1、数据清洗、整合 要求: ① 将“data01”、“data02”分别读取,并且合并成一个数据 ② 结合“户籍地城市编号”及“中国城市代码对照表”数据,将城市经纬度连接进数据中 ③ 分别提取“工作地”中的省、市 提示: ① 可以先读取“data01”、“data02”,然后用pd.concat()来连接数据 ② 新建字段“工作地-省”,“工作地-市”,“工作地-区县”,如果数据中“工作地”字段无法提取省和市,则用“未识别”填充单元格 * 通过查看识别后的单元格,如果字数超过5则为“未识别”
import numpy as np import pandas as pd import matplotlib.pyplot as plt from bokeh.plotting import figure, show, output_file from bokeh.models import ColumnDataSource import warnings warnings.filterwarnings('ignore') ''' (1)数据加载及合并 ''' import os os.chdir('C:\\Users\\Administrator\\Desktop\\python数据分析\\项目\\09姓氏') df01 = pd.read_csv('data01.csv', encoding = 'utf-8') df02 = pd.read_csv('data02.csv', encoding = 'utf-8') df_city = pd.read_excel('中国行政代码对照表.xlsx', sheetname = 0) #读取数据 df = pd.concat([df01, df02]) df = pd.merge(df,df_city, left_on = '户籍地城市编号', right_on = "行政编码") df['工作地'] = df['工作地'].str[:15] del df['户籍地城市编号'] del df['行政编码'] ''' (2)提取工作地的省市区县 ''' df['工作地_省'] = df['工作地'].str.split('省').str[0] #提取省 df['工作地_市'] = df['工作地'].str.split('省').str[1].str.split('市').str[0] df['工作地_市'][df['工作地_省'].str.len() > 5] = df['工作地_省'].str.split('市').str[0] #提取市 df['工作地_区县']= '' df['工作地_区县'][(df['工作地_市'].str.len() < 5)&(df['工作地'].str.contains('区'))] = df['工作地'].str.split('市').str[1].str.split('区').str[0] + '区' df['工作地_区县'][(df['工作地_市'].str.len() > 5)&(df['工作地'].str.contains('区'))] = df['工作地'].str.split('区').str[0] + '区' df['工作地_区县'][(df['工作地_市'].str.len() < 5)&(df['工作地'].str.contains('县'))] = df['工作地'].str.split('市').str[1].str.split('县').str[0] + '县' df['工作地_区县'][(df['工作地_市'].str.len() > 5)&(df['工作地'].str.contains('县'))] = df['工作地'].str.split('县').str[0] + '县' #识别区县 df['工作地_省'][df['工作地_省'].str.len() > 5] = '未识别' df['工作地_市'][df['工作地_市'].str.len() > 5] = '未识别' df['工作地_区县'][(df['工作地_区县'].str.len() > 5) | (df['工作地_区县'].str.len() < 2)] = '未识别' #整理未识别单元格 df.columns = ['姓', '工作地', '户籍所在地_省', '户籍所在地_市','户籍所在地_区县', '户籍所在地_lng', '户籍所在地_lat', '工作地_省','工作地_市','工作地_区县' ]
import numpy as np import pandas as pd import matplotlib.pyplot as plt from bokeh.plotting import figure, show, output_file from bokeh.models import ColumnDataSource import warnings warnings.filterwarnings('ignore') ''' (1)数据统计,找到姓氏TOP20 ''' name_count = df['姓'].value_counts()[:20] result1_01 = pd.DataFrame({'count': name_count, 'count_pre': name_count/name_count.sum()}) #筛选数据并统计 ''' (2)bokeh做联动柱状图 ''' from bokeh.models import HoverTool from bokeh.layouts import gridplot name_list = result1_01.index.tolist() source = ColumnDataSource(result1_01) #创建数据 output_file('project09_01.html') hover1 = HoverTool(tooltips = [('姓氏计数', "@count")]) result1 = figure(plot_width = 800, plot_height = 250, x_range = name_list, title = '中国姓氏TOP20 - 计数', tools = [hover1, 'reset, xwheel_zoom, pan']) result1.vbar(x = 'index', top = 'count', source = source, width = 0.9, alpha = 0.7, color = 'red') result1.ygrid.grid_line_dash = [6, 4] result1.xgrid.grid_line_dash = [6, 4] #柱状图1 hover2 = HoverTool(tooltips = [('姓氏占比', "@count_pre")]) result2 = figure(plot_width = 800, plot_height = 250, x_range = result1.x_range, title = '中国姓氏TOP20 - 占比', tools = [hover2, 'reset, xwheel_zoom, pan']) result2.vbar(x = 'index', top = 'count_pre', source = source, width = 0.9, alpha = 0.7, color = 'green') result1.ygrid.grid_line_dash = [6, 4] result1.xgrid.grid_line_dash = [6, 4] #柱状图1 p = gridplot([result1], [result2]) show(p) print('finish')
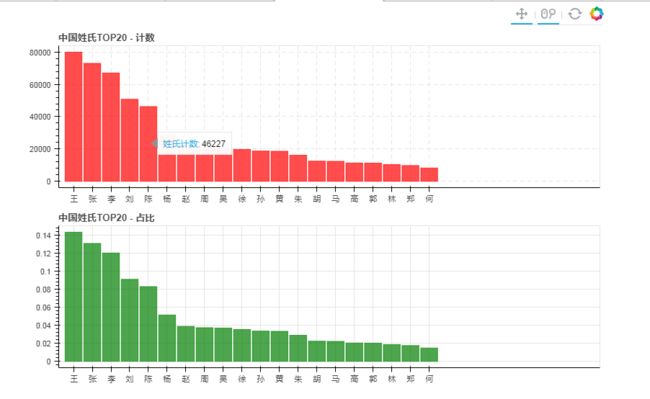
''' (3)查看“王”姓氏分布 ''' data_wang1 = df[df['姓'] == '王'] writer = pd.ExcelWriter('C:\\Users\\Administrator\\Desktop\\python数据分析\\项目\\09姓氏\\wangb1.xlsx') data_wang1.to_excel(writer, 'sheet1', index = False) writer.save() #导出数据1
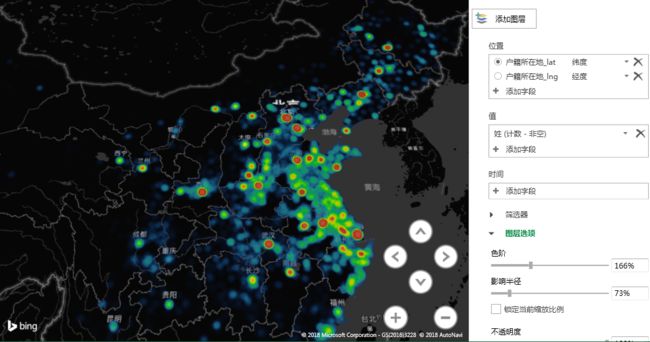
data_wang2 = data_wang1.groupby([ '户籍所在地_lng', '户籍所在地_lat', '户籍所在地_市'],)['姓'].count() data_wang2 = data_wang2.reset_index() data_wang2.columns = ['lng', 'lat', 'name', 'value'] writer = pd.ExcelWriter('C:\\Users\\Administrator\\Desktop\\python数据分析\\项目\\09姓氏\\wangb2.xlsx') data_wang2.to_excel(writer, 'sheet1', index = False) writer.save() #导出数据2
然后把数据data.xlsx替换下
import pandas as pd import os os.chdir(r'C:\Users\Administrator\Desktop\python数据分析\项目\09姓氏\data02_3D_Bar_Map') # 输入文件所在路径,例如:'C:/Users/Desktop/' data = pd.read_excel('data.xlsx', sheetname=0,header=0) datajs = data.to_json(orient='records',force_ascii=False) print('转换后数据为:\n',datajs) #转换为json数据
在百度地图拾取中心点坐标(以武汉为点),在settings.py里边设置下
http://loo2k.com/getpoint/
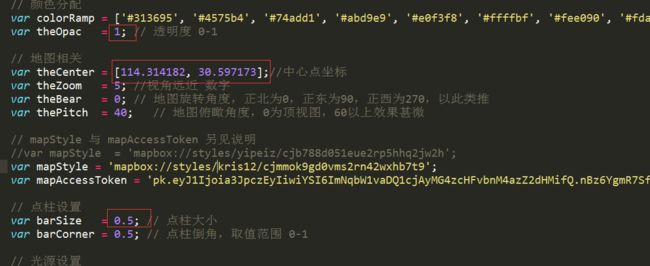
HTML页面展示


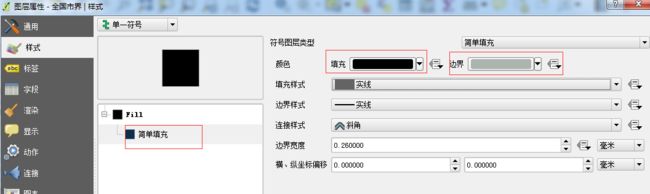

另存为start.shap
终点文件---->>>
跟上边一样,加载end.shap
使用LinePlotter插件

另存为:转换为48N的坐标系经纬度带,它是中心
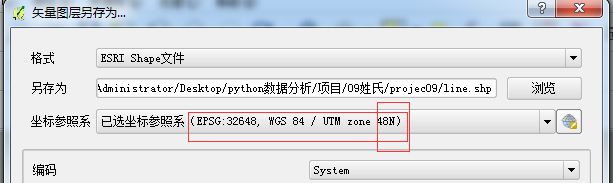
把项目属性的坐标也改成48N的

添加长度length字段:

给length字段加个渐进的样式

最终得到图

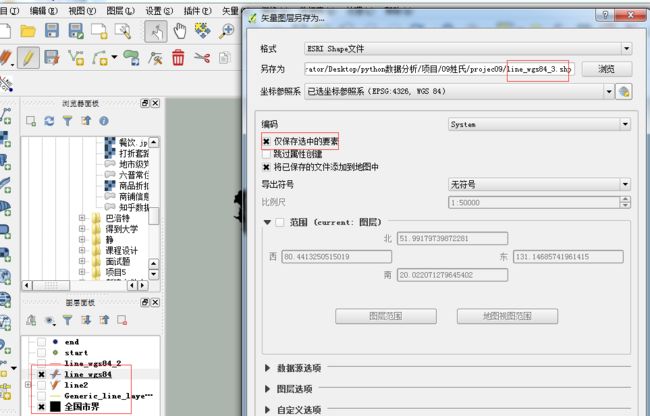
把line2转为地理坐标系WGS84
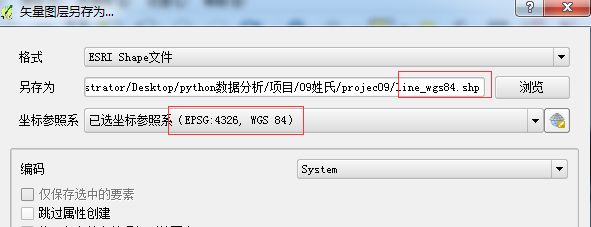
与此同时属性表里边应该有个value字段,它的计数;count字段是个字符串的格式,要把它转成一个整数;
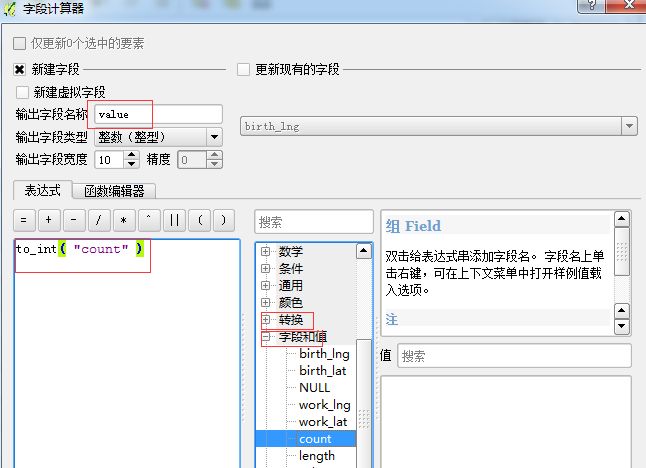
记得要把空值null给去掉了

再进行反选

再给它转换为json格式文件
这样子试了它还是有空值;
有时候它会识别不了,仅保存选中要素,刚刚做了反选。
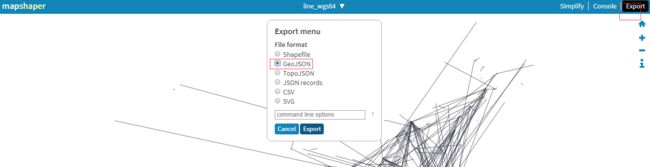
然后使用 http://mapshaper.org/ 把它转换导出json文件

导出json文件
把data文件换成-->>转换好的json文件;再在settings里边调节线的宽度和尾迹的宽度。
