我的Python学习笔记_Day17 正则表达式 自定义异常 内存管理机制 拷贝
文章目录
- 自定义异常
- 内存管理基础
- Python的内存管理机制
- 1)内存的申请
- 2)内存的释放
- 拷贝
- 1. 直接赋值
- 2. 浅拷贝和深拷贝
- 3. 深拷贝
- 正则表达式
- 1. 什么是正则表达式
- 2. 正则符号
- 匹配符号
- 1)普通字符
- 2)特殊字符
- 检测符号
- 匹配次数
- 贪婪和非贪婪
- 分支和分组
- 分支
- 分组
- 作业
自定义异常
要求这个类必须继承Exception
__str__返回值就是错误信息描述
class MyOnlyError(Exception):
def __str__(self):
return '报错信息'
内存管理基础
-
c语言
内存分为栈区间和堆区间
栈区间的内存是系统自动申请自动释放
堆上的内存需要程序通过调用malloc函数取申请,通过调用free函数去释放
-
高级语言(java\C++\OC\Python)中的内存管理机制,都是针对堆上的内存的管理进行的自动化操作
Python的内存管理机制
C系列、Java等语言普通数据放在栈区间里,对象(如果有)放在堆区间里
而python中,一切皆对象,所以一切数据都是在堆区间中
相当于所有的变量都是指针
1)内存的申请
python中所有的数据都是存在堆区间中的,变量是保存在栈区间的,变量中保存的是保存在堆中的数据的地址,相当于所有的变量都是指针
重新给变量赋值,会先在堆区间中开辟新的内存区域,来保存新的数据,然后将新的数据的地址重新保存到变量
但是如果使用数字或者字符串给变量赋值,不会直接开辟新的内存,而是先检查内存中有没有这个数据,如果有,直接将原来的数据的地址给变量
2)内存的释放
python中有一套机制叫垃圾回收机制
一个数据对应的内存空间是否释放,就看这个数据的引用计数是否为0;如果引用计数为0,数据对应的内存就会被自动释放
增加引用计数:增加数据的引用(让更多的变量来保存数据的地址)
减少引用计数:删除引用,或者让引用去保存新的数据
特殊情况:循环引用问题(在python中不存在)
你引用我,我引用你
python的垃圾回收机制会自动处理循环引用问题
拷贝
1. 直接赋值
用一个变量直接给另外一个变量赋值的时候赋的地址,赋值后两个变量保存的是同一个数据的地址
在栈区间里的两个变量都指向堆区间里的同一个数据,改动其中一个,另一个也跟着动
a = [1, 2, 3]
b = a
a[0] = 999
print(b) # [999, 2, 3]
2. 浅拷贝和深拷贝
复制原数据,产生一个新的数据(值和原数据一样,地址不同),然后将新的数据的地址返回
如果有子对象,子对象不会复制(浅拷贝相对深拷贝的特点)
import copy
a = [1, 2, 3]
b = copy.copy(a)
a[0] = 999
print(b) # [1, 2, 3]
上面是浅拷贝,ab改变本身数据的时候不会影响另一个
3. 深拷贝
复制原数据,产生一个新的数据(值和原数据一样,地址不同),然后将新的数据的地址返回
如果有子对象,子对象也会复制(深拷贝相对浅拷贝的特点)
from copy import copy, deepcopy
class Dog:
def __init__(self, name, age=10):
self.name = name
self.age = age
class Person:
def __init__(self, name, age=10, dog=None):
self.name = name
self.age = age
self.dog = dog
p1 = Person('Tom', dog=Dog('dd'))
p2 = p1
p3 = copy(p1)
p4 = deepcopy(p1)
p2.dog.name = 'p2的狗'
p3.dog.name = 'p3的狗'
p4.dog.name = 'p4的狗'
print(p1.dog.name)
print(p2.dog.name)
print(p3.dog.name)
print(p4.dog.name)
上面说明直接赋值、浅拷贝数据里的对象不会复制,即p1,p2,p3三个人的狗是同一条狗,而深拷贝数据里的对象会复制,即p4的狗是自己的,长得跟p1的狗一样而已
正则表达式
1. 什么是正则表达式
用正则符号来描述字符串规则,让字符串匹配更简单的一种工具
正则本身的语法和编程语言无关,几乎所有的编程语言都支持正则
python通过提供re模块来支持正则表达式
2. 正则符号
匹配符号
一定要有一个字符与之匹配
1)普通字符
在正则表达式中没有特殊功能或者特殊意义的字符都是普通字符
普通字符在正则表达式中就代表这个符号本身,匹配的时候只能和这个指定的字符进行匹配
import re
value = '13ab'
re = re.fullmatch(r'13ab', value)
if re:
print('匹配')
相当于:
if value == r'13ab':
print('匹配')
2)特殊字符
| 写法 | 说明 |
|---|---|
| . | 任意字符 |
| \w | ASCII码表中, 只能匹配,字母、数字、下划线; ASCII码表以外的都可以匹配 存在意义不大 |
| \d | 匹配任意一个数字字符,等价于 [0-9] |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f] |
| \W, \D, \S | 匹配非小写所匹配的字符 即小写的能匹配的大写的就不能匹配 |
| [字符集] | 匹配字符集中的任意一个字符(见例子) 一个中括号只能匹配一个字符 |
| [^字符集] | 匹配非字符集中的任意一个字符 |
字符集例子
a. [普通字符集]
[abc12]:匹配a、b、c、1、2五个字符中的任意一个
b. [字符1-字符2]
匹配字符1的编码值到字符2的编码值之间的所有字符
要求字符1的编码值必须小于字符2的
[1-9]:匹配123456789中的任意一个
[a-z]:匹配任意一个小写字母
[a-zA-Z]:匹配任意一个字母
[\u4e00-\u9fa5]:匹配任意一个中文字符
[1-9abc]:匹配123456789和a、b、c中的任意一个字符
[\dxy]:匹配数字和x、y中的任意一个字符
检测符号
| 写法 | 说明 |
|---|---|
| \b | 检测是否是单词结尾(见例子) 单词结尾:所有可以区分出两个不同单词的符号都是单词结尾,其中包括字符串开头和字符串结尾 用法:检测\b所在的位置是否是单词结尾;不影响匹配时候的字符串长度 相当于检测广义上的分隔符 |
| ^ | 检测^所在的位置是否是字符串开头 |
| $ | 检测$所在的位置是否是字符串结尾 |
\b 的例子:
'ab\b':匹配一个长度是2的字符串,字符串为'ab',并且要求b的后面是单词边界
\b在匹配中没用,但是在search查找里有用,可以找到单独的字符串
匹配次数
| 字符 | 说明 |
|---|---|
| 字符? | 字符匹配0次或1次 如:[a-z]? 小写字母出现0次或1次 |
| 字符* | 字符匹配0次或多次 如:[a-z]* 小写字母出现0次或多次 |
| 字符+ | 字符匹配1次或多次 如:[a-z]+ 小写字母出现1次或多次 |
| 字符{} | 四种用法见下 |
字符{}:
1.字符{N} - 字符匹配N次
2.字符{M,N} - 字符匹配M到N次
3.字符{M,} - 字符匹配至少M次
4.字符{,N} - 字符匹配至多N次
练习:写一个正则表达式判断输入的内容是否是整数
r'[+-]?[1-9]\d*'
贪婪和非贪婪
匹配次数不确定时,有贪婪和非贪婪两种状态
? * + {M,N} {M,} {,N} 默认是贪婪的
?? *? +? {M,N}? {M,}? {,N}? 加问号变成非贪婪
贪婪:在能匹配成功的前提下,尽可能多的匹配
import re
re_str = r'\d{3,5}'
print(re.search(re_str, 'abc123456789'))
# 结果:import re
re_str = r'a.+b'
print(re.search(re_str, 'jijalbkajsejfaibkdjfei'))
# 结果:非贪婪:在能匹配成功的前提下,尽可能少的匹配
import re
re_str = r'\d{3,5}?'
print(re.search(re_str, 'abc123456789'))
# 结果:import re
re_str = r'a.+?b'
print(re.search(re_str, 'jijalbkajsejfaibkdjfei'))
# 结果:分支和分组
分支
正则1|正则2
先让正则1去匹配,如果匹配失败,再用正则2匹配;
只要两个中有一个能够匹配成功就成功
例子:匹配三个数字或者三个字母
r'\d{3}|[a-zA-Z]{3}'
例子:匹配一个字符串,abc前是三个数字或三个字母
r'\d{3}abc|[a-zA-Z]{3}abc'
分组
(正则表达式) - 看作一个整体
上一个例子中,分组可以这样写:
r'(\d{3}|[a-zA-Z]{3})abc'
(正则表达式)\M - 在\M的位置重复前面第M个分组匹配到的内容
练习:匹配字符串中某一个部分重复前面的
如:abc123abc xab456xab
不能 abc123cab xab789eee
import re
str_re = r'([a-z]{3})\d{3}\1'
result = re.fullmatch(str_re, 'xab123xab')
print(result)
作业
-
写一个正则表达式判断一个字符串是否是ip地址
规则:一个ip地址由4个数字组成,每个数字之间用.连接。每个数字的大小是0-255
255.189.10.37 正确
256.189.89.9 错误import re str_re = r'(((\d{1,2})|(1\d{2})|(2[0-5]{2})).){3}((\d{1,2})|(1\d{2})|(2[0-5]{2}))' result = re.fullmatch(str_re, '255.1.1.1') print(result) # 0~255 : (\d{1,2})|(1\d{2})|(2[0-5]{2})这里错了,239不行了,应该把200-255分开成200-249,250-255
而且0不能开头
答案:
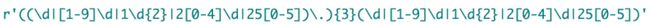
-
写一个正则表达式可以匹配任意有效数字
123 正确; 23.34 正确; -123 正确; +12.34 正确; 0.232 正确; -0.233 正确
0123 错误; 012.23 错误; 00.23 错误
import re str_re = r'[+-]?(([1-9]\d*)|(0\.\d+))' result = re.fullmatch(str_re, '-0.00000') print(result)错了,忽略了正常浮点数
答案:
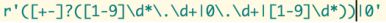
-
验证输入的内容只能是汉字
import re str_re = r'[\u4e00-\u9fa5]+' while True: value = input('请输入汉字, 输入q退出: ') if value == 'q': exit() result = re.fullmatch(str_re, value) if result: print('输入正确') else: raise ValueError('输入的内容必须是纯汉字!') -
验证是否是有效标识符: 由字母、数字、_组成并且数字不能开头
import re str_re = r'[a-zA-Z_][a-zA-Z_\d]*' result = re.fullmatch(str_re, '_default') print(result) -
能够完全匹配字符串“(010)-62661617”和字符串“01062661617”的正则表达式包括( )
A. r“\(?\d{3}\)?-?\d{8}” B. r“[0-9()-]+” C. r“[0-9(-)]*\d*” D. r“[(]?\d*[)-]*\d*”ABD
B是迷惑项,方括号中的圆括号不起作用,只是作为普通字符
C中(-)的-符号是特殊字符,不能作为普通字符,所以不能匹配字符串中的- -
能够完全匹配字符串
“c:\\rapidminer\\lib\\plugs”的正则表达式包括()A. r“c:\rapidminer\lib\plugs” B. r“c:\\rapidminer\\lib\\plugs” C. r“(?i)C:\\RapidMiner\\Lib\\Plugs” ?i:将后面的内容的大写变成小写 D. r“(?s)C:\\RapidMiner\\Lib\\Plugs” ?s:单行匹配BC
A少了 \D没有转换小写
-
能够完全匹配字符串“back”和“back-end”的正则表达式包括()
A. r“\w{4}-\w{3}|\w{4}” B. r“\w{4}|\w{4}-\w{3}” C. r“\S+-\S+|\S+” D. r“\w*\b-\b\w*|\w*”ABCD
-
能够完全匹配字符串“go go”和“kitty kitty”,但不能完全匹配“go kitty”的正则表达式包括()
A. r“\b(\w+)\b\s+\1\b” B. r“\w{2,5}\s*\1” C. r“(\S+) \s+\1” D. r“(\S{2,5})\s{1,}\1”AD
B没有分组,所以不能用 \1
C多了一个空格
-
能够在字符串中匹配“aab”,而不能匹配“aaab”和“aaaab”的正则表达式包括( )
A. r“a*?b” B. r“a{,2}b” C. r“aa??b” D. r“aaa??b”BC
A的两头是a和b,所以只有一个解,在只有一个解的情况下贪不贪婪没区别
D能匹配aaab,因为有唯一解,不管贪不贪婪ps:有多解才贪婪!!!