batch x seq_len x 2
end_loss = loss_fct(end_logits.view(-1, 2), end_positions.view(-1))

sequence_output, pooled_output, _ = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
sequence_heatmap = sequence_output # batch x seq_len x hidden
batch_size, seq_len, hid_size = sequence_heatmap.size()
start_extend = sequence_heatmap.unsqueeze(2).expand(-1, -1, seq_len, -1)
end_extend = sequence_heatmap.unsqueeze(1).expand(-1, seq_len, -1, -1)
# the shape of start_end_concat[0] is : batch x 1 x seq_len x 2*hidden
span_matrix = torch.cat([start_extend, end_extend], 3) # batch x seq_len x seq_len x 2*hidden
span_logits = self.span_embedding(span_matrix) # batch x seq_len x seq_len x 1
span_logits = torch.squeeze(span_logits) # batch x seq_len x seq_len
span_loss_fct = nn.BCEWithLogitsLoss()
span_loss = span_loss_fct(span_logits.view(batch_size, -1), span_positions.view(batch_size, -1).float())
这里不是太理解,我个人的推想是算出各个位置token是start或者end 之后,通过矩阵计算哪个S和E是正确实体的S和E
