Kettle构建Hadoop ETL实践(三):Kettle对Hadoop的支持
目录
一、Hadoop相关的步骤与作业项
二、连接Hadoop
1. 连接Hadoop集群
(1)开始前准备
(2)配置步骤
2. 连接Hive
3. 连接Impala
4. 建立MySQL数据库连接
三、导入导出Hadoop集群数据
1. 向HDFS导入数据
2. 向Hive导入数据
3. 从HDFS抽取数据到MySQL
4. 从Hive抽取数据到MySQL
四、执行HiveQL语句
五、执行MapReduce
1. 生成聚合数据集
(1)准备文件与目录
(2)建立一个用于Mapper的转换
(4)建立一个调用MapReduce步骤的作业
(5)执行作业并验证输出
2. 格式化原始web日志
(1)准备文件与目录
(2)建立一个用于Mapper的转换
(3)建立一个调用MapReduce步骤的作业
(4)执行作业并验证输出
六、提交Spark作业
1. 在Kettle主机上安装Spark客户端
2. 为Kettle配置Spark
(1)备份原始配置文件
(2)编辑spark-defaults.conf文件
(3)编辑spark-env.sh文件
(4)编辑core-site.xml文件
3. 提交Spark作业
(1)修改Kettle自带的Spark例子
(2)保存行执行作业
七、小结
本篇演示使用Kettle操作Hadoop上的数据。首先概要介绍Kettle对大数据的支持,然后用示例说明Kettle如何连接Hadoop,如何导入导出Hadoop集群上的数据,如何用Kettle执行Hive的HiveQL语句,还会用一个典型的MapReduce转换,说明Kettle在实际应用中是怎样利用Hadoop分布式计算框架的。本篇最后介绍如何在Kettle中提交Spark作业。
一、Hadoop相关的步骤与作业项
在“ETL与Kettle”(https://wxy0327.blog.csdn.net/article/details/107985148)的小结中曾提到,Kettle具有完备的转换步骤与作业项,使它能够支持几乎所有常见数据源。同样Kettle对大数据也提供了强大的支持,这体现在转换步骤与作业项的“Big Data”分类中。本例使用的Kettle 8.3版本中所包含的大数据相关步骤有19个,作业项有10个。表3-1和表3-2分别对这些步骤和作业项进行了简单描述。
| 步骤名称 |
描述 |
| Avro input |
读取Avro格式文件 |
| Avro output |
写入Avro格式文件 |
| Cassandra input |
从一个Cassandra column family中读取数据 |
| Cassandra output |
向一个Cassandra column family中写入数据 |
| CouchDB input |
获取CouchDB数据库一个设计文档中给定视图所包含的所有文档 |
| HBase input |
从HBase column family中读取数据 |
| HBase output |
向HBase column family中写入数据 |
| HBase row decoder |
对HBase的键/值对进行编码 |
| Hadoop file input |
读取存储在Hadoop集群中的文本型文件 |
| Hadoop file output |
向存储在Hadoop集群中的文本型文件中写数据 |
| MapReduce input |
向MapReduce输入键值对 |
| MapReduce output |
从MapReduce输出键值对 |
| MongoDB input |
读取MongoDB中一个指定数据库集合的所有记录 |
| MongoDB output |
将数据写入MongoDB的集合中 |
| ORC input |
读取ORC格式文件 |
| ORC output |
写入ORC格式文件 |
| Parquet input |
读取Parquet格式文件 |
| Parquet output |
写入Parquet格式文件 |
| SSTable output |
作为Cassandra SSTable写入一个文件系统目录 |
表3-1 Kettle转换中的大数据相关步骤
| 作业项名称 |
描述 |
| Amazon EMR job executor |
在Amazon EMR中执行MapReduce作业 |
| Amazon Hive job executor |
在Amazon EMR中执行Hive作业 |
| Hadoop copy files |
将本地文件上传到HDFS,或者在HDFS上复制文件 |
| Hadoop job executor |
在Hadoop节点上执行包含在JAR文件中的MapReduce作业 |
| Oozie job executor |
执行Oozie工作流 |
| Pentaho MapReduce |
在Hadoop中执行基于MapReduce的转换 |
| Pig script executor |
在Hadoop集群上执行Pig脚本 |
| Spark submit |
提交Spark作业 |
| Sqoop export |
使用Sqoop将HDFS上的数据导出到一个关系数据库中 |
| Sqoop import |
使用Sqoop将一个关系数据库中的数据导入到HDFS上 |
表3-2 Kettle作业中的大数据相关作业项
Kettle的设计很独特,它既可以在Hadoop集群外部执行,也可以在Hadoop集群内的节点上执行。在外部执行时,Kettle能够从HDFS、Hive和HBase抽取数据,或者向它们中装载数据。在Hadoop集群内部执行时,Kettle转换可以作为Mapper或Reducer任务执行,并允许将Pentaho MapReduce作业项作为MapReduce的可视化编程工具来使用。后面我们会用示例演示这些功能。关于Hadoop及其组件的基本概念和功能特性不是本专题所讨论的范畴,可参考其它资源。
二、连接Hadoop
Kettle可以与Hadoop协同工作。通过提交适当的参数,Kettle可以连接Hadoop的HDFS、MapReduce、Zookeeper、Oozie、Sqoop和Spark服务。在数据库连接类型中支持Hive和Impala。在本示例中配置Kettle连接HDFS、Hive和Impala。为了给本专题后面实践中创建的转换或作业使用,我们还将定义一个普通的mysql数据库连接对象。
1. 连接Hadoop集群
要使Kettle连接Hadoop集群,需要两个操作:设置一个Active Shim;建立并测试连接。Shim是Pentaho开发的插件,功能有点类似于一个适配器,帮助用户连接Hadoop。Pentaho定期发布Shim,可以从sourceforge网站下载与Kettle版本对应的Shim安装包。使用Shim能够连接不同的Hadoop发行版本,如CDH、HDP、MapR、Amazon EMR等。当在Kettle中执行一个大数据的转换或作业时,缺省会使用设置的Active Shim。初始安装Kettle时,并没有Active Shim,因此在尝试连接Hadoop集群前,首先要做的就是选择一个Active Shim,选择的同时也就激活了此Active Shim。设置好Active Shim后,再经过一定的配置,就可以测试连接了。Kettle内建的工具可以为完成这些工作提供帮助。
(1)开始前准备
在配置连接前,要确认Kettle具有访问HDFS相关目录的权限,访问的目录通常包括用户主目录以及工作需要的其它目录。Hadoop管理员应该已经配置了允许Kettle所在主机对Hadoop集群的访问。除权限外,还需要确认以下信息:
- Hadoop集群的发行版本。Kettle与Hadoop版本要匹配,本例使用的Kettle 8.3所对应的大数据支持矩阵详见“https://help.pentaho.com/Documentation/8.3/Setup/Components_Reference”。
- HDFS、MapReduce或Zookeeper服务的IP地址和端口号。
- 如果要使用Oozie,需要知道Oozie服务的URL。
本例中已经安装好4个节点的CDH 6.3.1集群,IP地址及主机名如下:
172.16.1.124 manager
172.16.1.125 node1
172.16.1.126 node2
172.16.1.127 node3
启动的Hadoop服务如图3-1所示,所有服务都使用缺省端口。关于CDH集群的安装与卸载,可以参见我的博客“基于Hadoop生态圈的数据仓库实践 —— 环境搭建(二)”和“一键式完全删除CDH 6.3.1”。
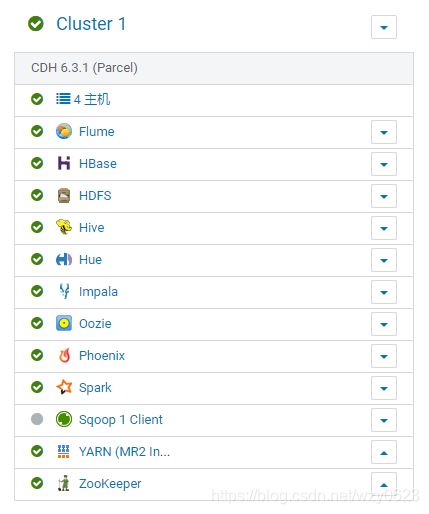 图3-1 Hadoop集群服务
图3-1 Hadoop集群服务
为了用主机名访问Hadoop相关服务,在Kettle主机(172.16.1.101)的/etc/hosts文件中添加了Hadoop集群四个节点的IP与主机名。
(2)配置步骤
1. 在Kettle中配置Hadoop客户端文件
在浏览器中登录Cloudera Manager,选择Hive服务,点击“操作”->“下载客户端配置”。在得到的hive-clientconfig.zip压缩包中包括了当前Hadoop客户端的12个配置文件。将其中的core-site.xml、hdfs-site.xml、hive-site.xml、yarn-site.xml、mapred-site.xml 5个文件复制到Kettle根目录下的plugins/pentaho-big-data-plugin/hadoop-configurations/cdh61/目录下,覆盖原来Kettle自带的这些文件。
2. 选择Active Shim
在Spoon界面中,选择主菜单“工具” -> “Hadoop Distribution...”,在对话框中选择“Cloudera CDH 6.1.0”,如图3-2所示,点击OK按钮确定后重启Spoon。
 图3-2 选择Active Shim
图3-2 选择Active Shim
3. 在Spoon中创建Hadoop clusters对象
新建一个转换,在工作区左侧的树的“主对象树”标签中,选择 Hadoop clusters -> 右键New Cluster,对话框中输入如图3-3所示的属性值。
 图3-3 Hadoop集群连接配置
图3-3 Hadoop集群连接配置
上图的Hadoop集群配置窗口中的选项及定义说明如下:
- Cluster Name:定义要连接的集群名称,这里为CDH631。
- Hostname(HDFS段):Hadoop集群中NameNode节点的主机名。由于本例中的CDH配置了HDFS HA,这里用HDFS NameNode服务名替代了主机名。
- Port(HDFS段):Hadoop集群中NameNode节点的端口号,HA不需要填写。
- Username(HDFS段):HDFS的用户名,通过宿主操作系统给出,不用填。
- Password(HDFS段):HDFS的密码,通过宿主操作系统给出,不用填。
- Hostname(JobTracker段):Hadoop集群中JobTracker节点的主机名。如果有独立的JobTracker节点,在此输入,否则使用HDFS的主机名。
- Port(JobTracker段):Hadoop集群中JobTracker节点的端口号,不能与HDFS的端口号相同。
- Hostname(ZooKeeper段):Hadoop集群中Zookeeper节点的主机名,只有在连接Zookeeper服务时才需要。
- Port(ZooKeeper段):Hadoop集群中Zookeeper节点的端口号,只有在连接Zookeeper服务时才需要。
- URL(Oozie段):Oozie WebUI的地址,只有在连接Oozie服务时才需要。
这是本例CDH的配置,你应该按自己的情况进行相应修改。然后点击“Test”按钮,测试结果如图3-4所示。正常情况下此时除了一个Kafka连接失败的警告外,其它都应该通过测试。Kafka连接失败,原因是没有配置Kafka的Bootstrap servers。我们在CDH中并没有启动Kafka服务,因此忽略此警告。
 图3-4 测试通过
图3-4 测试通过
关闭“Hadoop Cluster Test”窗口后,点击“Hadoop cluster”窗口的“确定”按钮,至此就建立了一个Kettle可以连接的Hadoop集群。
如果是首次配置Kettle连接Hadoop,难免会出现这样那样的问题,Pentaho文档中列出了配置过程中的常见问题及其通用解决方法,如表3-3所示。希望这能对Kettle或Hadoop新手有所帮助。
| 症状 |
通常原因 |
通用解决方法 |
| Shim和配置问题 |
||
| No shim |
|
|
| Shim doesn't load |
|
|
| The file system's URL does not match the URL in the configuration file |
*-site.xml文件配置错误 |
参考Pentaho “Set Up Pentaho to Connect to an Apache Hadoop Cluster”文档,检查配置文件,主要是core-site.xml文件是否配置正确。 |
| Sqoop Unsupported major.minor version Error |
在pentaho6.0中,Hadoop集群上的Java版本比Pentaho使用的Java版本旧。 |
|
| 连接问题 |
||
| Hostname does not resolve |
|
|
| Port name is incorrect |
|
|
| Can't connect |
|
|
| 目录访问或权限问题 |
||
| Can't access directory |
|
|
| Can't create, read, update, or delete files or directories |
认证或权限问题。 |
|
| Test file cannot be overwritten |
Pentaho测试文件已在目录中。 |
测试已运行,但未删除测试文件。需要手动删除测试文件。检查Kettle根目录下logs目录下的spoon.log文件中记录的测试文件名。测试文件用于验证用户可以在其主目录中创建、写入和删除。 |
表3-3 Kettle连接Hadoop时的常见问题
2. 连接Hive
Kettle把Hive当作一个数据库,支持连接Hive Server和Hive Server 2/3,数据库连接类型的名字分别为Hadoop Hive和Hadoop Hive 2/3。这里演示在Kettle中建立一个Hadoop Hive 2/3类型的数据库连接。
Hive Server有两个明显的问题,一是不够稳定,经常会莫名奇妙假死,导致客户端所有的连接都被挂起。二是并发性支持不好,如果一个用户在连接中设置了一些环境变量,绑定到一个Thrift工作线程,当该用户断开连接,另一个用户创建了一个连接,他有可能也被分配到之前的线程,复用之前的配置。这是因为Thrift不支持检测客户端是否断开连接,也就无法清除会话的状态信息。Hive Server 2的稳定性更高,并且已经完美支持了会话。从长远来看都会以Hive Server 2作为首选。
在工作区左侧的“主对象树”标签中,选择 “DB连接” -> 右键“新建”,对话框中输入如图3-5所示的属性值。
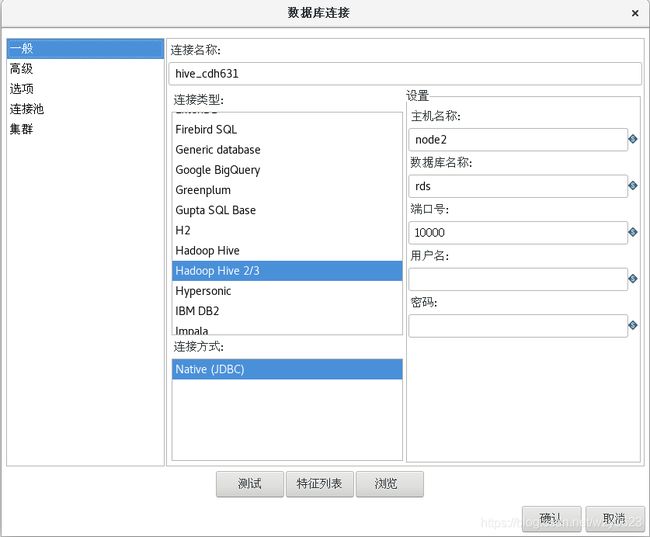 图3-5 Hive连接配置
图3-5 Hive连接配置
上图的数据库连接配置窗口中的选项及定义说明如下:
- Connection Name:定义连接名称,这里为hive_cdh631。
- Connection Type:连接类型选择Hadoop Hive 2/3。
- Host Name:输入HiveServer2对应的主机名。在Cloudera Manager中,从Hive服务的“实例”标签中可以找到。
- Datebase Name:这里输入的rds是Hive里已经存在的一个数据库名称。
- Port Number:端口号输入hive.server2.thrift.port参数的值。
- User Name:用户名,这里为空。
- Password:密码,这里为空。
点击“测试”,应该弹出成功连接窗口,显示内容如下:
正确连接到数据库[hive_cdh631]
主机名 : node2
端口 : 10000
数据库名 :rds为了让其它转换或作业能够使用此数据库连接对象,需要将它设置为共享。选择 “DB连接” -> hive_cdh631 -> 右键“共享”,然后保存转换。
3. 连接Impala
Impala是一个运行在Hadoop之上的大规模并行处理(Massively Parallel Processing,MPP)查询引擎,提供对Hadoop集群数据的高性能、低延迟的SQL查询,使用HDFS作为底层存储。对查询的快速响应使交互式查询和对分析查询的调优成为可能,而这些在针对处理长时间批处理作业的SQL-on-Hadoop传统技术上是难以完成的。Impala是Cloudera公司基于Google Dremel的开源实现。Cloudera公司宣称除Impala外的其它组件都将移植到Spark框架,并坚信Impala是大数据上SQL解决方案的未来,可见其对Impala的重视程度。
通过将Impala与Hive元数据存储数据库相结合,能够在Impala与Hive这两个组件之间共享数据库表。并且Impala与HiveQL的语法兼容,因此既可以使用Impala也可以使用Hive进行建立表、发布查询、装载数据等操作。Impala可以在已经存在的Hive表上执行交互式实时查询。
创建Impala连接的过程与Hive类似。在工作区左侧的“主对象树”标签中,选择“DB连接” -> 右键“新建”,对话框中输入如图3-6所示的属性值。
 图3-6 Impala连接配置
图3-6 Impala连接配置
上图的数据库连接配置窗口中的选项及定义说明如下:
- Connection Name:定义连接名称,这里为impala_cdh631。
- Connection Type:连接类型选择Impala。
- Host Name:输入任一Impala Daemon对应的主机名。在Cloudera Manager中,从Impala服务的“实例”标签中可以找到。
- Datebase Name:这里输入的rds是Hive里已经存在的一个数据库名称。
- Port Number:端口号输入Impala Daemon HiveServer2端口参数的值。
- User Name:用户名,这里为空。
- Password:密码,这里为空。
点击“测试”,应该弹出成功连接窗口,显示内容如下:
正确连接到数据库[impala_cdh631]
主机名 : node3
端口 : 21050
数据库名 :rds同hive_cdh631一样,将impala_cdh631数据库连接共享,然后保存转换。
4. 建立MySQL数据库连接
Kettle中创建数据库连接的方法都类似,区别只是在“连接类型”中选择不同的数据库,然后输入相关的属性,“连接方式”通常选择Native(JDBC)。例如MySQL连接配置如图3-7所示。
 图3-7 MySQL连接配置
图3-7 MySQL连接配置
这里的连接名称为mysql_node3。配置MySQL数据库连接需要注意的一点是,需要事先将对应版本的MySQL JDBC驱动程序拷贝到Kettle根目录的lib目录下,否则在测试连接时可能出现如下错误:
org.pentaho.di.core.exception.KettleDatabaseException:
Error occurred while trying to connect to the database
Driver class 'org.gjt.mm.mysql.Driver' could not be found, make sure the 'MySQL' driver (jar file) is installed.
org.gjt.mm.mysql.Driver本例中连接的MySQL服务器版本为5.6.14,因此使用下面的命令拷贝JDBC驱动,然后重启Spoon以重新加载所有驱动。
cp mysql-connector-java-5.1.38-bin.jar /root/pdi-ce-8.3.0.0-371/lib/至此成功创建了一个Hadoop集群对象CDH631,,以及三个数据库连接对象hive_cdh631、impala_cdh631和mysql_node3。
三、导入导出Hadoop集群数据
本节用四个示例演示如何使用Kettle导出导入Hadoop数据。这四个示例是:向HDFS导入数据;向Hive导入数据;从HDFS抽取数据到MySQL;从Hive抽取数据到MySQL。
1. 向HDFS导入数据
用Kettle将本地文件导入HDFS非常简单,只需要一个“Hadoop copy files”作业项就可以实现。它执行的效果同 hdfs dfs -put 命令是相同的。从下面的地址下载Pentaho提供的web日志示例文件,将解压缩后的weblogs_rebuild.txt文件放到Kettle所在主机的本地目录下。
http://wiki.pentaho.com/download/attachments/23530622/weblogs_rebuild.txt.zip?version=1&modificationDate=1327069200000
在Spoon中新建一个只包含“Start”和“Hadoop copy files”两个作业项的作业,如图3-8所示。
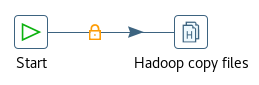 图3-8 向HDFS导入数据的作业
图3-8 向HDFS导入数据的作业
双击“Hadoop Copy Files”作业项,编辑属性如下:
- Source Environment:选择“Local”。
- 源文件/目录:选择本地文件,本例为“file:///root/kettle_hadoop/3/weblogs_rebuild.txt”
- 通配符:空。
- Destination Environment:选择“CDH631”,这是我们之前已经建立好的Hadoop Clusters对象。
- Destination File/Folder:选择HDFS上的目录,本例为/user/root。
保存并成功执行作业后,查看HDFS目录,结果如下。可以看到,weblogs_rebuild.txt文件已从本地导入HDFS的/user/root目录中。每次执行作业会覆盖HDFS中已存在的同名文件。
[hdfs@manager~]$hdfs dfs -ls /user/root
Found 1 items
-rw-r--r-- 3 root supergroup 77908174 2020-08-28 08:53 /user/root/weblogs_rebuild.txt
[hdfs@manager~]$2. 向Hive导入数据
Hive缺省是不能进行行级插入的,也就是说缺省时不能使用insert into ... values这种SQL语句向Hive插入数据。通常Hive表数据导入方式有以下两种:
- 从本地文件系统中导入数据到Hive表,使用的语句是:
load data local inpath 目录或文件 into table 表名; - 从HDFS上导入数据到Hive表,使用的语句是:
load data inpath 目录或文件 into table 表名;
再有数据一旦导入Hive表,缺省是不能进行更新和删除的,只能向表中追加数据或者用新数据整体覆盖原来的数据。要删除表数据只能执行truncate或者drop table操作,这实际上是删除了表所对应的HDFS上的数据文件或目录。
Kettle作业中的“Hadoop Copy Files”作业项可以将本地文件上传至HDFS,因此只要将前面的作业稍加修改,将Destination File/Folder选择为hive表所在的HDFS目录即可,作业执行的效果与load data local inpath语句相同。
首先从下面的地址下载Pentaho提供的格式化后的web日志示例文件,将解压缩后的weblogs_parse.txt文件放到Kettle所在主机的本地目录下。
http://wiki.pentaho.com/download/attachments/23530622/weblogs_parse.txt.zip?version=1&modificationDate=1327068013000
然后执行下面的HiveQL建立一个Hive表,表结构与weblogs_parse.txt文件的结构相匹配。
create table test.weblogs (
client_ip string,
full_request_date string,
day string,
month string,
month_num int,
year string,
hour string,
minute string,
second string,
timezone string,
http_verb string,
uri string,
http_status_code string,
bytes_returned string,
referrer string,
user_agent string)
row format delimited fields terminated by '\t';创建和前例相同的作业,只是修改以下两个作业项属性:
- 源文件/目录:file:///root/kettle_hadoop/3/weblogs_parse.txt
- Destination File/Folder:/user/hive/warehouse/test.db/weblogs
保存并成功执行作业后,查询test.weblogs表的记录与weblogs_parse.txt文件内容相同。
3. 从HDFS抽取数据到MySQL
从下面的地址下载文件
http://wiki.pentaho.com/download/attachments/23530622/weblogs_aggregate.txt.zip?version=1&modificationDate=1327067858000
这是Pentaho提供的一个压缩文件,其中包含一个名为weblogs_aggregate.txt的文本文件,文件中有36616行记录,每行记录有4列,分别表示IP地址、年份、月份、访问页面数,前5行记录如下。我们使用这个文件作为最初的原始数据。
0.308.86.81 2012 07 1
0.32.48.676 2012 01 3
0.32.85.668 2012 07 8
0.45.305.7 2012 01 1
0.45.305.7 2012 02 1用下面的命令把解压缩后的weblogs_aggregate.txt文件上传到HDFS的/user/root目录下。
hdfs dfs -put weblogs_aggregate.txt /user/root/在Spoon中新建一个如图3-9的转换。转换中只包含“Hadoop File Input”和“表输出” 两个步骤。
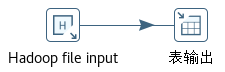 图3-9 从HDFS抽取数据到MySQL的转换
图3-9 从HDFS抽取数据到MySQL的转换
编辑“Hadoop File Input”步骤属性如下:
(1)“文件”标签
- Environment:选择“CDH631”。
- File/Folder:选择“/user/root/weblogs_aggregate.txt”
(2)“内容”标签
- 文件类型:CVS
- 分隔符:删除分号,点击“Insert TAB”按钮插入TAB分隔符。
- 头部:勾掉。
- 格式:选择“Unix”。
- 本地日期格式:选择“en_US”
(3)“字段”标签
输入如表3-4所示。
| 名称 |
类型 |
格式 |
长度 |
去除空字符串方式 |
重复 |
| client_ip |
String |
|
20 |
不去掉空格 |
否 |
| year |
Integer |
# |
15 |
不去掉空格 |
否 |
| month_num |
Integer |
# |
15 |
不去掉空格 |
否 |
| pageviews |
Integer |
# |
15 |
不去掉空格 |
否 |
表3-4 weblogs_aggregate.txt对应的字段
编辑“表输出”步骤属性如下:
- 数据库连接:选择“mysql_node3”。
- 目标表:输入“aggregate_hdfs”。
- 剪裁表:勾选。
mysql_node3是连接Hadoop时已经建好的一个MySQL数据库连接。“主选项”和“数据库字段”标签下的属性都不需要设置,“表字段”和“流字段”会自动映射。
下面执行SQL建立mysql的表:
use test;
create table aggregate_hdfs (
client_ip varchar(15),
year smallint,
month_num tinyint,
pageviews bigint
);保存并执行转换,然后查询aggregate_hdfs表,结果如下:
mysql> select count(*) from test.aggregate_hdfs;
+----------+
| count(*) |
+----------+
| 36616 |
+----------+
1 row in set (0.03 sec)
mysql> select * from test.aggregate_hdfs limit 5;
+-------------+------+-----------+-----------+
| client_ip | year | month_num | pageviews |
+-------------+------+-----------+-----------+
| 0.308.86.81 | 2012 | 7 | 1 |
| 0.32.48.676 | 2012 | 1 | 3 |
| 0.32.85.668 | 2012 | 7 | 8 |
| 0.45.305.7 | 2012 | 1 | 1 |
| 0.45.305.7 | 2012 | 2 | 1 |
+-------------+------+-----------+-----------+
5 rows in set (0.00 sec)4. 从Hive抽取数据到MySQL
在Spoon中新建一个如图3-10的转换。转换中只包含“表输入”和“表输出” 两个步骤。
 图3-10 从Hive抽取数据到MySQL的转换
图3-10 从Hive抽取数据到MySQL的转换
编辑“表输入”步骤属性如下:
- 数据库连接:选择“hive_cdh631”。
- SQL:输入下面的SQL语句:
select client_ip, year, month, month_num, count(*) as pageviews from test.weblogs group by client_ip, year, month, month_num
hive_cdh631是连接Hadoop时已经建好的一个Hive数据库连接。
编辑“表输出”步骤属性如下:
- 数据库连接:选择“mysql_node3”。
- 目标表:输入“aggregate_hive”。
- 剪裁表:勾选。
下面执行SQL建立mysql的表:
use test;
create table aggregate_hive (
client_ip varchar(15),
year varchar(4),
month varchar(10),
month_num tinyint,
pageviews bigint
);保存并执行转换,然后查询aggregate_hive表,结果如下:
mysql> select count(*) from test.aggregate_hive;
+----------+
| count(*) |
+----------+
| 36616 |
+----------+
1 row in set (0.03 sec)
mysql> select * from test.aggregate_hive limit 5;
+---------------+------+-------+-----------+-----------+
| client_ip | year | month | month_num | pageviews |
+---------------+------+-------+-----------+-----------+
| 0.45.305.7 | 2012 | Feb | 2 | 1 |
| 0.48.322.75 | 2012 | Jul | 7 | 1 |
| 0.638.50.46 | 2011 | Dec | 12 | 8 |
| 01.660.68.623 | 2012 | Jun | 6 | 1 |
| 01.660.70.74 | 2012 | Jul | 7 | 1 |
+---------------+------+-------+-----------+-----------+
5 rows in set (0.00 sec)四、执行HiveQL语句
在这个示例中演示如何用Kettle执行Hive的HiveQL语句。我们在“向Hive导入数据”一节建立的weblogs表上执行聚合查询,同时建立一个新表保存查询结果。新建一个Kettle作业,只有“START”和“SQL”两个作业项,如图3-11所示。
 图3-11 执行Hive HiveQL语句的作业
图3-11 执行Hive HiveQL语句的作业
编辑“SQL”作业项属性如下:
- 数据库连接:选择“hive_cdh631”。
- SQL脚本:
create table test.weblogs_agg as select client_ip, year, month, month_num, count(*) from test.weblogs group by client_ip, year, month, month_num;
保存并成功执行作业后检查hive表,结果如下:
hive> select count(*) from test.weblogs_agg;
...
36616可以看到weblogs_agg表中已经保存了全部的聚合数据。
五、执行MapReduce
1. 生成聚合数据集
“执行HiveQL语句”示例只用一句HiveQL就生成了聚合数据,本示例使用“Pentaho MapReduce”作业项完成相似的功能,把细节数据汇总成聚合数据集。当给一个关系型数据仓库或数据集市准备待抽取的数据时,这是一个常见的使用场景。我们把weblogs_parse.txt文件作为细节数据,目标是生成聚合数据文件,其中包含按IP和年月分组统计的PV数。
(1)准备文件与目录
# 创建格式化文件所在目录
hdfs dfs -mkdir /user/root/parse/
# 上传格式化文件
hdfs dfs -put -f weblogs_parse.txt /user/root/parse/
# 修改读写权限
hdfs dfs -chmod -R 777 /user/root/(2)建立一个用于Mapper的转换
 图3-12 生成聚合数据Mapper转换
图3-12 生成聚合数据Mapper转换
如图3-12所示的转换由“MapReduce Input”、“拆分字段”、“利用Janino计算Java表达式”、“MapReduce Output”四个步骤组成。
编辑“MapReduce Input”步骤如下:
- Key field:“Type”选择“String”,定义 Hadoop MapReduce 键的数据类型。
- Value field:“Type”选择“String”,定义 Hadoop MapReduce 值的数据类型。
该步骤输出两个字段,名称是固定的key和value,也就是Map阶段输入的键值对。
编辑“拆分字段”步骤如下:
- 需要拆分的字段:选择“value”。
- 分隔符:输入“$[09]”,以TAB作为分隔符。
- 字段:新的字段名如下,类型均为String。
client_ip full_request_date day month month_num year hour minute second timezone http_verb uri http_status_code bytes_returned referrer user_agent
该步骤将输入的value字段拆分成16个字段,输出17个字段(key字段没变,文本文件每行的key是文件起始位置到每行的字节偏移量)。
编辑“利用Janino计算Java表达式”步骤如表3-5所示。
| New field |
Java expression |
Value type |
| new_key |
client_ip + '\t' + year + '\t' + month_num |
String |
| new_value |
1 |
Integer |
表3-5 聚合数据转换中的“利用Janino计算Java表达式”步骤
该步骤为数据流中增加两个新的字段,名称分别定义为new_key和new_value。new_key字段的值定义为client_ip + '\t' + year + '\t' + month_num,将IP地址、年份、月份和字段间的两个TAB符拼接成一个字符串。new_value字段的值为1,数据类型是整数。该步骤输出19个字段。
编辑“MapReduce Output”步骤如下:
- Key field:选择“new_key”。
- Value field:选择“new_value”。
该步骤输出“new_key”和“new_value”两个字段,即Map阶段输出的键值对。
将转换保存为aggregate_mapper.ktr。
(3)建立一个用于Reducer的转换
 图3-13 生成聚合数据Reducer转换
图3-13 生成聚合数据Reducer转换
如图3-13所示的转换由“MapReduce Input”、“分组”、“MapReduce Output”三个步骤组成。
编辑“MapReduce Input”步骤如下:
. Key field:“Type”选择“String”。
. Value field:“Type”选择“Integer”。
该步骤输出两个字段,名称是固定的key和value,key对应Mapper转换的new_key输出字段,value对应Mapper转换的new_value输出字段。
编辑“分组”步骤如下:
- 构成分组的字段:选择“key”。
- 聚合:名称、Subject、类型三列的值分别是new_value、value、求和。
该步骤按key字段分组(key字段的值就是client_ip + '\t' + year + '\t' + month_num),对每个分组的value求和,每组的合计值定义为一个新的字段new_value。注意,此处的new_value和Mapper转换输出的new_value字段含义是不同的。Mapper转换输出的new_value字段对应这里的Subject字段值。
编辑“MapReduce Output”步骤如下:
- Key field:选择“key”。
- Value field:选择“new_value”。
输出Reducer处理后的键值对,这就是我们想要的结果。
将转换保存为aggregate_reducer.ktr。
(4)建立一个调用MapReduce步骤的作业
 图3-14 聚合数据Pentaho MapReduce作业
图3-14 聚合数据Pentaho MapReduce作业
如图3-14所示的作业使用mapper和reducer转换。需要编辑Pentaho MapReduce作业项的Mapper、Reducer、job Setup、Cluster四个标签页,每个标签页上的选项及定义。
Mapper标签:
- Transformation:选择第(1)步建立的Mapper转换,这里为“/root/kettle_hadoop/3/aggregate_mapper.ktr”。
- Input step name:输入“MapReduce Input”。这是接收mapping数据的步骤名,必须是一个MapReduce Input步骤的名称。
- Output step name:输入“MapReduce Output”。这是mapping输出步骤名,必须是一个MapReduce Output步骤的名称。
Reducer标签:
- Transformation:选择第(2)步建立的Reducer转换,这里为“/root/kettle_hadoop/3/aggregate_mapper.ktr”。
- Input step name:输入“MapReduce Input”。这是接收reducing数据的步骤名,必须是一个MapReduce Input步骤的名称。
- Output step name:输入“MapReduce Output”。这是reducing输出步骤名,必须是一个MapReduce Output步骤的名称。
Job Setup标签:
- Input path:输入“/user/root/parse/”。一个以逗号分隔的HDFS目录列表,目录中存储的是MapReduce要处理的源数据文件。
- Output path:输入“/user/root/aggregate_mr”。存储MapReduce作业输出数据的HDFS目录。
- Remove output path before job:勾选。执行作业时先删除输出目录。
- Input format:输入“org.apache.hadoop.mapred.TextInputFormat”,为输入格式的类名。
- Output format:输入“org.apache.hadoop.mapred.TextOutputFormat”,为输出格式的类名。
Cluster标签:
- Hadoop job name:输入“aggregate”。
- Hadoop cluster:选择“CDH631”,为一个已经定义的Hadoop集群。
- Number of mapper tasks:1。分配的mapper任务数,由输入的数据量所决定。典型的值在10-100之间。非CPU密集型的任务可以指定更高的值。
- Number of reduce tasks:1。分配的reducer任务数。一般来说,该值设置的越小,reduce操作启动的越快,设置的越大,reduce操作完成的更快。加大该值会增加Hadoop框架的开销,但能够使负载更加均衡。如果设置为0,则不执行reduce操作,mapper的输出将作为整个MapReduce作业的输出。
- Logging interval:60。日志消息间隔的秒数。
- Enable blocking:勾选。如果选中,作业将等待每一个作业项完成后再继续下一个作业项,这是Kettle感知Hadoop作业状态的唯一方式。如果不选,MapReduce作业会自己执行,而Kettle在提交MapReduce作业后立即会执行下一个作业项。除非选中该项,否则Kettle的错误处理在这里将无法工作。
将作业保存为aggregate_mr.kjb。
(5)执行作业并验证输出
[hdfs@node3~]$hdfs dfs -ls /user/root/aggregate_mr/
Found 2 items
-rw-r--r-- 3 root supergroup 0 2020-08-31 13:46 /user/root/aggregate_mr/_SUCCESS
-rw-r--r-- 3 root supergroup 890709 2020-08-31 13:46 /user/root/aggregate_mr/part-00000
[hdfs@node3~]$hdfs dfs -cat /user/root/aggregate_mr/part-00000 | head -10
0.308.86.81 2012 07 1
0.32.48.676 2012 01 3
0.32.85.668 2012 07 8
0.45.305.7 2012 01 1
0.45.305.7 2012 02 1
0.46.386.626 2011 11 1
0.48.322.75 2012 07 1
0.638.50.46 2011 12 8
0.87.36.333 2012 08 7
01.660.68.623 2012 06 1
cat: Unable to write to output stream.
[hdfs@node3~]$可以看到,/user/root/aggregate_mr/目录下生成了名为part-00000输出文件,文件中包含按IP和年月分组的PV数。
2. 格式化原始web日志
本示例说明如何使用Pentaho MapReduce把原始web日志解析成格式化的记录。
(1)准备文件与目录
# 创建原始文件所在目录
hdfs dfs -mkdir /user/root/raw
# 修改读写权限
hdfs dfs -chmod -R 777 /user/root/然后用Hadoop copy files作业项将weblogs_rebuild.txt文件放到HDFS的/user/root/raw目录下,具体操作参见前面“向HDFS导入数据”。
(2)建立一个用于Mapper的转换
 图3-15 格式化文件Mapper转换
图3-15 格式化文件Mapper转换
编辑“MapReduce Input”步骤如下:
- Key field:“Type”选择“String”。
- Value field:“Type”选择“String”。
编辑“正则表达式”步骤如下:
- 要匹配的字段:输入“value”。
- Result field name:输入“is_match”
- 为每个捕获组(capture group)创建一个字段:勾选。
- Replace previous fields:勾选。
- 正则表达式:
^([^\s]{7,15})\s # client_ip -\s # unused IDENT field -\s # unused USER field \[((\d{2})/(\w{3})/(\d{4}) # request date dd/MMM/yyyy :(\d{2}):(\d{2}):(\d{2})\s([-+ ]\d{4}))\] # request time :HH:mm:ss -0800 \s"(GET|POST)\s # HTTP verb ([^\s]*) # HTTP URI \sHTTP/1\.[01]"\s # HTTP version (\d{3})\s # HTTP status code (\d+)\s # bytes returned "([^"]+)"\s # referrer field " # User agent parsing, always quoted. "? # Sometimes if the user spoofs the user_agent, they incorrectly quote it. ( # The UA string [^"]*? # Uninteresting bits (?: (?: rv: # Beginning of the gecko engine version token (?=[^;)]{3,15}[;)]) # ensure version string size ( # Whole gecko version (\d{1,2}) # version_component_major \.(\d{1,2}[^.;)]{0,8}) # version_component_minor (?:\.(\d{1,2}[^.;)]{0,8}))? # version_component_a (?:\.(\d{1,2}[^.;)]{0,8}))? # version_component_b ) [^"]* # More uninteresting bits ) | [^"]* # More uninteresting bits ) ) # End of UA string "? " - 捕获组(Capture Group)字段:如下所示,所有字段都是String类型。
client_ip full_request_date day month year hour minute second timezone http_verb uri http_status_code bytes_returned referrer user_agent firefox_gecko_version firefox_gecko_version_major firefox_gecko_version_minor firefox_gecko_version_a firefox_gecko_version_b
编辑“过滤记录”步骤如下:
- 发送true数据给步骤:选择“值映射”。
- 发送false数据给步骤:选择“空操作(什么也不做)”
- 条件:选择“is_match = Y”
编辑“值映射”步骤如下:
- 使用的字段名:选择“month”。
- 目标字段名(空=覆盖):输入“month_num”。
- 不匹配时的默认值:输入“00”。
- 字段值:源值与目标值输入如下。
Jan 01 Feb 02 Mar 03 Apr 04 May 05 Jun 06 Jul 07 Aug 08 Sep 09 Oct 10 Nov 11 Dec 12
编辑“利用Janino计算Java表达式”步骤如下:
- New field:输入“output_value”。
- Java expression:输入如下。
client_ip + '\t' + full_request_date + '\t' + day + '\t' + month + '\t' + month_num + '\t' + year + '\t' + hour + '\t' + minute + '\t' + second + '\t' + timezone + '\t' + http_verb + '\t' + uri + '\t' + http_status_code + '\t' + bytes_returned + '\t' + referrer + '\t' + user_agent - Value type:选择“String”。
编辑“MapReduce Output”步骤如下:
- Key field:选择“key”。
- Value field:选择“output_value”。
将转换保存为weblog_parse_mapper.ktr。
(3)建立一个调用MapReduce步骤的作业
 图3-16 格式化文件Pentaho MapReduce作业
图3-16 格式化文件Pentaho MapReduce作业
编辑“Pentaho MapReduce”作业项如下。
Mapper标签:
- Transformation:选择上一步建立的转换,这里为“/root/kettle_hadoop/3/weblogs_parse_mapper.ktr”。
- Input step name:输入“MapReduce Input”。
- Output step name:输入“MapReduce Output”。
Job Setup标签:
- Input path:输入“/user/root/raw”。
- Output path:输入“/user/root/parse1”。
- Remove output path before job:勾选。
- Input format:输入“org.apache.hadoop.mapred.TextInputFormat”。
- Output format:输入“org.apache.hadoop.mapred.TextOutputFormat”。
Cluster标签:
- Hadoop job name:输入“Web Log Parse”。
- Hadoop cluster:选择“CDH631”。
- Number of mapper tasks:2
- Number of reduce tasks:0
- Logging interval:60
- Enable blocking:勾选。
将作业保存为weblogs_parse_mr.kjb。
(4)执行作业并验证输出
作业成功执行后检查HDFS的输出文件,结果如下。
[hdfs@node3~]$hdfs dfs -ls /user/root/parse1
Found 3 items
-rw-r--r-- 3 root supergroup 0 2020-08-31 10:59 /user/root/parse1/_SUCCESS
-rw-r--r-- 3 root supergroup 42601640 2020-08-31 10:59 /user/root/parse1/part-00000
-rw-r--r-- 3 root supergroup 42810160 2020-08-31 10:59 /user/root/parse1/part-00001
[hdfs@node3~]$hdfs dfs -get /user/root/parse1/part-00000
[hdfs@node3~]$head -5 part-00000
0 323.81.303.680 25/Oct/2011:01:41:00 -0500 25 Oct 10 2011 01 41 00 -0500 GET /download/download6.zip 200 0 - Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.19) Gecko/2010031422 Firefox/3.0.19
193 668.667.44.3 25/Oct/2011:07:38:30 -0500 25 Oct 10 2011 07 38 30 -0500 GET /download/download3.zip 200 0 - Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070719 CentOS/1.5.0.12-3.el5.centos Firefox/1.5.0.12
405 13.386.648.380 25/Oct/2011:17:06:00 -0500 25 Oct 10 2011 17 06 00 -0500 GET /download/download6.zip 200 0 - Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB6.3; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; InfoPath.2)
651 06.670.03.40 26/Oct/2011:13:24:00 -0500 26 Oct 10 2011 13 24 00 -0500 GET /product/demos/product2 200 0 - Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3
838 18.656.618.46 26/Oct/2011:17:15:30 -0500 26 Oct 10 2011 17 15 30 -0500 GET /download/download4.zip 200 0 - Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_3; en-us) AppleWebKit/531.22.7 (KHTML, like Gecko) Version/4.0.5 Safari/531.22.7
[hdfs@node3~]$可以看到,/user/root/parse1目录下生成了名为part-00000和part-00001的两个输出文件(因为使用了两个mapper),内容已经被格式化。
六、提交Spark作业
Kettle不但支持MapReduce作业,还可以通过“Spark Submit”作业项,向CDH 5.3以上、HDP 2.3以上、Amazon EMR 3.10以上的Hadoop平台提交Spark作业。在本示例中,我们先为Kettle配置Spark,然后修改并执行Kettle安装包中自带的Spark PI作业例子,说明如何在Kettle中提交Spark作业。
1. 在Kettle主机上安装Spark客户端
使用Kettle执行Spark作业,需要在Kettle主机安装Spark客户端。只要将CDH中Spark的库文件复制到Kettle所在主机即可。
-- 在172.16.1.127上执行
cd /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib
scp -r spark 172.16.1.101:/root/2. 为Kettle配置Spark
以下操作均在172.16.1.101以root用户执行。
(1)备份原始配置文件
cd /root/spark/conf/
cp spark-defaults.conf spark-defaults.conf.bak
cp spark-env.sh spark-env.sh.bak(2)编辑spark-defaults.conf文件
vim /root/spark/conf/spark-defaults.conf内容如下:
# 使用spark.yarn.archive减少任务启动时间
spark.yarn.archive=hdfs://nameservice1/user/spark/lib/spark_jars.zip
# 解决和yarn相关Jersey包冲突,避免spark on yarn启动spark-submit时出现java.lang.NoClassDefFoundError错误
spark.hadoop.yarn.timeline-service.enabled=false
# 记录Spark事件,用于应用程序在完成后重构WebUI
spark.eventLog.enabled=true
# 记录Spark事件的目录
spark.eventLog.dir=hdfs://nameservice1/user/spark/applicationHistory
# spark on yarn的history server地址
spark.yarn.historyServer.address=http://node3:18088(3)编辑spark-env.sh文件
vim /root/spark/conf/spark-env.sh内容如下:
#!/usr/bin/env bash
# hadoop配置文件所在目录
HADOOP_CONF_DIR=/root/pdi-ce-8.3.0.0-371/plugins/pentaho-big-data-plugin/hadoop-configurations/cdh61
# spark主目录
SPARK_HOME=/root/spark(4)编辑core-site.xml文件
vim /root/pdi-ce-8.3.0.0-371/plugins/pentaho-big-data-plugin/hadoop-configurations/cdh61/core-site.xml去掉下面这段的注释:
net.topology.script.file.name
/etc/hadoop/conf.cloudera.yarn/topology.py
3. 提交Spark作业
(1)修改Kettle自带的Spark例子
cp /root/pdi-ce-8.3.0.0-371/samples/jobs/Spark\ Submit/Spark\ submit.kjb /root/kettle_hadoop/3/spark_submit.kjb在Spoon中打开/root/kettle_hadoop/spark_submit.kjb文件,如图3-17所示。
 图3-17 Kettle自带的Spark例子
图3-17 Kettle自带的Spark例子
编辑Spark PI作业项如下:
- Spark Submit Utility:选择Spark提交程序,本例为“/root/spark/bin/spark-submit”。
- Master URL:因为yarn运行在CDH集群,而不是Kettle主机上,所以这里选择“yarn-cluster”。
- Files标签的Application Jar:选择“/root/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.3.1.jar”。
(2)保存行执行作业
Spark History Server Web UI如图3-18所示。
 图3-18 Spark UI看到提交的Spark作业
图3-18 Spark UI看到提交的Spark作业
七、小结
本篇以Kettle 8.3和CDH 6.3.1为例,介绍Kettle对Hadoop的支持。通过提交适当的参数,Kettle可以连接Hadoop的HDFS、MapReduce、Zookeeper、Oozie和Spark服务。Kettle的数据库连接类型中支持Hive、Hive 2/3和Impala。可以使用Kettle导出导入Hadoop集群中(HDFS、Hive等)的数据,执行Hive的HiveQL语句。Kettle支持在Hadoop中执行基于MapReduce的Kettle转换,还支持向Spark集群提交作业。这里演示的例子都是Pentaho官方提供示例。从下一篇开始,我们将建立一个模拟的Hadoop数据仓库,并用使用Kettle完成其上的ETL操作。