Java Stream Map和flatmap及集合处理
编程中多数要对集合进行各种操作,获取Map、Set、List等。
Map
比如一个对象List,获取所有人的名字集合
@Test
public void should_can_get_name_map() {
PersonInfo kaka = new PersonInfo("Kaka", 22);
PersonInfo hustzw = new PersonInfo("Hustzw", 24);
List personInfos = Lists.newArrayList(kaka, hustzw);
List nameList = personInfos.stream().map(PersonInfo::getName).collect(Collectors.toList());
assertThat(nameList).contains("Kaka");
} HashMap
构建一个属性和其本身的映射,比如根据人名找到人。
@Test
public void should_can_get_name_info_map() {
PersonInfo kaka = new PersonInfo("Kaka", 22);
PersonInfo hustzw = new PersonInfo("Hustzw", 24);
List personInfos = Lists.newArrayList(kaka, hustzw);
// 注意, 这里 key 不能重复,否则报错
Map nameInfoMap1 = personInfos.stream().collect(Collectors.toMap(PersonInfo::getName, x -> x));
Map nameInfoMap2 = personInfos.stream().collect(Collectors.toMap(PersonInfo::getName, Function.identity()));// 效果一样
assertThat(nameInfoMap1).containsKeys("Kaka", "Hustzw");
assertThat(nameInfoMap2).containsKeys("Kaka", "Hustzw");
} Set
同样是获取集合
@Test
public void should_can_get_set() {
PersonInfo kaka = new PersonInfo("Kaka", 22);
PersonInfo hustzw = new PersonInfo("Hustzw", 24);
List personInfos = Lists.newArrayList(kaka, hustzw);
// 注意, 这里 key 不能重复,否则报错
Set adultsSet = personInfos.stream().filter(x -> x.getAge() >= 18).collect(Collectors.toSet());
assertThat(adultsSet).contains(kaka, hustzw);
assertThat(adultsSet).contains(hustzw, kaka);
} flatmap
Java8的stream中提供flatmap也是用于构建Map,不过区别的是它会把结果打平。看个例子:
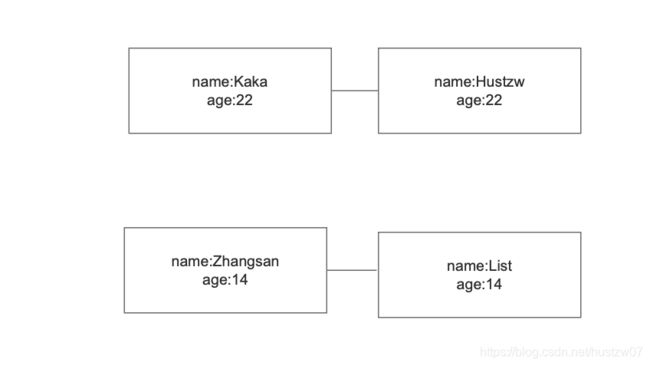
有两个List,想对所有元素按年龄分类。如果利用循环可能需要两层循环。
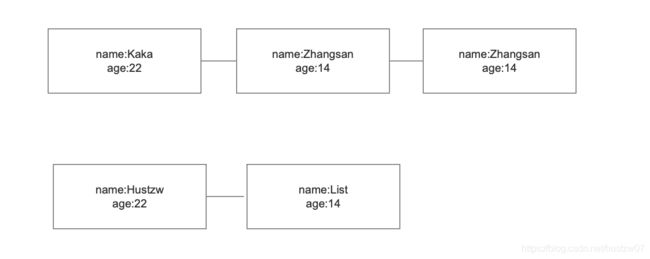
利用 flatemap后,打平后很容易对其操作。
代码:
@Test
public void should_can_get_name_info_flat_map() {
PersonInfo kaka = new PersonInfo("Kaka", 22);
PersonInfo hustzw = new PersonInfo("Hustzw", 22);
PersonInfo zhangSan = new PersonInfo("ZhangSan", 14);
PersonInfo lisi = new PersonInfo("LiSi", 14);
List firstInfos = Lists.newArrayList(kaka, zhangSan, zhangSan);
List secondInfos = Lists.newArrayList(hustzw, lisi);
List> complexInfos = Lists.newArrayList(firstInfos, secondInfos);
// 按年龄分组,不会去重
Map> map = complexInfos.stream().flatMap(l -> l.stream()).collect(Collectors.groupingBy(PersonInfo::getAge));
// 如果需要去重复
Map> distinctMap = complexInfos.stream().flatMap(l -> l.stream())// 重新生成一个Stream对象取而代之
.distinct().collect(Collectors.groupingBy(PersonInfo::getAge));
assertThat(map).containsKey(14);
assertThat(map.get(14).size()).isEqualTo(3);
assertThat(distinctMap.get(14).size()).isEqualTo(2);
} 集合处理
当然还有一些用于对集合过滤、统计的。看个例子:
@Data
@Builder
@AllArgsConstructor
public class Work {
private String name;
private String department;
private Integer age;
}下边对该类型的集合进行处理:
public class MyTest {
private List personList;
@Before
public void setup() {
personList = Lists.newArrayList();
personList.add(Work.builder().name("zhangsan").department("IT").age(20).build());
personList.add(Work.builder().name("lisi").department("IT").age(22).build());
personList.add(Work.builder().name("wangwu").department("HR").age(28).build());
personList.add(Work.builder().name("zhaoliu").department("Purchasing").age(23).build());
personList.add(Work.builder().name("liuqi").department("IT").age(22).build());
}
@Test
public void should_can_match() {
// 是否全部 20-30 岁
boolean allYoung = personList.stream().allMatch(work -> (20 <= work.getAge() && work.getAge() <= 30));
// 是否存在 age = 22的
boolean anyTwentyFive = personList.stream().anyMatch(work -> 22 == work.getAge());
// 没有 age = 25的
boolean noneTwentyFive = personList.stream().noneMatch(work -> 25 == work.getAge());
// 查找第一个满足条件的
Optional firstTwentyTwo = personList.stream().filter(work -> 22 <= work.getAge()).findFirst();
// 查找任何一个满足条件的,注意不一定是第一个
Optional anyTwentyTwo = personList.stream().filter(work -> 22 <= work.getAge()).findAny();
}
@Test
public void should_can_filter_it_work() {
// 年龄集合
List ageList = personList.stream().map(Work::getAge).distinct().collect(Collectors.toList());
// 最大年龄
Optional maxAgeWork = personList.stream().collect(Collectors.maxBy((s1, s2) -> s1.getAge() - s2.getAge()));
// 或者
Optional maxAgeWork2 = personList.stream().collect(Collectors.maxBy(Comparator.comparing(Work::getAge)));
// 最小年龄
Optional minAgeWork = personList.stream().collect(Collectors.minBy(Comparator.comparing(Work::getAge)));
// 部门年龄求和
Integer sumAgeForIT = personList.stream().filter(work -> "IT".equalsIgnoreCase(work.getDepartment())).collect(Collectors.summingInt(Work::getAge));
// 平均年龄
Double avgAge = personList.stream().collect(Collectors.averagingInt(Work::getAge));
// 名字拼接
String nameList = personList.stream().map(Work::getName).collect(Collectors.joining(","));
// 按部门group by
Map> deparmentWorkMap = personList.stream().collect(Collectors.groupingBy(Work::getDepartment));
// 按部门group by并计数
Map deparmentWorkCountMap = personList.stream().collect(Collectors.groupingBy(Work::getDepartment, Collectors.counting()));
// 按部门、年龄两级group by
Map>> deparmentAgeMap = personList.stream().collect(Collectors.groupingBy(Work::getDepartment, Collectors.groupingBy(Work::getAge)));
// 一分为二:IT部分和非IT部门
Map> partition = personList.stream().collect(Collectors.partitioningBy(work -> "IT".equals(work.getDepartment())));
}
@Test
public void should_can_statistic_int() {
List primes = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
IntSummaryStatistics stats = primes.stream().mapToInt(x -> x).summaryStatistics();
System.out.println(stats);
}
// 还有一些复杂
@Test
public void should_can_sort_by_asc() {
Map maxAgeWork = personList.stream().collect(Collectors.toMap(Work::getName, Function.identity(), BinaryOperator.maxBy(Comparator.comparing(Work::getAge))));
maxAgeWork.forEach((name, work) -> {
System.out.println("name is [" + name + "], age is [" + work.getAge() + "]");
});
}
// TODO summaryStatistics 方法可以帮我们获取:最大值,最小值,和,平均值信息
// 返回值为(Int/Long/Double)的 SummaryStatistics
// 获取每个部门的统计信息
@Test
public void should_can_get_group_by_age() {
Map result = personList.stream().collect(Collectors.groupingBy(Work::getDepartment, Collectors.summarizingInt(Work::getAge)));
System.out.println("Department | Statistics");
for (Map.Entry entry : result.entrySet()) {
System.out.printf("%10s : %70s\n", entry.getKey(), entry.getValue().toString());
}
}
} 返回值Int/Long/Double对应的统计方法分别是IntSummaryStatistics、LongSummaryStatistics、DoubleSummaryStatistics。
值得说的是:summaryStatistics 方法帮我们获取:最大值,最小值,和,平均值信息。即简单的数据类型的统计,就像这样:
Department | Statistics
Purchasing : IntSummaryStatistics{count=1, sum=23, min=23, average=23.000000, max=23}
HR : IntSummaryStatistics{count=1, sum=28, min=28, average=28.000000, max=28}
IT : IntSummaryStatistics{count=3, sum=64, min=20, average=21.333333, max=22}apache的SummaryStatistics
如果想要一些复杂的统计,可以考虑apache的commons-math3的SummaryStatistics。
compile "org.apache.commons:commons-math3:3.5"SummaryStatistics 可计算数组中最小值,最大值,平均值,几何平均,和,平方和,标准差,方差
DescriptiveStatistics 计算数组中最小值,最大值,平均值,几何平均,和,平方和,标准差,方差,百分位数,偏态,峰度,中位数。
Frequency 统计列表中的某些数据出现的频次
@Test
public void should_calculate_summary() {
SummaryStatistics statistics = new SummaryStatistics();
personList.stream().forEach(p -> statistics.addValue(p.getAge()));
System.out.println(statistics);
System.out.printf("%30s: %30s\n", "统计项", "数据");
System.out.printf("%30s: %30s\n", "数据个数", statistics.getN());
System.out.printf("%30s: %30s\n", "最小值", statistics.getMin());
System.out.printf("%30s: %30s\n", "最大值", statistics.getMax());
System.out.printf("%30s: %30s\n", "平均值", statistics.getMean());
System.out.printf("%30s: %30s\n", "几何平均值", statistics.getGeometricMean());
System.out.printf("%30s: %30s\n", "方差", statistics.getVariance());
System.out.printf("%30s: %30s\n", "总体方差", statistics.getPopulationVariance());
System.out.printf("%30s: %30s\n", "二阶矩", statistics.getSecondMoment());
System.out.printf("%30s: %30s\n", "二阶矩", statistics.getSecondMoment());
System.out.printf("%30s: %30s\n", "平方和", statistics.getSumsq());
System.out.printf("%30s: %30s\n", "标准差", statistics.getStandardDeviation());
System.out.printf("%30s: %30s\n", "对数和", statistics.getSumOfLogs());
Frequency frequency = new Frequency();
personList.stream().forEach(p -> frequency.addValue(p.getAge()));
System.out.println(frequency);
DescriptiveStatistics descriptiveStatistics = new DescriptiveStatistics();
personList.stream().forEach(p -> descriptiveStatistics.addValue(p.getAge()));
System.out.println(descriptiveStatistics);
// SimpleRegression 线性模型最小二乘回归
// OLSMultipleLinearRegression和GLSMultipleLinearRegression:提供最小二乘回归拟合线性模型
// NaturalRanking:排名转换
// Covariance:协方差相关
}还有
SimpleRegression:线性模型最小二乘回归
OLSMultipleLinearRegression、GLSMultipleLinearRegression:提供最小二乘回归拟合线性模型。
NaturalRanking:排名转换。
Covariance:协方差相关
有兴趣的可以自己尝试下