从源码的角度分析mybatis的核心流程(中)
前言:
上一篇学习的是mybatis核心流程中的初始化的过程,初始化其实就是将xml里面的内容解析到configuration对象中。这里接着上面流程继续学习mybatis的核心流程中的代理阶段和数据读写阶段,mybatis三大核心流程如下图所示

二、代理阶段
早些年在使用ibatis时候,其实是没有这个代理阶段的过程,我们使用如下的方式进行编程(面向sqlsession编程)
@Test
public void queryUser() {
SqlSession sqlSession = sqlSessionFactory.openSession();
TUser user = sqlSession
.selectOne("com.taolong.mybatis.test.TUserMapper.slectUserById", 1);
System.out.println(user);
}当apache对ibatis进行了修改之后编程了mybatis后,我们使用下面的方式进行编程(面向接口编程,达到解耦,程序员更喜欢的方式)
@Test
public void queryUser2() {
SqlSession sqlSession = sqlSessionFactory.openSession();
TUserMapper mapper = sqlSession.getMapper(TUserMapper.class);
TUser user = mapper.queryUserById(1);
System.out.println(user);
}从ibatis到mybatis的过程如下图所示,所以今天将的mybatis核心流程中的代理阶段和数据读写阶段就是如下图中的翻译的过程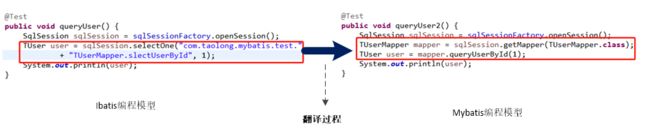
这里有个问题,就是TUserMapper是一个接口,并没有具体的实现类,那么mybatis是如何通过TUserMapper的接口来调用方法呢?带着这个问题,我们来阅读源码。同样通过debug的方式来跟踪源代码
(1)源码分析入口
@Test
public void queryUser2() {
SqlSession sqlSession = sqlSessionFactory.openSession();
//从这里打断点跟进去
TUserMapper mapper = sqlSession.getMapper(TUserMapper.class);
//可以看看mapper到底是什么
System.out.println(mapper .getClass().getName());
TUser user = mapper.queryUserById(1);
System.out.println(user);
}打断点进入源码,看看mapper到底是什么
(2)defaultSqlsession.getMapper()
public T getMapper(Class type) {
//从configuration中动态获取Mapper
return configuration.getMapper(type, this);
} (3)configuration.getMapper()
public T getMapper(Class type, SqlSession sqlSession) {
//从configuration中的注册mapper中心获取mapper对象
return mapperRegistry.getMapper(type, sqlSession);
} (4)mapperRegistry.getMapper()
@SuppressWarnings("unchecked")
public T getMapper(Class type, SqlSession sqlSession) {
//代理工厂,用于生成代理对象
final MapperProxyFactory mapperProxyFactory = (MapperProxyFactory) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
//通过工厂模式生成mapper对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
} (5)mapperProxyFactory.newInstance()
public T newInstance(SqlSession sqlSession) {
//MapperProxy是代理类,该类实现了InvocationHandler,所以可以看出是使用了动态代理模式
final MapperProxy mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
} (6)newInstance()
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy mapperProxy) {
//返回动态代理生成的代理对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
} 上面就是通过动态代理生成了一个mapper的对象进行增强,所以第二阶段的绑定阶段就是通过动态代理产生一个Mapper的对象,其实返回就是MapperProxy,当调用mapper的方法时,其实就是调用了MapperProxy中的invoke方法,这个动态代理的地方建议大家深入的了解一下,重点看一下MapperProxyFactory类、MapperProxy、InvocationHandler、Proxy如何生成动态代理。到这里,我们已经能够解释上面的一个问题(就是TUserMapper是一个接口,并没有具体的实现类,那么mybatis是如何通过TUserMapper的接口来调用方法呢?)因为这里的TUserMapper是生成的一个动态代理类来代理TUserMapper,而非真正的TUserMapper
三、数据读写阶段
既然知道TUserMapper是生成的动态代理类,那么当调用TUser user = mapper.queryUserById(1)时应该是调用了MapperProxy的invoke方法,我们继续跟着流程走,在继续流程之前我们带着第二个问题思考:sqlsession中有很多方法(select One,selectList,selectMap等)在ibatis中我们在代码中注明了要调用哪个方法,但是在mybatis没有注明,那么mybatis是如何知道调用的是哪个方法呢?
(1)MapperProxy.invoke()
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
//判断方法是否是object的方法,不增强
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {//判断是否是默认方法,不增强
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
//MapperMethod方法就是封装了mapper接口中对应方法的信息,它是mapper接口和sql语句的桥梁
final MapperMethod mapperMethod = cachedMapperMethod(method);
//如果是我们定义在mapper的操作数据库的方法,则执行下面代码
return mapperMethod.execute(sqlSession, args);
}这里mappedMethod非常重要,因为它封装了mapper接口中的方法信息,它是mapper接口和sql语句的桥梁,是通过它来确定调用sqlsession的具体的哪个方法,大家可以先看一下它的数据结构,MappedMethod中的SqlCommand里面封装了SqlCommandType(insert、update、delete、select),里面的name封装了对应的mapper接口名和方法名;MappedMethod中的MethodSignature封装了接口方法的返回值类型,以及ParamNameResolver可以解析出接口的入参。所以通过MappedMethod就可以知道他是调用sqlsession的哪个方法(sqlcommandType可以知道是增删改查的哪一个,再看它的返回类型是list还是一个对象就知道是调用sqlsession的selectOne还是selectList...)以及xml中的具体的哪个方法.。
(2)mapperMethod.execute()
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
//根据methodSignature,判断是调用执行的是哪个方法,
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
//这些方法最终都是会调用sqlsession.select方法
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
//其实selectOne其实最终也会调用selectList,然后去集合的第一个内容而已
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional() &&
(result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}(3)DefaultSqlSession.selectOne()
public T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
//还是会调用selectList方法
List list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
} (4)selectList()
public List selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//通过接口名+方法名获取(namespace+方法名)MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
//调用executor的query方法,查询
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
} 这里注意最后一句executor.query()方法,这里是使用了代理设计模式,BaseExecutor和CachingExecutor都是实现了Executor方法,那么这里是进入了CachingExecutor方法,这里面会涉及到mybatis中二级缓存的一些逻辑
(5)cachingExcutor.query()
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//获取mappedStatement的Cache
Cache cache = ms.getCache();
if (cache != null) {
//是否需要清空cache(在xml文件中的cache标签设置,比如flushInterval时间到期)
flushCacheIfRequired(ms);
//判断是否使用cache,xml文件中设置
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
//直接从缓存中获取结果
@SuppressWarnings("unchecked")
List list = (List) tcm.getObject(cache, key);
if (list == null) {
list = delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//查询的结果保存到缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//如果没有设置缓存,那么就直接调用被代理的对象方法查询
return delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
} 这里就是处理mybatis的二级缓存的逻辑,这是在一级缓存之前处理的,所以如果同时配置二级缓存和一级缓存那么会先使用二级缓存。另外判断是否使用二级缓存需要在mybatis-config.xml中配置属性cacheEnable和在相应的xml中配置cache标签属性。最后就是使用代理设计模式调用BaseExecutor.query()(baseExecutor的子类)
(6)baseExecutor.query()
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//判断是否需要清空一级缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List list;
try {
queryStack++;
//从一级缓存中取出结果,返回
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//从数据中查询结果
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
} 这里是涉及到mybatis的一级缓存的逻辑,能从一级缓存中获取结果就取出结果,否则就查询数据库。有两个需要注意的地方:1,一级缓存中的CacheKey是计算时非常严格的它是由mappedStatement,parameter,rowBounds和boundSql一起生成的一个值;2,如果有update、insert、delete这些操作,缓存是会清空的。感兴趣的可以深入了解一下。接着流程往下
(7)queryFromDatabase()
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//查询结果,这里使用了模板设计模式,
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//查询的结果加入到缓存中,方便下次使用
localCache.putObject(key, list);
//这下面应该是存储过程相关的,如果是存储过程那么类型就是Callable
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
} 接着往下看,我们是调用doQuery()方法,但是BaseExecutor是没有实现doQuery(),这里实际上使用了模板设计模式,将操作延迟到子类中(BatchExecutor,CloseExecutor,ReuseExecutor,SimpleExecutor),
SimpleExecutor:默认配置,使用statement对象访问数据库,每次访问都要创建statement对象
ReuseExecutor:使用预编译PrepareStatement对象访问数据库,访问时,会重用缓存中的statement对象
BatchExecutor:实现批量操作多条sql的能力
不同的子类有不同的实现,如果想了解更多关于模板设计模式,请参考(模板设计模式),我们这里看SimpleExecutor.doQuery()
(8)simpleExecutor.doQuery()
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//这里面生成的是statementHandler的实现类 RoutingStatementHandler
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
//调用 RoutingStatementHandler.query()
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
} 这里为什么要使用RoutingStatementHandler.query()方法呢,其实是使用了静态代理设计模式,请继续往下看
(9)RoutingStatementHandler.query()
public List query(Statement statement, ResultHandler resultHandler) throws SQLException {
return delegate.query(statement, resultHandler);
} 我们来看看RoutingStatementHandler中被代理的对象是哪个
(9-1)RoutingStatementHandler()
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//其实从这里判断是选择代理哪个statement
switch (ms.getStatementType()) {
//默认的statement
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
//预编译的statement
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
//存储过程的statement
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}其实这里就是使用静态的代理模式判断到底需要代理哪一个statement,不得不赞叹mybatis的代码写的非常优雅,一个看似非常简单的地方,如果换作是我们直接在就在上面使用if else判断得了。我们这里显然是用了PreparedStatement,因为会预编译嘛
(10)PreparedStatement.query()
public List query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//执行查询
ps.execute();
//处理结果集
return resultSetHandler. handleResultSets(ps);
} 其实到这里就已经完成了一次数据库的查询操作。还剩下一个处理结果集,放到下一篇文章中解析,因为这一篇的篇幅太长了,害怕大家没耐心往下看。
下面用几幅图帮助大家来更好的理解上面的内容
1、Executor的类的关系
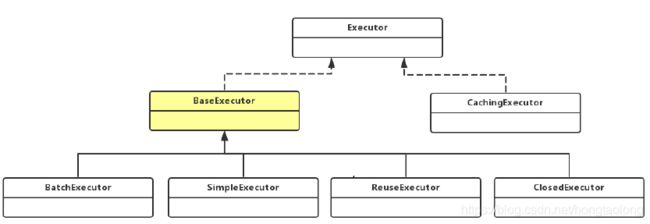
(1)CacheingExecutor里面涉及到二级缓存的逻辑,如果能从缓存中获取结果,就直接返回,二级缓存会优先于一级缓存
(2)使用了代理模式来代理BaseExecutor的子类,来实现查询的功能
(3)BaseExecutor使用了模板设计模式将具体的不同的查询延迟到它的子类中
(4)BaseExecutor定义了一级缓存的逻辑
2、StatementHandler的类的关系
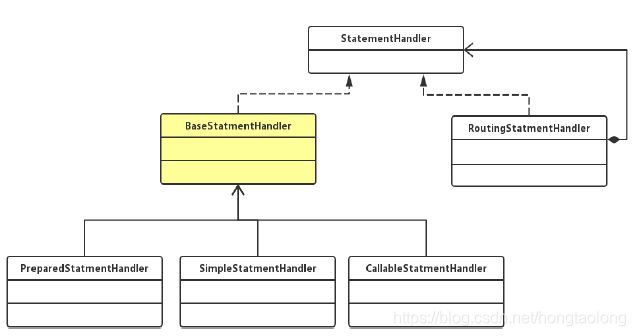
(1)RoutingStatementHandler使用了代理模式,根据参数判断具体是调用了哪个StatementHandler处理
(2)不同的statementHandler实现了不同的查询请求,单一指责的原则
3、Executor内部的运作图
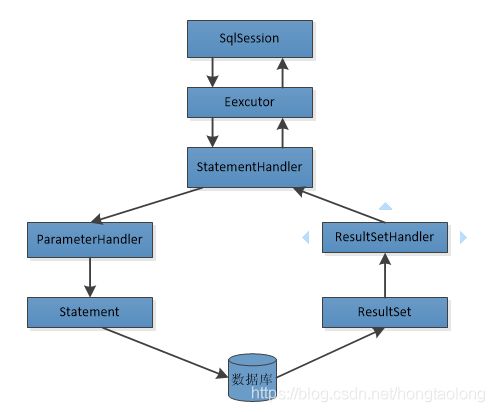
mybatis的代理阶段和数据读写阶段暂时写到这里,关于结果集的映射解析放到下面一篇文章解析,如有问题欢迎大家指正,谢谢!