这个问题我们应该经常会见到,想写这个问题是因为微软面试中,面试官问了这问题,而且要写代码,尼玛,最可恨的是不准用容器,哥当时就跪了。。。
这个问题就是最常见的topK问题,解决思路:首先统计文档中所有不同word出现的频率,然后对所有不同的word按照出现频率排序,取出出现频率最大的k个words。
1.统计文档中所有不同word出现的频率
统计文档中word的频率的方法,要根据文档的数据量来决定:
(1)如果文档中数据能够全部读入内存,那么可以通过map/hashmap来直接统计各个word出现的频率。之所以采用map/hashmap结构,是因为它们的查找,修改效率很高,map在对数级别,hashmap在常数级别。
(2)如果文档中的word的数据不足以全部读入内存甚至远远超过了内存的容量,那只能通过分治的思想来解决,其中对于大数据比较好的解决办法:将这个文档通过hash(word)%n,hash到n个不同的小文件中,n根据文档的大小以及内存空间而定,hash后,所有相同的word肯定会在同一个文件中,然后分别对这n个文件分别利用map/hashmap来统计其中word的频率,分别求出topk,最后进行合并求总的topk。
2.求topk
当所有不同word的频率求出来之后,就是如何求出topk的问题了,抛开前面的条件,topk问题有很多解法:
(1)最简单的方法,冒泡或选择排序,求出最大的k个元素,时间复杂度在O(kn);
(2)基于快排的选择排序,在随机化的情况下,时间复杂度在O(n);
(3)局部淘汰法1,取前k个元素,建立一个数组,然后遍历所有元素,依次与数组中最小的元素比较,若大于,则替换。这种方法时间复杂度为O(kn);
(4)局部淘汰法2,取前k个元素,维护一个小根堆,遍历所有元素,依次与堆顶元素进行比较,若大于,则替换并重新使其为小根堆,这种方法的时间复杂度为O(nlgk)
(3)和(4)的最大的好处在于只需遍历一边序列就可以得到topk的结果,效率是很高的,还有就是在无法将序列全部加载到内存中时,这两种方法是最好的选择。
这里我采用三种map结构:map, hash_map(VS2008),unordered_map,来实现问题1,unordered_map在c++11中已经正式成为STL的一部分,是底层采用hash实现的map,和各家的实现的hashmap(不在C++标准中)的机制是一样的。采用(4)来解决topk的问题,下面是实现代码:
#include
#include
#include
#include
程序的运行结果如下:
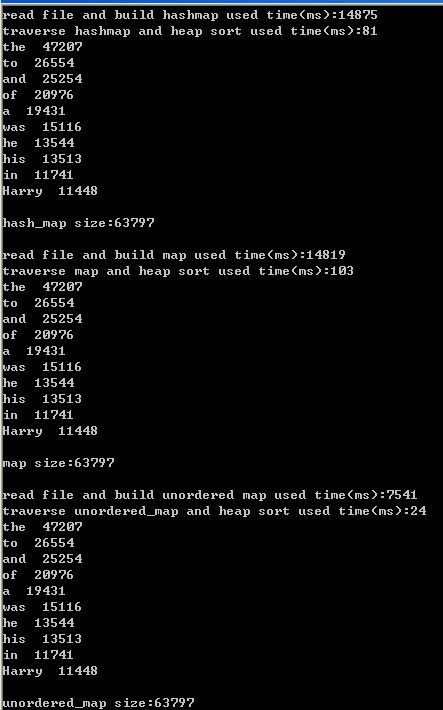
由于数据量比较小,hash_map和map的效率差不多,但unordered_map的效率要高出很多,可能和unordered_map底层的hash函数的设计有很大关系。
STL中的高效能的容器很是值得我们学习的。。。
Jun 2, 2013 @library