使用IDEA 2019在windows 10 上连接远程hadoop集群(虚拟机)开发MapReduce
0 前序
暑假期间参加了一个关于大数据的培训,当时用培训老师给出的相关软件实验了一遍,感觉收获很大,回到学校后在更新的版本中又实现了一遍,这里主要就在新版本中的一些环境配置做些笔记,供自己后续实践参考,有些步骤可能会多余,但由于是初学,也就只能在自己掌握的情况下做些调整。
在前期的CentOS中集群环境下的hadoop 3.2 配置中没有碰到过多的问题,主要的一个就是jdk的选择问题,之前选的最新版本jdk12,配置中出现一些问题,查了资料后有一篇文章中写到在jdk 9 以上的环境要如何操作等等,自己按文中提供的方法操作后还是有问题,遂放弃。后来看到Java 版本选择问题中有如下内容,
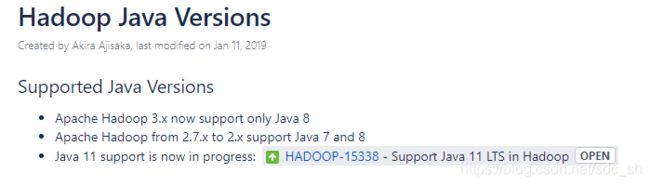
因此还是老老实实的用回 java 8 , 选用的是jdk-8u221-linux-x64.tar.gz, 解压安装简单的配置后hadoop启动正常。
1. windows 下 JAVA访问HDFS
1)windows下hadoop的安装
关于在windows 下通过java访问hdfs中hadoop的安装配置,自己不是很理解,感觉把下载的hadoop-3.2.0 解压到windows中某个目录后,添加2个文件,没有其它的配置就可以用了,windows中hadoop起的作用不是很清楚,后续有时间再摸索。
hadoop 3.2.0 的解压
在windows下把hadoop-3.2.0.tar.gz解压到相应目录(个人习惯在D:\Program Files\)。在解压过程中会碰到如下错误:
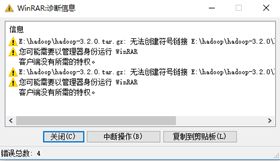 hadoop-3.2.0.tar.gz解压错误
hadoop-3.2.0.tar.gz解压错误
解决方法,在cmd中使用解压命令:start winrar x -y hadoop-3.2.0.tar.gz,如果是解压在其它地方,后面在复制到其它目录,则会出现“文件名对目标文件夹可能太长”类似错误,这个错误主要发生在复制,剪切的时候。解决方法为,直接拷贝到目标目录,然后直接解压到当前目录即可。
2)创建项目时用到的lib库
根据java程序的功能不同,需要的库会略有不同,基本上是“hadoop-3.2.0\share\hadoop”下Common目录下的“hadoop-common-3.2.0.jar,hadoop-kms-3.2.0.jar,hadoop-nfs-3.2.0.jar”,以及该目录下的lib文件夹下的所有文件,加上实际功能的lib,比如访问hdfs,则再加上“hadoop-3.2.0\share\hadoop”下hdfs目录下的jar包以及lib下的所有文件。在创建的工程中按下面步骤操作:
-
a) idea工程中新建目录lib
-
b) 将之前准备的jar包拷贝到工程的lib目录中
-
c) lib目录右键 Add as Library
这种方法是每个工程都需要重复这个操作,使得最后的工程文件夹比较大,个人倾向于另一种操作方法。可参考:Hadoop Intellij IDEA本地开发环境搭建。
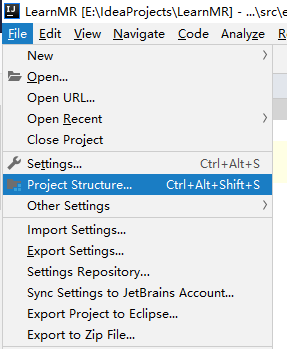
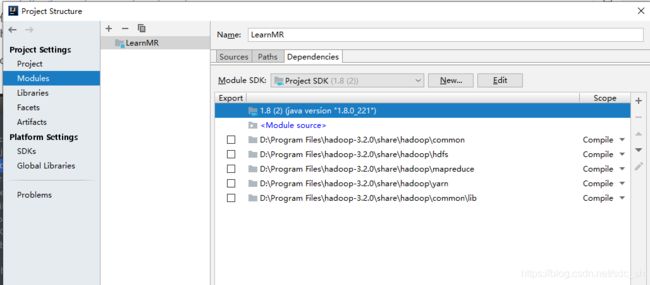
打开Project Structure ... (File--> Project Structure, IntelliJ IDEA 2019版),把windows 环境下hadoop share下的相关的jar导入(Modules --> Dependencies),
3) 获取hadoop.dll和 winutils.exe
在github.com上搜索与Hadoop版本对应的hadoop.dll和 winutils.exe, https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.0/bin 下载hadoop.dll和winutils.exe, 然后复制到 D:\Program Files\hadoop-3.2.0\bin目录下,同时把hadoop.dll 复制到System32/SysWOW64。
至此,环境配置就完成了,接下来可以编写源代码了。
4)运行wordcount MapReduce实例。
根据各自的编程习惯组织源码结构,本人的目录结构如下:(代码是参照培训时代码,根据自己的命名习惯略有改动)
分别输入相应代码:
4-1. WordCountMapper.java
package edu.gnnu.mapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//super.map(key, value, context);
//获取读取到的每一行数据
String line = value.toString();
//通过空格进行分割
String[] words = line.split(" ");
//将初步处理的结果进行输出
for (String word: words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
4-2 WordCountReducer.java
package edu.gnnu.reducer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//super.reduce(key, values, context);
Integer count = 0;
for(IntWritable value: values){
//将每一个分组中的数据进行累加计数
count += value.get();
}
//将最终结果进行输出
context.write(key, new IntWritable(count));
}
}
4-3 WordCountMaster.java
package edu.gnnu.master;
import edu.gnnu.mapper.WordCountMapper;
import edu.gnnu.reducer.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMaster {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//初始化配置
System.setProperty("hadoop.home.dir","D:\\Program Files\\Hadoop-3.2.0");
String Hadoop_Url = "hdfs://192.168.80.128:9000/";
Configuration conf = new Configuration();
//初始化job参数,指定job名称
Job job = Job.getInstance(conf,"WordCount");
//设置运行job的类
job.setJarByClass(WordCountMaster.class);
//设置Mapper类
job.setMapperClass(WordCountMapper.class);
//设置Reducer类
job.setReducerClass(WordCountReducer.class);
//设置Map的输出数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Reducer的输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输出的路径
FileInputFormat.setInputPaths(job, new Path(Hadoop_Url+"input/wordCount"));
//设置输出的路径
FileOutputFormat.setOutputPath(job, new Path(Hadoop_Url+"output/wordCount/1"));
//提交job
boolean result = job.waitForCompletion(true);
//执行成功后进行后续操作
if (result) {
System.out.println("Congratulations!");
}
}
}
运行代码前需要一些准备工作,比如 /input/wordCount目录要存在,并且要把相应的数据文件复制过去。
5)错误输出及原因
之前配置好了后运行没有问题,重启机器后再次运行出现如下错误。
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:645)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:1230)
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:160)
at org.apache.hadoop.util.DiskChecker.checkDirInternal(DiskChecker.java:100)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:77)
at org.apache.hadoop.util.BasicDiskValidator.checkStatus(BasicDiskValidator.java:32)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:331)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:394)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:165)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:146)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:130)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:123)
at org.apache.hadoop.mapred.LocalJobRunner$Job.
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:794)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:251)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1570)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1567)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1567)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1588)
at edu.gnnu.master.WordCountMaster.main(WordCountMaster.java:49)
Process finished with exit code 1
google搜索后发现也有类似的问题,重启IntelliJ IDEA 后运行正常。