Machine Reading Comprehension: The Role of Contextualized Language Models and Beyond
机器阅读理解(MRC)旨在教机器阅读和理解人类语言,这是自然语言处理(NLP)的长期目标。随着深度神经网络的爆发和上下文语言模型(contextualized language models-CLM)的发展,MRC的研究经历了两个重大突破。作为一种现象,MRC和CLM对NLP社区有很大的影响。在本次调查中,我们提供了有关MRC的全面,比较性综述,涵盖了有关以下方面的总体研究主题:1)MRC和CLM的起源和发展,尤其着重于CLM的作用;2)MRC和CLM对NLP社区的影响; 3)MRC的定义,数据集和评估; 4)从人类认知过程的角度出发,从两阶段编码器-解码器解决架构的角度来看,一般的MRC架构和技术方法;5)以前的重点,新兴的话题以及我们的经验分析,其中我们特别关注在MRC研究的不同时期有效的方法。我们建议对这些主题进行全视图分类和新的分类法。 我们得出的主要观点是:1)MRC促进了从语言处理到理解的进步; 2)MRC系统的快速改进极大地受益于CLM的开发; 3)MRC的主题正逐渐从浅的文本匹配转变为认知推理。
1.Introduction
自然语言处理(NLP)任务可以大致分为两类:1)基本的NLP,包括语言建模和表示,以及语言结构和分析,包括形态分析,分词,句法,语义和语篇配对等;2)NLP应用,包括机器问答,对话系统,机器翻译以及其他语言理解和推理任务。 随着NLP的飞速发展,自然语言理解(NLU)引起了广泛的兴趣,一系列的NLU任务应运而生。 在早期,NLU被视为NLP的下一阶段。随着更多可用的计算资源,更复杂的网络成为可能,并且激励研究人员朝着人类语言理解的前沿发展。 在NLU领域,机器阅读理解(MRC)作为一项新的典型任务不可避免地蓬勃发展。 图1概述了语言处理和理解背景下的MRC
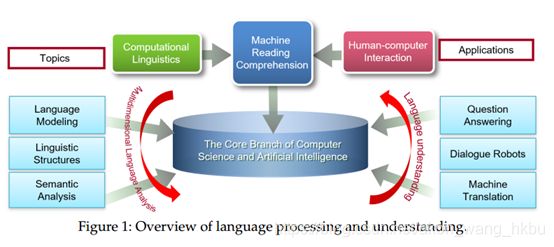
MRC是NLU的一项长期目标,旨在教机器读取和理解文本数据。 它具有重要的应用场景,例如问题解答和对话系统. MRC的相关研究可以追溯到故事理解的研究. 经过数十年的衰落,MRC成为最近的热门研究课题,并且经历了快速的发展。 MRC对NLU和更广泛的NLP社区具有至关重要的影响。作为涉及综合知识表示,语义分析和推理的NLP的主要挑战性问题之一,MRC在过去十年中激发了巨大的研究兴趣。MRC的研究经历了两个重要的高峰,即:1)深度神经网络的爆发; 2)上下文化语言模型(CLM)的发展。图2显示了过去五年中MRC和CLM的研究趋势统计。
随着深度神经网络的引入和像NLP中的注意机制这样的有效架构,MRC的研究兴趣自2015年左右开始蓬勃发展。 主要主题是细粒度的文本编码以及更好的段落和问题交互.
CLM引领上下文化语言表示的新天堂-使用整个句子级别的表示进行语言建模作为预训练,而LM的上下文相关隐藏状态用于下游任务特定的fine-tuning。 深度预训练的CLM大大增强了语言编码器的功能,MRC的基准测试结果显着提高,这刺激了向更复杂的阅读,理解和推理系统发展的过程。结果,MRC的研究越来越接近于人类认知和现实应用。 另一方面,越来越多的研究人员有兴趣分析和解释MRC模型的工作原理,并研究数据集之外的真实能力,例如对抗攻击的表现以及MRC数据集的benchmark的容量。人们普遍担心的是,MRC系统的能力被高估了,这表明它仍然处于浅表理解阶段,这是从表面模式匹配启发式方法得出的。 对模型和数据集的这种评估对于MRC方法学的下一阶段研究将具有启发性。

尽管很明显,从长远来看,计算能力极大地增强了MRC系统的能力,但构建简单,可解释且实用的模型对于实际应用同样重要。 回顾过去的突出亮点是有益的。 通用性质,尤其是过去的有效方法以及MRC对NLP社区的启发,将为将来的研究提供启示,这是本工作讨论的重点。
这项工作审查了MRC,涵盖了背景,定义,影响,数据集,技术和基准测试成功率,经验评估,当前趋势和未来机会的范围。 我们的主要贡献概述如下:
- 全面审查和深入讨论
我们对MRC的起源和发展进行了全面的回顾,特别关注了CLM的作用。 通过从认知心理学的角度将MRC系统表述为两阶段求解体系,我们提出了MRC技术体系的新分类法,并对研究主题进行了全面的讨论以获取见解。 通过调查有关不同类型的MRC的典型模型和主要旗舰数据集和排行榜的趋势,以及我们的经验分析,我们可以观察到不同研究阶段技术的进步。
- 涵盖重点和新兴主题
MRC经历了快速的发展。 我们介绍了以前的重点和新兴主题,包括将传统的NLP任务转换为MRC形式,多种粒度特征建模,结构化知识注入,上下文化的句子表示,匹配交互和数据增强,涵盖了这些内容。
- 未来展望
这项工作总结了未来研究的趋势和讨论,包括数据集和模型的可解释性,先决技能的分解,复杂的推理,大规模理解,低资源MRC,多模式语义基础以及更深而有效的模型设计。
本调查的其余部分安排如下:首先,我们介绍了CLM的背景,分类和派生词,并在§2中讨论了CLM和MRC之间的相互影响。 §3中给出了MRC的概述,包括对一般NLP范围,编队,数据集和评估指标的影响; 然后,我们从两阶段求解体系结构的角度讨论技术方法,并总结第4节中的主要主题和面临的挑战; 接下来,我们将在§5中进行更深入的研究,通过回顾典型MRC模型中的趋势和重点,发现在MRC的不同阶段有效的方法。 我们的经验分析也被报告用于验证基于强大CLM的简单有效的策略优化; 最后,我们在§6中讨论了趋势和未来机会,并在§7中得出了结论。
2. The Role of Contextualized Language Model
2.1 From Language Model to Language Representation
语言建模是用于自然语言处理的深度学习方法的基础。 学习单词表示法一直是一个活跃的研究领域,并引起了数十年的巨大研究兴趣,包括非神经方法和神经方法。 关于语言建模,基本主题是n-gram语言模型(LM)。 n-gram语言模型是单词(n-gram)序列上的概率分布,可以将其视为从(n-1)-gram预测unigram的训练目标。神经网络使用连续且密集的表示形式,或者进一步word embedding来进行预测,这对于减轻维数的诅咒是有效的–随着在越来越大的文本上训练语言模型,唯一词的数量增加。与Word2Vec或GloVe所学习的词嵌入相比,句子是人类使用语言时能提供完整含义的最小单位。 NLP的深度学习很快发现,这是使用网络组件对句子输入进行编码的常见要求,因此我们需要使用Encoder对整个句子级别的上下文进行编码。编码器可以是传统的RNN,CNN或最新的基于Transformer的架构,例如(例如ELMo,GPT,BERT,XLNet),RoBERTa,ALBERT和ELECTRA,用于捕获上下文化的句子级语言表示形式。这些编码器与滑动窗口输入(例如Word2Vec中使用的编码器)的不同之处在于它们覆盖整个句子,而不是滑动窗口使用的任何固定长度的句子片段。 当我们必须在MRC任务中处理段落时,这种区别尤其重要,因为段落中总是包含很多句子。 当模型面对段落时,句子而不是单词是段落的基本单位。 换句话说,MRC以及NLP的其他应用程序任务都需要一个句子级编码器,以将句子表示为嵌入内容,从而捕获深度和上下文相关的句子级信息。
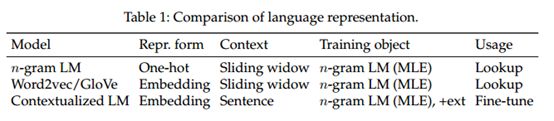
可以采用n-gram语言模型的样式来训练编码器模型,以便出现语言表示,其中包括四个元素:1)表示形式; 2)上下文; 3)训练对象(例如n-gram语言模型); 4)用法。 对于上下文化语言表示,每个单词的表示取决于使用该单词的整个上下文,这是动态embedding。 表1给出了三种主要语言表示方法的比较。
2.2 CLM as Phenomenon
2.2.1 Revisiting the Definition.
首先,我们想回顾一下最近的上下文编码器的定义。 对于代表性模型,ELMo被称为深度上下文化词表示,以及用于语言理解的深度双向转换器的BERT预训练。 随着后续研究的进行,有研究称这些模型为预训练(语言)模型. 我们认为这样的定义是合理的,但不够准确。 就语言表示体系结构的演变以及当今这些模型的实际用法而言,应该将这些模型的重点放在上下文中(以ELMo的名义显示)。作为有限的计算资源的共识,通常的做法是在公开预训练的资源之后使用特定于任务的数据微调模型,因此预训练既不是必需的,也不是核心要素。 如表1所示,训练目标是从n-gram语言模型得出的。 因此,我们认为预训练和微调只是我们使用模型的方式。 本质是语言模型中的深度上下文表示; 因此,在本文中,我们称这些预训练模型为上下文化语言模型(CLM)。
2.2.2 Evolution of CLM Training Objectives.
在这一部分中,我们将抽象出n-gram语言模型与随后的上下文化LM技术之间的内在联系。 然后,考虑培训目标的重要作用,我们详细阐述了典型CLM的演变。
关于语言模型的训练,标准和通用做法是使用n-gram语言建模。 这也是CLM中的核心培训目标。 n-gram语言模型在文本(n-gram)序列上产生概率分布,这是经典的最大似然估计(MLE)问题。 语言建模也称为自回归(AR)方案。
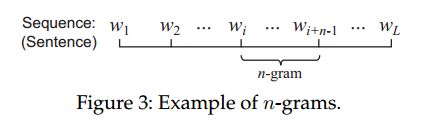
具体而言,给定一个文本中的n个项的序列![]() (图3),该序列的概率测量为
(图3),该序列的概率测量为

其中![]() 表示序列中
表示序列中![]() 的条件概率,以通过
的条件概率,以通过![]() 上的上下文表示来估计。 LM训练是通过最大化可能性来执行的:
上的上下文表示来估计。 LM训练是通过最大化可能性来执行的:

其中θ表示模型参数
在实践中,已证明n-gram模型在建模语言数据方面非常有效,而语言数据是现代语言应用程序的核心组成部分。 早期的上下文表示是通过静态word embedding和网络编码器获得的。例如,CBOW和Skip-gram要么使用上下文预测单词,要么逐单词预测上下文,其中n-gram上下文由固定的滑动窗口提供。训练后的模型参数作为单词嵌入矩阵(也称为查找表)输出,其中包含词汇表中每个单词的上下文无关表示。 然后将向量用在神经网络的低层(即嵌入层)中,并且进一步使用编码器(例如RNN)来获取输入句子的上下文表示。
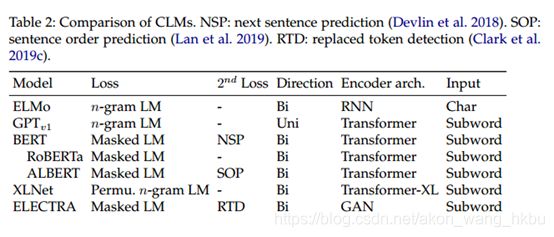
对于最近的LM派生的上下文呈现,后续优化的重点是上下文。 他们用更大的n-grams训练,它们覆盖了整个句子,其中n扩展到句子长度-当n扩展到最大时,条件上下文因此对应于整个序列。单词表示是整个句子的功能,而不是预定义查找表上的静态向量。 相应的功能模型被视为上下文化语言模型。这样的上下文模型可以直接用于为任务特定的微调生成上下文敏感的句子级别表示。 表2显示了CLM的比较。
对于输入句子![]() ,我们从等式(2)在长度L的上下文中扩展n-gram语法LM的目标:
,我们从等式(2)在长度L的上下文中扩展n-gram语法LM的目标:
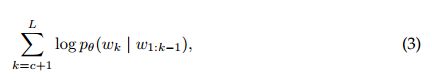
其中c是将序列分为非目标条件子序列k≤c和目标子序列k> c的切入点。 它可以进一步以双向形式编写:
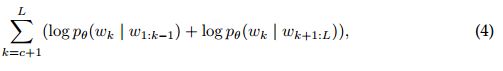
它对应于ELMo中使用的双向LM。 ELMo的双向建模是通过独立训练的向前和向后LSTM的串联实现的。
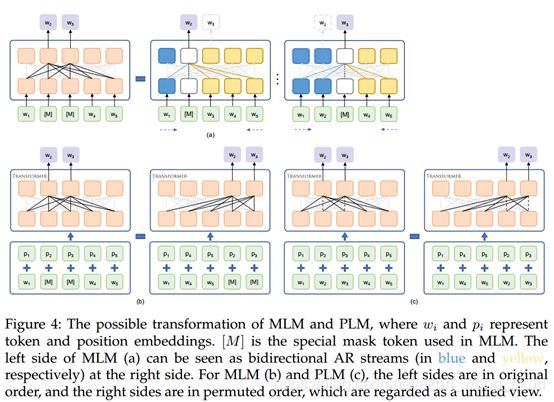
为了允许同时进行双向(或非定向)训练,BERT采用了Transformer一次处理整个输入,并提出了Masked LM(MLM)以利用左右上下文的优势。 句子中的某些标记被概率很小的特殊掩码符号随机替换。 然后,训练模型以基于上下文预测被屏蔽的tokens。
在某种程度上,可以将MLM视为n-gram LM的一种变体(图4(a)--双向自回归n-gram LM.令D使用掩码符号[M]表示掩码位置的集合。 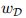 为被屏蔽tokens的集合,
为被屏蔽tokens的集合,![]() 为被屏蔽语句的集合。 如图4(b)左侧所示,
为被屏蔽语句的集合。 如图4(b)左侧所示, 和
和![]() MLM的目标是最大化以下目标:
MLM的目标是最大化以下目标:

与等式(4)相比,很容易发现预测是基于等式(5)中的整个上下文,而不是每个估计仅基于一个方向,这表明了BERT和ELMo的主要差异。 但是,BERT的本质问题是,在进行微调时始终看不到mask符号,这会导致预训练和微调之间不匹配.
为了缓解这个问题,XLNet利用置换LM(PLM)使因子分解阶的所有可能置换的预期对数似然性最大化,这是AR LM的目标。对于输入句子![]() ,我们将
,我们将![]() 作为排列组合集{1,2,···,L}。
作为排列组合集{1,2,···,L}。
对于排列组合![]() ,我们将z分为非目标条件子序列z≤c和目标子序列z> c,其中c是切点。目的是最大化以非目标tokens为条件的目标tokens的对数似然性:
,我们将z分为非目标条件子序列z≤c和目标子序列z> c,其中c是切点。目的是最大化以非目标tokens为条件的目标tokens的对数似然性:
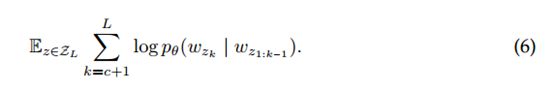
MLM和PLM的关键都是根据从n-gram导出的特定上下文来预测单词,这些单词可以在统一视图中建模。详细地,在单词顺序不敏感的假设下,当输入句子是可置换的(具有不敏感的单词顺序)时,MLM可以直接统一为PLM,如图4(b-c)所示。由于基于BERT和XLNet的基于Transformer的模型的性质,因此可以满足要求。 Transformer将标记及其在句子中的位置作为输入,并且对这些标记的绝对输入顺序不敏感。 因此,MLM的目标函数也可以写成排列形式,

其中![]() 表示位置
表示位置![]() 中的特殊掩码标记[M]。
中的特殊掩码标记[M]。
从等式(3),(6)和(7),我们看到MLM和PLM与n-gram LM具有相似的公式,但P(s)中的条件上下文部分略有不同:![]() 和
和![]() 上的MLM条件,以及
上的MLM条件,以及![]() 上的PLM条件。MLM和PLM都可以由n-gram LM解释,甚至可以统一成一个通用形式。在类似的启发下,MPNet结合了Masked LM和Premuted LM来充分利用这两个优势。
上的PLM条件。MLM和PLM都可以由n-gram LM解释,甚至可以统一成一个通用形式。在类似的启发下,MPNet结合了Masked LM和Premuted LM来充分利用这两个优势。
2.2.3 Architectures of CLMs
到目前为止,主要有三种主要的语言建模体系结构:RNN,Transformer和Transformer-XL。 图5描述了三种编码器架构。
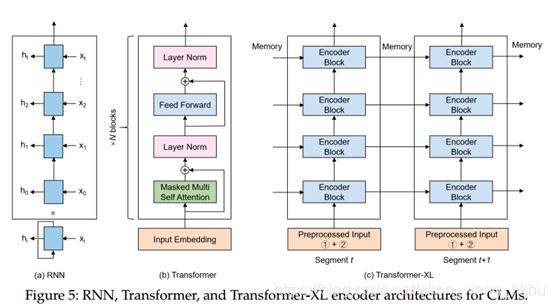
RNN。 RNN及其派生词是用于语言编码和建模的流行方法。 广泛使用的变体是GRU和LSTM。 RNN模型一一处理输入标记(通常是单词或字符)以捕获它们之间的上下文表示。 但是,RNN的处理速度很慢,并且由于梯度消失,学习长期依存关系的能力仍然受到限制。
Transformer。 为了缓解RNN的上述问题,提出了Transformer,该Transformer采用多头自注意模块接收tokens(即子词)的一部分,并将相应的position embedding作为输入,从而立即学习序列的直接连接。 一一处理token的过程。
Transformer-XL。 尽管RNN和Transformer体系结构都取得了令人瞩目的成就,但它们的主要局限性在于捕获了远程依赖关系。 Transformer-XL结合了RNN和Transformer的优势,后者在输入数据的每个段上都使用了自注意力模块,并使用递归机制来学习连续段之间的依存关系。 详细地,提出了两种新技术:
Segment-level Recurrence.
提出了递归机制,以通过使用来自先前分段的信息来对长期依赖性进行建模。 在训练过程中,为前一个片段计算的表示形式将被固定并缓存,以便在模型处理下一个新片段时用作扩展上下文。 此重复机制在解决上下文碎片问题方面也很有效,为新段的前面的tokens提供了必要的上下文。
Relative Positional Encoding.
原始位置编码分别处理每个段。 结果,来自不同段的tokens具有相同的位置编码。 与仅位于第一层之前的编码位置相反,新的相对位置编码被设计为每个注意力模块的一部分。 它基于tokens之间的相对距离,而不是其绝对位置。
2.2.4 Derivative of CLMs.
预训练和微调已成为NLP的新范例,其主要主题是构建强大的编码器。 基于令人印象深刻的模型(如ELMo和BERT)的启发,提出了各种各样的CLM派生工具。 在这一部分中,我们讨论有关MRC任务的各种主要变体。 表3显示了CLM衍生产品的性能比较。 这些模型背后的进步主要有四个主题:

Masking Strategy.
BERT的原始掩码基于subword,这不足以使用本地子字信号捕获全局信息。 SpanBERT提出了一种基于几何分布的随机跨度掩盖策略,这表明所提出的掩蔽有时甚至比掩盖语言一致的跨度更好。为了避免在每个epoch中对每个训练实例使用相同的Mask,RoBERTa每次向模型输入序列时都使用动态Mask来生成mask pattern,这表明动态mask对于预训练很多步骤或使用较大步数至关重要。 缩放数据集。 ELECTRA通过采用替换的tokens检测目标,提高了mask效率。
Knowledge Injection
通过embedding fusion和masking,可以轻松地将额外的知识合并到CLM中。 SemBERT指出,融合语义角色标签嵌入和单词嵌入可以产生更好的语义级别的语言表示,这表明显着的单词级别的高级标记功能可以与子单词级别的标记表示很好地集成在一起。 SG-Net提出了一种兴趣依赖掩盖策略,以将语法信息用作更好的语言学启发表示的约束。
Training Objective
除了语言模型中使用的核心MLE损失外,还研究了一些其他目标,以更好地适应目标任务。 BERT采用了下一个句子预测(NSP)损失,它与NLI任务中的配对形式相匹配。 为了更好地模拟句子间的连贯性,ALBERT用句子顺序预测(SOP)损失代替了NSP损失。 进一步StuctBERT 在预训练中将单词级排序和句子级排序作为结构目标。SpanBERT使用跨度边界目标(SBO),该模型要求模型基于跨度边界预测掩盖的跨度,以将结构信息集成到预训练中。 UniLM通过三种类型的语言建模任务扩展了掩码预测任务:单向,双向和序列到序列(Seq2Seq)预测。 Seq2Seq MLM也被用作目标,它采用统一的Text to Text Transformer进行通用语言建模。 ELECTRA提出了新的预训练任务-替代了tokens检测(RTD),并据此设计了生成器鉴别器模型。 训练生成器执行MLM,然后鉴别器预测被替代的输入中的每个标记是否被生成器样本替换.
Model Optimization
RoBERTa发现,可以通过以下方法大大提高模型性能:1)训练模型时间更长,批次更大,数据量更多。 2)删除下一句预测目标; 3)训练更长的序列; 4)对训练数据进行动态masking。 Megatron提出了一种层内模型并行方法,可以有效地训练非常大的transformer模型。为了获得重量轻但功能强大的模型以供实际使用,模型压缩是一种有效的解决方案。 ALBERT使用跨层参数共享和因式分解参数化来减少模型参数。 知识蒸馏(KD)也引起了人们的关注。 BERT-PKD提出了一种承受KD机制,该机制可从教师模型的多个中间层中学习以进行增量知识提取。DistilBERT在预训练阶段利用了一种知识蒸馏机制,该机制引入了三重损失,将语言建模,蒸馏和余弦距离损失结合在一起。 TinyBERT采用了具有嵌入输出,隐藏状态和自我注意分布的分层蒸馏。 MiniLM对老师的最后一个Transformer层的自注意力分布和价值关系进行了提炼,以指导学生模型训练。 此外,量化是通过压缩参数精度的另一种优化技术。 Q-BERT应用了基于Hessian的混合精度方法以最小的精度损失和更有效的推断来压缩模式。
2.3 Correlations Between MRC and CLM
从实践的角度来看,MRC和CLM是相辅相成的。 MRC是一个具有挑战性的问题,涉及到全面的知识表示,语义分析和推理,这引起了极大的研究兴趣并刺激了包括CLM在内的各种高级模型的开发。 如表4所示,MRC还可作为语言表示的适当测试平台,这是CLM的重点。 另一方面,CLM的进步极大地促进了MRC任务,使模型性能获得了可观的提升。 有了这种必不可少的关联,人类同等性能已首次实现,并且在CLM发布后经常得到报道。

3. MRC as Phenomenon
3.1 Classic NLP Meets MRC
MRC对NLP任务有很大的启发。 大多数NLP任务都可以从MRC这样的新任务中受益。 优势可能在于以下两个方面:1)MRC样式模型的强大功能,例如保持成对训练模式(如CLM的预训练)和上下文更好的建模(如多回合问题解答); 2)以MRC的形式统一不同的任务,并利用多任务处理来共享和转移知识。
传统的NLP任务可以转换为QA形式的上下文理解,包括问题回答,机器翻译,摘要,自然语言推理,情感分析,语义角色标记,zero-shot关系提取,面向目标的对话,语义解析, 和常识代词解析。 MRC的跨度提取任务的形成还为标准文本分类和回归任务(包括GLUE基准中的那些以及实体和关系提取任务)带来了优越或可比的性能。 由于MRC旨在评估机器模型对人类语言的理解程度,因此该目标实际上类似于“对话状态跟踪(DST)”的任务。 最近的研究通过为对话状态中的每个槽值(slot)专门设计一个问题,将DST任务表述为MRC形式,并提出了用于对话状态跟踪的MRC模型。
3.2 MRC Goes Beyond QA
在大多数NLP / CL论文中,MRC通常是针对给定参考文本(例如段落)的问答任务。正如Chen所讨论的,MRC和质量检查之间存在密切的关系。 (浅)阅读理解可以视为问答的一个实例,但它们强调的是不同的最终目标。我们认为,一般MRC是一个探究语言理解能力的概念,这与NLU的定义非常接近。相反,QA是一种格式,它应该是检查机器如何理解文本的实际方法。理由是难以衡量MRC的主要目标-评估人类语言的机器理解程度。为此,QA是一种相当简单有效的格式。 MRC还超越了传统的QA,例如通过引用开放文本来进行事实性质量保证或知识库质量保证,目的是避免对结构化手工知识库中的事实进行预先设计和检索的工作。因此,尽管MRC任务采用问题回答的形式,但它不仅可以看作是QA的扩展或变体,而且还可以看作是有关在某些情况下研究语言理解能力的新概念。 阅读理解是用来衡量通过阅读积累的知识的古老术语。 对于机器,它涉及对机器进行培训以阅读非结构化自然语言文本(例如书或新闻),理解和吸收知识,而无需人工管理。
从某种程度上说,传统的语言理解和推理任务,例如文本蕴涵(TE),在理论上也可以被视为一种MRC。 共同的目标是在阅读和理解输入文本后做出预测; 因此,通常会同时评估NLI和标准MRC任务,以评估模型的语言理解能力。 此外,它们的形式可以相互转换。 MRC可以形成为NLI格式,并且NLI也可以视为多选MRC(含蓄的,中立的或矛盾的)。
3.3 Task Formulation
给定参考文件或段落作为标准格式,MRC要求机器回答有关此文件的问题。 MRC的形成可以描述为元组
在MRC的探索中,构建高质量,大规模的数据集与优化模型结构同等重要。 继Chen(2018)之后,现有的MRC变体可以大致分为四类:1)完形填空; 2)选择题; 3)跨度提取,和4)自由形式预测。
3.4 Typical Datasets
Cloze-style
对于完形填空样式的MRC,问题包含一个占位符,并且计算机必须确定哪个词或实体是最合适的选项。 标准数据集包括CNN/Daily Mail,Children’s Book Test dataset (CBT),BookTest,Who did What,ROCStories,CliCR。
Multi-choice
此类MRC要求机器根据给定的段落在给定的候选选项中找到唯一正确的选项。 主要数据集是MCTest(Richardson,Burges和Renshaw 2013),QA4MRE(Sutcliffe等人2013),RACE(Lai等人2017),ARC(Clark等人2018),SWAG(Zellers等人2018)。 ,DREAM(Sun et al.2019a)等。
Span Extraction
在MRC类别中,答案是从给定段落中提取的跨度。 典型的基准数据集是SQuAD(Rajpurkar等人2016),TrivialQA(Joshi等人2017),SQuAD 2.0(有无法回答的问题的提要)(Rajpurkar,Jia和Liang 2018),NewsQA(Trischler等人2017), SearchQA(Dunn et al.2017)等
Free-form Prediction
这种类型的答案是基于对段落的理解的抽象自由形式。 形式多种多样,包括生成的文本范围,是/否判断,计数和枚举。 对于自由形式的质量检查,广泛使用的数据集是MS MACRO(Bajaj等人2016),NarrativeQA(Koˇcisky等人2018),Dureader(He等人2018)。 此类别还包括最近的会话式MRC,例如CoQA(Reddy,Chen和Manning 2019)和QuAC(Choi等人2018),以及涉及计数和算术表达式的离散推理类型(Dua等人2019)。 等
除了各种格式外,数据集还不同于1)上下文样式,例如,单段,多段,长文档和对话历史记录; 2)问题类型,例如开放式自然问题,完形填空和搜索查询; 3)回答形式,例如实体,词组,选择和自由形式的文本; 4)域,例如Wikipedia文章,新闻,考试,临床,电影剧本和科学文本; 5)具体的技能目标,例如无法回答的问题验证,多轮对话,多跳推理,数学预测,常识推理,共指解决。
3.5 Evaluation Metrics
对于完备的样式和多项选择的MRC,常见的评估指标是准确性。 对于基于范围的质量检查,广泛使用的指标是完全匹配(EM)和(宏观平均)F1得分。 EM衡量与任何一个真实答案完全匹配的预测比率。 F1分数用于衡量预测结果与真实答案之间的平均重叠程度。 对于非抽取形式,例如生成质量保证,答案不仅限于原始上下文,因此还采用了ROUGE -L(Lin 2004)和BLEU(Papineni等人2002)进行评估。
3.6 Towards Prosperous MRC
最新的MRC测试评估基于在线服务器,这需要提交模型以评估不可见的测试集的性能。 官方排行榜也可用于轻松比较大家提交的模型的好坏。 一个典型的例子是SQuAD。 开放而轻松的参与任务激发了MRC研究的繁荣,这可以为其他NLP任务提供很好的先例。 我们认为,MRC任务的成功可以归纳如下:
- Computable Definition
由于自然语言的含糊性和复杂性,一方面,一个清晰而可计算的定义是必不可少的(例如,clozestyle,multi-choice,span-based等)。
- Convincing Benchmarks
为了促进任何应用程序的进步,技术,开放和可比较的评估都是必不可少的,包括令人信服的评估指标(例如EM和F1)和评估平台(例如排行榜,自动在线评估)。
任务的定义与自动评估密切相关。 没有可计算的定义,就不会有可信的评估。
3.7 Related Surveys
先前的调查论文主要概述了MRC的现有语料库和模型。 我们的调查与以前的调查在以下几个方面有所不同:
- 我们的工作将更加深入,以提供更全面且可比较的评论,并从NLP场景的更广泛视角深入解释MRC的起源和发展,特别关注CLM的作用。 我们得出的结论是,MRC促进了从语言处理到理解的进步,并且MRC的主题正在从浅层文本匹配逐渐过渡到认知推理。
- 在技术方面,我们通过将MRC系统表述为基于认知心理学的两阶段体系结构,提出了MRC体系结构的新分类法,并对技术方法进行了全面的讨论。 我们总结了MRC开发不同阶段的技术方法和重点。 我们表明,MRC系统的快速改进极大地受益于CLM的进步。
- 除了通过研究MRC排行榜的典型模型和趋势,广泛涵盖了MRC研究中的主题之外,还提供了我们自己的实证分析。 还深入讨论了各种新出现的主题,例如,模型和数据集的解释,必备技能的分解,复杂的推理,资源匮乏的MRC等。 根据我们的经验,我们为MRC研究展示我们的观察和建议。
我们相信,这项调查将帮助受众更深入地了解MRC的发展和亮点,以及MRC与更广泛的NLP社区之间的关系
4. Technical Methods
4.1 Two-stage Solving Architecture
受认知心理学双过程理论的启发,人脑的认知过程可能涉及两种不同类型的过程:情境感知(阅读)和分析认知(理解),前者在隐式过程中收集信息,然后后者进行控制推理并执行目标。 基于上述理论基础,从体系结构设计的角度来看,解决MRC问题的标准阅读系统(阅读器)通常由两个模块或构建步骤组成:
1)建立一个CLM作为编码器;
2)根据任务特点设计巧妙的解码器机制。
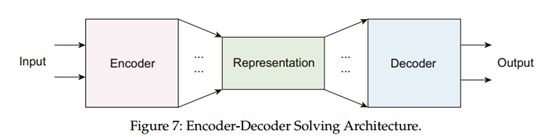
我们发现,从编码器-解码器体系结构的角度看,MRC系统的通用体系结构可通过表述为两阶段求解体系结构而最小化。 通用编码器将输入编码为上下文向量,解码器特定于特定任务。 图7显示了该体系结构。
4.2 Typical MRC Architecture
在此,我们根据上述编码器解码器框架介绍两种典型的MRC架构:1)传统的基于RNN的BiDAF和2)CLM支持的BERT。
4.2.1 Traditional RNN-based BiDAF.
在CLM发明之前,早期的研究广泛采用RNN作为序列的特征编码器,其中GRU由于其快速有效的性能而最受欢迎。 输入部分,例如段落和问题,分别输入到编码器。 然后,在预测答案之前,将编码后的序列传递给attention层,以匹配段落和问题之间的相互作用。 典型的MRC模型是BiDAF,它由四个主要层组成:1)编码层,将文本转换为单词和字符嵌入的联合表示; 2)使用BiGRU获得上下文化的句子级别表示的上下文编码; 3)attention层,对段落和问题之间的语义交互进行建模; 4)答案预测层产生答案。 前两层是Encoder的对应部分,后两层充当Decoder的角色
4.2.2 Pre-trained CLMs for Fine-tuning
使用CLM时,输入段落和问题会作为一个长序列连接在一起,以提供CLM,从而合并了基于RNN的MRC模型中的编码和交互过程。 因此,通用编码器已被很好地形式化为CLM,并附加了一个简单的特定于任务的线性层作为解码器来预测答案。
4.3 Encoder
编码器部分的作用是将自然语言文本向量化为潜在空间,并进一步对整个序列的上下文特征进行建模。
4.3.1 Multiple Granularity Features.
Language Units. 利用单词的细粒度特征是以前研究中的热门话题之一。 为了解决词汇量不足(OOV)问题,字符级embedding曾经是词embedding之外的一个常见单位。 但是,字符不是自然的最小语言单位,这使得探索字符和词之间的潜在单位(子词)以建模子词形态或词汇语义非常有价值。 为了同时利用单词级和字符级表示,还研究了MRC的子单词级表示。 在Zhang,Huang和Zhao(2018)中,我们提出了基于BPE的subword分割以缓解OOV问题,并进一步采用基于频率的过滤方法来加强对低频词的训练。 由于字符和单词之间的高度灵活的粒状表示,子单词作为基本有效的语言建模单元已被广泛用于最近的主导模型。
Salient Features. 语言功能(例如词性(POS)和命名实体(NE)标签)被广泛用于丰富单词嵌入。 诸如语义角色标签(SRL)标签和语法结构之类的一些语义功能也显示了对诸如MRC之类的语言理解任务的有效性。 此外,指示符功能(如二进制完全匹配(EM)功能)也是简单有效的指示,它可以测量问题中是否存在上下文词。
4.3.2 Structured Knowledge Injection.
将人类知识纳入神经模型是人工智能的主要研究兴趣之一。 最近基于Transformer的深度上下文语言表示模型已被广泛用于从大量未标记的数据中学习通用语言表示,在一系列NLU基准测试中取得了显著成绩。 但是,他们仅从普通的上下文相关功能(如字符或单词嵌入)中学习,而很少考虑人类语言中表现出的显式层次结构,这些结构可以为语言表示提供丰富的依赖提示。 最近的研究表明,对结构化知识进行建模已显示出对语言编码的好处,可以将其分为语言知识和常识。
Linguistic Knowledge. 语言语言学是人类智慧的产物,语法,语义的全面建模和语法对于为有效的语言建模和理解提供有效的结构化信息至关重要.
Commonsense. 目前,阅读理解仍然基于浅段提取,有限文本中的语义匹配以及常识知识的建模表示。 人们通过多年的知识积累已经学会了常识。 在人类眼中,“太阳从东方升起,在西方落下”是直截了当的,但是用机器学习是一个挑战。为了方便研究,提出了常识性任务和数据集,例如ROCStories,SWAG,CommonsenseQA,ReCoRD和Cosmos QA。 有几个常识性知识图可以作为优先知识来源,包括ConceptNet,WebChild和ATOMIC。 让机器有效地学习和理解人类常识以用于归纳,推理,计划和预测,是一个重要的研究课题。
4.3.3 Contextualized Sentence Representation.
以前,RNN(例如LSTM和GRU)被视为序列建模或语言模型中的最佳选择。 但是,循环体系结构具有致命缺陷,在训练过程中很难并行执行,从而限制了计算效率。 Vaswani等。 (2017)提出了Transformer,它完全基于自我关注而不是RNN或卷积。 Transformer不仅可以实现并行计算,还可以捕获任何跨度的语义相关性。 因此,越来越多的语言模型倾向于选择它作为特征提取器。 这些CLM在大型文本语料库上进行了预训练,可以很好地用作捕获上下文化句子表示形式的强大编码器。
4.4 Decoder
在对输入序列进行编码之后,解码器部分用于使用上下文化的序列表示来解决任务,该序列化表示特定于详细的任务要求。 例如,要求解码器为多选MRC选择适当的问题,或为基于跨度的MRC预测答案跨度。
直到最近,几乎所有MRC系统(即深入的预训练模型)都将重点放在编码器方面,因为系统可能会简单而直接地受益于足够强大的编码器。 同时,尽管已经显示出,无论编码器的如何强大(即,采用的预 训练有素的CLM)。 在这一部分中,我们从三个方面讨论解码器的设计:1)匹配网络; 2)答案指针,2)答案验证者和3)答案类型预测变量。
4.4.1 Matching Network.
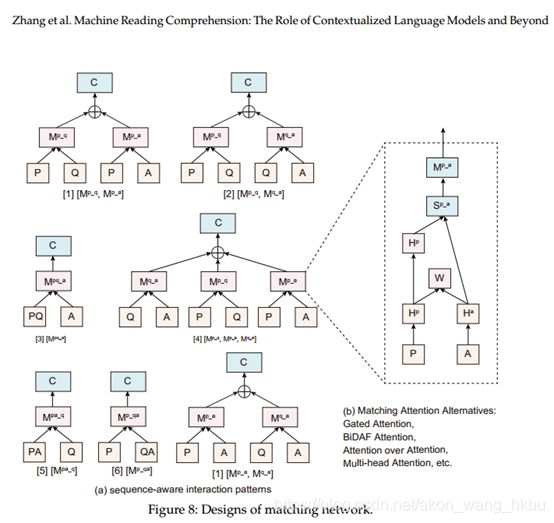
早期趋势是段落和问题之间基于注意的各种交互,包括:attention sum,Gated
Attention,Self-matching,BiDAF Attention,Attention over Attention和Co-match Attention。
在基于Transformer的backbones时代,一些工作还研究了基于注意力的段落和问题的交互,例如双重协同匹配注意。图8给出了考虑三种可能序列的完全匹配模式:段落(P),问题(Q ),并回答候选选项(A). 序列P,Q或A可以串联在一起,例如,PQ表示P和Q的串联。M被定义为匹配操作。 例如, ![]() 对P和A的隐藏状态之间的匹配进行建模。例如,我们在图8-(b)中描述了简单但广泛使用的匹配注意M,有关其表达的详细说明,请参见第5.6.3节。 参考。 然而,对匹配机制的研究已成为已经强大的CLM编码器的瓶颈,而CLM编码器本质上与模型配对序列具有交互作用。
对P和A的隐藏状态之间的匹配进行建模。例如,我们在图8-(b)中描述了简单但广泛使用的匹配注意M,有关其表达的详细说明,请参见第5.6.3节。 参考。 然而,对匹配机制的研究已成为已经强大的CLM编码器的瓶颈,而CLM编码器本质上与模型配对序列具有交互作用。
4.4.2 Answer Pointer.
跨度预测是MRC任务的主要重点之一。 大多数模型通过生成与估计答案范围相对应的开始位置和结束位置来预测答案。 指针网络用于早期MRC模型.
为了训练模型以预测MRC任务的答案范围,标准最大似然方法用于预测答案范围的完全匹配(EM)起始和结束位置。 这是一个严格的目标,它鼓励以精确的答案为代价,以惩罚有时同样准确的附近或重叠的答案为代价。 为了缓解该问题并预测更可接受的答案,采用了基于强化学习算法的自评判性策略学习来衡量预测答案和ground truth之间单词重叠时的奖励,从而朝着F1指标(而非EM指标)进行优化--基于跨度的MRC
4.4.3 Answer Verifier
对于有关MRC的问题无法解答的问题,读者必须谨慎处理两个方面:1)对回答的问题给出准确的答案; 2)有效分辨出无法回答的问题,然后拒绝回答。 通过引入额外的验证程序模块或答案验证机制,这些要求使读者的设计复杂化。 图9显示了验证程序的可能设计。 变体主要有三折(有关配方的详细说明,请参见第5.6节)
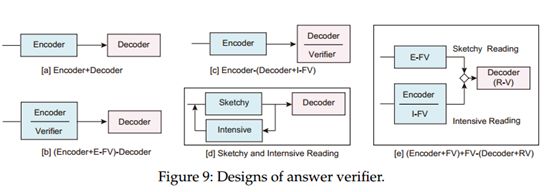
1)基于阈值的可回答验证(TAV)。 验证机制可以简化为超出预期范围概率的可回答阈值,该阈值被功能强大的CLM广泛使用以快速建立读者.
2)多任务样式验证(密集)。 通常,对于模块设计,答案跨度预测和答案验证是与多任务学习一起训练的(图9(c)). 刘等2018在上下文中添加了一个空词标记,并为读者添加了一个简单的分类层。 Hu等(2019c)使用两种类型的辅助损失,独立跨度损失来预测合理的答案和独立无答案损失来决定问题的可回答性。 此外,采用了额外的验证程序来确定输入的代码片段是否需要预测的答案(图9(b)). Back等。(2020)开发了一个基于注意力的满意度得分,以比较问题嵌入和候选答案嵌入。 它可以通过显示问题内未满足的条件来说明为什么将一个问题归类为不可回答(图9(c))。 张等。(9c)(2020c)提出了一种线性验证层,用于上下文嵌入,该上下文嵌入由上下文词表示形式的开始和结束分布加权,该上下文词表示形式与BERT的特殊[CLS]token表示形式相连接(图9(c))。
3)外部并行验证(概略)。 Zhang,Yang和Zhao(2020)提出了一个Retro-Reader,该阅读器整合了阅读和验证策略的两个阶段:1)粗略阅读,简短地涉及段落和问题的关系,并给出初步判断; 2)精读以验证答案并给出最终预测(图9(d))。 在实现中,该模型被构造为后验证(RV)方法,该方法将多任务样式验证作为内部验证(IV)与来自仅针对回答问题决策训练的并行模块的外部验证(EV)相结合。 并且实际上具有基本相同的性能,这最终导致了并行读取模块的设计,如图9(e)所示。
4.4.4 Answer Type Predictor
大多数神经阅读模型通常设计为提取连续范围的文本作为答案。 对于更加开放和现实的场景,其中答案涉及各种类型,例如数字,日期或文本字符串,可以使用几个预定义的模块来处理不同种类的答案。
4.5 Training Objectives
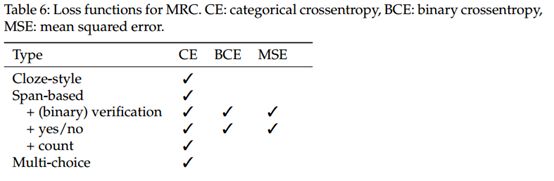
表6显示了不同类型的MRC的训练目标。 广泛使用的目标函数是交叉熵。 对于某些特定类型,例如二进制答案验证,分类交叉熵,二进制交叉熵和均方误差,也进行了研究(Zhang,Yang和Zhao 2020)。 同样,对于涉及“是”或“否”答案的任务,也可以使用三个替代功能。 为了进行计数,以前的研究倾向于使用交叉熵将其建模为多类分类任务。
5. Technical Highlights
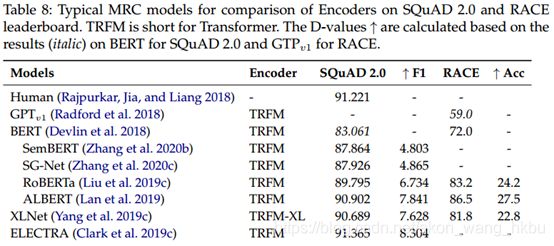
在这一部分中,我们通过回顾有关MRC主要类型,cloze-type CNN=DailyMail (Hermann et al. 2015), multi choice RACE (Lai et al. 2017)和pan extraction SQuAD (Rajpurkar et al. 2016; Rajpurkar, Jia, and Liang 2018), 表7、8、9、10、11显示了统计信息,从中我们总结了以下观察和想法(我们将在随后的部分中详细介绍):
1)CLM大大提高了当前MRC的基准。 携带大量知识的更深,更宽的编码器成为新的主题。 深度神经网络的编码能力尚未达到上限。 但是,训练此类CLM非常耗时且计算量大。 轻巧和精致的CLM对于现实世界和通用用法将更友好,这可以通过设计更巧妙的模型和学习策略以及知识蒸馏来实现。
2)近年来见证了匹配网络的减少。 早些年见证了基于注意力的机制的兴起,以改善段落和问题之间的交互和匹配信息,这些机制与RNN编码器配合得很好。 在CLM普及之后,优势消失了。 直观地讲,原因可能是CLM是基于交互的模型(例如,以成对的序列作为对交互进行建模的输入),但不是好的特征提取器。 这种差异可能是CLM的预训练类型,也可能是由于transformer架构所致。 从某种程度上讲,它还促进了从浅文本匹配到对MRC研究的更复杂的知识理解的转变。
3)除了编码方面,优化解码器模块对于获得更准确的答案也至关重要。 特别是对于要求模型确定问题是否可以回答的SQuAD2.0,通常需要训练单独的验证者或带有验证损失的多任务处理。
4)来自类似MRC数据集的数据扩充有时会起作用。 除了使用TraiviaQA或NewsQA数据集作为额外训练数据报道的一些工作外,还有许多提交的名字中包含有关数据扩充的术语。 同样,在CLM领域中,很少有使用扩充的工作。 此外,CLM的预训练也可以视为数据增强,这对于提高性能具有很大的潜力。
在下面的部分中,我们将详细介绍以前的工作的重点。 我们还进行了一系列的经验研究,以评估简单的策略优化,作为感兴趣的读者的参考(第5.6节)
5.1 Reading Strategy
关于MRC挑战的解决方案的见解可以从人类的认知过程中得出。 因此,基于人类的阅读模式,提出了一些有趣的阅读策略,例如“学习略读文本”,“学习停止阅读”以及我们提出的回顾性阅读。 此外,还提出了三种通用策略:来回阅读,突出显示和自我评估,以改善非抽取性MRC。
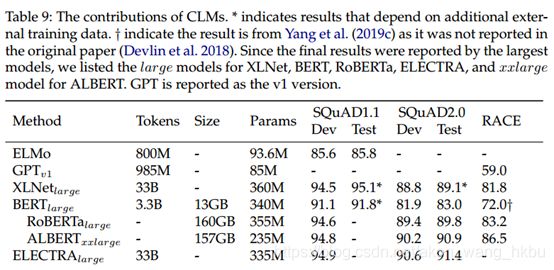
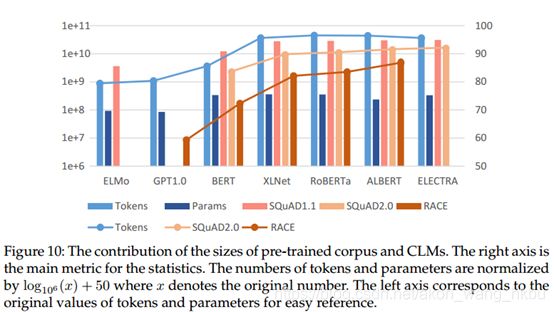
5.2 CLMs Become Dominant
如表9所示,CLM将MRC基准提高到了更高的阶段。 除了上下文化的句子级表示法外,CLM的进步还与更大的模型大小和大规模的预训练语料库有关。 从表9和图10的进一步说明中,我们看到模型大小和训练数据的规模都在显着增加,这有助于下游MRC模型的性能.
5.3 Data Augmentation
由于大多数高质量的MRC数据集都是人工注释的,并且不可避免地相对较小,因此提高性能的另一种简单方法是数据增强。 早期有效的数据增强是为训练特定模型注入额外的相似MRC数据。 最近,使用预先在大规模未标记语料库上进行过训练的CLM也可以视为一种数据增强。
训练数据扩充。 有多种方法可以提供额外的数据来训练功能更强大的MRC模型,包括:1)将各种MRC数据集组合为训练数据增强(TDA); 2)多任务; 3)自动生成问题,例如反向翻译和综合生成。但是,我们发现使用CLM时获得的收益很小,因为CLM可能已经包含了不同数据集之间最常见和最重要的知识。
大规模的预培训。 最近的研究表明,CLM通过预培训很好地获得了语言信息(第6.1节中有更多讨论),这对于在MRC任务上取得令人印象深刻的结果很有可能。
5.4 Decline of Matching Attention
如表10-11所示,很容易注意到注意机制是以前基于RNN的MRC系统中的关键组件。
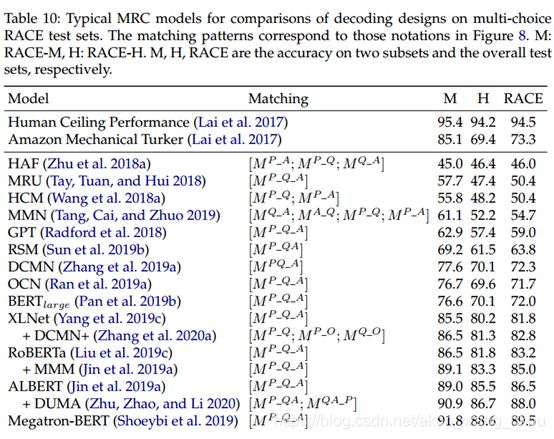
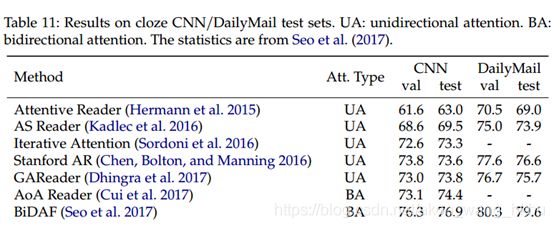
我们看到双向注意(BA)的效果比单向注意更好,并且共同注意是一种更好的匹配方法,它表明了更多轮匹配的发展,这将有效地直观地捕获更多的细粒度信息。 当使用CLM作为编码器时,我们观察到显式的段落和问题关注只能显示出非常小的边缘,甚至性能下降。 原因可能是,当采用段落和问题的整个串联序列时,CLM是基于交互的匹配模型。不建议将其用作代表模型。 Bao等(2019)也报道了类似的观察结果,表明BERT中序列的统一建模优于之前分别处理编码和匹配的网络。
在CLM进行上下文编码后,可能已经很好地建模了用于理解理解的主要连接,并且重要信息被汇总到特殊tokens的表示形式中,例如BERT的[CLS]和[SEP]。 我们发现上述CLM的编码过程与传统RNN的编码过程大不相同,传统RNN的每个tokens的隐藏状态在一个方向上连续传递,而没有质量聚集和表示的退化。这种现象可以解释为什么输入序列之间的交互注意 与基于RNN的特征提取器配合使用时效果很好,但在CLM领域没有明显优势。
5.5 Tactic Optimization
答案验证的目的。 为了进行答案验证,将目标建模为分类或回归将对最终结果产生轻微影响。 但是,基于backbone网络的进展可能会有所不同,因为一些工作由于性能更好而导致了回归损失,而最近的工作报告说在某些情况下分类会更好。
答案范围内的依赖性。 最近基于CLM的模型将跨度预测部分简化为独立的分类目标。 但是,结束位置与开始预测有关。 作为早期工作中的一种常用方法,联合集成起始逻辑和序列隐藏状态以获得最终逻辑,有可能进一步增强。 最近另一个被忽略的方面是答案范围内所有标记的依赖性,而不是仅考虑开始和结束位置。
重新排列候选答案。 答案重排适用于模仿双重检查的过程。 一种简单的策略是在从神经网络生成答案后使用N最佳排序策略。 与之前的对候选答案进行排名的工作不同,Hu等人。 (2019a)提出了一种算术表达式重新排名机制,以对通过beam search解码的候选表达进行排名,以在重新排名期间合并其上下文信息以进一步确认预测。
5.6 Empirical Analysis of Decoders
为了获得关于如何进一步改善MRC的见识,我们报告了针对不依赖主干模型的,广泛使用的SQuAD2.0数据集,通过常规,直接的策略优化来改善模型性能的尝试。 这些方法包括三种类型:验证,交互和应答依赖。
5.6.1 Baseline.
我们采用BERTlarge和ALBERTxxlarge作为基准。
Encoding.
首先将输入的句子标记为单词(subword tokens)。 令![]() 表示长度为L的子字标记的序列。对于每个token,输入的embedding是其token embedding,position embedding和token-type embedding的总和。令
表示长度为L的子字标记的序列。对于每个token,输入的embedding是其token embedding,position embedding和token-type embedding的总和。令![]() 是编码器的输出,是长度为L的编码语句词的嵌入特征。然后,将输入的嵌入内容馈送到深层的Transformer层中,以学习上下文表示。令
是编码器的输出,是长度为L的编码语句词的嵌入特征。然后,将输入的嵌入内容馈送到深层的Transformer层中,以学习上下文表示。令![]() 是第g层的特征。
是第g层的特征。![]() 的特征
的特征![]() 由下式计算
由下式计算
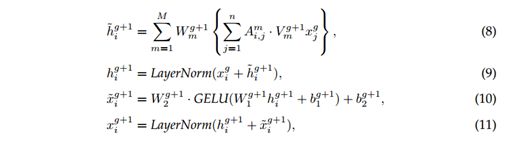
其中m是attention heads的索引,![]() 表示第m个元素中元素i和j之间的attention weights,通过
表示第m个元素中元素i和j之间的attention weights,通过![]() 归一化。
归一化。![]() 和
和![]() 是第m个attention head的可学习权重.
是第m个attention head的可学习权重. ![]() 和
和![]() 分别是可学习的权重和偏置。最后,我们得到输入序列
分别是可学习的权重和偏置。最后,我们得到输入序列![]() 的最后一层隐藏状态作为输入序列的上下文表示。
的最后一层隐藏状态作为输入序列的上下文表示。
Decoding.
基于跨度的MRC的目的是找到通道中的跨度作为答案,因此我们采用具有SoftMax操作的线性层,并以H作为输入,以获取起始和终止概率s和e:
![]()
基于阈值的可回答验证(Threshold based answerable verification :TAV)。 对于无答案的问题预测,给定输出的开始和结束概率s和e,以及验证概率v,我们计算具有答案的分数![]() 和没有答案的分数
和没有答案的分数![]()
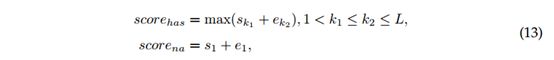
其中s1和e1表示特殊tokens[CLS]的对应logits,如用于答案验证的基于BERT的模型中一样。 我们获得has-answer和no-answer之间的差异分数作为最终分数。 根据development set设定并确定可回答阈值δ。 如果最终分数高于阈值δ,则模型会预测给出具有答案分数的答案范围,否则预测为空字符串。
Training Objective.
答案跨度预测的训练目标定义为开始和结束预测的交叉熵损失
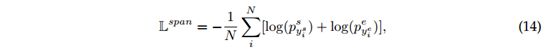
其中![]() 和
和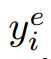 分别是示例i的ground-truth开始和结束位置。 N是示例数。
分别是示例i的ground-truth开始和结束位置。 N是示例数。
5.6.2 Verification
答案验证对于涉及无法回答的MRC任务至关重要。 我们尝试添加一个外部独立的分类器模型,该模型与MRC模型相同,但训练目标(E-FV)除外。 我们对预测的验证对数和原始启发式无答案对数进行加权,以决定问题是否可以回答。 此外,我们还研究了如何在原始跨度损失和验证损失之间添加多任务处理作为内部前置验证器(internal front verifier :I-FV)。 内部验证损失可以是交叉熵损失(I-FV-CE),二进制交叉熵损失(I-FV-BE)或回归样式均方误差损失(I-FV -MSE)。
合并的第一个标记(特殊符号,[CLS])表示形式![]() ,作为序列的整体表示形式,被传递到完全连接层以获取分类对数或回归得分。 假设
,作为序列的整体表示形式,被传递到完全连接层以获取分类对数或回归得分。 假设![]() 表示预测,而
表示预测,而![]() 是可回答性目标,则三个替代损失函数定义如下:
是可回答性目标,则三个替代损失函数定义如下:
(1)将交叉熵作为损失函数进行分类验证:
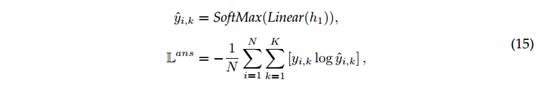
其中K是类数。 在这项工作中,K = 2。
(2)对于二进制交叉熵作为分类验证的损失函数:
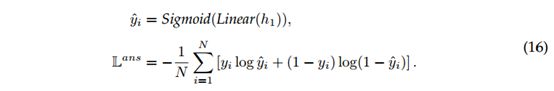
(3)对于回归验证,采用均方误差作为其损失函数:
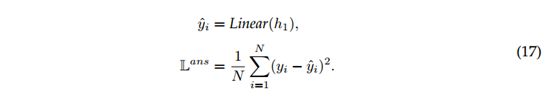
在训练期间,FV的联合损失函数是跨度损失和验证损失的加权总和。
![]()
其中α1和α2是权重。 我们为实验设置α1=α2= 0.5
我们凭经验发现,进行联合损失训练可以产生更好的结果,因此我们还报告了以下结果:1)所有I-FV损失的总和(所有I-FV:I-FV-CE,I-FV-BE和I -FV MSE),2)通过计算E-FV和I-FV的logits之和(表示为v)作为最终可回答的logits,将外部和内部验证(所有I-FV + E-FV)组合在一起。 在后一种情况下,TAV被重写为
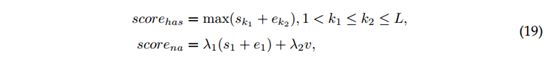
其中λ1和λ2是权重。 我们设置λ1=λ2= 0.5。
5.6.3 Interaction.
为了获得每个段落和问题的表示,我们根据其位置信息将最后一层隐藏状态H分为![]() 和
和![]() 作为问题和段落的表示。在一个小批量中,这两个序列都被填充到最大长度。 然后,我们研究了两种潜在的问题感知匹配机制:1)Transformer-style multi-head attention(MH-ATT),以及2)traditional dot attention(DT-ATT)
作为问题和段落的表示。在一个小批量中,这两个序列都被填充到最大长度。 然后,我们研究了两种潜在的问题感知匹配机制:1)Transformer-style multi-head attention(MH-ATT),以及2)traditional dot attention(DT-ATT)
- Multi-head Attention
我们将![]() 和H馈送到经过Lu et al. (2019)等人启发的经过修订的一层多头注意力层。由于多头自注意力的设置为Q = K = V,它们都是从输入序列中得出的,我们将输入Q替换为H,将K和V都替换为
和H馈送到经过Lu et al. (2019)等人启发的经过修订的一层多头注意力层。由于多头自注意力的设置为Q = K = V,它们都是从输入序列中得出的,我们将输入Q替换为H,将K和V都替换为![]() 以得到问题的感知上下文表示
以得到问题的感知上下文表示![]() 。
。
- Dot Attention
另一种选择是通过将问题表示![]() 作为对表示
作为对表示![]() 的关注,将
的关注,将![]() 和H馈送到传统的匹配attention层:
和H馈送到传统的匹配attention层:
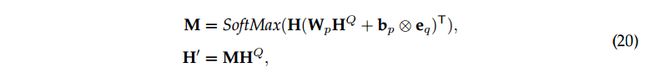
其中![]() 和
和![]() 是可学习的参数。
是可学习的参数。 ![]() 是一个全1的向量,用于将偏差向量重复到矩阵中。 M表示在有关的两个序列中分配给不同隐藏状态的权重。
是一个全1的向量,用于将偏差向量重复到矩阵中。 M表示在有关的两个序列中分配给不同隐藏状态的权重。 ![]() 是所有隐藏状态的加权和,它表示H中的向量如何与
是所有隐藏状态的加权和,它表示H中的向量如何与![]() 中的每个隐藏状态对齐。
中的每个隐藏状态对齐。
最后,如上面的解码和TAV部分所述,将表示![]() 用于以后的预测。
用于以后的预测。
5.6.4 Answer Dependency
最近的研究分别使用H来预测答案的开始和结束范围,而忽略了开始和结束表示的依赖性。 我们通过将起始logits和H通过一个线性层连接起来以获得结束logits,来对起始logits和结束logits之间的依赖关系进行建模:
![]()
其中[; ]表示concatenation.
5.6.5 Findings
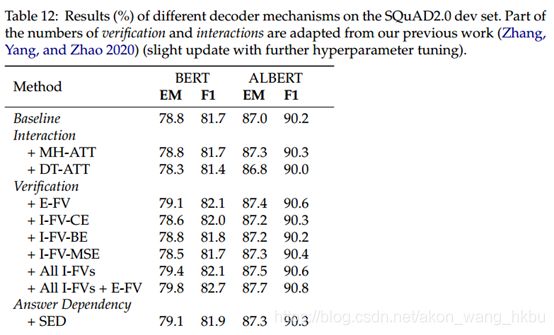
表12示出了结果。 我们的观察结果如下:
- 对于答案验证,任何一个前端验证器都可以提高基线,并且集成所有验证器可以产生更好的结果。
- 在强大的CLM之后添加额外的交互层只会带来微不足道的改善,这证明了CLM捕获段落和问题之间关系的强大能力
- 答案依赖性可以有效地提高精确匹配分数,从而可以直观地帮助您获得更精确匹配的答案范围。
6. Trends and Discussions
6.1 Interpretability of Human-parity Performance
近年来,在MRC排行榜上经常出现关于超过人类水平的结果的报道,这进一步激发了研究MRC系统的“真正”能力以及系统掌握的知识或阅读理解技能的研究兴趣。 这种解释吸引了CLM模型,MRC数据集和模型的各个方面。
对于CLM模型。 由于CLM模型是上下文文本表示的基本模块,因此指出要捕获的知识,尤其是CLM处理模型所具有的语言能力,对于微调下游任务至关重要,对于MRC也是至关重要的。 关于CLM模型最近学到的内容,引起了激烈的讨论。 最近的工作试图通过研究多头注意力层的注意力图来进行解释(Clark等人2019b),并进行诊断测试(Ettinger 2020)。 克拉克等(2019b)发现attention heads非常适合语法和共指的语言概念。 Ettinger(2020)引入了一套诊断测试来评估BERT的语言能力,这表明BERT对角色转换和相同类别的区分表现出敏感性。 尽管如此,它仍然难以与富有挑战性的推理和基于角色的事件预测相提并论,并且在否定的意义上也表现出明显的失败。
用于MRC数据集和模型。 到目前为止,MRC系统仍然是一个黑匣子,在很多情况下(我们必须知道如何以及为什么能够获得答案)使用它是非常冒险的。 深入研究MRC模型的解释或设计可解释的MRC体系结构至关重要。尽管MRC数据集迅速崛起并且相应的模型不断显示出令人印象深刻的结果,但仍然难以解释MRC系统学到了什么,MRC数据集多样性的基准容量也是如此(Sugawara等人2018,2019; Schlegel等人2020 )。通用论点是MRC系统的功能被高估,因为由于现有数据集的基准测试不精确,因此MRC模型不一定提供人类层面的理解。 尽管到目前为止,有许多模型显示出人类水平的得分,但我们不能说它们成功地完成了人类水平的阅读理解。 问题主要在于当前流行的神经模型的显式内部处理以及数据集所测量的内容的低解释性。 该模型可以正确回答许多问题,这些问题不一定需要语法和复杂的推理。例如,Jia and Liang (2017) and Wallace et al. (2019)提供了手工制作的对抗示例,以显示MRC系统很容易注意力k就分散了。 Sugawara et al. (2019)还指出,模型已经正确回答的大多数问题并不一定需要语法和复杂的推理。 干扰因素不仅可以评估当前模型的脆弱性,还可以作为显着的困难负样本来加强模型训练(Gao et al. 2019b).
此外,正如我们先前的工作(Zhang,Yang和Zhao,2020年)所讨论的那样,由于各种MRC基准数据集中的当前结果都相对较高,且改善幅度相对较小,因此很少能确认产生的结果在统计上比基线显着。 为了模型的可复制性,有必要在评估MRC模型时进行统计测试。
6.2 Decomposition of Prerequisite Skills
作为人体检验的经验,良好的理解力要求技能的不同方面。 我们研究的潜在解决方案是分解数据集所需的技能并进行技能评估,从而为模型能力提供更具可解释性和令人信服的基准。 此外,考虑遵循标准化格式将是有益的,这可以使进行跨数据集评估变得更简单(Fisch et al. 2019),并训练一个可以在具有特定技能的不同数据集上工作的综合模型。
关于相应的基准数据集构造,SQuAD数据集成功并用作标准基准并不是巧合。 除了数据集的高质量和特定重点外,限制提交频率的在线评估平台还可以确保令人信服的评估。 另一方面,对具有许多复杂问题类型的一些综合数据集保持谨慎是很自然的,这需要许多求解器模块以及处理技巧–我们应该报告令人信服的评估,并对单独的类型或子任务进行详细评估,而不是仅仅追求总体SOTA结果。 除非诚实地报告并统一这些处理技巧的标准,否则评估将很麻烦且难以复制。
6.3 Complex Reasoning
先前的大多数进展都集中在浅层QA检查任务上,而现有的基于检索和匹配的技术可以非常有效地解决这些问题。 这些任务并没有衡量所讨论的QA系统的理解和理解,仅测试了将注意力集中在特定单词和文本上的方法的能力。为了更好地使质量保证领域的进展与我们在解决此类任务时对人类表现和行为的期望相一致,一类新的问题,例如“复杂”或“挑战”推理,已成为热门话题。 复杂的推理通常可以被认为是需要智能行为和推理才能解决的实例。
已经提出了针对这种理解的最新研究,包括多跳QA(Welbl,Snettorp和Riedel 2018; Yang等2018)和会话QA(Reddy,Chen和Manning 2019; Choi等2018)。 为了处理复杂的多跳关系,多跳常识推理需要专门的机制设计。 此外,结构化知识提供了丰富的先验常识上下文,这促进了近年来符号和语义空间之间多跳常识知识融合的研究(Lin等人2019; Ma等人2019)。 对于对话质量检查,建模多回合依赖关系需要额外的内存设计,以捕获上下文信息流并准确而一致地解决问题(Huang,Choi和tau Yih 2019)
在技术方面,基于图的神经网络(GNN)包括图注意力网络,图卷积网络和图递归网络已用于复杂推理(Song等人2018; Qiu等人2019b; Chen,Wu和Zaki 2019; Jiang et al.2019; Tu et al.2019,2020)。设计基于GNN的模型背后的主要直觉是,回答需要探索和推理的多个碎片化的证据,这类似于人类可解释的逐步解决问题的行为。通常,机器学习中经常出现的另一个主题是对现有模型的重新审视以及它们在公平的实验环境中的表现。邵等人(2020年)提出了一个担忧,即图结构对于多跳推理可能不是必需的,并且图注解可以被视为CLM中使用的一种自注解的特殊情况。我们已经看到了从GNN的启发式应用到更合理的方法的转换以及关于图模型有效性的讨论。在以后的研究中,对GNN的深入分析以及GNN与CLM之间的联系和差异将鼓舞人心
6.4 Large-scale Comprehension
当前大多数MRC系统都基于给定段落作为参考上下文的假设。 但是,对于实际的MRC应用程序,参考段落,甚至文档,总是冗长且细节繁琐。 但是,最近的基于LM的模型工作缓慢,甚至无法处理长文本。 对于开放域和自由形式的质量保证,尤其是参考文献通常规模较大的情况,知识提取能力尤其需要(Guu等人,2020年)。 一个简单的解决方案是通过计算与问题的相似度来训练模型以选择相关的信息片段(Chen等人2017; Clark和Gardner 2018; Htut,Bowman和Cho 2018; Tan等人2018; Wang等人) (c).2018c; Zhang,Zhao和Zhang 2019; Yan等人2019; Min等人2018; Nishida等人2019)。 另一种技术是通过利用文本摘要或压缩来总结参考上下文的重要信息(Li et al.2019c)。
由于大多数自然语言缺乏丰富的注释数据,因此低资源处理是一个热门的研究主题(Wang等,2019; Zhang等,2019c)。 由于大多数MRC研究均基于英语数据集,因此与其他没有高质量MRC数据集的语言相比,存在相当大的差距。 可以通过以下方法缓解这种情况:通过域适应(Wang等,2019)迁移训练好的英语MRC模型,并训练半监督(Yang等,2017b; Zhang和Zhao 2018)或多语言MRC系统(Liu等) 等.2019a; Lee等人2019; Cui等人2019)。
MRC系统中暴露的另一个主要缺点是,在对其进行训练时,知识的可传递性不足(Talmor和Berant,2019年),甚至过大地适合特定的数据集。 由于大多数著名的数据集都是从Wikipedia文章构建的,因此CLM的明显好处可能是训练语料库中包含的相同或相似文本模式,例如上下文,主题等。设计健壮的MRC模型仍然是一项重大挑战, 不受真实噪音的影响。 构建跨领域,尤其是看不见的领域进行泛化的NLP系统也至关重要(Fisch等人2019)
6.6 Multimodal Semantic Grounding
与人类学习相比,当前的纯文本处理模型的性能相对较弱,因为这种模型仅学习文本特征,而没有感知外部世界,例如视觉信息。在人类学习中,人们通常通过视觉图像,听觉声音,单词和其他方式来理解世界。人脑通过多模式语义理解来感知世界。因此,多模式语义建模更接近于人类的感知,这有助于更全面的语言理解。何时以及如何充分利用不同的方式来提高阅读理解和推论仍然是一个悬而未决的问题。一个相关的研究主题是视觉问题解答(Goyal et al.2017),旨在根据给定的图像回答问题。但是,由于QA仅关注一个图像上下文,因此它仍处于研究的早期阶段。作为更实际的方案,对各种模式进行联合建模将是潜在的研究兴趣,并且对实际应用(例如,电子商务客户支持)有利。例如,给定混合的文本,图像和音频背景对话上下文,则要求机器相应地对查询做出响应。随着计算能力的不断提高,我们相信听觉,触觉和视觉感官信息以及语言的共同监督对于下一阶段的认知至关重要。
6.7 Deeper But Efficient Network
除了高质量的基准数据集之外,增加的计算资源(例如GPU)使我们能够构建更深更广的网络。 过去十年见证了从RNN到深度变形器的传统特征提取器,具有更大的上下文建模能力。 未来,我们相信随着GPU容量的快速发展,将提出更深入,更强大的骨干框架,并进一步提高MRC系统的基准性能。 同时,可能通过大型模型的知识提炼得到的更小,更精巧的系统也占据了一定的市场,这依赖于快速,准确的阅读理解解决能力来进行实际应用。
7. Conclusion
这项工作全面审查了MRC在背景,定义,发展,影响,数据集,技术和基准重点,趋势和机遇方面的研究。 我们首先简要介绍了MRC的历史以及上下文化语言模型的背景。 然后,我们讨论了上下文语言模型的作用以及MRC对NLP社区的影响。 在编码器到解码器的框架中总结了以前的技术进步。 在研究了MRC系统的机制之后,我们展示了MRC研究不同阶段的亮点。 最后,我们总结了趋势和机遇。 我们得出的基本观点是:1)MRC促进了从语言处理到理解的进步; 2)MRC系统的快速改进极大地受益于CLM的进步; 3)MRC的主题正逐渐从浅的文本匹配转变为认知推理。