Flink(2):实现流处理实例(Java和scala)
一、实现功能
使用scala和java分别实现Flink的流式处理。
二、实现功能代码
1.Java
(1)代码
package com.bd.flink._1130WordCount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Created by Administrator on 2019/11/30.
* 使用Java API开发Flink 实时处理
*/
public class StreamingWordCountJava {
public static void main(String[] args) throws Exception {
int port=0;
//通过传入参数获取端口,但是默认式9999
try {
ParameterTool parameterTool=ParameterTool.fromArgs(args);
port=parameterTool.getInt("port");
}catch (Exception e){
System.out.println("端口未输入,默认端口为9999");
port=9999;
}finally {
}
//第一步:创建开发环境
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
//第二步:读取数据
DataStreamSource text=env.socketTextStream("hadoop01",9999);
//第三步:开发业务逻辑(transform operations)
text.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(String value, Collector> collector) throws Exception {
String[] tokens=value.toLowerCase().split(" ");
for (String token : tokens) {
if(token.length()>0){
collector.collect(new Tuple2(token,1));
}
}
}
}).keyBy(0).timeWindow(Time.seconds(5)).sum(1).print().setParallelism(1); //setParallelism并行度设置为1
//第四步:执行程序(execute program),Streaming 需要执行
env.execute("Streaming app is running");
}
} (2)开启服务器对应端口9999
[root@hadoop ~]# nc -lk 9999(3)添加运行参数端口号:--key value形式输入
输入:--port 9999
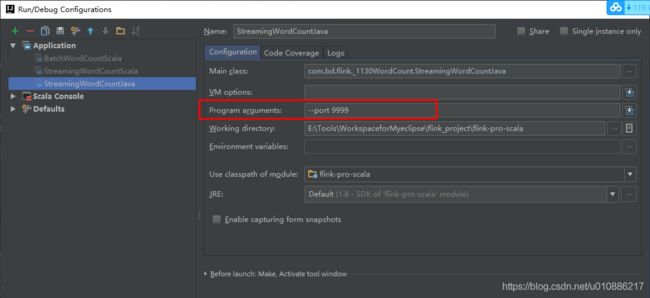
(4)运行程序,同时输入
[root@hadoop ~]# nc -lk 9999
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ssIdea中,结果输出
(aa,7)
(cd,7)
(bb,7)
(we,7)
(dfe,7)
(fd,7)
(ss,7)
2.Scala
(1)代码
package com.bd.flink._1130WordCount
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* Created by Administrator on 2019/11/30.
* 流处理:scala
*/
object StreamingWordCountScala {
def main(args: Array[String]): Unit = {
//第一步:创建开发环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//第二步:读取数据
val text=env.socketTextStream("hadoop01",9999)
//第三步:开发业务逻辑(transform operations)
import org.apache.flink.api.scala._
text.flatMap(_.split(" "))
.map((_,1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.print()
.setParallelism(1)
//第四步:执行程序(execute program),Streaming 需要执行
env.execute("Flink Streaming WordCount")
}
}(2)开启服务器对应端口9999
[root@hadoop ~]# nc -lk 9999(3)运行程序,同时输入
[root@hadoop ~]# nc -lk 9999
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss
aa bb cd we fd dfe ss客户端结果输出
(aa,7)
(cd,7)
(bb,7)
(we,7)
(dfe,7)
(fd,7)
(ss,7)