(4)MySQL实例启动原理及mysqld服务三层结构
MySQL实例原理及mysqld服务三层结构
文章目录
- MySQL实例原理及mysqld服务三层结构
- MySQL实例
- 例子一 : windows系统中的进程启用原理。
- 例子二 : mysql数据库启用原理
- 例子三 : MySQL启动过程
- mysqld 服务程序结构
- 第一层: 连接层
- 第二层: SQL层
- 查询缓存解释说明
- 第三层: 储存引擎层
MySQL实例
- mysql启动过程
1)启动后台守护进程,并生成工作线程,
2)预分配内存结构供mysql处理数据使用
- 实例是什么?
MySQL的后台进程+线程+预分配的内存结构
- 原理上来讲实例是不包括数据的:
- 第一种理解方式:
数据库→ 实例+数据文件 - 第二种理解方式:
数据库管理系统 → 实例+数据文件
例子一 : windows系统中的进程启用原理。

- 说明:
在windows系统中,文件和程序都是
存放在磁盘中的某一个位置,当我们打开word文件后会相应的一起打开word应用,并向内存申请一段内存空间,然后让应用运行起来,程序会被放入内存中,文件也会在内存中缓存,word程序使用应用指令修改缓存中的文件数据内容,保存时,再把变更后的文件写入到磁盘中去,然后关闭程序
- 注意:
在windows中是启用程序后才会占用内存
例子二 : mysql数据库启用原理
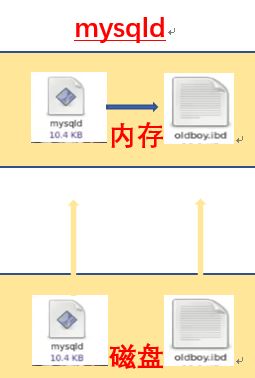
- mysql存放数据的文件目录
/application/mysql/data
(1)所有的数据都会存放在此目录
(2)在数据目录下会存放表
比如shuai.idb数据文件
(3)所有的数据都会在这里存着
- 说明:
- 相同点:
mysql和Windows中的word相同点是mysql也是将程序运行起来修改文件。
- 不同点:
执行/etc/init.d/mysqld start后mysql程序就会一直从内存中等待着被使用
(守护进程:mysqld)在启动的过程中一次性的申请一段内存,把需要用到的内存结构都分配好.
例子三 : MySQL启动过程
- MySQL在启动过程
- 启动后台守护进程(mysqld),并生成工作线程
- 预分配内存结构供MySQL处理数据使用
- 线程是干活的,进程是分配线程的
- MySQL启动过程中,启动了一个守护进程(mysqld),并生成了许多线程
- mysqld 作为实例中最核心的组成
- mysqld 是一个守护进程,但
本身不能自主启动 - 由mysqld这个主进程来
派生出子线程,负责所有协调的工作,让子线程进行工作
- 实例是什么?
- MySQL的后台进程+线程+预分配的内存结构统称为实例
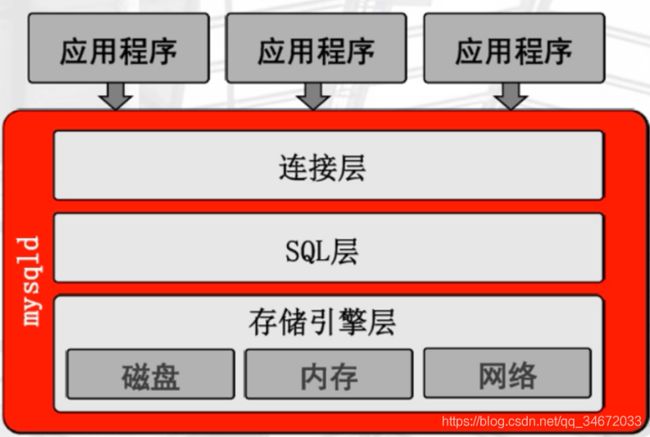
mysqld 服务程序结构
- 分为三层结构
- 连接层
- SQL层
- 存储引擎层
- 如下图所示
第一层: 连接层
- 协议: 提供连接协议
TCP/IP协议
socket套接字
- 验证: 验证连接协议的合法性
检查连接的用户/密码和白名单(IP地址)是否存在于数据库的表中,如果没有则不能通过验证登录到数据库中.
mysql> select user,host,password from mysql.user;
+------+-----------+-------------------------------------------+
| user | host | password |
+------+-----------+-------------------------------------------+
| root | localhost | *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 |
| root | db01 | |
| root | 127.0.0.1 | |
+------+-----------+-------------------------------------------+
- 线程: 开辟一个专用线程来提供连接服务(
接受SQL/返回结果),将SQL语句交给SQL层继续处理
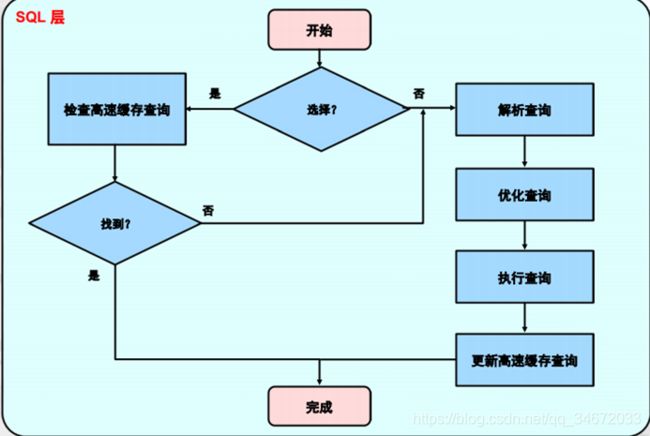
第二层: SQL层
-
SQL层处理流程图解
-
SQL:结构化的查询语言(数据库内部的逻辑语言)又分为:
DDL:数据库定义语言
DCL:数据库控制语言
DML:数据库操作语言
DQL:数据查询语言
- SQL层功能解析
(1)接收到SQL语句
判断语法,判断语义,判断语句类型:(DML,DDL,DCL,DQL)
(2)数据库不能真正理解SQL语句
必须明确的知道,数据在哪个磁盘的,哪个文件的哪个,哪个页上。
(3)数据库对象授权情况进行检查.
(4)解析SQL语句(解析器)
将sql语句解析成多种执行计划,MySQL没法直接执行SQL语句,必须解析成执行计划,运行执行计划,最终生成如何去磁盘找数据的方式.
(5)优化器
根据不同执行计划,选择它认为成本最低的执行计划
MySQL5.6以后学习了oracle的基于代价算法,从N种执行计划中,选择代价最小的交给"执行器"
(6)执行器
执行器根据优化器的选择,按照优化器建议执行SQL语句,得到去哪找SQL语句需要访问的数据
具体:
在哪个数据文件上的哪个数据页中?
将以上结果传送给下层继续处理。
(7)接收储存引擎层的数据,结构化成表的形式(将取出的数据抽象成管理员或用户能看懂的方式(表)),通过连接层提供的专用线程,将表数据返回给用户。
(7)提供查询缓存
缓存之前查询的数据,加入查询的表是一个经常变动的表,查询缓存不要设置太大,
query_cache(查询缓存),建议使用memcache或者Redis替代。
(8)日志记录(binlog)
查询缓存解释说明
- 缓存条件,原理
MySQL Query Cache是用来缓存我们所执行的SELECT语句以及该语句的结果集,MySql在实现Query Cache的具体技术细节上类似
典型的K/V存储,就是将SELECT语句和该查询语句的结果集做了一个HASH映射并保存在一定的内存区域中。当客户端发起SQL查询时,Query Cache的查找逻辑是,先对SQL进行相应的权限验证,接着就通过Query Cache来查找结果(注意必须是完全相同,即使多一个空格或者大小写不 同都认为不同,即使完全相同的SQL,如果使用不同的字符集、不同的协议等也会被认为是不同的查询而分别进行缓存)。它不需要经过Optimizer模块进行执行计划的分析优化,更不需要发生同任何存储引擎的交互,减少了大量的磁盘IO和CPU运算,所以有时候效率非常高。
- 查询缓存的工作流程如下:
- 命中条件
(1)缓存存在一个hash表中,通过查询SQL,查询数据库,客户端协议等作为key.
在判断是否命中前,MySQL不会解析SQL,而是直接使用SQL去查询缓存,SQL任何字符上的不同,如空格,注释,都会导致缓存不命中.
(2)如果查询中有不确定数据,例如CURRENT_DATE()和NOW()函数,那么查询完毕后则不会被缓存.所以,包含不确定数据的查询是肯定不会找到可用缓存的
(3)内存的容量不一定是内存越大越好,要保持刚刚好!这与命中率有关
- 工作流程
- 服务器接收SQL,以SQL和一些其他条件为key查找缓存表(额外性能消耗)
- 如果找到了缓存,则直接返回缓存(性能提升)
- 如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等.
- 执行完SQL查询结果以后,将SQL查询结果存入缓存表(额外性能消耗)
第三层: 储存引擎层
-
存储引擎层功能
(1)接收上层的执行结果
(2)取出磁盘文件和相应数据
(3)返回给SQL层,结构化之后生成表格,由专用线程返回给客户端 -
储存引擎概览:
存储引擎是充当不同表类型的处理程序的服务器组件:
-
储存引擎用于:
(1)存储数据(将SQL语句做的修改转储到磁盘上)
(2)检索数据(把存进去的数据在提取出来)
(3)通过索引查找数据(通过缓存缓冲机制提供mysql数据库的整体性能) -
双层处理:
(1)上层包括SQL解析器和优化器
(2)下层包含一组储存引擎 -
SQL层不依赖于存储引擎:
(1)引擎不影响SQL处理
(2)也有一些例外的情况
- 依赖于存储引擎的功能
- 存储介质
- 事物功能
- 锁定
- 备份和恢复(比如支持热备)
- 优化
- 特殊功能:
1) 全文搜索
2) 引用完整性
3) 空间数据处理