Spark执行过程【源码分析+图示】——启动脚本(standalone模式)
文章目录
- 前言
- 1. 执行start-master.sh脚本
- 1.1 源码分析
- 1.2 图示
- 2. 执行start-slaves.sh脚本
- 2.1 源码分析
- 2.1.1 Worker的main方法
- 2.1.2 Worker执行onStart方法(内部发送消息去Master注册)
- 2.1.3 Master收到RegisterWorker消息
- 2.1.4 Worker注册成功收到RegisteredWorker消息
- 2.1.5 Worker知道自己注册成功了,向Master报告自己的运行状态
- 2.1.6 schedule方法
- 2.2 图示
- 2.2.1 执行完Worker的main方法
- 2.2.2 Master接受RegisterWorker消息
- 3. 执行spark-submit脚本
- 3.1 SparkSubmit的main方法
- 3.2 invoke启动RestSubmissionClient主类
- 3.3 Master中的RestSubmissionServer接受消息
- 3.4 Master接受RequestSubmitDriver消息
- 3.4.1 构造DriverInfo结构(DriverDescription作为参数)
- 3.4.2 schedule()方法
前言
start-all.sh脚本:
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
# Load the Spark configuration
. "${SPARK_HOME}/sbin/spark-config.sh"
# Start Master
"${SPARK_HOME}/sbin"/start-master.sh
# Start Workers
"${SPARK_HOME}/sbin"/start-slaves.sh
以上的脚本会启动start-master.sh和start-slaves.sh两个脚本
其中start-master.sh启动的是“org.apache.spark.deploy.master.Master”这个类,也就是说要去执行它的main方法。而start-slaves.sh脚本是启动conf/slaves中指定的每一个slave:【./start-slave.sh spark://10.47.85.111:port】。
我们讨论Standalone集群部署模式,Master节点:Master机器;Slave节点:Slave1机器、Slave2机器。
1. 执行start-master.sh脚本
1.1 源码分析
main方法如下:
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf
val args = new MasterArguments(argStrings, conf)
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
rpcEnv.awaitTermination()
}
其中args中的host、port是Master的地址和端口号,然后是内部的startRpcEnvAndEndpoint方法:
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
//构造Master时候,会初始化StandaloneRestServer(RestSubmissionServer的子类)这个Server,并执行它的start方法。
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
/*给Master发送BoundPortsRequest消息,构造一个BoundPortsResponse对象*/
val portsResponse = masterEndpoint.askSync[BoundPortsResponse](BoundPortsRequest)
//返回值
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)
}
Master对象在被new完之后,会执行其内部的onStart方法,这里只需要知道会执行这个方法,具体原因另外解释。
val portsResponse = masterEndpoint.askSync[BoundPortsResponse](BoundPortsRequest)
表示通过Master的ref【需要注意的是这里的masterEndpoint变量其实不是RpcEndpoint类型,而是RpcEndpointRef类型的】给Master这个endpoint发送一个BoundPortsRequest类型的消息,Master是一个RpcEndpoint类型的对象,所以我们在它的receiveAndReply方法可以看到它对该类型消息的处理,如下:
case BoundPortsRequest =>
context.reply(BoundPortsResponse(address.port, webUi.boundPort, restServerBoundPort))
可以看到这里构造了一个BoundPortsResponse类型的对象,里面有一个重要的参数restServerBoundPort,它是Master内部的一个变量,定义如下:
if (restServerEnabled) {
val port = conf.getInt("spark.master.rest.port", 6066)
restServer = Some(new StandaloneRestServer(address.host, port, conf, self, masterUrl))
}
restServerBoundPort = restServer.map(_.start())
这里我们就启动了这个Server(当然"spark.master.rest.enabled"参数要为true)。这个Server和我们后面说提交的时候的RestSubmissionClient是对应的。
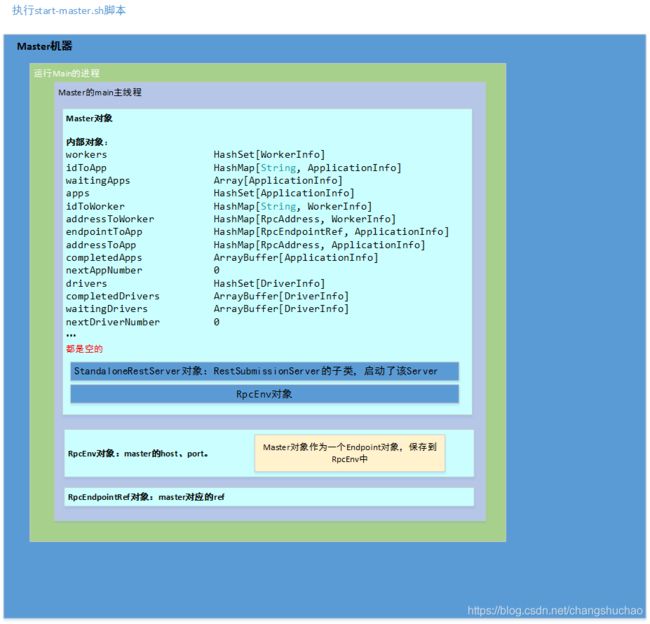
1.2 图示
执行完Master的main方法,此时的Master机器中的进程
2. 执行start-slaves.sh脚本
2.1 源码分析
2.1.1 Worker的main方法
Worker中的main方法:
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf
val args = new WorkerArguments(argStrings, conf)
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir, conf = conf)
rpcEnv.awaitTermination()
}
构造WorkerArguments对象,这个对象里面会获取机器的核心数、内存大小。接着看startRpcEnvAndEndpoint方法,如下:
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
cores: Int,
memory: Int,
masterUrls: Array[String],
workDir: String,
workerNumber: Option[Int] = None,
conf: SparkConf = new SparkConf): RpcEnv = {
// The LocalSparkCluster runs multiple local sparkWorkerX RPC Environments
val systemName = SYSTEM_NAME + workerNumber.map(_.toString).getOrElse("")
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(systemName, host, port, conf, securityMgr)
val masterAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
rpcEnv.setupEndpoint(ENDPOINT_NAME, new Worker(rpcEnv, webUiPort, cores, memory,
masterAddresses, ENDPOINT_NAME, workDir, conf, securityMgr))
rpcEnv
}
这里构造了Worker对象,将其当做参数设置到rpcEnv中。
2.1.2 Worker执行onStart方法(内部发送消息去Master注册)
按照上面的说法,Worker也会执行自己的onStart方法:
override def onStart() {
...
registerWithMaster()
...
}
我们暂时关注registerWithMaster方法:
private def registerWithMaster() {
// onDisconnected may be triggered multiple times, so don't attempt registration
// if there are outstanding registration attempts scheduled.
registrationRetryTimer match {
case None =>
registered = false
registerMasterFutures = tryRegisterAllMasters() //给多有Master发送注册消息
connectionAttemptCount = 0
registrationRetryTimer = Some(forwordMessageScheduler.scheduleAtFixedRate(
new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReregisterWithMaster))
}
},
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
INITIAL_REGISTRATION_RETRY_INTERVAL_SECONDS,
TimeUnit.SECONDS))
case Some(_) =>
logInfo("Not spawning another attempt to register with the master, since there is an" +
" attempt scheduled already.")
}
}
tryRegisterAllMasters方法:
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
masterRpcAddresses.map { masterAddress =>
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
val masterEndpoint = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
//发送RegisterWorker消息
sendRegisterMessageToMaster(masterEndpoint)
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
}
})
}
}
其实就是通过一个线程池对所有的Master发送RegisterWorker消息(可能有备用Master)。消息包含这个Worker的主要信息,代码如下:
private def sendRegisterMessageToMaster(masterEndpoint: RpcEndpointRef): Unit = {
masterEndpoint.send(RegisterWorker(
workerId,
host,
port,
self,
cores,
memory,
workerWebUiUrl,
masterEndpoint.address))
}
2.1.3 Master收到RegisterWorker消息
我们看Master中的receive方法中接受RegisterWorker消息的代码:
case RegisterWorker(
id, workerHost, workerPort, workerRef, cores, memory, workerWebUiUrl, masterAddress) =>
logInfo("Registering worker %s:%d with %d cores, %s RAM".format(
workerHost, workerPort, cores, Utils.megabytesToString(memory)))
if (state == RecoveryState.STANDBY) {
workerRef.send(MasterInStandby)
} else if (idToWorker.contains(id)) {
workerRef.send(RegisterWorkerFailed("Duplicate worker ID"))
} else { //当前的Master不是备用的,同时还没有编号为id的worker注册过
//构造WorkerInfo数据结构
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,
workerRef, workerWebUiUrl)
if (registerWorker(worker)) { //判断当前过来注册的Worker是否可以注册
persistenceEngine.addWorker(worker)
//发送RegisteredWorker消息给这个Worker,意思是成功在Master上注册了,带上这个Master的地址和ref
workerRef.send(RegisteredWorker(self, masterWebUiUrl, masterAddress))
//调度
schedule()
} else {
val workerAddress = worker.endpoint.address
logWarning("Worker registration failed. Attempted to re-register worker at same " +
"address: " + workerAddress)
workerRef.send(RegisterWorkerFailed("Attempted to re-register worker at same address: "
+ workerAddress))
}
}
2.1.4 Worker注册成功收到RegisteredWorker消息
查看Worker中的receive方法:
case msg: RegisterWorkerResponse =>
handleRegisterResponse(msg)
RegisteredWorker消息是RegisterWorkerResponse的子类,接着看方法:
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {
msg match {
case RegisteredWorker(masterRef, masterWebUiUrl, masterAddress) =>
...
registered = true
//更新内部的记录的master的信息(记录当前的活跃的Master),表示当前是在哪个Master注册的
changeMaster(masterRef, masterWebUiUrl, masterAddress)
//定期给自己发送心跳,然后自己再给Master发送心跳
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(SendHeartbeat)
}
}, 0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)
...
//遍历当前Worker中的Executor进程,抽象成ExecutorDescription对象
val execs = executors.values.map { e =>
new ExecutorDescription(e.appId, e.execId, e.cores, e.state)
}
//drivers.keys.toSeq表示当前的运行在这个Worker中的任务名称集合,它和上述的ExecutorDescription对象集合一起用来描述当前Worker的状态,然后当成参数构成WorkerLatestState消息,发送给Master节点。
masterRef.send(WorkerLatestState(workerId, execs.toList, drivers.keys.toSeq))
case ...
}
}
2.1.5 Worker知道自己注册成功了,向Master报告自己的运行状态
我们还是来查看Master的receive方法中如何处理WorkerLatestState类型的消息:
case WorkerLatestState(workerId, executors, driverIds) =>
//收到某个Worker的运行状态,尝试更新Master中存储的对应Worker的状态
idToWorker.get(workerId) match {
case Some(worker) =>
//对当前的Worker运行的Executor进行遍历,对于那些Master中的executors集合中不存在的Executor,发送KillExecutor消息给对应的Worker【Worker会从它的executors集合中找出该Executor进程并interrupt方法】
for (exec <- executors) {
val executorMatches = worker.executors.exists {
case (_, e) => e.application.id == exec.appId && e.id == exec.execId
}
if (!executorMatches) {
// master doesn't recognize this executor. So just tell worker to kill it.
worker.endpoint.send(KillExecutor(masterUrl, exec.appId, exec.execId))
}
}
//对当前的Worker运行的任务进行遍历,对于那些Master中drivers数组中不存在的任务,发送KillDriver消息给对应的Worker【Worker会从drivers集合中找出该Driver,更新其状态为killed,对进程执行destroy方法】
for (driverId <- driverIds) {
val driverMatches = worker.drivers.exists { case (id, _) => id == driverId }
if (!driverMatches) {
// master doesn't recognize this driver. So just tell worker to kill it.
worker.endpoint.send(KillDriver(driverId))
}
}
case None =>
logWarning("Worker state from unknown worker: " + workerId)
}
2.1.6 schedule方法
2.1.3中最后Master在处理RegisterWorker消息过程的最后,还执行了schedule方法,这是调度的方法,但是我们还在启动阶段,所以目前没有driver需要调度,我们暂时不看此方法。
2.2 图示
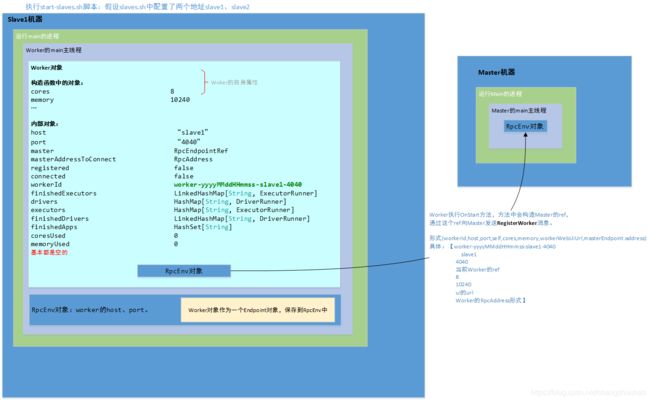
2.2.1 执行完Worker的main方法
假设两个Slave的core都是8个,内存都是10240M。分别为:“slave1”、“slave2”,端口号均为4040。
2.2.2 Master接受RegisterWorker消息
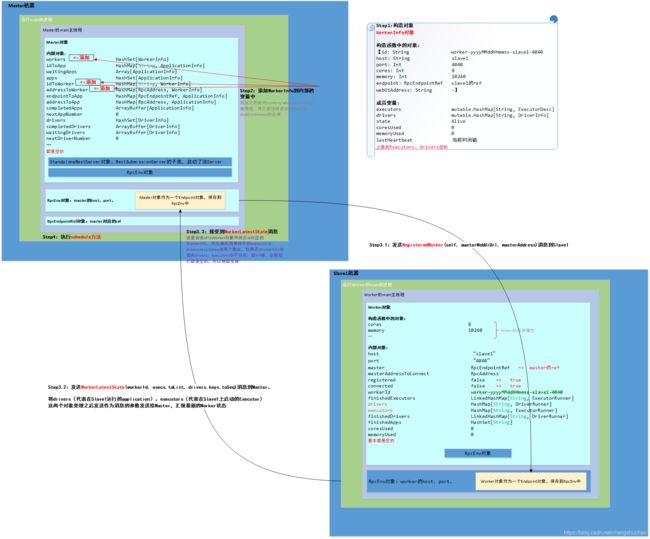
最后会执行schedule方法,因为我们现在是启动Worker期间,Master中的waitingDrivers数组内部是空的,因为我们还没有提交任何Job。我们暂时不看这个方法。
3. 执行spark-submit脚本
我们假设提交命令为:
./spark-submit.sh \
--class org.apache.spark.examples.SparkPi \ #jar中的主类
--master spark://207.184.161.138:7077 \ #master(可以多个,逗号分隔)
--deploy-mode cluster \ #部署模式 集群模式
--executor-memory 1G \ #该任务的executor的大小
--total-executor-cores 2 \ #该任务的executor的核心数
--supervise \ #Driver失败了,会重启
/path/to/examples.jar \ #jar包地址
1000 #主类中的参数
在spark-submit.sh脚本中,我们知道执行的类是”org.apache.spark.deploy.SparkSubmit“。
3.1 SparkSubmit的main方法
override def main(args: Array[String]): Unit = {
//拿到submit脚本传入的参数
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
printStream.println(appArgs)
}
//根据传入的参数匹配对应的执行方法
appArgs.action match {
//根据传入参数提交命令
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
我们主要看submit方法,传入的是SparkSubmitArguments对象,这里面有很多对象,大部分为null,我们的命令里面没有说明是submit、kill,默认是submit。我们看submit方法:
private def submit(args: SparkSubmitArguments): Unit = {
//childArgs里面是【子进程的运行时环境:包括参数、classpath、系统属性和入口类】
//childMainClass里面主要是【”org.apache.spark.deploy.rest.RestSubmissionClient“】
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
//定义了doRunMain方法
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
...
}
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
//如果是standalone集群
if (args.isStandaloneCluster && args.useRest) {
try {
//使用rest方式提交任务,入口类为org.apache.spark.deploy.rest.RestSubmissionClient
printStream.println("Running Spark using the REST application submission protocol.")
doRunMain()
} catch {
case e: SubmitRestConnectionException =>
printWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
//如果rest方式失败,则用旧的rpc方式提交,入口类为:org.apache.spark.deploy.Client
args.useRest = false
submit(args)
}
// In all other modes, just run the main class as prepared
} else {
doRunMain()
}
}
runMain方法中主要是如下一行代码:
mainMethod.invoke(null, childArgs.toArray)
执行了”org.apache.spark.deploy.rest.RestSubmissionClient“的main方法,并将我们提交的命令一并带过去了。
3.2 invoke启动RestSubmissionClient主类
main方法如下:
def main(args: Array[String]): Unit = {
if (args.length < 2) {
sys.error("Usage: RestSubmissionClient [app resource] [main class] [app args*]")
sys.exit(1)
}
val appResource = args(0) //jar包
val mainClass = args(1) //主类
val appArgs = args.slice(2, args.length) //其他参数
val conf = new SparkConf
val env = filterSystemEnvironment(sys.env)
run(appResource, mainClass, appArgs, conf, env)
}
run方法:
def run(
appResource: String,
mainClass: String,
appArgs: Array[String],
conf: SparkConf,
env: Map[String, String] = Map()): SubmitRestProtocolResponse = {
val master = conf.getOption("spark.master").getOrElse {
throw new IllegalArgumentException("'spark.master' must be set.")
}
val sparkProperties = conf.getAll.toMap
//与上文中Master端的StandaloneRestServer是对应的。
val client = new RestSubmissionClient(master)
val submitRequest = client.constructSubmitRequest(
appResource, mainClass, appArgs, sparkProperties, env)
client.createSubmission(submitRequest)
}
上面我们可以看到在run方法中新建了RestSubmissionClient对象。通过constructSubmitRequest方法,将我们的jar包地址、主类、主类参数、环境变量等参数组装成CreateSubmissionRequest对象——submitRequest。然后执行方法createSubmission,如下:
def createSubmission(request: CreateSubmissionRequest): SubmitRestProtocolResponse = {
logInfo(s"Submitting a request to launch an application in $master.")
var handled: Boolean = false
var response: SubmitRestProtocolResponse = null
for (m <- masters if !handled) {
validateMaster(m)
//得到的url形如【http://master:4040/v1/submissions/create】
val url = getSubmitUrl(m)
try {
//发送消息出去给server
response = postJson(url, request.toJson)
response match { //成功的返回值
case s: CreateSubmissionResponse =>
if (s.success) {
reportSubmissionStatus(s)
handleRestResponse(s)
handled = true
}
case unexpected =>
handleUnexpectedRestResponse(unexpected)
}
} catch {
case e: SubmitRestConnectionException =>
if (handleConnectionException(m)) {
throw new SubmitRestConnectionException("Unable to connect to server", e)
}
}
}
response
}
3.3 Master中的RestSubmissionServer接受消息
postJson之后,就是对应的Server对CreateSubmissionRequest类型的消息进行接受处理了,我们查看RestSubmissionServer类(StandaloneRestServer是它的子类),发现如下路由:
protected lazy val contextToServlet = Map[String, RestServlet](
s"$baseContext/create/*" -> submitRequestServlet,
s"$baseContext/kill/*" -> killRequestServlet,
s"$baseContext/status/*" -> statusRequestServlet,
"/*" -> new ErrorServlet // default handler
)
create类型的消息由submitRequestServlet处理,查看它的doPost方法:
private[rest] abstract class SubmitRequestServlet extends RestServlet {
protected override def doPost(
requestServlet: HttpServletRequest,
responseServlet: HttpServletResponse): Unit = {
val responseMessage =
try {
val requestMessageJson = Source.fromInputStream(requestServlet.getInputStream).mkString
//解析出jar包,主类等参数
val requestMessage = SubmitRestProtocolMessage.fromJson(requestMessageJson)
// The response should have already been validated on the client.
// In case this is not true, validate it ourselves to avoid potential NPEs.
requestMessage.validate()
handleSubmit(requestMessageJson, requestMessage, responseServlet)
} catch {
// The client failed to provide a valid JSON, so this is not our fault
case e @ (_: JsonProcessingException | _: SubmitRestProtocolException) =>
responseServlet.setStatus(HttpServletResponse.SC_BAD_REQUEST)
handleError("Malformed request: " + formatException(e))
}
sendResponse(responseMessage, responseServlet)
}
//未实现,在子类StandaloneSubmitRequestServlet中实现
protected def handleSubmit(
requestMessageJson: String,
requestMessage: SubmitRestProtocolMessage,
responseServlet: HttpServletResponse): SubmitRestProtocolResponse
}
我们看StandaloneSubmitRequestServlet中的handleSubmit的具体实现:
protected override def handleSubmit(
requestMessageJson: String,
requestMessage: SubmitRestProtocolMessage,
responseServlet: HttpServletResponse): SubmitRestProtocolResponse = {
requestMessage match {
//消息类型是CreateSubmissionRequest
case submitRequest: CreateSubmissionRequest =>
val driverDescription = buildDriverDescription(submitRequest)
//给master endpoint发送RequestSubmitDriver消息
val response = masterEndpoint.askSync[DeployMessages.SubmitDriverResponse](
DeployMessages.RequestSubmitDriver(driverDescription))
val submitResponse = new CreateSubmissionResponse
submitResponse.serverSparkVersion = sparkVersion
submitResponse.message = response.message
submitResponse.success = response.success
submitResponse.submissionId = response.driverId.orNull
val unknownFields = findUnknownFields(requestMessageJson, requestMessage)
if (unknownFields.nonEmpty) {
// If there are fields that the server does not know about, warn the client
submitResponse.unknownFields = unknownFields
}
submitResponse
case unexpected =>
responseServlet.setStatus(HttpServletResponse.SC_BAD_REQUEST)
handleError(s"Received message of unexpected type ${unexpected.messageType}.")
}
}
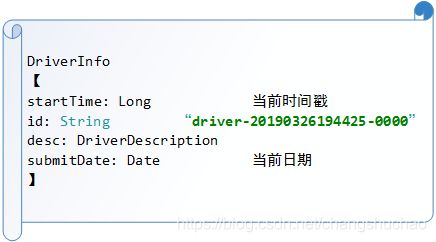
主要是构造了DriverDescription数据结构,结构如下:

然后通过Master的ref发送RequestSubmitDriver(driverDescription)消息给Master这个Endpoint。
3.4 Master接受RequestSubmitDriver消息
我们查看Master的receiveAndReply方法中如何处理RequestSubmitDriver类型消息的代码:
case RequestSubmitDriver(description) =>
if (state != RecoveryState.ALIVE) {//不是主master
val msg = s"${Utils.BACKUP_STANDALONE_MASTER_PREFIX}: $state. " +
"Can only accept driver submissions in ALIVE state."
context.reply(SubmitDriverResponse(self, false, None, msg))
} else {
logInfo("Driver submitted " + description.command.mainClass)
//根据description创建一个DriverInfo对象【DriverInfo实现了Serializable接口,是可序列化的】
val driver = createDriver(description)
persistenceEngine.addDriver(driver)
// Master将这个DriverInfo对象添加待调度列表中
waitingDrivers += driver
//总的列表
drivers.add(driver)
//调度
schedule()
//返回结果给handleSubmit方法,把driver传给Server,然后Server把结果再传给driver
context.reply(SubmitDriverResponse(self, true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}"))
}
3.4.1 构造DriverInfo结构(DriverDescription作为参数)
其中构造的DriverInfo结构如下:
3.4.2 schedule()方法
该方法源码如下:
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) {
return
}
//将传入集合【这里将workers这个Set转成Seq,筛选出Seq里面状态为ALIVE的那一部分】顺序打乱
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
//在我这个例子里面为 2
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
//遍历待调度的Driver(就是要运行的任务)。在我这个例子,当前只有一个
for (driver <- waitingDrivers.toList) {
var launched = false
var numWorkersVisited = 0
while (numWorkersVisited < numWorkersAlive && !launched) {
//取出打乱顺序的Worker中的worker,假设是Slave1
val worker = shuffledAliveWorkers(curPos)
//计数器累加
numWorkersVisited += 1
//在我们的示例中:
// Worker的memoryFree是10240M,coresFree是8
// driver.desc中mem为512M,cores为1
//这里的Slave1的内存和core数都能满足driver,所以可以直接在该Worker上启动driver
if(worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
//启动Driver的方法
launchDriver(worker, driver)
//启动完成之后将该driver从待调度列表删除
waitingDrivers -= driver
//启动状态变成true
launched = true
}
curPos = (curPos + 1) % numWorkersAlive
}
}
//第四步数
startExecutorsOnWorkers()
}