从招聘信息看-数据分析师(数据分析报告)
从招聘信息看-数据分析师
项目简介
有意转向数据分析这个岗位,那自然首先需要对这个岗位有所了解。最直接,最真实的方式就是从企业那里获取需求信息,从而能够知道自己学习的方向和简历的准备。
本次项目主要利用爬虫爬去拉钩网上根据数据分析这一关键词所查询的岗位在全国范围能的岗位搜索结果,进行一些数据分析来了解“数据分析”。
数据来源和数据集
本项目所使用的数据集全部来源于拉钩网,之所以选择拉钩网作为本项目的数据源,主要是因为相较于其他招聘网站,拉勾网上的职位信息非常完整,整洁,极少存在信息的缺漏,并且几乎所有展现出来的信息都是非常的规范化,本次数据获取为通过python撰写爬虫代码来进行数据爬去,得到的为csv文件,方便后续处理,爬去时间为4月11号。
本次爬去的信息主要获得了一下信息:
城市:City,岗位名称:Title,公司名称:Company,公司编号:Company_Number,所属行业:Company_Industry,公司规模:Company_Scale,月薪Salary,经验要求:Experience,学历要求:Education_level,在职状态(如全职):State',福利:State,岗位职责和任职要求:Description。
目的
主要希望通过实际的数据来解答针对数据分析岗位的一些疑惑,具体来讲:主要针对一下几个问题:
- 数据分析岗位需求的地域性分布;
- 整个群体中薪酬分布的情况;
- 不同城市数据分析师的薪酬情况;
- 该岗位对于工作经验的要求是怎样的;
- 根据工作经验的不同,薪酬是怎样变化的;
- 从用人单位的角度看,数据分析师应当具备哪些技能?
- 掌握不同的技能是否会对薪酬有影响?影响是怎样的?
技术和工具
本项目主要以Python为编程语言,Python代码简单十分容易被读写,具有丰富和强大的库,其在网络爬虫的传统应用领域,在大数据的抓取方面具有先天优势。项目的主体分为三大部分:第一部分是数据爬去,python在pycharm上进行的窜写的一个简单的爬虫工具。第二部分是数据清洗,由于是直接爬去的网上数据,需要对数据进行去重和归一化处理。第三部分进行数据分析,两部分均在Jupyter上进行。
数据搜集:
主要使用了urllib库用于抓取网页,selenium用于处理鸡动态加载网页,lxml库从而使用xpath进行网页解析,csv库用于得到数据的存储,当然使用time库进行爬去速度的控制。
 以下为主要爬去的字段和代码,部分字段名在存取csv格式是,已经更改。
以下为主要爬去的字段和代码,部分字段名在存取csv格式是,已经更改。
共爬去拉钩网根据数据分析关键词爬去前29页内容,得到429条数据,分别爬去字段12个:其中Company_Nuamber为改拉勾网中所链接的具体公司信息的url最后一部分,为防止公司名称情况,以此作为公司编码唯一标识符。

本次爬去的信息主要获得了一下信息:
城市:City,岗位名称:Title,公司名称:Company,公司编号:Company_Number,所属行业:Company_Industry,公司规模:Company_Scale,月薪Salary,经验要求:Experience,学历要求:Education_level,在职状态(如全职):State',福利:State,岗位职责和任职要求:Description。
数据整理
数据加载:

数据处理:

由于会进行薪资分析。故需要获得需要字段。

另外需要去重处理,根据'Company_Number','Title'两个字段进行去重,'Company_Number'为公司编号,属于该公司唯一标识符,'Title'为职位名称,本次数据爬去时间为4月12号,所爬去的工作发布时间范围均为近一周,所以同一公司发布的相同职位视为重复值进行去重处理。处理后的数据为389条。

数据分析
主要使用了numpy,pandas,matplotlib,jieba,worscloud这几个库
地域性分布:
分别绘制了柱状图和饼图由于在柱状图上不能很好的显示各个百分比,进而绘制了饼状图:


进一步绘制一个饼图:
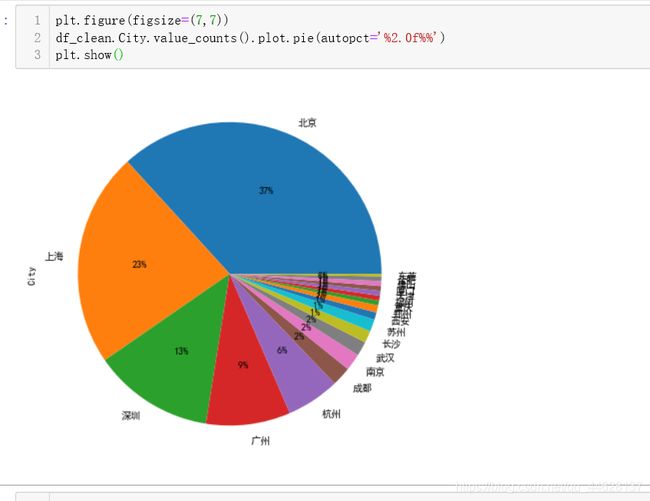

有图可知,在本次统计量范围内,全国有19个城市有数据分析师的需求,数据分析需求以北京最大达到37%,然后依次为上海,深圳,广州,这四个城市综合占比高达82%,杭州位列第五名。
所在行业:


所在前三为:移动互联网,金融,数据服务,其次为电子商务,看来数据分析及偏向与互联网,金融等领域,同时,在北上广深等人才需求量大。这些一线城市都有大量的互联网企业,这与该职位的地域和行业的情况是完全吻合的。,总的的来说这种饼状图是根据行业标签拆分来看的,误差比较大,在拉钩网上公司很大一部分公司具有两种标签的,在这里只是简单的进行李各个标签的统计,同时考虑到拉钩网是一个偏重互联网行业的招聘平台,所以分析并不是十分色全面。
简而言之,数据分析岗位,大量的工作机会集中在北上广深和杭州,希望向这方面发展的同学还是要到这些城市进行多多尝试。当然,所在的行业很可能为移动互联网,金融,数据服务等行业。也需要注意的是,这些城市都集中了大量的各个行业的人才,竞争压力也是十分大的。
总体薪酬情况:


如同大多数其他工作一样,数据分析师的薪资也是属于右偏分布,大多数人的收入集中在5k-30每月,只有少数人能获得很高的收入,让人充满期待。需要说明的是,拉钩网上的薪资是一个区间值,在这里为了方便分析,我取中间值进行分析。因此,实际的薪酬可能有所偏差。
不同城市的薪酬分布情况:



在知道城市需求的情况下,忽略掉哪些人才需求量较小的城市,我重点关注排名前6的城市。从图上可以看出六大城市的薪酬总体来说较为集中,这个我们前面看的全国的总体薪酬分布是一致的。北京的薪酬中位数大约在20K,局全国首位,其次为上海稍微少一些,以这六个城市,在右边可以看到平均薪资在18.7k。
不同工作经验的薪酬装状况:


很显然随着工作经验的提升,数据分析师的工资也在不断提高。经验不限的考虑到为转行等等情况,月薪与应届毕业生相似,同时工资均值在箱体上缘,基本在第三分位数,说明有一部分可以拿到教为客观的工资,但是大部分人工资依旧较为集中在10k一下。总的来讲,由现有的数据来看,数据分析师似乎是一个常青职业方向,在10年内大概不会因为年龄的增长导致收入下降。
对于是经验需求:


从图上看,用人单位需求度最高的为经验1-3年和经验3-5年的熟练的分析师需求量最大,经验不足1年的需求量最小,对于应届毕业生似乎要较为友好一些。另外对应经验5-10年的需求量也较少。
从这个分布我们大致可以猜出:数据分析是一个年轻的职业方向,大量的需求在1-3年和3-5年。对于数据分析师来讲,5年是一个瓶颈期,如果5年内没有转型或者质的提升,以后的竞争压力比较大。
技能关键词:



从词云显示可以看出,数据分析师这一岗位,企业最看重的为数据挖掘的能力,那么详细来看就要求这个岗位的从业人员需要的技能为Python,Excel,SQL,Spss,ppt,hive,BI和Mysql等,要求从从业人员有进行提供数据,将会算法,建立模型,提供数据报表和可视化展示。在人员品德上要求为有责任心,良好的沟通能力,逻辑思维,抗压能力好等等。
那么想要从事数据分析岗位的小伙伴必备技能看起来就:Python,SQL,Excel。
为了进一步挖掘技能对工资的影响,我在这里进一步绘制了不同技能对工资影响的气泡图,在这里较为简单的举例了常见的15个工具形技能,y轴对应于薪资及包含该技能的平均工资,气泡大小为招聘岗位数量。

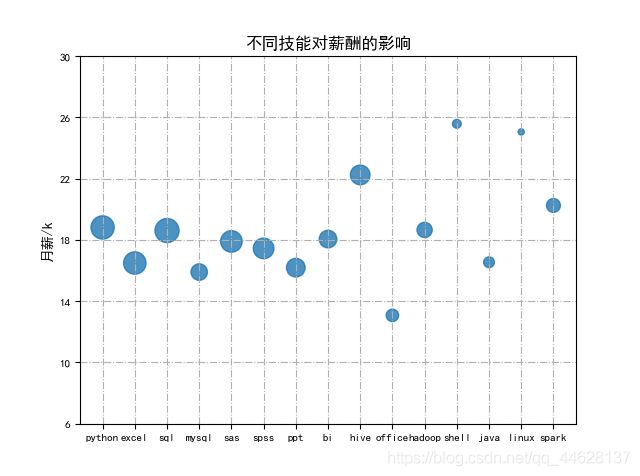
在这15项技能中可以看出,shell、Hive、Spark,Liunx则四者的平均薪资最高,相较于其他技能来说有较大差异。对数据分析师工作有所了解的可以知道,hive和Spark都是应用于分布式数据处理,而Shell脚本则是Liunx系统下的必备技能。它们共同指向:海量数据分布式处理。
所以,想拿高薪的小伙伴注意,海量数据处理、分布是处理框架是走向高薪的正确方向。
另外值得注意的是,在数据分析领域,Python语言的平均薪酬要高于Java语言,而SQL语言、Excel则能让你保持在中等收入水平,SAS、SPSS,还有数据可视化工具BI拥有众多的需求,多技能意味这能适应更多的企业要求,也意味这更多的工作机会。
结论分析
- 数据分析这一岗位有大量工作机会集中在北上广深和杭州。
- 数据分析师这一岗位主要的领域为移动互联网,金融法,数据服务等行业。
- 大多数人数据分析师的工资集中在10K-25K,每月,只有少数的人能够获得高工资。
- 从待遇上来看,数据分析师留在深圳发展是个不错的选择,其次是北京、上海。
- 对于数据分析师是年轻的职业,大量的企业需求为经验1-3年和3-5年,对于经验不限的人数招聘也较为友好。
- 对于数据分析师来说,五年似乎是个瓶颈,5年以后需要面临转型或者需要有质的提升。此时竞争压力将会比较大。
- 随着经验的提升,数据分析师的薪酬也在不断提高,有丰富工作经验的人能获得相当丰厚的薪酬。
- 数据分析市的需求有数据挖掘的基本能力,对于技能的具体要求排在前列的有:SQL、Python、Excel。SAS、Spss等等,其中Python,SQL和Excel简直为必备技能。当然对于个人还要求有良好的责任心,抗压能力,沟通能力等等。
- 海量数据,分布式处理框架是走向高薪的正确方向。
- 而SQL语言、Excel则能让你保持在中等收入水平,SAS、SPSS,还有数据可视化工具BI拥有众多的需求,多技能意味这适应更多的企业要求,也意味这更多的工作机会。
思考和总结:
首先,对于数据分析师爬虫所爬去的数据量并不是很大,同时在由于是在拉勾网上所爬去的相关信息主要是互联网行业,对于其他行业的企业并不一定适用,如需要全面分析需要更多的数据获取。其次,对于数据分析师技能的分析,只做了工具形技能的分析,并且是在假设技能之间是无相关关系的情况下进行分析。首先技能的选择较为片面,如需要拓展如统计学,数学,计算机专业,算法,书写数据分析报告等等,同时技能归类如SQL技能统计(如应考虑MySQL·的归类)也是有所偏差。最后,本次数据分析报告主要参照优达学城网站的《数据分析师挣了多少前?“黑”了招聘网站告诉你》这篇文章。再次特别感谢。
由于时间有限,在这里就不进一步分析展开。有不足之处,还望见谅。