ElasticSearch自动补全功能之分词器选择
阅读该文档需要对es有一定的了解。
需求:根据输入地址段查询相关地址。
目前系统情况:目前es搜索字段采用ik_max_word分词器进行分词,但是该分词器不会对英文和数字进行分词,导致一种情况:
我的es库里面有类似:武汉市洪山区武大园一路9号武大吉奥4楼408室,但是我使用match_phrase设置了slop(保证输入框内容顺序,并且允许跳字)搜索 武汉市洪山区武大园一路9号武大吉奥4楼4 会无结果返回,因为408没有被分词导致的。
思考:方案1:使用通配符(wildcard )+match,wildcard虽然可以解决数字和英文没被分词的问题,但是输入内容的顺序及跳字最最重要的是相关度不符合要求,而且查询效率较低被放弃。方案2:添加分词器,我们在进行输入框联想自动补全功能时,选用nGram分词器(该分词器解释:https://www.elastic.co/guide/en/elasticsearch/reference/6.4/analysis-ngram-tokenizer.html),对目标字段进行分词。
1、创建测试索引:
{
"_all": {
"enabled": false
},
"settings": {
"analysis": {
"tokenizer": {
"my_ngram": {
"type": "nGram",
"min_gram": "1",
"max_gram": "20",
"token_chars": [
"letter",
"digit"
]
}
},
"analyzer": {
"mylike": {
"tokenizer": "my_ngram",
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {
"hxl_test01": {
"dynamic": false,
"properties": {
"title": {
"type": "string",
"analyzer": "mylike",
"search_analyzer": "standard"
}
}
}
}
}
nGram分词的相关配置,上面官方链接有详细解释。注意:"min_gram": "1", "max_gram": "20",这两个参数的含义及理解。
2、验证查询情况:
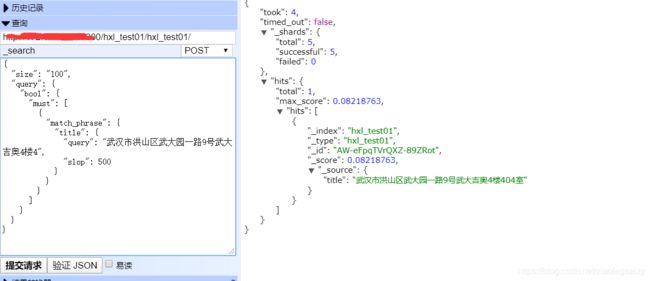 这样看,该分词器是起作用了,但是slop调小到200左右就不会出结果了,我们一般字面理解slop是字符之间的间隔(实际理解可以参考match_phrase官方介绍),这样看搜索语句slop这么大才能出结果是不是很不舒服,为什么呢,还有程序代码里面slop设置的很小在几十左右,怎么在不更新产品的情况下实现客户无感切换呢,而且关键的一点上面设置的max_gram参数越大我们的空间占用也越大,相当耗费存储资源。
这样看,该分词器是起作用了,但是slop调小到200左右就不会出结果了,我们一般字面理解slop是字符之间的间隔(实际理解可以参考match_phrase官方介绍),这样看搜索语句slop这么大才能出结果是不是很不舒服,为什么呢,还有程序代码里面slop设置的很小在几十左右,怎么在不更新产品的情况下实现客户无感切换呢,而且关键的一点上面设置的max_gram参数越大我们的空间占用也越大,相当耗费存储资源。
带着这样的疑问,查看了一下ngram分词器的效果,如下:(武汉市洪山区武大园一路9号武大吉奥4楼404室 为例)
//查询分词效果(hxl_test01--索引名称,mylike--分词器名称,武汉市洪山区武大园一路9号武大吉奥4楼404室--值)6.0以下
http://localhost:9200/hxl_test01/_analyze?analyzer=mylike&text=武汉市洪山区武大园一路9号武大吉奥4楼404室/
//查询分词效果 6.0以上
http://localhost:9200/_analyze/?pretty{ "analyzer": "ik_max_word", "text": "测试用例" }
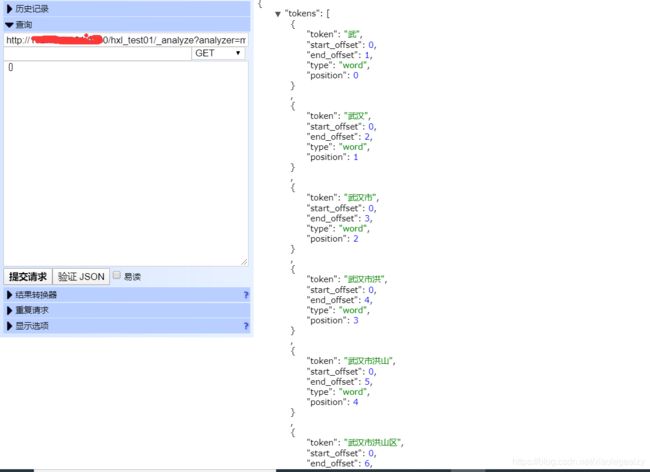
可以看到它的分词结果很多排列组合,相对standard占用了相对很大的内存。
看到这里就想到了一个ngram一个关键参数
min_gramMinimum length of characters in a gram. Defaults to
1.
max_gramMaximum length of characters in a gram. Defaults to
2.
是不是设置max_gram为1,让它把一串字符串分割为一个一个的字(字母/数字)就可以解决这种问题呢。
3、重建索引;删除hxl_test01,把步骤1的max_gram改为1重新put一遍即可。
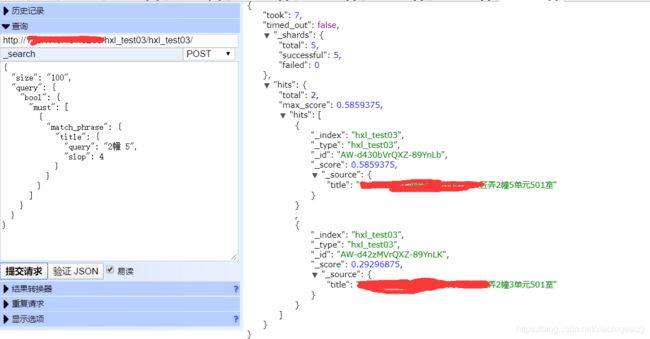
可见我们的猜想是对的,这样基本满足我们产品当前版本地址栏自动补全时的需求了。
总结:现在es社区还是很活跃的,日常遇到的需求基本都有解决方案,需要耐心的阅读/理解官方文档,在了解了基本用法之后,然后再去一些专业网站找相关问题的解决方案就会很容易了。
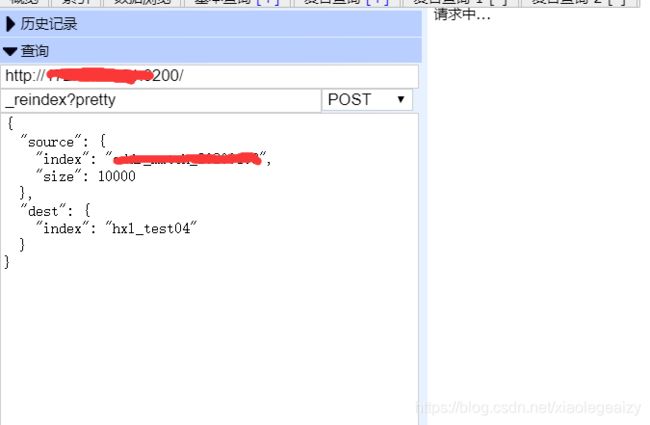
复制es索引数据到一个新的索引:(只需要修改source.index--源索引,和dest.index--目标索引;source.size批量提交设置size可以根据自己数据量调整,数据量大的情况下需要耐心等待请求中。。。。)
本人对分词器研究有限,某些东西的理解可能有偏差,望大家不吝赐教。(如有es查询功能相关的疑问欢迎骚扰。)
很多问题都可以在es中文社区找到相关解决方案或者受到别人的启发(https://elasticsearch.cn/)。