HBase compact 总结 及 调优配置
1 Compaction介绍
在HBase中,每当memstore的数据flush到磁盘后,就形成一个storefile,当storefile的数量越来越大时,会严重影响HBase的读性能 ,所以必须将过多的storefile文件进行合并操作。Compaction是Buffer-flush-merge的LSM-Tree模型的关键操作,主要起到如下几个作用:
(1)合并文件
(2)清除删除、过期、多余版本的数据
(3)提高读写数据的效率
HBase中实现了两种compaction的方式:minor and major. Minor compactions will usually pick up a couple of the smaller adjacent StoreFiles and rewrite them as one. Minors do not drop deletes or expired cells, only major compactions do this. Sometimes a minor compaction will pick up all the StoreFiles in the Store and in this case it actually promotes itself to being a major compaction.
这两种compaction方式的区别是:
<1> Minor操作只用来做部分文件的合并操作以及包括minVersion=0并且设置ttl的过期版本清理,不做任何删除数据、多版本数据的清理工作。
<2>Major操作是对Region下的HStore下的所有StoreFile执行合并操作,最终的结果是整理合并出一个文件。
2 Compaction执行流程及核心算法
在HBase实现中,通过CompactionChecker线程来定时检查是否需要执行compaction,同时每当RegionServer发生一次memstore flush操作之后也会进行检查是否需要进行compaction操作。具体的执行流程通过下面的章节进行展开。
2.1 Compaction执行流程
2.1.1 HRegionServer启动流程
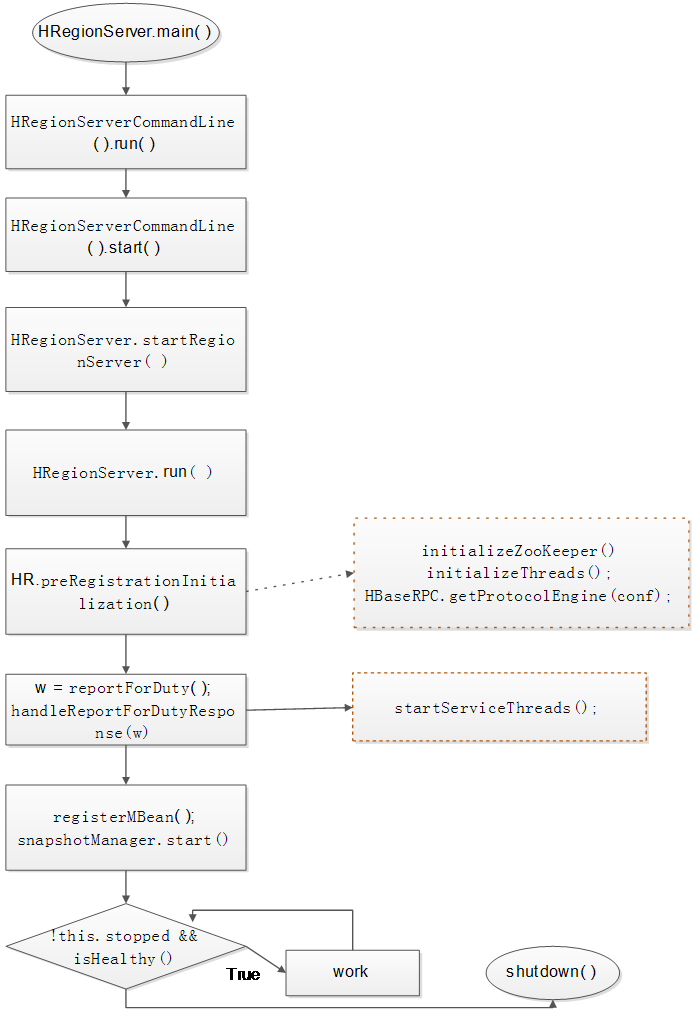
在regionserver的启动过程中,与compact相关的主要是在initializeThreads() 和 startServiceThreads()部分,在initializeThreads()中,主要是初始化了compact处理线程CompactSplitThread和compact检查线程CompactionChecker。线程CompactionChecker每隔10000秒检查一次是否需要进行Compact,当需要进行Compact的时候,CompactSplitThread开始处理每一个Compact请求。
2.1.2 CompactionChecker执行流程
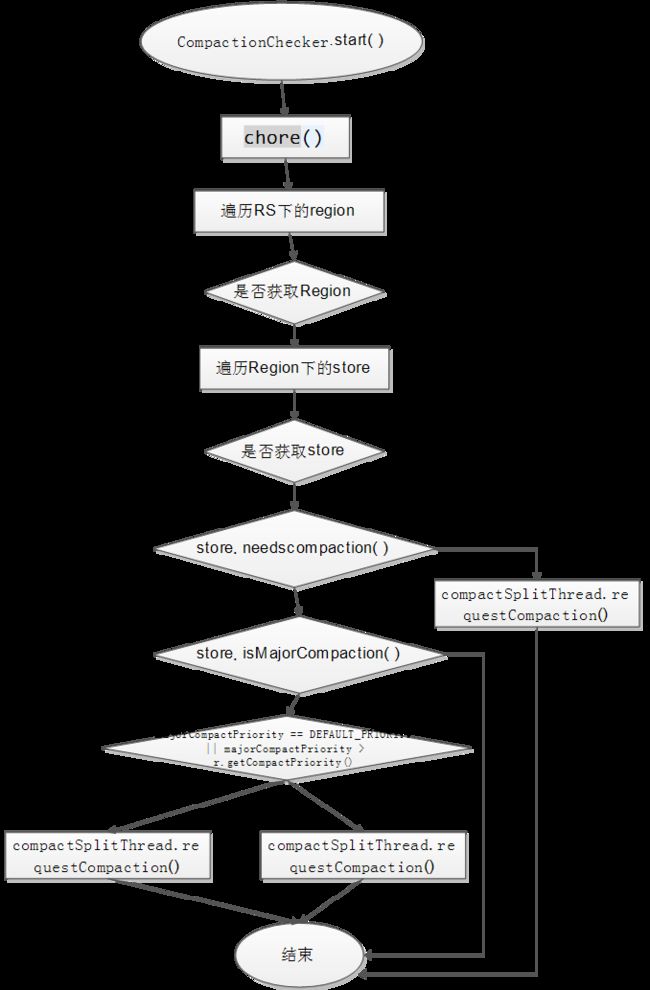
Compact检查线程每隔10000秒(可配置)开始检查当前Regionserver下的Region是否需要进行Compact,检查的过程是遍历每个Region,然后遍历该Region下的每个store,然后判断该store是否需要进行Compact,判断的标准是:
(storefiles.size() - filesCompacting.size()) > minFilesToCompact
即:当前store下storefile数量减去正在进行Compact的storefile的数量 大于 minFilesToCompact(可配置)值的时候 需要进行Compact,那么就开启一个CompactSplitThreads线程开始处理。如果上述判断失败,检查线程还会判断是否需要进行major_compact,如果需要,还要根据Compact的优先级开始不同优先级的CompactSplitThreads线程进行处理。
2.1.3 CompactSplitThread执行流程
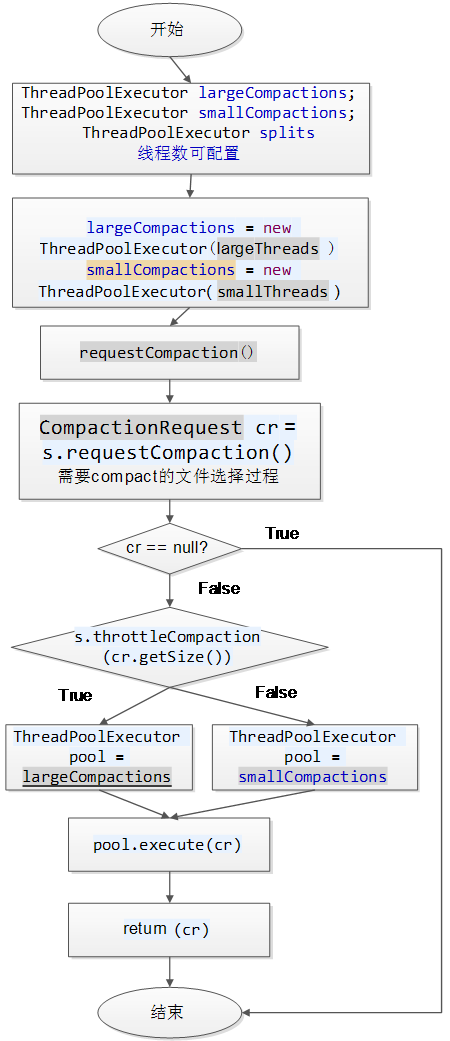
CompactSplitThread处理线程初始化两个线程池:largeCompactions和smallCompactions,这两个线程池的线程数目都是可以配置的。线程池初始化完毕之后,在一个store里选择需要Compact的storefile,选择完毕后封装成一个CompactRequest请求。在执行该请求之前,需要判断选择那个线程池进行处理,选择判断的方式是:
s.throttleCompaction(cr.getSize())? largeCompactions : smallCompactions
即:如果需要compact的storefile的size大于配置值的情况下选择largeCompactions线程,反之。在具体处理线程池选择完毕之后,开始执行Compact过程,pool.execute(cr),即一个CompactRequest请求是一个继承Runnable的类,他实现了run()方法,具体的执行流程在下一章节描述。
2.1.4 CompactionRequest 执行流程
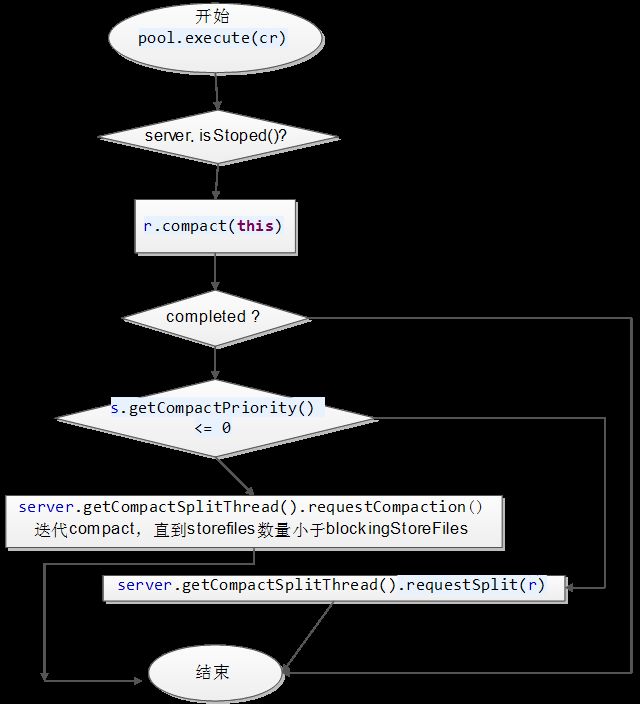
一个CompactRequest的处理过程是从r.compact()开始的,当一个Region的compact过程处理完毕之后,还需要判断是否需要迭代执行Compact,判断的条件是:
this.blockingStoreFileCount - this.storefiles.size()<=0
blockingStoreFileCount小于等于当前store下storefile的数量时,还需要继续进行compact,即需要将每个的store下的storefile的数量保持在blockingStoreFileCount(可配置)以下。


Region的compact函数最终调用的是store的compact函数,而每个store类都有一个compactor实例,Compactor类包含了compact算法的具体实现过程。
2.2 Compact File选择算法
(过程复杂,后期整理)
2.3 Compact 实现算法
(过程复杂,后期整理)
3 Compact参数调优
通过整理Hbase compact的流程,可以发现很多与compact相关的参数可以进行调整。具体参数如下所示:
| 参数名 |
含义 |
默认值 |
调优配置 |
| hbase.hregion.majorcompaction |
majorCompaction自动执行的时间间隔 |
86400000 s |
0 |
| hbase.hstore.compaction.min (hbase.hstore.compactionThreshold) |
触发compaction的参数 |
3 |
最大值 |
| hbase.hstore.compaction.max |
每次Compact合并文件数的上限 |
10 |
|
| hbase.hstore.blockingStoreFiles |
st在storefile数量的上限 |
7 |
最大值 |
| hbase.hstore.blockingWaitTime |
minor_compaction阻塞data update的时间上限值 |
9000 ms |
|
| hbase.regionserver.thread.compaction.small |
smallCompaction线程池的线程数 |
1 |
5 |
| hbase.regionserver.thread.compaction.large |
largeCompaction 线程池的线程数 |
1 |
5 |
| hbase.hstore.compaction.kv.max |
compaction过程中,每次从Hfile中读取kv的个数 |
10 |
不发生oom情况下,可以调大 |
| hbase.hstore.compaction.min.size |
选取Compaction文件时的参数值 |
memstore.flush.size |
|
| hbase.regionserver.thread.compaction.throttle |
判断选择那个线程池 |
2 * minFilesToCompact * memstoreFlushSize |
|
| hbase.server.thread.wakefrequency |
每隔一定时间检查是否需要进行compaction |
10000s |
为了减少compact,是否可以调高? |
对于以上配置,都是与Compaction相关的参数,在保证读性能的前提下,需要优化上述配置,以尽量减少Compaction的发生,上述配置是完全禁止了compaction,然后在实际中以手动的或者定时的方式去执行compaction。
PS: 上述的配置关闭了minor compaction,一开始 线上写压力不大,所以在凌晨的major compact做完后, 积累的storefile数量一直不多,所以没有对读造成性能影响。 后来 , 线上集群写压力上升,每天下午4,5点的时候 每个region下都有 200-500的storefile积压,业务端出现了大量的读超时。因此minor compaction关闭是错的选择,
目前修改为: hbase.hstore.compaction.min 10 , hbase.hstore.blockingStoreFiles 100; 即当一个region下storefile数量到10时,开始执行minor_compact, 如果写压力很大,以至于达到100个时, block一下写(停止blocking的条件:要么小于100,要么超过配置的block time).