CentOS虚拟机Java环境中MapReduce Hadoop的WordCount(词频运算)程序连接数据入门
目录
1. Hadoop 简介
2. Hadoop 的架构
3. MapReduce 简介
4. Hadoop HDFS 简介
5. HDFS架构
6. MapReduce开发流程概念(重点)
7. maperuce 运算开发示例(重点)
8. hdfs 的数据类型(重点)
9. 完整代码
1. Hadoop 简介
Hadoop是使用Java编写,允许分布式集群,使用简单的编程模型的计算机大型数据集处理的Apache的开源框架。Hadoop框架应用工程提供跨计算机集群的分布式存储和计算的环境。Hadoop是专为单一服务器到上千台机器扩展,每个机器都可以提供本地计算和存储。
2. Hadoop 的架构
在其核心,Hadoop主要有两个层次,即:加工/计算层(MapReduce),以及存储层(Hadoop分布式文件系统)。

3. MapReduce 简介
MapReduce是一种并行编程模型,是一种处理技术和程序模型基于Java的分布式计算,用于编写普通硬件的设计,谷歌对大量数据的高效处理(多TB数据集)的分布式应用在大型集群(数千个节点)以及可靠的容错方式。MapReduce程序可在Apache的开源框架Hadoop上运行。MapReduce算法包含了两项重要任务,即Map和Reduce。Map采用了一组数据,并将其转换成另一组数据,其中,各个元件被分解成元组(键/值对)。其次,减少任务,这需要从Map作为输入并组合那些数据元组成的一组小的元组输出。作为MapReduce暗示的名称的序列在Map作业之后执行Reduce任务。【以下的MapReduce运算开发示例做详细说明】。
4. Hadoop HDFS 简介
Hadoop文件系统使用分布式文件系统设计开发。它是运行在普通硬件。不像其他分布式系统,HDFS是高度容错以及使用低成本的硬件设计。
HDFS拥有超大型的数据量,并提供更轻松地访问。为了存储这些庞大的数据,这些文件都存储以冗余的方式的方式来拯救系统免受可能的数据损失,在发生故障时。同样,HDFS也使得可用于并行处理的应用程序。
HDFS的特点:①它适用于在分布式存储和处理。②Hadoop提供的命令接口与HDFS进行交互。③名称节点和数据节点的帮助用户内置的服务器能够轻松地检查集群的状态。④流式访问文件系统数据。⑤HDFS提供了文件的权限和验证。
5. HDFS架构
下面给出的是Hadoop的文件系统的体系结构。
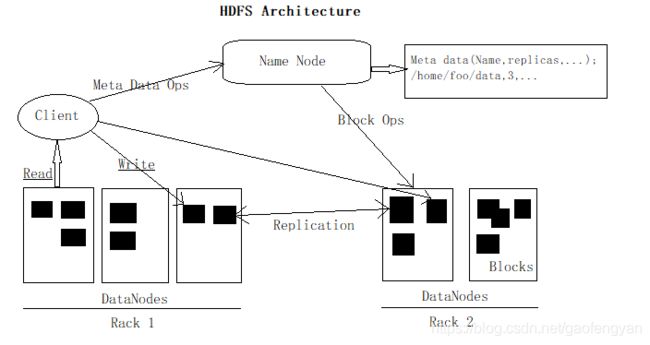
HDFS遵循主从架构,它具有以下元素:
名称节点 - Namenode:包含GUN/Linux操作系统和软件名称节点的普通硬件。他是一个可以在商品硬件上运行的软件。具有名称节点系统作为主服务器,他执行以下任务:管理文件系统命名空间。规范客户端对文件的访问。它也执行文件系统操作,如重命名,关闭和打开文件和目录。
数据节点 - datanode:具有GUN/Linux操作系统和软件Datanode的普通硬件。对于集群中的每一个节点(普通硬件/系统),都有一个数据节点。这些节点管理数据存储在他们的系统。数据节点上的文件系统执行的读写操作,根据客户的请求。还根据名称节点的指令执行操作,如块的创建,删除和复制。
块:一般用户数据存储在HDFS文件。在一个文件系统中的文件将被划分为一个或多个段和/或存储在个人数据的节点。这些文件段被称为块。换句话说,数据的HDFS可以读取或写入的最小量被称为一个块。缺省的块大小为64MB,但他可以增加按照需要在HDFS配置来改变。
6. MapReduce开发流程概念(重点)
mapreduce 运算框架主要实现 hadoop 的数据处理。数据处理中流经过5个节点。
数据流: input -> split -> map -> shuffle -> reduce (最后 reduce 输出)
6.1 input
input 是将被运算的数据(文件)切成默认的是64M的块(block)方便后续运算。
6.2 split
切片,将Input中的块按照行切成片(片是键值对),方便后续Map运算。
wordcount split 数据处理:每行的起始下标作为输出键,每行的内容作为输出值。
6.3 map(开发做)
对slipt的片(行)进行数据处理,处理成键值对。
wordcount map 数据处理:将每行拆分成每一个单词作为输出键,个数设置为1 作为输出值。
6.4 shuffle
混洗,将所有的map运算结果重新按照键分组,输出键值对。
wordcount 中 shuffle将map的相同键的数据合并成一条,值是一个固定值为1的数组。
6.5 reduce(开发做)
将混洗的结果集做数据处理。
wordcount的 reduce数据处理:将键对应的值(值为1的数字)的做累加,即得出我们每个单词出现个数。
6.6 输出(output)
7. maperuce 运算开发示例(重点)

这里分布式设备(两台从机)会将不规则的不管是文件还是文件夹统一分配成规则的文件方式,并将所有文件分割成默认的64MB的多个块,这样就可以达到selever做任务的时候达到负载均衡的平均处理效果,提高工作效率。map是按照需求来拆分每一行(可以是将一拆分成多个单词,也可以是将多个合并成一个),并且是键值对关系,键对应的是字符串,值对应的是固定值为1的数组;那么在混洗的时候也要对应数据类型,输入的是字符串键,和数组类型。并且在运算过程中全是泛型方式。在开发中主要开发【map】、【shuffle】、【reduce】,而【shuffle】可以不用动,因为混洗本身是自带,不用开发。这里我们就重点开发MapReduce五步中的两步:【map】、【reduce】。
示例两个文件【所在路径:hdfs://node1:9000/input/下】:
1.txt
this is a hadoop text .hadoop is a application .
this is a example .2.txt
java
mysql
hadoop
mybatismapreduce运算开发环境说明:我这里时安装的VMware Workstation Pro15运行环境(这个可以不做版本要求),在工具里安装了3个CentOS6.6的虚拟机,一台主机,两台从机,安装了jdk,eclipse,hadoop,并按要求进行了配置。这里不再赘述相关配置,前面的博客有相关的安装配置。
1)用命令启动hadoop运算(使用结束后记得按反顺序关闭运算框架):
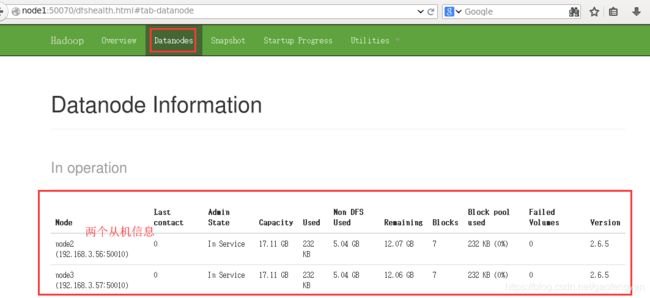
[hduser@node1 ~]$ ./hadoop/sbin/start-dfs.sh [hduser@node1 ~]$ ./hadoop/sbin/start-yarn.sh 2)启动浏览器:http://node1:50070/ 查看是否启动运算的分布式成功:

准备工作(使用虚拟机中安装的eclipse作业):
1)新建一个mapreduce项目:wordcountdemo【new】->【project】->【Map/Reduce Project】->【project name:wordcountdemo】->【finish】
2)新建资源文件夹:【右键项目名】->【new】->【source folder】->【folder name:resource】->【finish】
3)增加配置文件 core-site.xml , log4j.properties (两个配置文件在hadoop安装目录下的conf文件都能找到,可直接使用)
4)新建一个class WordCountJob(开发map、开发reduce、创建job并执行)
引导的包:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;7.1 Map 开发
Map 要求:
1)静态类
2)继承hadoop 的 Mapper父类方法【Mapper
* 第1个参数:map 输入 键 的类型
* 第2个参数:map 输入 值 的类型
* 第3个参数:map 输出 键 的类型
* 第4个参数:map 输出 值 的类型3)重写map()
/**
* 开发map
*
* @author hduser
* 第1个参数:map 输入键的类型
* 第2个参数:map 输入值的类型
* 第3个参数:map 输出键的类型
* 第4个参数:map 输出值的类型
*/
public static class WordCountMapper extends Mapper {
/**
* 每一个切片 会执行一次map方法,
* keyIn是每一行的键,
* valueIn 是每一行的值,
* context 是上下文容器,用于将map的结果输出到下一步
* wordcount map 把value拆成单个单词
* @throws InterruptedException
* @throws IOException
*/
public void map(Object keyIn,Text valueIn,Context ctx) throws IOException, InterruptedException{
//固定值1 作为输出值
IntWritable valueOut = new IntWritable(1);
Text keyOut = null;
//this is hadoop application.
StringTokenizer token = new StringTokenizer(valueIn.toString());
//按照迭代器用法使用
while (token.hasMoreTokens()) {
String key = token.nextToken();
keyOut = new Text(key);
ctx.write(keyOut, valueOut);
}
}
} 7.2 Rreduce 开发
Reduce 要求:
1)静态类
2)继承hadoop 的 reduce父类方法【Reducer
3)重写reduce()
public static class WordCountReducer extends Reducer{
public void reduce(Text keyIn,Iterable valuesIn,Context ctx) throws IOException, InterruptedException{
Text keyOut = keyIn;
//输出值
IntWritable valueOut = new IntWritable();
int sum = 0 ;
//循环混洗后的数字数组,如[1,1,1,1,1]
for (IntWritable val : valuesIn) {
sum += val.get(); //转成int型 , 做累加
}
valueOut.set(sum); //转成字符串输出去,将累加的结果转化为IntWritable类型
ctx.write(keyOut, valueOut); //输出到下一步
} 7.3 创建并启动job
1)加载hdfs配置文件(配置hdfs访问入口)
2)创建一个job并确定设置job(运算作业)的主启动类。
3)设置job的map自定义静态类
4)设置job的reduce自定义静态类
5) 配置最终输出(reduce)的输出键和值的类型
6)mapreduce 作业需要的资源位置(总输入位置)
7)mapreduce 作业结果的保存位置(总输出位置)
8) 启动
9)注意:这里的mapreduce作业结果集总输出位置的文件是不能在hdfs中存在的,必须是在这里启动后重建的,如果hdfs中存在文件,启动时会抛异常。【Path outputPath = new Path("hdfs://node1:9000/output/wc3");】
public static void main(String[] args) throws Exception {
// 创建job 执行job
// 1)加载hdfs配置文件(配置hdfs访问入口)
Configuration conf = new Configuration();
// 2)创建一个job并确定设置job(运算作业)的主启动类。
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJob.class);
// 3)设置job的map自定义静态类
job.setMapperClass(WordCountMapper.class);
// 4)设置job的reduce自定义静态类
job.setReducerClass(WordCountReducer.class);
// 5) 配置最终输出(reduce)的输出键和值的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6)mapreduce 作业需要的资源位置(总输入位置)
Path inputPath1 = new Path("hdfs://node1:9000/input/1.txt");
Path inputPath2 = new Path("hdfs://node1:9000/input/2.txt");
FileInputFormat.addInputPath(job, inputPath1);
FileInputFormat.addInputPath(job, inputPath2);
// 7)mapreduce 作业结果的保存位置(总输出位置)
Path outputPath = new Path("hdfs://node1:9000/output/wc3");
FileOutputFormat.setOutputPath(job, outputPath);
// 8) 启动
System.exit(job.waitForCompletion(true)?0:1);
}7.4)启动运算后的结果:

8. hdfs 的数据类型(重点)
1)字符串 Text , 等同于Java中的字符串。在hdfs中Text类型是字节文件。
Text -> String
Text t :转成String t.toString()
String -> Text
Text t = new Text(字符串);2)整型数字 IntWritable 等同于Java中的Integer
IntWritable 转 int
IntWritable a;
int b = a.get();//转化
int 转 IntWritable
IntWritable a = new IntWritable(数字);
或
IntWritable a = new IntWritable();
a.set(数字);3)长整型 LongWritable 等同于Java中的Long
9. 完整代码
package org.kgc1803.demo;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 词频
*
* @author hduser
*
*/
public class WordCountJob {
/**
* 开发map
*
* @author hduser
* 第一个参数:map 输入键的类型
* 第2个参数:map 输入值的类型
* 第3个参数:map 输出键的类型
* 第4个参数:map 输出值的类型
*/
public static class WordCountMapper extends Mapper {
/**
* 每一个切片 会执行一次map方法,
* keyIn是每一行的键,
* valueIn 是每一行的值,
* context 是上下文容器,用于将map的结果输出到下一步
* wordcount map 把value拆成单个单词
* @throws InterruptedException
* @throws IOException
*/
public void map(Object keyIn,Text valueIn,Context ctx) throws IOException, InterruptedException{
//固定值1 作为输出值
IntWritable valueOut = new IntWritable(1);
Text keyOut = null;
//this is hadoop application.
StringTokenizer token = new StringTokenizer(valueIn.toString());
//按照迭代器用法使用
while (token.hasMoreTokens()) {
String key = token.nextToken();
keyOut = new Text(key);
ctx.write(keyOut, valueOut);
}
}
}
// 开发reduce
public static class WordCountReducer extends Reducer{
public void reduce(Text keyIn,Iterable valuesIn,Context ctx) throws IOException, InterruptedException{
Text keyOut = keyIn;
//输出值
IntWritable valueOut = new IntWritable();
int sum = 0 ;
//循环混洗后的数字数组,如[1,1,1,1,1]
for (IntWritable val : valuesIn) {
sum += val.get(); //转成int型 , 做累加
}
valueOut.set(sum); //转成字符串输出去,将累加的结果转化为IntWritable类型
ctx.write(keyOut, valueOut); //输出到下一步
}
}
public static void main(String[] args) throws Exception {
// 创建job 执行job
// 1)加载hdfs配置文件(配置hdfs访问入口)
Configuration conf = new Configuration();
// 2)创建一个job并确定设置job(运算作业)的主启动类。
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJob.class);
// 3)设置job的map自定义静态类
job.setMapperClass(WordCountMapper.class);
// 4)设置job的reduce自定义静态类
job.setReducerClass(WordCountReducer.class);
// 5) 配置最终输出(reduce)的输出键和值的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6)mapreduce 作业需要的资源位置(总输入位置)
Path inputPath1 = new Path("hdfs://node1:9000/input/1.txt");
Path inputPath2 = new Path("hdfs://node1:9000/input/2.txt");
FileInputFormat.addInputPath(job, inputPath1);
FileInputFormat.addInputPath(job, inputPath2);
// 7)mapreduce 作业结果的保存位置(总输出位置)
Path outputPath = new Path("hdfs://node1:9000/output/wc3");
FileOutputFormat.setOutputPath(job, outputPath);
// 8) 启动
System.exit(job.waitForCompletion(true)?0:1);
}
}