爬虫实战 用matlab爬取链家房价 爬虫入门( 超详细!)
1. 我们首先进入广州链家网站观察其结构
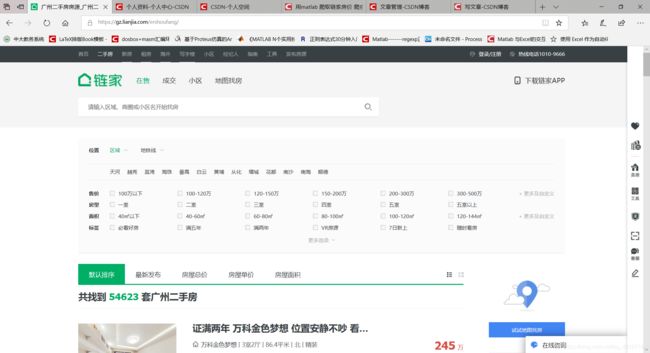 然后我们勾选需要组合的价格大小等,因为一种组合只能显示100页,一页最多30个选择,为了避免重复爬取数据,我们每一种类型都只勾选一种,得到下面的网址:
然后我们勾选需要组合的价格大小等,因为一种组合只能显示100页,一页最多30个选择,为了避免重复爬取数据,我们每一种类型都只勾选一种,得到下面的网址:
 我们可以发现 l 代表房型,a表示面积,p表示价格,pg表示页数,后面的数字表示选中的第几个,也可以多选
我们可以发现 l 代表房型,a表示面积,p表示价格,pg表示页数,后面的数字表示选中的第几个,也可以多选
2. 下一步我们选择一种组合方式查看网页源代码,观察需要的数据怎么提取
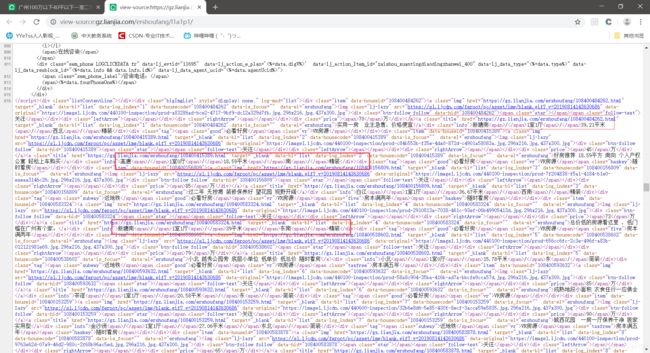 在中间找到信息的存放格式
在中间找到信息的存放格式
3. 下面以这个网页为例,找到需要的信息
Website='https://gz.lianjia.com/ershoufang/pg1l1a1p1/';
[source, state]=urlread(Website);
Site=string(regexp(source,'(?<=).*?(?=)','match')');
% 这个正则表达式的含义为将满足前面 为,后面为的字符串提取出来
详细介绍请看另一文章
输出结果:
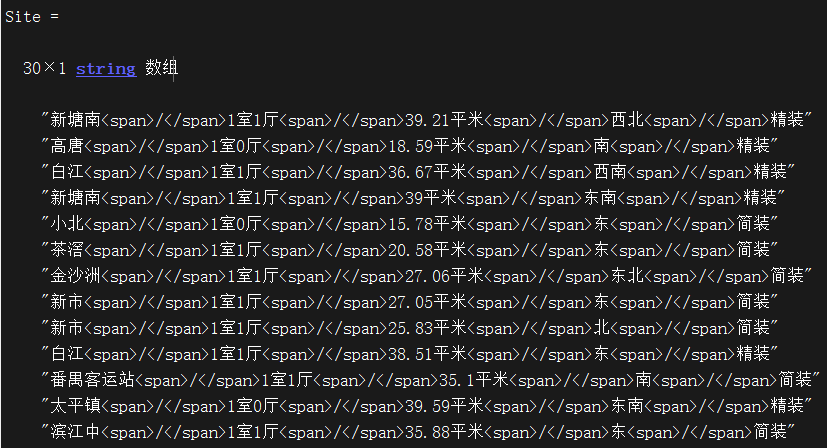
下面这段代码用于提取房子信息以及去除不符合条件的房子介绍,比如说里面会混入一些车位,这样会有一些属性没有,会导致后面的字符串矩阵维度错误,实现方式是判断每一套房子的属性的个数,将不等于5的房子去除,里面用到了cellfun函数,这个函数是向量化编程的一个重要函数,可以对元胞数组里面的元素分别使用某一函数,详细介绍请移步 cellfun介绍
aa=regexp(Site,'/','split');
haha=cell2mat(cellfun(@size ,aa,'UniformOutput',false));
haha=find(haha(:,2)~=5);
aa(haha)=[]
然后将aa按照属性排列
aa=reshape([aa{:}],5,length(aa))'
得到效果如下

至此,一页的大部分数据就已经全部取出来了,房价和单价都在aa中还没提取,下面爬取对房源的描述,这些属性可以存放到一个矩阵里面然后再一次全部写入Excel中
Describe=string(regexp(source,'(?<=" data-is_focus="" data-el="ershoufang">).*?(?=)','match')');
Describe=(regexp(Describe,'(?<=data-is_focus="" data-el="ershoufang">).*?','split'));
Describe=reshape([Describe{:}],2,length([Describe{:}])/2)';
Describe=Describe(:,2);
Describe(haha)=[]
结果如图:

需要注意的是,由于我们在前面过滤了不符合条件的房子,这里的房源描述也要根据前面的过滤结果进行过滤,但是有一个问题就是不是所有的房源都有描述,所以还需要自行调整。
Site=aa(:,1);
HouseType=string(aa(:,2));
HouseArea=string(aa(:,3));
Decoration=string(aa(:,5));
这里分别得到位置,房型,面积,装修
Average='(?<=data-price=")\d*\.?\d*?(?=">)';
Average=string(regexp(source,Average,'match')');
HousePrice='(?<=)\d*\.?\d*?(?=)';
HousePrice=string(regexp(source,HousePrice,'match')');
HousePrice(haha)=[];
Average(haha)=[];
同样用正则表达式提取出房价等信息,最后将数据进行整理准备写入
SS=[SS ;Site];
HT=[HT ;HouseType];
HA=[HA; HouseArea];
De=[De; Decoration];
HP=[HP; HousePrice] ;
Av=[ Av ;Average];
DB=[DB ;Describe];
Data=[ string('地址') string('房型') string('大小') string('装修') string('总价/万') string('单价/万');SS HT HA De HP Av;];
xlswrite('Data.xls',Data);

4. 下面是完整代码
Type='l'; %表示选中的房型
Area='a'; %表示选中的面积
Price='p'; % 表示选中的价格
% 顺序为 pg l a p,后面需要斜杠
SS=[];HT=[];HA=[];HP=[];De=[];Av=[];DB=[]; % 用于保存得到的数据
p=1:6
for l=1:6
for a=1:6
Website=['https://gz.lianjia.com/ershoufang/' 'pg1' Type num2str(l) Area num2str(a) Price num2str(p)];
[source, state]=urlread(Website);
if ~state
continue;
end
GetTotalPage='(?<="page-data=''{"totalPage":).*?(?=,"curPage)';
TotalPage=str2double(regexp(source,GetTotalPage,'match'));
if isempty(TotalPage)
continue;
end
for pg=1:TotalPage
Website=['https://gz.lianjia.com/ershoufang/' 'pg' num2str(pg) Type num2str(l) Area num2str(a) Price num2str(p)];
[source state]=urlread(Website);
if ~state
disp('爬取网页出错,当前序号:');
l
a
p
end
Site=string(regexp(source,'(?<=).*?(?=)','match')');
% aa 为数据集
try
aa=regexp(Site,'/','split');
haha=cell2mat(cellfun(@size ,aa,'UniformOutput',false));
haha=find(haha(:,2)~=5);
aa(haha)=[];
catch
continue;
end
try
aa=reshape([aa{:}],5,length(aa))';
catch
continue
end
Describe=string(regexp(source,'(?<=" data-is_focus="" data-el="ershoufang">).*?(?=)','match')');
Describe=(regexp(Describe,'(?<=data-is_focus="" data-el="ershoufang">).*?','split'));
Describe=reshape([Describe{:}],2,length([Describe{:}])/2)';
Describe=Describe(:,2);
Describe(haha)=[]; % 简介,标题
Site=aa(:,1);
HouseType=string(aa(:,2));
HouseArea=string(aa(:,3));
Decoration=string(aa(:,5));
clear aa;
Average='(?<=data-price=")\d*\.?\d*?(?=">)';
Average=string(regexp(source,Average,'match')');
HousePrice='(?<=)\d*\.?\d*?(?=)';
HousePrice=string(regexp(source,HousePrice,'match')');
HousePrice(haha)=[];
Average(haha)=[];
SS=[SS ;Site];
HT=[HT ;HouseType];
HA=[HA; HouseArea];
De=[De; Decoration];
HP=[HP; HousePrice] ;
Av=[ Av ;Average];
DB=[DB ;Describe];
end
end
end
end
Data=[ string('地址') string('房型') string('大小') string('装修') string('总价/万') string('单价/万');SS HT HA De HP Av;];
xlswrite('Data.xls',Data);
结果如下:
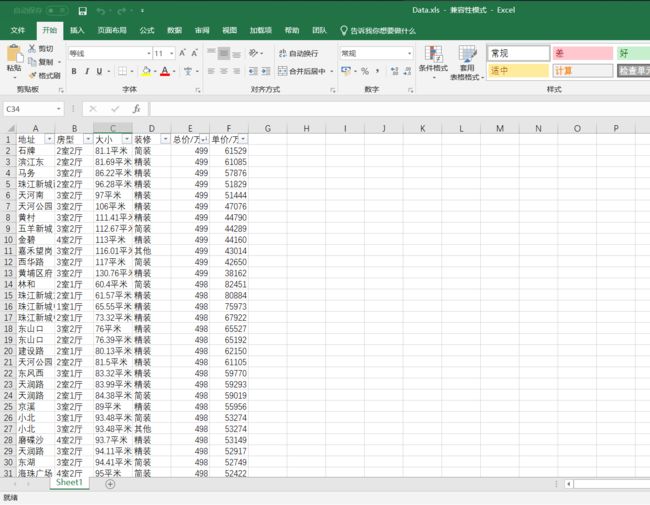
如果需要得到更美观的Excel表格请看matlab对Excel进行控制