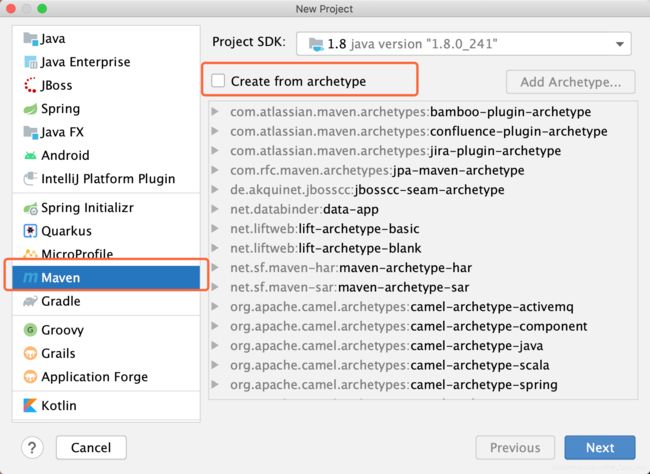
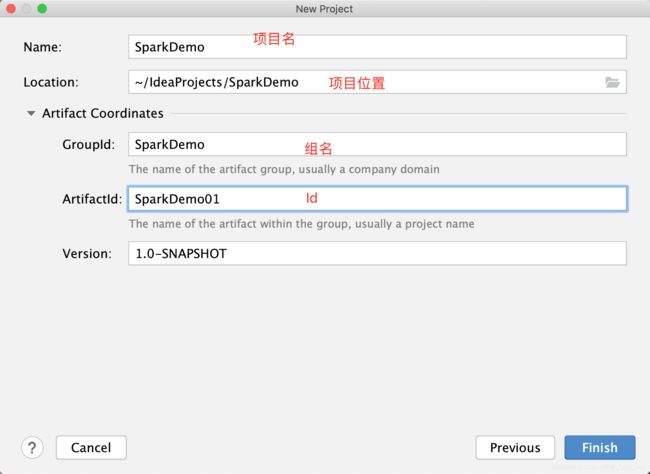
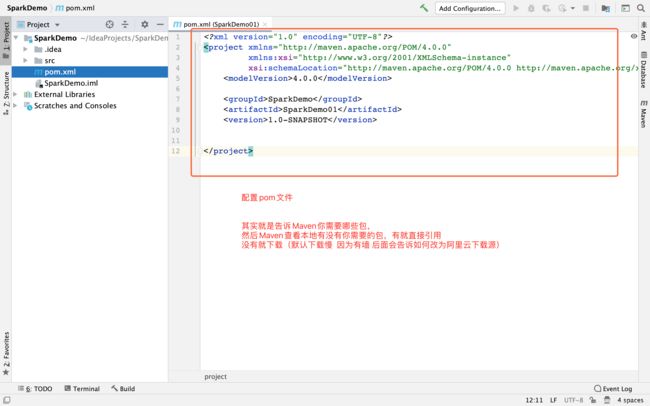
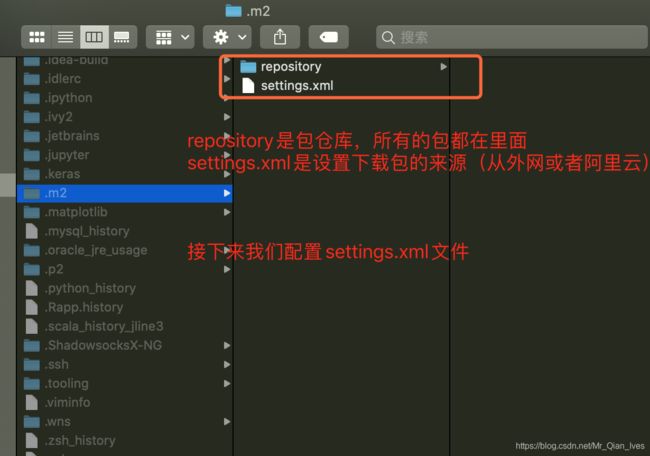
<?xml version="1.0" encoding="UTF-8"?><settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"><pluginGroups /><proxies /><servers /><!-- maven自动下载的jar包,会存放到该目录下 --><localRepository>此处需要修改(你想把下载的包放在哪?)</localRepository><mirrors><mirror><id>alimaven</id><mirrorOf>central</mirrorOf><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/repositories/central/</url></mirror><mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf></mirror><mirror><id>central</id><name>Maven Repository Switchboard</name><url>http://repo1.maven.org/maven2/</url><mirrorOf>central</mirrorOf></mirror><mirror><id>repo2</id><mirrorOf>central</mirrorOf><name>Human Readable Name forthis Mirror.</name><url>http://repo2.maven.org/maven2/</url></mirror><mirror><id>ibiblio</id><mirrorOf>central</mirrorOf><name>Human Readable Name forthis Mirror.</name><url>http://mirrors.ibiblio.org/pub/mirrors/maven2/</url></mirror><mirror><id>jboss-public-repository-group</id><mirrorOf>central</mirrorOf><name>JBoss Public Repository Group</name><url>http://repository.jboss.org/nexus/content/groups/public</url></mirror><mirror><id>google-maven-central</id><name>Google Maven Central</name><url>https://maven-central.storage.googleapis.com
</url><mirrorOf>central</mirrorOf></mirror><!-- 中央仓库在中国的镜像 --><mirror><id>maven.net.cn</id><name>oneof the central mirrors in china</name><url>http://maven.net.cn/content/groups/public/</url><mirrorOf>central</mirrorOf></mirror></mirrors></settings>
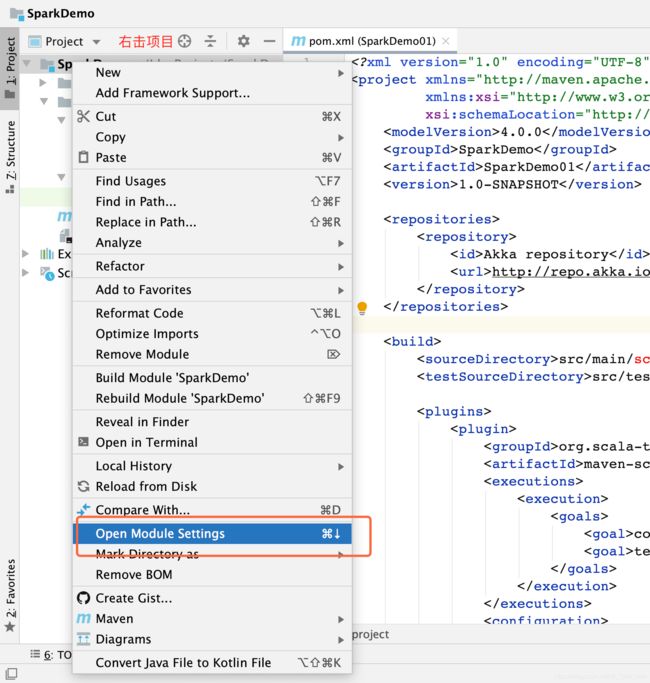
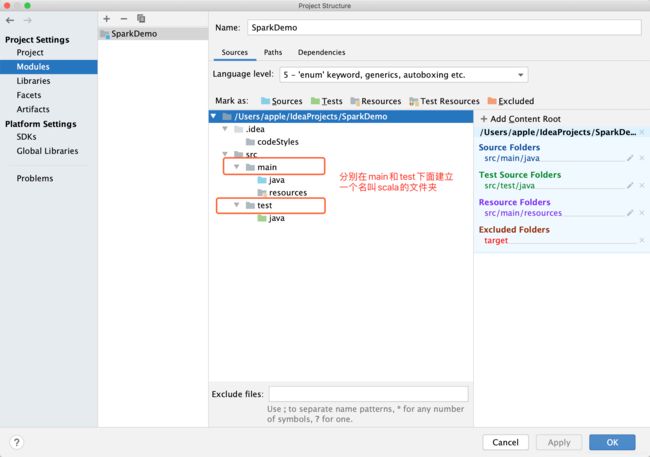
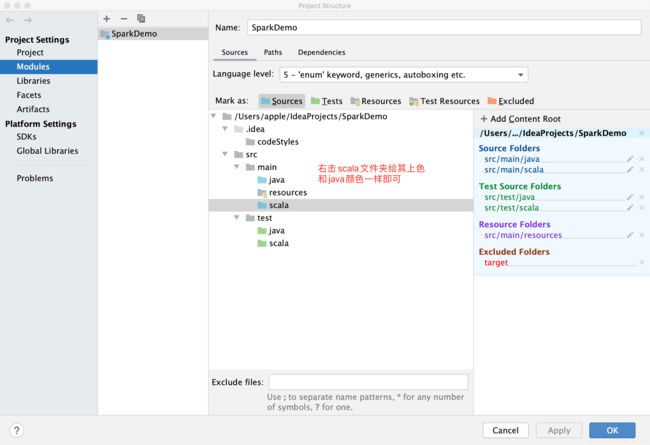
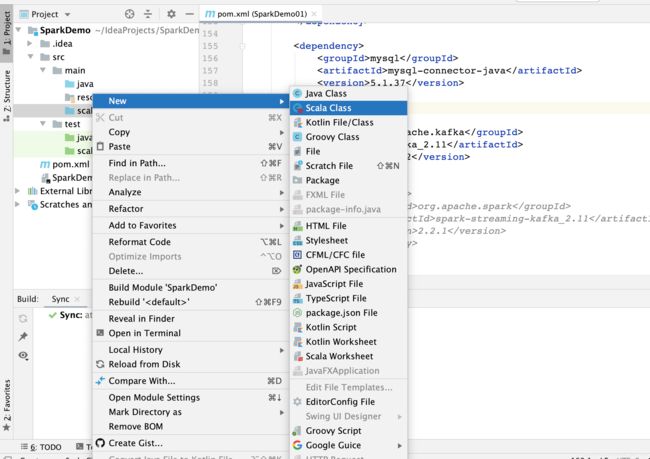
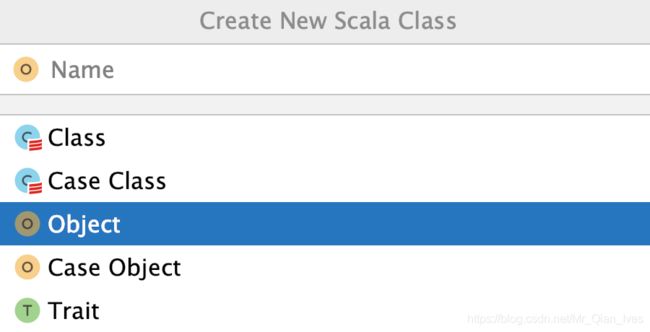
配置scala文件夹
右击即可建立文件夹
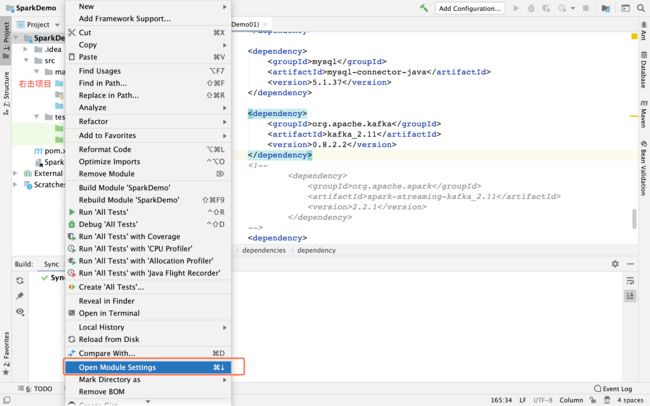
Reimport(同步jar包)
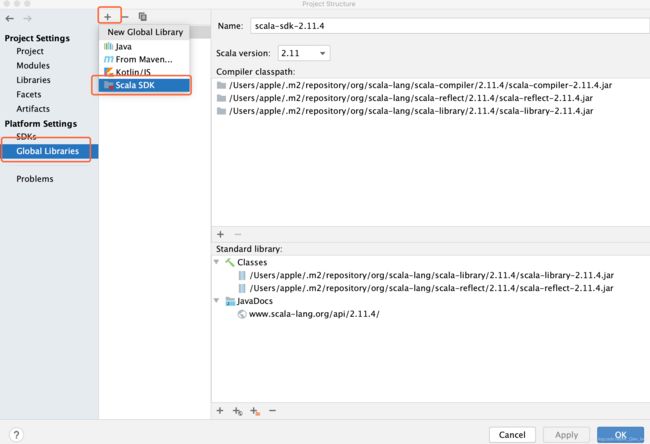
导入ScalaSDK
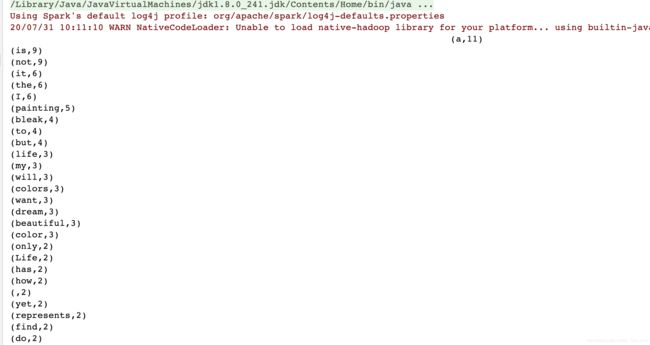
WordCount(java中的hello word)
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.log4j.{Level, Logger}import org.apache.spark.{SparkConf, SparkContext}
object wordCount {
def main(args: Array[String]): Unit ={//设置日志输出级别
Logger.getLogger("org").setLevel(Level.WARN)//配置RDD环境
val dataNow =newSimpleDateFormat("yyyy-MM-dd-HH:mm ").format(newDate)
val sparkconf =newSparkConf().setAppName(dataNow).setMaster("local[*]")
val sparkcontext =newSparkContext(sparkconf)//读取文件
val filePath ="/Users/apple/IdeaProjects/SparkInBigData/src/main/scala/wordCount.txt"
val rdd1 = sparkcontext.textFile(filePath)
val counts = rdd1.flatMap(t => t.split(" ")).map(word =>(word,1)).reduceByKey(_ + _)//第n个数加第n+1个数.sortBy(_._2,false)//按照第二个元素排序 降序.collect().foreach(println)//collect收集、foreach循环、println输出
sparkcontext.stop()}}
数据源
Everyone has their own dreams I am the same But my
dream is not a lawyer not a doctor not actors not
even an industry Perhaps my dream big people will
find it ridiculous but this has been my pursuit
My dream is to want to have a folk life I want it
to become a beautiful painting it is not only sharp
colors but also the colors are bleak I do not rule
out the painting is part of the black but I will
treasure these bleak colors Not yet how about a
colorful painting if not bleak add color how can
it more prominent American Life is like painting
painting the bright red color represents life beautiful
happy moments Painting a bleak color represents life
difficult unpleasant time You may find a flat with
a beautiful road is not very good yet but I do not
think it will If a person lives flat then what is
the point Life is only a short few decades I want
it to go Finally Each memory is a solid
最近受我的朋友委托用js+HTML做一个像手册一样的程序,里面要有可展开的大纲,模糊查找等功能。我这个人说实在的懒,本来是不愿意的,但想起了父亲以前教我要给朋友搞好关系,再加上这也可以巩固自己的js技术,于是就开始开发这个程序,没想到却出了点小问题,我做的查找只能绝对查找。具体的js代码如下:
function search(){
var arr=new Array("my
实例:
CREATE OR REPLACE PROCEDURE test_Exception
(
ParameterA IN varchar2,
ParameterB IN varchar2,
ErrorCode OUT varchar2 --返回值,错误编码
)
AS
/*以下是一些变量的定义*/
V1 NUMBER;
V2 nvarc
Spark Streaming简介
NetworkWordCount代码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
代码示例:
# include <stdio.h>
//冒泡排序
void sort(int * a, int len)
{
int i, j, t;
for (i=0; i<len-1; i++)
{
for (j=0; j<len-1-i; j++)
{
if (a[j] > a[j+1]) // >表示升序
nginx日志分割 for linux 默认情况下,nginx是不分割访问日志的,久而久之,网站的日志文件将会越来越大,占用空间不说,如果有问题要查看网站的日志的话,庞大的文件也将很难打开,于是便有了下面的脚本 使用方法,先将以下脚本保存为 cutlog.sh,放在/root 目录下,然后给予此脚本执行的权限
复制代码代码如下:
chmo
http://bukhantsov.org/2011/08/how-to-determine-businessobjects-service-pack-and-fix-pack/
The table below is helpful. Reference
BOE XI 3.x
12.0.0.
y BOE XI 3.0 12.0.
x.
y BO
大家都知道吧,这很坑,尤其是用惯了mysql里的自增字段设置,结果oracle里面没有的。oh,no 我用的是12c版本的,它有一个新特性,可以这样设置自增序列,在创建表是,把id设置为自增序列
create table t
(
id number generated by default as identity (start with 1 increment b