Zabbix监控进程CPU及内存
本文以写脚本至zabbix中的配置思路为主 其中一些必要的脚本及命令经供参考 最后会附上一个自动发现服务器中最占用资源的监控脚本
以监控nginx进程为例:
1 脚本 截取出现在服务器中nginx的CPU利用率
#!/bin/bash
cpu=`ps aux|grep "nginx"|grep -v "grep"|awk '{sum+=$3}; END{print sum}'`
echo $cpu
给1脚本zabbix的权限及可执行权限。
2 进入zabbix配置文件中:/etc/zabbix/zabbix_agentd.conf(此为ubuntu路径 Centos及其他需自行查询)
增加(可在空白处直接增加或者在# UnsafeUserParameters=0下一行增加):
UserParameter=XXX,/opt/zabbix/scripts/脚本名.sh(此处XXX赋值自己起名即可,此赋值以后需要)
重启zabbix_agent
3 去zabbix服务端测试脚本是否能被读取:
zabbix_get -p10050 -k 'XXX' -s IP
-p的10050是默认端口 如果更改则输入更改后的端口号
-k 'XXX' 这里XXX是刚才在agent端的zabbix配置文件中赋的值
IP 填写agent端的IP “这里注意 需要查看agent配置文件中写服务端IP的格式 如果写的公网这里就要用公网 写的内网这里就是用内网
4 上一步在zabbix server端能成功返回值后就可以进入zabbix中设置:
(1)配置模板
在配置--模板--创建模板

创建完模板后 点击刚创建的模板 然后开始配置监控项
(2)配置监控项:
配置--模板--leo--监控项--创建监控项
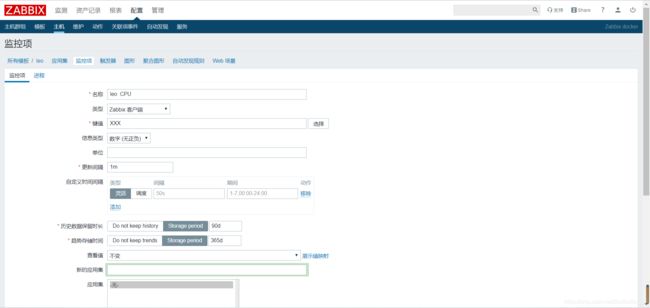
这一步中 键值就需要写你在agent中设置的XXX 名称和间隔和新的应用集自己起名即可
然后去设置模板连接到主机
配置--主机--点击主机名--模板--搜索框--选择自己的模板-确定-更新
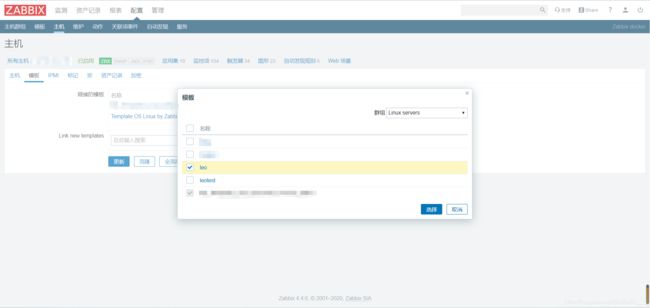
设置完后就可以查看数据 需要等几分钟
先去最新数据看是否有数据产生
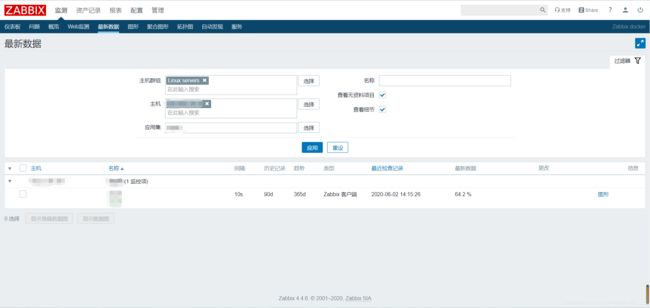
选择主机 选择应用集 等一分钟左右刷新一下 就可以看到最新数据。然后其他就可以在仪表盘创建图像了
最后附上一个转载的自动发现占资源的脚本及监控:
脚本1:
# cat discovery_process.sh
#!/bin/bash
#system process discovery script
top -b -n 1 > /tmp/.top.txt && chown zabbix. /tmp/.top.txt
proc_array=(`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$10}END{for(k in a)print a[k],k}'|sort -gr|head -10|cut -d" " -f2`)
length=${#proc_array[@]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i<$length;i++))
do
printf "\n\t\t{"
printf "\"{#PROCESS_NAME}\":\"${proc_array[$i]}\"}"
if [ $i -lt $[$length-1] ];then
printf ","
fi
done
printf "\n\t]\n"
printf "}\n"或者(这两个脚本效果一样)
# cat discovery_process2.sh
#!/bin/bash
#system process discovery script
top -b -n 1 > /tmp/.top.txt && chown zabbix. /tmp/.top.txt
proc_array=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$10}END{for(k in a)print a[k],k}'|sort -gr|head -10|cut -d" " -f2`
length=`echo "${proc_array}" | wc -l`
count=0
echo '{'
echo -e '\t"data":['
echo "$proc_array" | while read line
do
echo -en '\t\t{"{#PROCESS_NAME}":"'$line'"}'
count=$(( $count + 1 ))
if [ $count -lt $length ];then
echo ','
fi
done
echo -e '\n\t]'
echo '}'执行一下 会输出最占用资源的进程名
第二脚本 用于zabbix监控具体项目
#!/bin/bash
#system process CPU&MEM use information
#mail: [email protected]
mode=$1
name=$2
process=$3
mem_total=$(cat /proc/meminfo | grep "MemTotal" | awk '{printf "%.f",$2/1024}')
cpu_total=$(( $(cat /proc/cpuinfo | grep "processor" | wc -l) * 100 ))
function mempre {
mem_pre=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$10}END{for(k in a)print a[k],k}' | grep "\b${process}\b" | cut -d" " -f1`
echo "$mem_pre"
}
function memuse {
mem_use=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$10}END{for(k in a)print a[k]/100*'''${mem_total}''',k}' | grep "\b${process}\b" | cut -d" " -f1`
echo "$mem_use" | awk '{printf "%.f",$1*1024*1024}'
}
function cpuuse {
cpu_use=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$9}END{for(k in a)print a[k],k}' | grep "\b${process}\b" | cut -d" " -f1`
echo "$cpu_use"
}
function cpupre {
cpu_pre=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$9}END{for(k in a)print a[k]/('''${cpu_total}'''),k}' | grep "\b${process}\b" | cut -d" " -f1`
echo "$cpu_pre"
}
case $name in
mem)
if [ "$mode" = "pre" ];then
mempre
elif [ "$mode" = "avg" ];then
memuse
fi
;;
cpu)
if [ "$mode" = "pre" ];then
cpupre
elif [ "$mode" = "avg" ];then
cpuuse
fi
;;
*)
echo -e "Usage: $0 [mode : pre|avg] [mem|cpu] [process]"
esac执行一下第二个脚本试试:
[root@Zabbix_19F ~]# ./process_check.sh avg mem mysqld #输出mysqld进程使用的内存(计算公式:3832*18.5/100)
708.92
[root@Zabbix_19F ~]# ./process_check.sh pre mem mysqld #输出mysqld进程内存的使用率
18.5
[root@Zabbix_19F ~]# ./process_check.sh avg cpu mysqld #单个CPU的mysqld进程使用率
3.9
[root@Zabbix_19F ~]# ./process_check.sh pre cpu mysqld #所有CPU的mysqld进程的使用率
0.004875没问题后配置agent 还是在agent的conf中配置UserParameter
UserParameter=discovery.process,/opt/zabbix/scripts/discovery_process.sh
UserParameter=process.check[*],/opt/zabbix/scripts/process_check.sh $1 $2 $3
配置完后重启