dataframe,python,numpy 问题索引1
20200724
data = data.apply(pd.to_numeric, errors=‘ignore’)
应用时候忽略错误
20200719
TypeError: ‘Series’ objects are mutable, thus they cannot be hashed
result_quan.iloc[result_quan[‘相似度’]==1,‘包含’]=1
loc没写
20200707
https://editor.csdn.net/md?articleId=107187574
对列表元素去重并保持原来顺序
20200624
https://blog.csdn.net/weixin_43368684/article/details/88756103
列中不包含某个字符
df[df[“col”].str.contains(‘this’|‘that’)==False]
df = pd.DataFrame({“A”: [“Hello”, “this”, “World”, “apple”]})
df[df[‘A’].str.contains(“Hello|World”)==False]
A
1 this
3 apple
20200618
https://www.cnblogs.com/liulangmao/p/9301032.html
shift
pandas DataFrame.shift()函数可以把数据移动指定的位数
period参数指定移动的步幅,可以为正为负.axis指定移动的轴,1为行,0为列.
20200527
空表添加行数据
if (biaonr.shape[0]https://blog.csdn.net/roamer314/article/details/80886075
20200518
zdlx=[ i if i in biaonr.columns else ‘’ for i in zdlx.tolist()]
zdlx=sorted(zdlx)
zdlx=set(zdlx)
zdlx=list(zdlx)
zdlx=zdlx[1:]
列表中剔除某些元素

列表追加转为dataframe
20200516
[ i if ‘pb’ in i else ‘’ for i in ycjg.columns ]
列表生成式
20200515
perr=zengq.iloc[i:i+1,:]
加个冒号直接取出来就是dataframe 不是series 不需要再转换
fg[‘col_name’]=fg[‘col_name’].apply(lambda x:x.lstrip())
fg[‘comments’]=fg[‘comments’].apply(lambda x:x.lstrip())
去除单元格左边空格
20200514

dataframe 累乘是向下累乘
当单元格的值是列表或者元组的时候,分组聚合运算会出问题
In [25]: gb = df.groupby(‘gender’)
In [26]: gb.
gb.agg gb.boxplot gb.cummin gb.describe gb.filter gb.get_group gb.height gb.last gb.median gb.ngroups gb.plot gb.rank gb.std gb.transform
gb.aggregate gb.count gb.cumprod gb.dtype gb.first gb.groups gb.hist gb.max gb.min gb.nth gb.prod gb.resample gb.sum gb.var
gb.apply gb.cummax gb.cumsum gb.fillna gb.gender gb.head gb.indices gb.mean gb.name gb.ohlc gb.quantile gb.size gb.tail gb.weight
分组聚合运算类型
分组累乘之后 索引会自动改成数字序列?
https://blog.csdn.net/zxyhhjs2017/article/details/93498104?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-30.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-30.nonecase
累乘
dataframe 中某列是元组 使得dataframe 不能显示出来?
gp=duiying.groupby([‘qian’,‘hou’],as_index=True)
pltj=gp[‘hou’].count()
pltj=pltj.to_frame(name=‘num’)
pltj.index=range(pltj.shape[0])
pltj[‘index’]=list(pltj.index)
分组统计之后 多层索引转换为列
20200423
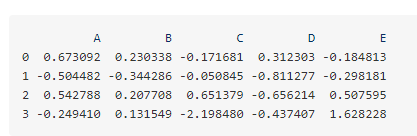
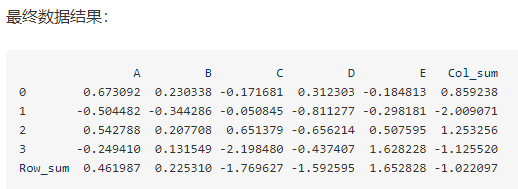
求各行的和各列的和
https://my.oschina.net/u/2306127/blog/1920367
DataFrame数据预览
计算各列数据总和并作为新列添加到末尾
df[‘Col_sum’] = df.apply(lambda x: x.sum(), axis=1)
计算各行数据总和并作为新行添加到末尾
df.loc[‘Row_sum’] = df.apply(lambda x: x.sum())
最终数据结果:
data_=data_[data_.columns[0:-1]]
通过列名取出来一列还是dataframe 不用再从series转换
https://www.cnblogs.com/zhoudayang/p/5564219.html
https://blog.csdn.net/cow66/article/details/100119058
重点
同时对多列进行操作
ycjg[str(j)+‘pb’] = ycjg.apply(lambda x:x[str(j)] ==x[‘mubc’],axis=1)
apply括号里面的x 代表前面传入的是 ycjg dataframe
要每个元素单独比较 axis=1 每列的每个元素对应比较
axis=0 每行的元素对应比较
多列比较 两列比较 两列操作
df[‘duplication’]=df.apply(lambda x: 1 if ((x[0]==x[1])) else 0 ,axis=0 )
只能是X[0] 这种形式,不能用x[‘mubc’]的形式
df[df[‘target’]==‘脉搏’]
直接df通过true false 来筛选的时候,筛选的是整行
20200414
字符转换为数值
https://www.cnblogs.com/sench/p/10134094.html
from sklearn import preprocessing
le = preprocessing.LabelEncoder() #获取一个LabelEncoder
le = le.fit([“male”, “female”]) #训练LabelEncoder, 把male编码为0,female编码为1
sex = le.transform(sex) #使用训练好的LabelEncoder对原数据进行编码
print(sex)
20200413
行追加用append,concat
列插入 用 insert
# X.iloc[:, i_outlier] = X.iloc[:, i_outlier].astype(float)
类型转换花的时间很多!
20200410
https://blog.csdn.net/uvyoaa/article/details/79157786
分组取前n行
https://pandas.pydata.org/pandas-docs/stable/user_guide/groupby.html
groupby api
grouped = df.groupby([‘class’]).head(2)
goupby之后就是对每类分别操作?
https://blog.csdn.net/The_Time_Runner/article/details/84076716
set_index:删除原来索引,并用新的数字列覆盖索引
reset_index:drop false 将原来的索引加入当前df作为列 同时用数字改写行索引
drop true 不作为列 同时用数字改写行索引
reset_index()
test_data.groupby(‘release_year’)[‘genre’].value_counts()
分组对某列计数
注意筛选条件最终的表现形式是True或False
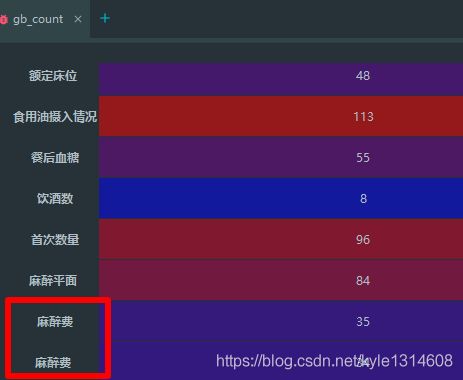
看起来是相同的但是实际上有个有空格,导致分组统计的时候
会出现两个值
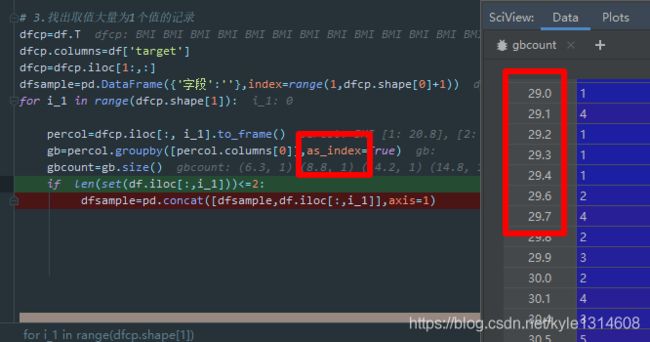
gb=df.groupby([‘target’],as_index=True)
gb_count=gb.size() 是series
对分组列本身值统计计数 如图在上

不是size 而count的结果会把所有列索引保留
https://blog.csdn.net/meiqi0538/article/details/82533456
series 追加,添加值
列名的更改
df.rename(columns={‘原列名’:‘新列名’}, inplace=True)
append,concat 出问题 基本上就是两张表的行或者列索引
不一致导致的
20200408
ValueError: column index (256) not an int in range(256)
https://www.cnblogs.com/z-x-y/p/9639702.html
sigle_col=group.loc[i_gp, :]
sigle_col=(sigle_col.to_frame()).T
series 转dataframe
20200407
(df_test.loc[df_test.loc[:,‘列1’]==‘你好’,‘列1’])=‘大哥’
筛选 赋值 注意大圆括号 不能少
series或者dataframe 才能赋值 如果加iloc[0] 反而不能赋值
20200326
分组排序
df=df.groupby(‘LABEL1’).apply(lambda x:x.sort_values(‘行数’)).reset_index(drop=True)
test2=df_test.sort_values([‘列2’,‘列3’],ascending=[True,True])
两种效果是一样的
20200325

statis.to_excel(path + ‘统计结果_’ + str(i_sam) + ‘.xls’)
前面的to_excel 如果和后面的xls 不对应的话
输出就会像上面的错误
dataframe 模糊的 是df 进行比较 没取到具体的值
20200322
def dot_index(x):
dot_index=re.search(r'\.',str(x)).span()[0]
return dot_index
df['len'] = df.iloc[:, i].apply(lambda x: 1 if ((x!=0)&(int(str(x)[(dot_index(x)+1):]) ==0) & (len(str(int(x)))==1)) else 2)
某个字符所在的索引,判断是否是个位数
for i_outlier in tqdm(range(df_.shape[1])):
# print(i_outlier)
min_ = np.percentile(df_.iloc[:, i_outlier], 0.5, interpolation=‘lower’)
max_ = np.percentile(df_.iloc[:, i_outlier], 99.5, interpolation=‘higher’)
filter=df_.iloc[:, i_outlier][(df_.iloc[:, i_outlier] > max_) | (df_.iloc[:, i_outlier] < min_)]
df_.iloc[:, i_outlier][(df_.iloc[:, i_outlier] > max_) | (df_.iloc[:, i_outlier] < min_)] = 0
dataframe 大部分都是索引问题
如果for 的指和索引相同 且索引存在重复时候,第四行将会改变所有相同的索引
20200321
min_ = np.percentile(df_.iloc[:, i_outlier], 0.5, interpolation=‘lower’)
max_ = np.percentile(df_.iloc[:, i_outlier], 99.5, interpolation=‘higher’)
filter=df_.iloc[:, i_outlier][(df_.iloc[:, i_outlier] > max_) | (df_.iloc[:, i_outlier] < min_)]
有可能取出来是空值,最小和最大的值的个数都很多
这样就筛选不出来
20200320
df_sample.loc[0seg:1(seg-1),str(i_1000)]=fuzhi #划分出的数据加到sample表,复制用dataframe不行,series 才可, 左右两边形式相同
series=series
dataframe=dataframe
20200319
df.loc[True]
df[True] 二者皆可以
20200319
df = df.loc[~df.iloc[:, 0].str.contains(‘心率’), :]
series 判断是否包含某些字符
20200318
df=df[~df[col_name[0]].isin([‘0’, ‘0.0’, ‘’])]
判断某列是否含有某值
20200317
X_train = df_train.iloc[:,0:-1]
索引-1 为最后一列
20200313
空值
isna() 不能识别’’
替换成‘’,筛选的时候用 aa==‘’
excel里面的空白,读到dataframe 里面是不存在的
无法显示出来的,比如本来一列有10行,有两个空白
读入之后就只剩下8个数据,两个空白无法显示出来
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
(sigcol0.iloc[0] + sigcolna.iloc[0]) + sigcol00.iloc[0] > df.shape[0] * 0.5
sigcol0 是series 不能 sigcol0>15 不能直接判断
必须把值取出来再判断
apply 只适合于apply
20200311
https://blog.csdn.net/qq_22238533/article/details/70917102
随机打乱
concat 合并 行或者
列索引不相同就会产生错误
df.notna() 非空值
dataframe 整体选择
df=df[df!=0] 零的部分变成nan,因为其要保存整体索引的不变
df=df[df.isna()] 这样好像是不起作用的
即使是按列来操作也是不行的,因为其要按最多值的列的索引
来concat 最终还是达不到只删除空值,非空值自动靠拢的目的
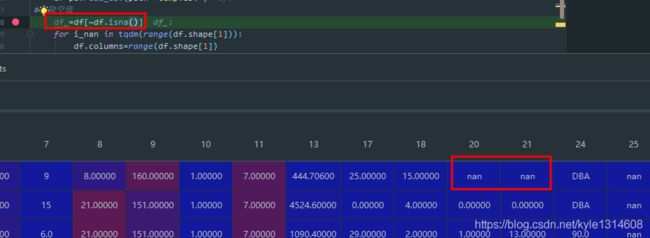
为什么非空值选不出来
20200310
指定位置插入列
df_minmax.insert(loc=0,column=‘784’,value=’’)
df_sample=pd.DataFrame({'0':[0]*seg},index=[0]*seg)
创建
正则要删除 “…” 主要"."是通配符,需要转义
re.sub(r’…’, ‘.’, x) 替换的部分就不用转义了 in_file=in_file.loc[in_file.iloc[:,0]!= ‘.’] #去掉纯粹的点号
后面的等号是指整个字符为一个点号
pandas series 方法
df2 = df[df[columnname].str.contains(area)] 就是选择包含area变量中的字符串的行。
20200309
quantity=former_data.loc[former_data[‘target’]==target_,‘quantity’]
dataframe 筛选
只有loc 才有上面那种用法 相当于前面指定行,后面指定列
df整体只能是整行整行的筛选
csv 没有行数限制
xlsx 最高一百多万行
20200306
写条件判断的时候,多条件组合的所有情况
还有最边上的情况要考虑完全
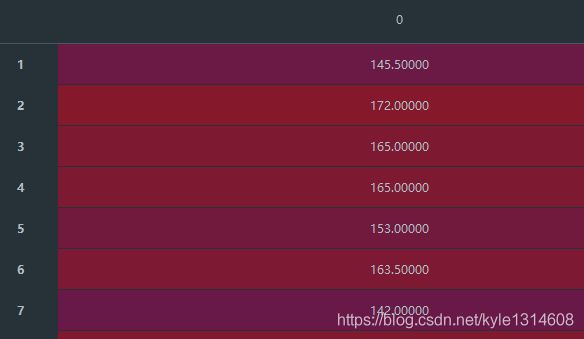
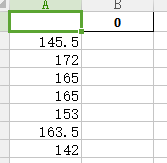
xlsx输出变成了这样,csv 输出则为正常
df.sample.columns = [[df[‘target’].iloc[i]]]
columns 等于的值 对象是列表的列表
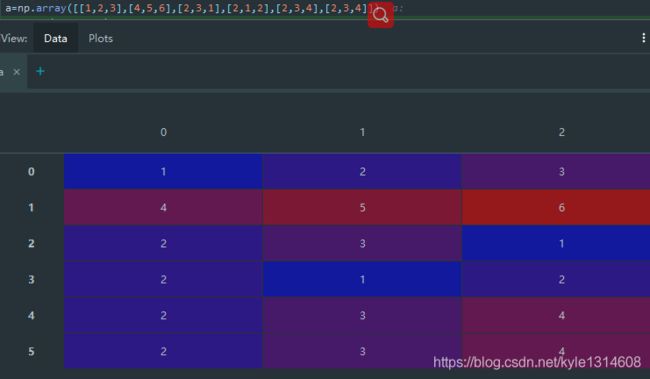
numpy,ndarray,dataframe 行列的对应
20200305
删除 test_dict_df.drop([‘id’],axis=1)
dataframe 的坑
data_df=data_df.dropna(thresh=0.5*data_df.shape[0],axis=0)
这里的阈值一定要设置 不然 一旦有一个值为空 整个都会被删掉
20200304
df.iloc[:, i_outlier][(df.iloc[:,i_outlier]>max_) or (df.iloc[:,i_outlier]
对每一行和每一列进行循环处理好像只能for循环
而对每一行或者每一列里面的每个值进行处理 则可以增加一行
或者一列来处理 不用for循环
20200303
iloc 不能用于扩展,会报溢出错误
而loc可以直接添加行或者列
dataframe 的index 本身是个array 对象
https://blog.csdn.net/qwertyuiop5rghar/article/details/84454670
https://blog.csdn.net/qwertyuiop5rghar/article/details/84454670
增加行 只能用 loc? 不能用iloc
扩充数据的时候 用增加行比增加列容易
http://www.voidcn.com/article/p-fnoxvztw-bxs.html
用字典随机填充数据

填充的时候前后的形状要对齐
缺失值填充
https://blog.csdn.net/donghf1989/article/details/51167083/
20200302
def sort_handling(self, df):
df_=df.astype(float)
for i_col in df_.columns:
temp_sort=df_.loc[:, i_col].sort_values()
temp_sort.index=range(temp_sort.shape[0])
df_.loc[:, i_col] = temp_sort #排序后索引没对齐 需要重新更改索引
每列单独排序
df_.loc[:, i_col] = df_.loc[:, i_col].sort_values() #排序后索引没对齐 需要重新更改索引
索引对不齐 执行不成功 需要更改索引
20200302
找出nan以及inf
https://blog.csdn.net/alanguoo/article/details/77198503
20200228
numpy数据类型dtype转换
https://www.jianshu.com/p/a1da90edf87f
dataframe 所有值筛选
df=df[df!=0]
20200226
在类里面 调用其中的某个函数时候用self.aa()
不能是在类内部,应该是在 某个函数内部才能调用self
字符到数值的映射
https://blog.csdn.net/liulunyang/article/details/88089962
dataframe 增加列 insert
https://blog.csdn.net/W_weiying/article/details/85247436
dataframe array 相互转换

20200225
df[‘舒张压.17’]=df[‘舒张压.17’].apply(lambda x: ‘’ if 1-bool(x.isdecimal()) else x)
1-bool(a) True 和 False的转换
if 的前面空值,直接写‘’,不用写x=‘’ 隐含已经有x=了
https://blog.csdn.net/laoyuanpython/article/details/94214189
判断是否为数值
df_sort[‘身高’][df_sort[‘身高’]<38.0]=int(df_sort[‘身高’].mean())
某一列中选出某些值 然后统一更改 左边中括号里面得到的是索引
df[col][df[col] >limit]=df[col][df[col] >limit]/1000
批量处理
列名称的改写
data_df.columns=[df['label'].iloc[i]]
20200224 空值或者Nan的选择
重点
对于不确定是什么样的空值
https://www.cnblogs.com/wqbin/p/12032073.html
data_df_not_nan=data_df[data_df!=‘NaN’]
data_df_non = data_df[data_df ==‘NaN’]
data_df_1=data_df[~data_df.isnull()]
上面是针对值为none的过滤
对NaN的处理 用dropna?
https://blog.csdn.net/xu136090331/article/details/94784021 这个是重点
https://www.jianshu.com/p/ab64424ee99e
上面两种为什么不起作用
https://blog.csdn.net/lwgkzl/article/details/80948548
空值的处理
df.dropna()
df[‘舒张压.17’][df[‘舒张压.17’]==’’] = 0
如果是空白 那用‘’处理
参考:
(3条消息)pandas中的DataFrame按指定顺序输出所有列 - quintind的专栏 - CSDN博客
https://blog.csdn.net/quintind/article/details/79691574
(1)创建数据框:
-
import pandas
as pd
-
grades = [
48,
99,
75,
80,
42,
80,
72,
68,
36,
78]
-
df = pd.DataFrame( {
'ID': [
"x%d" % r
for r
in range(
10)],
-
'Gender' : [
'F',
'M',
'F',
'M',
'F',
'M',
'F',
'M',
'M',
'M'],
-
'ExamYear': [
'2007',
'2007',
'2007',
'2008',
'2008',
'2008',
'2008',
'2009',
'2009',
'2009'],
-
'Class': [
'algebra',
'stats',
'bio',
'algebra',
'algebra',
'stats',
'stats',
'algebra',
'bio',
'bio'],
-
'Participated': [
'yes',
'yes',
'yes',
'yes',
'no',
'yes',
'yes',
'yes',
'yes',
'yes'],
-
'Passed': [
'yes'
if x >
50
else
'no'
for x
in grades],
-
'Employed': [
True,
True,
True,
False,
False,
False,
False,
True,
True,
False],
-
'Grade': grades})
-
print(df)
输出:

(2)整理按指定列输出
代码:
-
col = [
'Grade',
'Passed',
'ID',
'Class',
'Gender',
'Participated',
'Employed',
'ExamYear']
-
df=df.ix[:,cols]
输出:

(3) 数据框转化成列表
方法一:
借助数组
-
import numpy
as np
-
df = np.arrary(df)
-
df1 = df.tolist()
方法二:
df1 = (df.values).tolist()
输出结果:

(4)数据框中某一列的值转化为字符串
-
df2 = (df.values).tostring()
-
df3 = (df[
'ID'].values).tostring()
输出: 

不懂为啥是这个样子
希望的样子:
代码:
-
df4 = tuple(df[
'ID'])
-
df5 = str(df4)
输出:
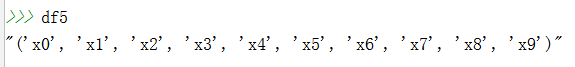
-- coding:utf-8--
import numpy as np
import pandas as pd
data_x = pd.read_csv(“E:/Tianchi/result/features.csv”,usecols=[2,3,4])#pd.dataframe
data_y = pd.read_csv(“E:/Tianchi/result/features.csv”,usecols=[5])
train_data = np.array(data_x)#np.ndarray()
train_x_list=train_data.tolist()#list
print(train_x_list)
print(type(train_x_list))
-- coding: utf-8 --
“”"
Created on Sat Jul 21 20:06:20 2018
@author: heimi
“”"
import warnings
warnings.filterwarnings(“ignore”)
import pandas as pd
import numpy as np
#导入自定义模块
import sys
from pandas import Series,DataFrame
from numpy import nan as NA
from os import path
sys.path.append( path.dirname(path.dirname(path.abspath(file))))
import mytools.midtools as midtools
from matplotlib.font_manager import FontProperties
#显示中文
font=FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=12)
path=r’D:/code12temp/自己笔记/’
pd.set_option(‘display.width’,None)
Series数据的连接
s1 = Series([0,1],index=[“a”,“b”])
s2 = Series([2,3,4],index=[“c”,“d”,“e”])
s3 = Series([5,6],index=[“f”,“g”])
result = pd.concat([s1,s2,s3])
result
result = pd.concat([s1,s2,s3],keys=[“one”,“two”,“three”])
result
#直接在外面再追加一层索引
#合并重叠数据
a = Series([NA,2.5,NA,3.5,4.5,NA],index=list(“fedcba”))
b = Series(np.arange(len(a)),dtype=np.float64,index=list(“fedcba”))
pd.concat([a,b])
#用其中一个Series中的数据给另一个Series中的数据作为补丁
resultB = b[:-2]
resultB
resultA = a[2:]
resultA
resultB.combine_first(resultA) #二者索引相同的时候 用ResultB的索引优先
而且B的元素为NAN的,通过A中有点来填充,B 中没有的,A中有的,直接填上
反正就是A的元素只会增加,不会减少
#创建层次化索引 两层索引
data = Series(np.random.randn(10),index= [list(“aaabbbccdd”),[1,2,3,1,2,3,1,2,2,3]])
data
将行索引(index)转换到列索引上(columns) 没行列
result = data.unstack()
result
result.stack()
DataFrame 中的行索引和列索引的重塑和转换
data = DataFrame(np.arange(6).reshape(2,3),
index=pd.Index([“上海”,“北京”],name=“省份”),
columns=pd.Index([2011,2012,2013],name=“年份”))
data
将DataFrame的列索引转化到行索引 烈士
result = data.stack()
#将DataFrame的行索引转化为列索引
#unstack()默认转换的最内层的层次化索引
result.unstack()
#第一种方法,转换的时候,指定层次化索引的名称
result=result.unstack(“省份”) #相当于交换了行列
result.stack()
#第二种方法,转换的时候,指定层次化的索引 0是result的第一列,1是后面一层
data=result.unstack(1)
data.unstack(1)
#在对DataFrame进行unstack操作时,作为旋转轴的级别将会成为结果中的最低级别
data = DataFrame(np.arange(6).reshape(2,3),
index=pd.Index([“Ohio”,“Colorado”],name=“state”),
columns=pd.Index([“one”,“two”,“three”],name=“nu mbers”))
data
result = data.stack()
df = DataFrame({“left”:result, #直接以series 为对象 并带来了行索引
“right”:result+5},
columns=pd.Index([“left”,“right”],name=“side”))
df
result = df.unstack(“state”) #放到原来索引的下一层
s1=Series([0,1,2,3],index=list(“abcd”))
s2 = Series([4,5,6],index=list(“cde”))
#将s1和s2拼接成一个具有层次化索引的Series
result = pd.concat([s1,s2],keys=[“one”,“two”])
result
#将结果中的行索引变成列索引 #多层索引序号以零开头
tempResult = result.unstack(1)
tempResult
#全部还原,空值用NaN填充
tempResult.stack(dropna=False)
3、pandas高级应用–数据转化、清除重复数据
data = DataFrame({“k1”:[“one”]*3+[“two”]*4,
“k2”:[1,1,2,3,3,4,4]})
#第一种方法,去重
#检测DataFrame中的每行数据是否为重复数据行
mask = data.duplicated() #当前行的记录和上一行记录进行比较
mask
#通过花式索引去除重复的数据
data[~mask] #保留为false的
#第二种方法:去重
#通过DataFrame内置的drop_duplicates()方法去除重复的数据行.
#去除
data.drop_duplicates()
data[“v1”] = range(7)
只以k1这一列为标准去重
data.drop_duplicates([“k1”])
#通过制定keep参数制定需要保留特定的重复数据
#keep=“first” 保留重复数据第一次出现的行索引
#keep=“last” 保留重复数据最后一次的行索引
#keep=False 只要有重复数据,就全部丢掉
data=DataFrame({‘food’:[‘bacon’,‘pulled pork’,‘bacon’,‘Pastrami’,
‘corned beef’,‘Bacon’,‘pastrami’,‘honey ham’,‘nova lox’],
‘ounces’:[4,3,12,6,7.5,8,3,5,6]})
meat_to_animal={
‘bacon’:‘pig’,
‘pulled pork’:‘pig’,
‘pastrami’:‘cow’,
‘corned beef’:‘cow’,
‘honey ham’:‘pig’,
‘nova lox’:‘salmon’}
data[“animal”]=data[“food”].map(str.lower).map(meat_to_animal)
data[“animal”] = data[‘food’].map(lambda x: meat_to_animal[x.lower()])
#这里的x.lower相当key了
4、pandas高级应用–数据替换
series = Series([1,-999,2,-999,-1000,3])
#单个数据替换
series.replace(-999,NA)
#多个数据替换
series.replace([-999,-1000],NA)
#replace方法传入字典,针对不同的值,进行不同的替换
#第一种方法
series.replace({-999:NA,-1000:0})
#第二种方法
series.replace([-999,-1000],[NA,0])
5、pandas高级应用–数据拆分
from matplotlib import pyplot as plt
age = [20,22,25,27,21,23,37,31,61,45,41,32]
#将所有年龄进行分组
bins = [18,25,35,60,100] #前开后闭
#使用pandas中的cut对年龄数据进行分组
cats = pd.cut(age,bins)
#调用pd.value_counts方法统计每个区间段的人数
pd.value_counts(cats) #直接统计
#区间属于那一行索引 按大小排序的
cats.codes
#为分类出每一组年龄加上标签
group_names = [“Youth”,“YouthAdult”,“MiddleAged”,“senior”]
#用group_name中的值,把区间替换
personType = pd.cut(age,bins,labels=group_names) #为什么这里不对
plt.hist(personType)
plt.show()
06、pandas高级应用–数据分割
data = np.random.randn(1000) # 服从正太分布
result = pd.qcut(data,4) # cut将data数据均分为4组
result
统计落在每个区间的元素个数
pd.value_counts(result)
cut函数分割一组数据 cut计算:找出data中的最大值最小值,之差除以4,得出区间值,然后以这个区间值分四份
data = np.random.randn(20)
用cut函数将一组数据分割成n份 precision:保留小数点的有效位数
result = pd.cut(data,4,precision=2)
pd.value_counts(result)
data = np.random.randn(1000)
根据分位数差的百分比分割
result=pd.qcut(data,[0,0.1,0.5,0.9,1.0])
pd.value_counts(result)
如果分为数的差值的和小于1的情况 分割的结果,安装分位数差之和计算
result = pd.qcut(data,[0,0.1,0.3,0.75])
pd.value_counts(result)
series.str.contains
http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.contains.html
07、pandas高级应用–数据的过滤和筛选
data = np.random.randn(1000,4)
df = DataFrame(data)
np.random.seed(num) #num是生成随机数的种子
np.random.randn() ##默认生成随机数的种子数是当前时间的时间戳
#定义一个种子数
np.random.seed(33)
np.random.rand()
np.random.seed(12345)
data = DataFrame(np.random.randn(1000,4))
data
简单的数据统计信息
data.describe()
获取数据的第四列
col = data[3]
筛选出绝对值大于3的数 #对series 直接饮用 np的数学函数,用中括号来放置条件
col[np.abs(col)>3]
查找出数据集中有任意某一列的值出现大于3的行数据
data[(np.abs(data)>3).any(1)] #对所有列进行处理
将所有绝对值大于3的正数设置为3,绝对值大于3的负数设置为-3
获取数据的符号
data[np.abs(data)>3] = np.sign(data)*3 #取符号
data.describe()
08、pandas高级应用–读写文件数据
import sys
pandas读取csv文件
data = pd.read_csv(‘data/ex1.csv’)
data
读取的csv文件没有标题,默认分配表头索引
pd.read_csv(‘data/ex2.csv’,header=None)
自定义添加标题
pd.read_csv(‘data/ex2.csv’,names=[‘a’,‘b’,‘c’,‘e’,‘name’])
指定行索引
pd.read_csv(‘data/ex2.csv’,names=[‘a’,‘b’,‘c’,‘e’,‘name’],index_col=‘name’) #不是很懂
将读取的数据进行层次化索引
pd.read_csv(‘data/csv_mindex.csv’,index_col=[‘key1’,‘key2’])
通过skiprows参数指定需要跳过的行索引
pd.read_csv(‘data/ex4.csv’,skiprows=[0,2,3])
加载存在NaN值缺值数据,把na_values对应的值替换为NaN
pd.read_csv(‘data/ex5.csv’,na_values=3)
把数据集中的NAN值替换
data.to_csv(sys.stdout,na_rep=[‘NULL’])
只写入数据,不写入行和列的索引
data.to_csv(sys.stdout,index=False,header=False)
data.to_csv(‘data/aa.csv’,index=False,header=False)
通过columns来指定写入文件中的列
data.to_csv(sys.stdout,index=False,columns=[‘a’,‘c’,‘message’])
09、pandas高级应用–数据的聚合及分组计算
df = DataFrame({“key”:[‘a’,‘a’,‘b’,‘b’,‘a’],
“key2”:[‘one’,‘two’,‘one’,‘two’,‘one’],
“data1”:np.random.randn(5),
“data2”:np.random.randn(5)})
df
选取data1数据列按照key1进行分组
groupd = df[“data1”].groupby(df[‘key’]) #除了可以按列分组,也可以按行分组
调用已经分组好的数据中一些方法,即可得出相应的统计结果
获取分组中每一组数据的平均值
groupd.mean()
根据key和key2两个列数据进行分组
grouped = df[‘data1’].groupby([df[‘key’],df[‘key2’]])
求平均
grouped.mean()
获取分组后每一组中相应元素出现的次数
df.index
df.groupby([df[‘key’],df[‘key2’]]).size() #或 df.groupby([‘key’,‘key2’]).size() #按行索引分组
for in 循环输出分组的结果
for name,group in df.groupby(“key”):
print(name)
print(group)
将groupby 分类结果转化成字典
pices = dict(list(df.groupby(‘key’))) #list的时候以逗号分隔key和values,dict 以分号代替逗号
pices[‘b’]
按照列的数据类型分组
group = df.groupby(df.dtypes,axis=1)
dict(list(group))
group.size()
选择分类数据中的一个或一组
方法一: 生成的数据类型是DataFrame
df.groupby([‘key’,‘key2’])[[‘data2’]].mean()
方法二: 生成的类型是series
df[‘data2’].groupby([df[‘key’],df[‘key2’]]).mean() #series 的groupby 和 dataframe 的groupby 是不一样的
方法三:
df.groupby([‘key’,‘key2’])[‘data2’].mean()
通过字典或series进行分组
people = DataFrame(np.random.randn(5,5),columns=list(‘abcde’),index=[‘Joe’,‘Stenve’,‘Wes’,‘Jim’,‘Travis’])
people
创建一个将列名进行映射的字典
mapping = {‘a’:‘red’,‘b’:‘red’,‘c’:‘blue’,‘d’:‘blue’,‘e’:‘red’,‘f’:‘orange’}
by_columns = people.groupby(mapping,axis=1) #相当于对列进行分组
gp=dict(list(by_columns)) #分组之后结果展示
gp[‘blue’]
by_columns.sum() #横向相加
将mapping转化成Series
seriesMap = Series(mapping)
people.groupby(seriesMap,axis=1).count() #即是不是这个dataframe的列也是可以作为分组的 #对列的数目进行统计 对每个行索引来说
分组后常用的计算方法
dict_obj = {‘key1’ : [‘a’, ‘b’, ‘a’, ‘b’, ‘a’, ‘b’, ‘a’, ‘a’],
‘key2’ : [‘one’, ‘one’, ‘two’, ‘three’, ‘two’, ‘two’, ‘one’, ‘three’],
‘data1’: np.random.randint(1,10, 8),
‘data2’: np.random.randint(1,10, 8)}
df = DataFrame(dict_obj)
按照key1进行分组求和
df.groupby(‘key1’).sum()
df[[‘data1’]].groupby(df[‘key1’]).sum()
求最大值
df.groupby(‘key1’).max()
df.groupby(‘key1’).describe()
第一种方法
定义一个函数,求获得DataFrame中某一列数据的最大值和最小值之差
def peak_range(df):
print(type(df))
return df.max()-df.min()
df.groupby(‘key1’).agg(peak_range) #分组之后对每列进行函数处理
用匿名函数的方式
第二种方法
df.groupby(‘key1’).agg(lambda df: df.max()-df.min())
使用agg对分组后的数据调用多个聚合函数
df.groupby(‘key1’).agg([‘mean’,‘sum’,‘count’,‘min’,‘std’,peak_range]) # 带引号的参数是内置聚合函数
df.groupby(‘key1’).agg([‘mean’,‘sum’,‘count’,‘min’,‘std’,(‘ptp’,peak_range)]) #peak_range 给peak_range起一个别名,叫ptp #起别名
使用字典实现数据集的每列作用不同的聚合函数
dict_mapping = {‘data1’:‘mean’,‘data2’:‘sum’}
df.groupby(‘key1’).agg(dict_mapping) #agg 传入函数 对每列进行不同的操作
以"没有索引形式"返回聚合函数的计算结果
df = pd.DataFrame(data={‘books’:[‘bk1’,‘bk1’,‘bk1’,‘bk2’,‘bk2’,‘bk3’], ‘price’: [12,12,12,15,15,17]})
将分组之后的books列作为索引
df.groupby(“books”,as_index=True).sum() #默认对剩下的price 进行处理
不让分组之后的books列作为索引
df.groupby(“books”,as_index=False).sum()
tips=pd.read_csv(path+’/input/pandasData/tips.csv’,encoding=‘gbk’)
10、pandas高级应用–分组计算apply
为tips数据集添加新的一列,作为客户给的小费占消费总额的百分比
tips[‘tip_pct’] = tips[‘tip’]/tips[‘total_bill’]
定义函数,筛选出小费占比最大的前五条数据
def top(df,n=5,columns=‘tip_pct’):
return df.sort_values(by=columns)[-n:]
top(tips,n=6)
#对数据集按抽烟进行分组
group = tips.groupby(‘smoker’)
group
使用apply方法分别求出抽烟和不抽烟的客户中的消费占比排在前五客户
group.apply(top) #直接对分组结果进行应用函数 相当于对两类都进行了处理
显示抽烟和不抽烟客户的数量
group.size()
group.count()
为apply中使用的函数传参
tips.groupby([‘smoker’,‘day’],group_keys=False).apply(top,columns=‘total_bill’,n=2) #前面是函数,后面是参数
#不显示key
frame = pd.DataFrame({‘data1’: np.random.randn(1000),
‘data2’: np.random.randn(1000)})
result = pd.cut(frame.data1,4) #每个值对应一个区间
pd.value_counts(result)
定义一个函数,求data1数据列各项参数计算
def get_stats(group):
return { ‘min’: group.min(), ‘max’: group.max(),
‘count’:group.count(), ‘mean’: group.mean() }
grouped = frame.data2.groupby(result)
dict(list(grouped))
grouped.apply(get_stats).unstack()
加权平均和相关系数
df = pd.DataFrame({‘category’: [‘a’, ‘a’, ‘a’, ‘a’, ‘b’, ‘b’, ‘b’,‘b’],
‘data’: np.random.randn(8), ‘weights’: np.random.rand(8)})
grouped = df.groupby(‘category’)
grouped.size()
Python数据处理进阶——pandas
https://www.cnblogs.com/llhy1178/p/6762459.html
df = DataFrame(np.random.randn(4,3), columns= list(“bde”),
index= [“Utah”, “Ohio”, “Texas”, “Oregon”])
print np.abs(df)
将函数应用到各列或行所形成的一维数组上。
f = lambda x : x.max() - x.min()
每一列的最大值减最小值
print (df.apply(f, axis=0))
每一行的最大值减最小值
print (df.apply(f, axis=1))
返回值由多个值组成的Series
返回值由多个值组成的Series
def f(x):
return Series([x.min(), x.max()], index=[“min”,“max”]) #对每列进行处理
print (df.apply(f)) #默认是对列进行操作
保留两位小数点
format = lambda x : “%.2f” % x
print (df.applymap(format)) #apply对series和对整个dataframe,applymap 对整个dataframe,map对series
print (df[“e”].map(format))
通过建立函数可以实现对数据库所有元素的修改操作
对dataframe的整体操作 所有元素操作
总的来说就是apply()是一种让函数作用于列或者行操作,applymap()是一种让函数作用于DataFrame每一个元素的操作,而map是一种让函数作用于Series每一个元素的操作
排序和排名
obj = Series(np.arange(4.), index=[“b”,“a”,“d”,“c”])
print obj.sort_index()
frame = DataFrame(np.arange(8).reshape((2,4)),index=[“three”,“one”],
columns=[“d”,‘a’,‘b’,‘c’])
按照索引的行进行排序
print (frame.sort_index(axis=1))
按照索引的列进行排序
print frame.sort_index(axis=0)
按照值的列进行排序(必须传入一个列的索引且只能排列一组)
frame.sort_values(‘b’, axis=0, ascending=False)
按照值的行进行排序(必须传入一个行的索引且只能排列一组)
frame.sort_values(“one”, axis=1, ascending=False)
根据多个列进行排序
frame.sort_index(by=[“a”,“b”])
排名
obj1 = Series([7,-5,7,4,2,0,4])
obj1.rank()
加减乘除 add代表加,sub代表减, div代表除法, mul代表乘法
df1 = DataFrame(np.arange(12).reshape((3,4)), columns=list(“abcd”))
df2 = DataFrame(np.arange(20).reshape((4,5)), columns=list(“abcde”))
df1 + df2 #找不到匹配的位置直接为空
将缺失值用0代替
df1.add(df2, fill_value=0) #找不到匹配的位置用单独一方的值替代
再进行重新索引时,也可以指定一个填充值
df1.reindex(columns=df2.columns, fill_value=0)
data = {“state”: [“Ohio”,“Ohio”,“Ohio”,“Nevada”,“Nevada”],
“year” : [2000, 2001, 2002, 2001, 2002],
“pop” : [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = DataFrame(data)
frame
矩阵的横坐标
frame.columns
矩阵的纵坐标
print frame.index
获取列通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series:
print frame[“state”]
print frame.year
获取行也通过类似字典标记的方式或属性的方式,比如用索引字段ix
print frame.ix[3]
精准匹配
val = Series([-1.2, -1.5, -1.7], index=[“two”, “four”, “five”])
frame.index = Series([‘one’, ‘two’, ‘three’, ‘four’, ‘five’])
frame.debt = val #debt 是啥东东
print frame
为不存在的列赋值存在列中的某个值会创建出一个布尔列。关键字del用于删除列。
frame[“eastern”] = frame.state == “Ohio”
del frame[“eastern”] # 只能这样表示 删除列
嵌套字典
pop = { “Nevada” : {2001 : 2.4, 2002 : 2.9},
“Ohio” : {2000 : 1.5, 2001 : 1.7, 2002 : 3.6}
}
传给DataFrame,它会被解释为:外层字典的键作为列,内层键则作为行索引
frame2 = DataFrame(pop)
对该结果进行转置
frame2.T
内层字典的键会被合并、排序以形成最终的索引。
frame3 = DataFrame(pop, index=[2001, 2002, 2003])
frame3.index.name = “year”; frame3.columns.name = “state” #索引和列只有一个名字
重新索引
obj = Series([4.5, 7.2, -5.3, 3.6], index=[“d”, “b”, “a”, “c”])
reindex将会根据新索引进行重排。
obj2 = obj.reindex([“a”, “b”, “c”, “d”, “e”])
print obj2
将缺失值用0代替
obj2 = obj.reindex([“a”, “b”, “c”, “d”, “e”], fill_value= 0)
print obj2
插值处理–Series
obj3 = Series([“blue”, “purple”, “yellow”], index=[0,2,4])
前向填充ffill或pad
obj3.reindex(range(6), method=“ffill”)
print a
后向填充bfill或backfill
b = obj3.reindex(range(6), method=“bfill”)
print b
插值处理–DataFrame
import numpy as np
f = DataFrame(np.arange(9).reshape((3,3)), index=[“a”,“c”,“d”],
columns=[“Ohio”, “Texas”, “California”])
改变行的索引
f2 = f.reindex([“a”,“b”,“c”,“d”], fill_value=9)
print f2
改变列的索引
col = [“Texas”, “Utah”, “California”]
f3 = f.reindex(columns=col)
print f3
同时改变列和行的索引 不成功
f4 = f.reindex([“a”,“b”,“c”,“d”], method=“ffill”,
columns=[“Texas”, “Utah”, “California”])
print f4
丢弃指定轴上的项–Series
mys = Series(np.arange(5.), index=[“a”,“b”,“c”,“d”,“e”])
print mys
drop()删除某个索引以及对应的值
mys_new = mys.drop(“c”)
print mys_new
mys_new1 = mys.drop([“c”,“e”])
print mys_new1
丢弃指定轴上的项–DataFrame
data = DataFrame(np.arange(16).reshape((4,4)),
index=[“Ohio”, “Colorado”, “Utah”, “New York”],
columns=[“one”, “two”, “three”, “four”])
删除某行轴上的值
data1 = data.drop([“Ohio”,“Utah”], axis=0) # axis=0代表行
print data1
删除某列轴上的值
data2 = data.drop([“one”,“three”], axis=1) # axis=1代表列
print data2
obj = Series(range(5), index=[‘a’, ‘a’, ‘b’, ‘b’, ‘c’])
使用is_unique属性可以知道他的值是否是唯一的
obj.index.is_unique
obj[‘a’]
df = DataFrame(np.random.randn(4, 3), index=[‘a’, ‘b’, ‘a’, ‘b’])
df.ix[“b”, 1]
df[1]
pandas中的索引高级处理:
索引、选取和过滤–Series
obj = Series(np.arange(4), index=[“a”,“b”,“c”,“d”])
print obj[“b”]
print obj[1]
print obj[2:4]
print obj[[“b”,“a”,“d”]]
print obj[[1,3]]
print obj[obj < 2]
利用标签的切片运算与普通的python切片运算不同,其末端是包含的
print obj[“b”:“c”]
obj[“b”:“c”] = 5
print obj
结束