python 基础学习总结
文章目录
- 基本语法(python基础)
- 算数运算符
- 变量命名
- 数据类型
- 整数和浮点数
- 布尔型运算符、比较运算符和逻辑运算符
- 字符串
- 字符串格式化format
- .format方法
- format方法使用例子
- format函数
- 列表
- 列表函数
- 元组
- 集合(set)
- 字典
- 字典遍历
- 字典删除
- 字典设置默认值
- 字的视图
- 字典格式化字符串
- 复合数据结构
- 控制流
- If 语句
- 缩进
- 循环
- Zip 和 Enumerate
- zip
- Enumerate
- 列表推导式(列表生成式)
- 函数
- 函数头部
- 函数主体
- 函数的命名规范
- 默认参数
- 文档(注释)
- 函数使用技巧:
- Lambda 表达式
- filter函数
- map函数
- reduce函数
- 迭代器和生成器
- 模块
- 包
- 标准模块
- 类和对象
- 虚拟环境
- 脚本编写
- 在脚本中接受原始输入
- 处理错误
- 读写文件
- 读取文件
- 写入文件
- 导入本地脚本
- 导入模块技巧
- 模块、软件包和名称
- 第三方库
- 实用的第三方软件包
- 在线资源的优先级
基本语法(python基础)
以下为Udacity及慕课网中PYTHON入门课程总结。
算数运算符
特殊之处:
1 取幂符号:**
2 //是相除后向下取整
变量命名
1 变量名称中使用常规字母、数字和下划线。不能包含空格,并且需要以字母或下划线开头
2 不能使用保留字或内置标识符
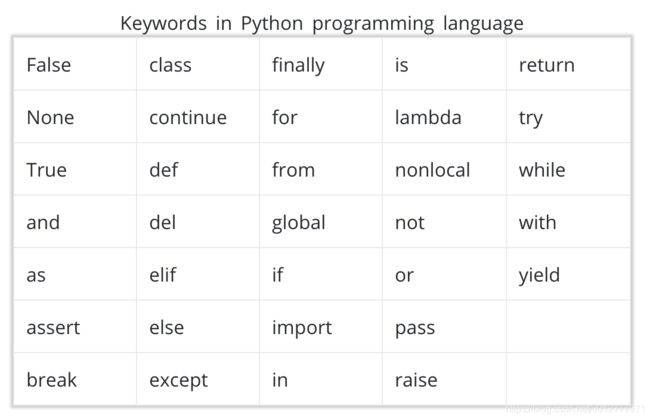
数据类型
整数和浮点数
数字值可以用到两种 python 数据类型:
int - 表示整数值
float - 表示小数或浮点数值
可以通过以下语法创建具有某个数据类型的值:
x = int(4.7) # x is now an integer 4
y = float(4) # y is now a float of 4.0
可以使用函数 type 检查数据类型:
>>> print(type(x))
int
布尔型运算符、比较运算符和逻辑运算符
布尔数据类型存储的是值 True 或 False,通常分别表示为 1 或 0。
比较运算符
符号使用情况 布尔型 运算符
5 < 3 False 小于
5 > 3 True 大于
3 <= 3 True 小于或等于
3 >= 5 False 大于或等于
3 == 5 False 等于
3 != 5 True 不等于
三个逻辑运算符
逻辑使用情况 布尔型 运算符
5 < 3 and 5 == 5 False 检查提供的所有语句是否都为 True
5 < 3 or 5 == 5 True 检查是否至少有一个语句为 True
not 5 < 3 True 翻转布尔值
字符串
在 python 中,字符串的变量类型显示为 str。你可以使用双引号 " 或单引号 ’ 定义字符串。如果你要创建的字符串包含其中一种引号,你需要确保代码不会出错。
>>> my_string = 'this is a string!'
>>> my_string2 = "this is also a string!!!"
你还可以在字符串中使用 \,以包含其中一种引号:
>>> this_string = 'Simon\'s skateboard is in the garage.'
>>> print(this_string)
Simon's skateboard is in the garage.
你可以对字符串执行其他多种操作。如
>>> first_word = 'Hello'
>>> second_word = 'There'
>>> print(first_word + second_word)
HelloThere
>>> print(first_word + ' ' + second_word)
Hello There
>>> print(first_word * 5)
HelloHelloHelloHelloHello
>>> print(len(first_word))
5
你还可以使用字符串索引
>>> first_word[0]
H
>>> first_word[1]
e
你可以更改变量类型以执行各种不同的操作。例如
>>>"0" + "5"
>>>0 + 5
>>>"0" + 5
>>>0 + "5"
字符串函数通过使用小括号接收一个参数,如len(),type(),print()
此外,字符串还有诸多方法可以使用,python 中的方法和函数相似,但是它针对的是你已经创建的变量。方法与特定变量中的数据类型相关。 方法相当于通过.来调用的一种函数。例如,lower()是一个字符串方法,对于一个叫 “sample string” 的字符串,它可以这样使用:sample_string.lower()。

每个方法都接受字符串本身作为该方法的第一个参数。但是,它们还可以接收其他参数。我们来看看几个示例的输出。
>>> my_string.islower()
True
>>> my_string.count('a')
2
>>> my_string.find('a')
3
字符串格式化format
.format方法
Format strings contain “replacement fields” surrounded by curly braces {}. Anything that is not contained in braces is considered literal text, which is copied unchanged to the output. If you need to include a brace character in the literal text, it can be escaped by doubling: {{ and }}.
“replacement fields"的语法如下图:

The field_name is optionally followed by a conversion field, which is preceded by an exclamation point ‘!’, and a format_spec, which is preceded by a colon ‘:’. 即conversion和format_spec是非强制可选项。
The field_name itself begins with an arg_name that is either a number or a keyword. If it’s a number, it refers to a positional argument, and if it’s a keyword, it refers to a named keyword argument. If the numerical arg_names in a format string are 0, 1, 2, … in sequence, they can all be omitted (not just some) and the numbers 0, 1, 2, … will be automatically inserted in that order. The arg_name can be followed by any number of index or attribute expressions. An expression of the form ‘.name’ selects the named attribute using getattr(), while an expression of the form ‘[index]’ does an index lookup using getitem(). 即arg_name处可以是数值或者关键字,如果是顺序排列的数值(0,1,2…)则可以省略。arg_name后可以跟”.name"来提取arg的属性值(比如arg是某个具有属性的类的实例),也可以跟[索引]提取arg索引位置的值(比如arg是列表)。

The conversion field causes a type coercion before formatting. Normally, the job of formatting a value is done by the format() method of the value itself. However, in some cases it is desirable to force a type to be formatted as a string, overriding its own definition of formatting. By converting the value to a string before calling format(), the normal formatting logic is bypassed.
Three conversion flags are currently supported: ‘!s’ which calls str() on the value, ‘!r’ which calls repr() and ‘!a’ which calls ascii().

The format_spec field contains a specification of how the value should be presented, including such details as field width, alignment, padding, decimal precision and so on.
format方法使用例子

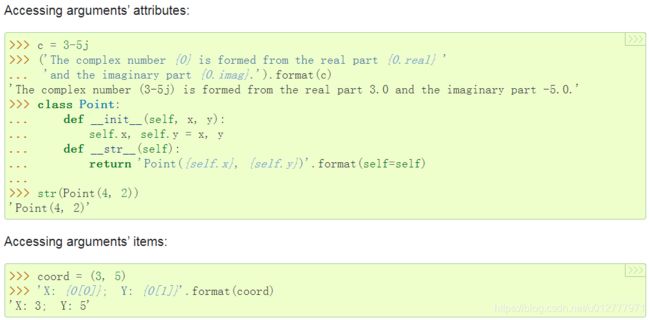


A format_spec field can also include nested replacement fields within it. These nested replacement fields may contain a field name, conversion flag and format specification, but deeper nesting is not allowed. The replacement fields within the format_spec are substituted before the format_spec string is interpreted. This allows the formatting of a value to be dynamically specified.即format_spec可以嵌套replacement field使用,实现format_spec动态更新。
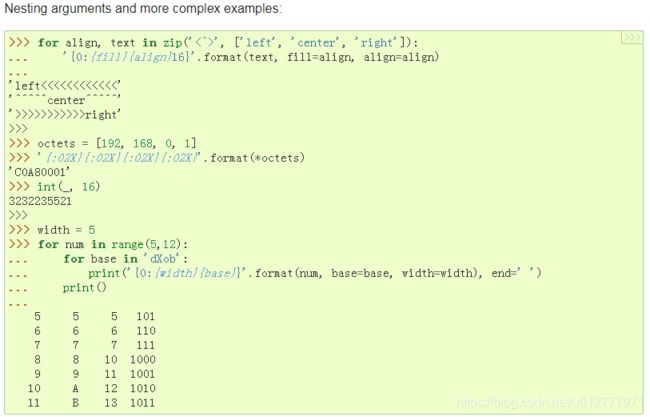
format函数


列表
你可以使用方括号创建列表。列表可以包含我们到目前为止所学的任何数据类型并且可以混合到一起。
lst_of_random_things = [1, 3.4, 'a string', True]
这是一个包含 4 个元素的类别。在 python 中,所有有序容器(例如列表)的起始索引都是 0。因此,要从上述列表中获取第一个值,我们可以编写以下代码:
>>> lst_of_random_things[0]
1
我们可以使用切片功能从列表中提取多个值。在使用切片功能时,务必注意,下限索引包含在内,上限索引排除在外。
>>> lst_of_random_things = [1, 3.4, 'a string', True]
>>> lst_of_random_things[1:2]
[3.4]
如果你要从列表的开头开始,也可以省略起始值。
>>> lst_of_random_things[:2]
[1, 3.4]
或者你要返回到列表结尾的所有值,可以忽略最后一个元素。
>>> lst_of_random_things[1:]
[3.4, 'a string', True]
我们还可以使用 in 和 not in 返回一个布尔值,表示某个元素是否存在于列表中,或者某个字符串是否为另一个字符串的子字符串。
>>> 'this' in 'this is a string'
True
>>> 'in' in 'this is a string'
True
>>> 'isa' in 'this is a string'
False
>>> 5 not in [1, 2, 3, 4, 6]
True
>>> 5 in [1, 2, 3, 4, 6]
False
可变性是指对象创建完毕后,我们是否可以更改该对象。
>>> my_lst = [1, 2, 3, 4, 5]
>>> my_lst[0] = 'one'
>>> print(my_lst)
['one', 2, 3, 4, 5]
列表是可变的,字符串是不可变的,意味着如果要更改该字符串,你需要创建一个全新的字符串。
字符串和列表都是有序的。
列表函数
len() 返回列表中的元素数量。
max() 返回列表中的最大元素。最大元素的判断依据是列表中的对象类型。数字列表中的最大元素是最大的数字。字符串列表中的最大元素是按照字母顺序排序时排在最后一位的元素。因为 max() 函数的定义依据是大于比较运算符。如果列表包含不同的无法比较类型的元素,则 max() 的结果是 undefined。
min() 返回列表中的最小元素。它是 max() 函数的对立面,返回列表中的最小元素。
sorted() 返回一个从最小到最大排序的列表副本,并使原始列表保持不变。

删除列表多个元素,将对应的slice置为空列表。
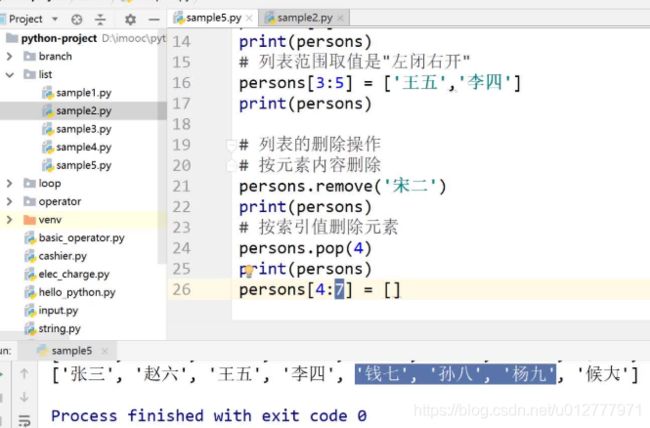
join方法
Join 是一个字符串方法,将字符串列表作为参数,并返回一个由列表元素组成并由分隔符字符串分隔的字符串。
new_str = "\n".join(["fore", "aft", "starboard", "port"])
print(new_str)
fore
aft
starboard
port
name = "-".join(["García", "O'Kelly"])
print(name)
García-O'Kelly
请务必注意,用英文逗号 (,) 将要连接的列表中的每项分隔开来。忘记分隔的话,不会触发错误,但是会产生意外的结果。
append方法
letters = ['a', 'b', 'c', 'd']
letters.append('z')
print(letters)
['a', 'b', 'c', 'd', 'z']
注意:append函数没有return任何参数,所以x=a.append(3)运行结果是x为none。
copy方法
copy用于对原有列表进行复制并创建一个新列表,与元列表地址不一致。
person = [1,2,3]
person1 = person.copy()
person2 = person
print(person1 is person)
print(person2 is person)
输出为:
False
True
range() & zip()
range和zip返回的是object 在内存中的地址。
names_and_heights = zip(names, heights)
print(names_and_heights)
输出为:
可以使用list()将其转换为列表。
元组
元组是另一个实用容器。它是一种不可变有序元素数据类型。通常用来存储相关的信息。请看看下面这个关于纬度和经度的示例:
location = (13.4125, 103.866667)
print("Latitude:", location[0])
print("Longitude:", location[1]
元组和列表相似,它们都存储一个有序的对象集合,并且可以通过索引访问这些对象。但是与列表不同的是,元组不可变,你无法向元组中添加项目或从中删除项目,或者直接对元组排序。
元组还可以用来以紧凑的方式为多个变量赋值。
dimensions = 52, 40, 100
length, width, height = dimensions
print("The dimensions are {} x {} x {}".format(length, width, height))
在定义元组时,小括号是可选的,如果小括号并没有对解释代码有影响,程序员经常会忽略小括号。
在第二行,我们根据元组 dimensions 的内容为三个变量赋了值。这叫做元组解包。你可以通过元组解包将元组中的信息赋值给多个变量,而不用逐个访问这些信息,并创建多个赋值语句。
如果我们不需要直接使用 dimensions,可以将这两行代码简写为一行,一次性为三个变量赋值!
length, width, height = 52, 40, 100
print("The dimensions are {} x {} x {}".format(length, width, height))
元祖不允许对元素进行修改。但是如果元祖元素为列表,则可对该列表进行修改。
元祖支持元祖运算符(加减乘除,同列表)创建新元祖。
创建单元素元祖不能忘记逗号。




集合(set)
集合是一个包含唯一元素的可变无序集合数据类型。集合的一个用途是快速删除列表中的重复项。集合是python中的内置数据结构。集合可以看作没有value的字典。
创建空集合:set()



numbers = [1, 2, 6, 3, 1, 1, 6]
unique_nums = set(numbers)
print(unique_nums)
输出为:
{1, 2, 3, 6}
集合和列表一样支持 in 运算符。和列表相似,你可以使用 add 方法将元素添加到集合中,并使用 pop 方法删除元素。但是,当你从集合中拿出元素时,会随机删除一个元素。注意和列表不同,集合是无序的,因此没有“最后一个元素”。
fruit = {"apple", "banana", "orange", "grapefruit"} # define a set
print("watermelon" in fruit) # check for element
fruit.add("watermelon") # add an element
print(fruit)
print(fruit.pop()) # remove a random element
print(fruit)
输出为:
False
{'grapefruit', 'orange', 'watermelon', 'banana', 'apple'}
grapefruit
{'orange', 'watermelon', 'banana', 'apple'}
集合可以使用for循环遍历
集合不支持索引取数据
集合支持成员函数,in
集合新增数据
add,一次新增一个元素,若元素已存在则忽略
update,一次添加多个元素
集合删除元素
remove,删除不存在元素时报错退出程序
discard,删除不存在元素时忽略操作继续执行
集合替换元素:先删除再添加
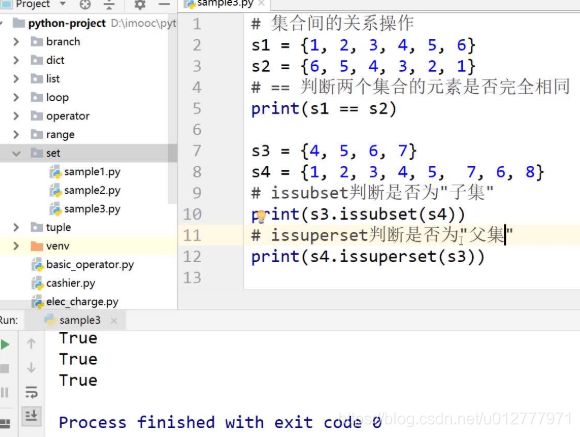
集合间关系操作
判断是否相等:==
issubset
issupperset
isdisjoint (True代表不存在重复元素)
字典
字典是可变数据类型,其中存储的是唯一键到值的映射。下面是存储元素和相应原子序数的字典。
elements = {"hydrogen": 1, "helium": 2, "carbon": 6}


列表为有序存储,且存储在连续区域,按索引值访问;
字典为无需存储,按hash值进行存储,按键值访问,访问速度极快。
字典的键可以是任何不可变类型,例如整数或元组,而不仅仅是字符串。甚至每个键都不一定要是相同的类型!我们可以使用方括号并在括号里放入键,查询字典中的值或向字典中插入新值。
print(elements["helium"]) # print the value mapped to "helium"
elements["lithium"] = 3 # insert "lithium" with a value of 3 into the dictionary
我们可以像检查某个值是否在列表或集合中一样,使用关键字 in 检查值是否在字典中。字典有一个也很有用的相关方法,叫做 get。get 会在字典中查询值,但是和方括号不同,如果没有找到键,get 会返回 None(或者你所选的默认值)。
print("carbon" in elements)
print(elements.get("dilithium"))
输出:
True
None
Carbon 位于该字典中,因此输出 True。Dilithium 不在字典中,因此 get 返回 None,然后系统输出 None。如果你预计查询有时候会失败,get 可能比普通的方括号查询更合适,因为错误可能会使程序崩溃。
创建空字典: dic1 = {}
字典遍历

字典删除

字典设置默认值
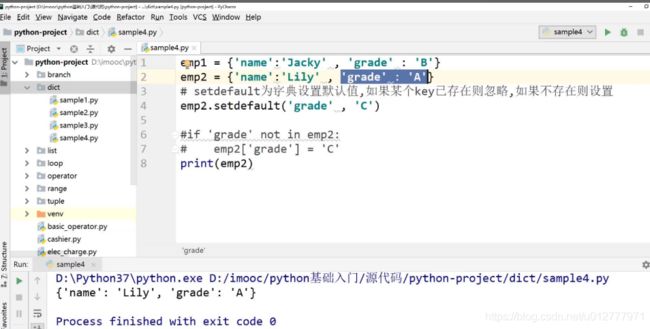
字的视图
字典的视图
用处:字典的视图对象随字典内容变化而变化
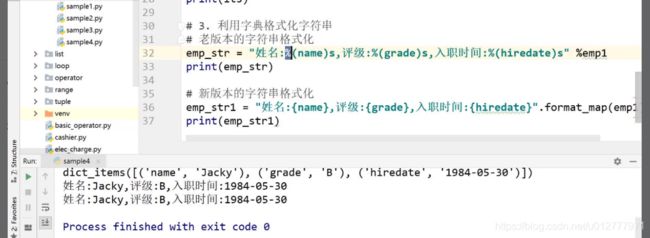
字典格式化字符串
恒等运算符
关键字 运算符
is 检查两边是否恒等,即两边元素内存地址是否一致。
is not 检查两边是否不恒等
复合数据结构
我们可以在其他容器中包含容器,以创建复合数据结构。例如,下面的字典将键映射到也是字典的值!
elements = {"hydrogen": {"number": 1,
"weight": 1.00794,
"symbol": "H"},
"helium": {"number": 2,
"weight": 4.002602,
"symbol": "He"}}
我们可以如下所示地访问这个嵌套字典中的元素。
helium = elements["helium"] # get the helium dictionary
hydrogen_weight = elements["hydrogen"]["weight"] # get hydrogen's weight
控制流
If 语句
if season == 'spring':
print('plant the garden!')
elif season == 'summer':
print('water the garden!')
elif season == 'fall':
print('harvest the garden!')
elif season == 'winter':
print('stay indoors!')
else:
print('unrecognized season')
缩进
一些其他语言使用花括号来表示代码块从哪开始,从哪结束。在 Python 中,我们使用缩进来封装代码块。例如,if 语句使用缩进告诉 Python 哪些代码位于不同条件语句里面,哪些代码位于外面。
循环
Python 有两种类型的循环:for 循环和 while 循环。for 循环用来遍历可迭代对象。
可迭代对象是每次可以返回其中一个元素的对象,包括字符串、列表和元组等序列类型,以及字典和文件等非序列类型。你还可以使用迭代器和生成器定义可迭代对象
# iterable of cities
cities = ['new york city', 'mountain view', 'chicago', 'los angeles']
# for loop that iterates over the cities list
for city in cities:
print(city.title())
cities = ['new york city', 'mountain view', 'chicago', 'los angeles']
for index in range(len(cities)):
cities[index] = cities[index].title()
For 循环是一种“有限迭代”,意味着循环主体将运行预定义的次数。这与“无限迭代”循环不同,无限迭代循环是指循环重复未知次数,并在满足某个条件时结束,while 循环正是这种情况。下面是一个 while 循环的示例。
card_deck = [4, 11, 8, 5, 13, 2, 8, 10]
hand = []
# adds the last element of the card_deck list to the hand list
# until the values in hand add up to 17 or more
while sum(hand) <= 17:
hand.append(card_deck.pop())
有时候我们需要更精准地控制何时循环应该结束,或者跳过某个迭代。在这些情况下,我们使用关键字 break 和 continue,这两个关键字可以用于 for 和 while 循环。
break 使循环终止
continue 跳过循环的一次迭代
Zip 和 Enumerate
zip 和 enumerate 是实用的内置函数,可以在处理循环时用到。
zip
zip 返回一个将多个可迭代对象组合成一个元组序列的迭代器。每个元组都包含所有可迭代对象中该位置的元素。例如,
list(zip([‘a’, ‘b’, ‘c’], [1, 2, 3])) 将输出 [(‘a’, 1), (‘b’, 2), (‘c’, 3)].
letters = ['a', 'b', 'c']
nums = [1, 2, 3]
for letter, num in zip(letters, nums):
print("{}: {}".format(letter, num))
除了可以将两个列表组合到一起之外,还可以使用星号拆分列表。
some_list = [('a', 1), ('b', 2), ('c', 3)]
letters, nums = zip(*some_list)
这样可以创建正如之前看到的相同 letters 和 nums 列表。
Enumerate
enumerate 是一个会返回元组迭代器的内置函数,这些元组包含列表的索引和值。当你需要在循环中获取可迭代对象的每个元素及其索引时,将经常用到该函数。
letters = ['a', 'b', 'c', 'd', 'e']
for i, letter in enumerate(letters):
print(i, letter)
输出:
0 a
1 b
2 c
3 d
4 e
列表推导式(列表生成式)
在 Python 中,你可以使用列表推导式快速简练地创建列表。下面是之前的一个示例:
capitalized_cities = []
for city in cities:
capitalized_cities.append(city.title())
可以简写为:
capitalized_cities = [city.title() for city in cities]
你还可以向列表推导式添加条件语句。在可迭代对象之后,你可以使用关键字 if 检查每次迭代中的条件。
squares = [x**2 for x in range(9) if x % 2 == 0]
上述代码将 squares 设为等于列表 [0, 4, 16, 36, 64],因为仅在 x 为偶数时才评估 x 的 2 次幂。如果你想添加 else,将遇到语法错误。
如果你要添加 else,则需要将条件语句移到列表推导式的开头,直接放在表达式后面,如下所示。
squares = [x**2 if x % 2 == 0 else x + 3 for x in range(9)]
列表推导式并没有在其他语言中出现,但是在 python 中很常见。


函数
def cylinder_volume(height, radius):
pi = 3.14159
return height * pi * radius ** 2
cylinder_volume(10, 3)
函数定义包含几个重要部分。
函数头部
我们从函数头部开始,即函数定义的第一行。
函数头部始终以关键字 def 开始,表示这是函数定义。
然后是函数名称(在此例中是 cylinder_volume,因为函数名是要一个单词,所以需要用_进行连接),遵循的是和变量一样的命名规范。你可以在本页面下方回顾下命名规范。
名称之后是括号,其中可能包括用英文逗号分隔的参数(在此例中是 height 和 radius)。形参(或实参)是当函数被调用时作为输入传入的值,用在函数主体中。如果函数没有参数,这些括号留空。
头部始终以英文冒号 : 结束。
函数主体
函数的剩余部分包含在主题中,也就是函数完成操作的部分。
函数主体是在头部行之后缩进的代码。在此例中是定义 π 和返回体积的两行代码。
在此主体中,我们可以引用参数并定义新的变量,这些变量只能在这些缩进代码行内使用。
主体将经常包括 return 语句,用于当函数被调用时返回输出值。return 语句包括关键字 return,然后是经过评估以获得函数输出值的表达式。如果没有 return 语句,函数直接返回 None(例如内置 print() 函数)。
函数的命名规范
函数名称遵守和变量一样的命名规范。
默认参数
我们可以向函数中添加默认参数,以便为在函数调用中未指定的参数提供默认值。
def cylinder_volume(height, radius=5):
pi = 3.14159
return height * pi * radius ** 2
在上述示例中,如果在函数调用中忽略了 radius,则将该参数设为 5。如果我们调用 cylinder_volume(10),该函数将使用 10 作为高度,使用 5 作为半径。但是,如果调用 cylinder_volume(10, 7),7 将覆盖默认的值 5。
此外注意,我们按照位置向参数传递值。可以通过两种方式传递值:按照位置和按照名称。下面两个函数的效果是一样的。
cylinder_volume(10, 7) # pass in arguments by position
cylinder_volume(height=10, radius=7) # pass in arguments by name
在函数中使用变量时,务必要考虑作用域。如果变量是在函数内创建的,则只能在该函数内使用该变量。你无法从该函数外面访问该变量。
文档(注释)
文档使代码更容易理解和使用。函数尤其容易理解,因为它们通常使用文档字符串,简称 docstrings。文档字符串是一种注释,用于解释函数的作用以及使用方式。下面是一个包含文档字符串的人口密度函数。
def population_density(population, land_area):
"""Calculate the population density of an area. """
return population / land_area
文档字符串用三个引号引起来,第一行简要解释了函数的作用。如果你觉得信息已经足够了,可以在文档字符串中只提供这么多的信息;一行文档字符串完全可接受,如上述示例所示。
def population_density(population, land_area):
"""Calculate the population density of an area.
INPUT:
population: int. The population of that area
land_area: int or float. This function is unit-agnostic, if you pass in values in terms
of square km or square miles the function will return a density in those units.
OUTPUT:
population_density: population / land_area. The population density of a particular area.
"""
return population / land_area
如果你觉得需要更长的句子来解释函数,可以在一行摘要后面添加更多信息。在上述示例中,可以看出我们对函数的参数进行了解释,描述了每个参数的作用和类型。我们经常还会对函数输出进行说明。
文档字符串的每个部分都是可选的。但是,提供文档字符串是一个良好的编程习惯。
函数使用技巧:
1.序列传参:fun(*list)
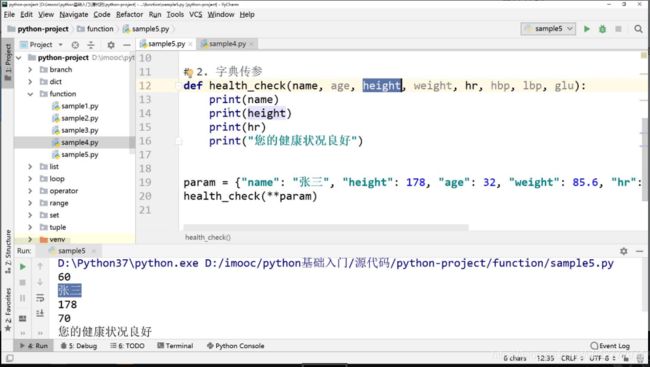
2.字典传参:fun(**dict)
Lambda 表达式
你可以使用 Lambda 表达式创建匿名函数,即没有名称的函数。lambda 表达式非常适合快速创建在代码中以后不会用到的函数。尤其对高阶函数或将其他函数作为参数的函数来说,非常实用。
我们可以使用 lambda 表达式将以下函数
def multiply(x, y):
return x * y
简写为:
double = lambda x, y: x * y
Lambda 函数的组成部分
关键字 lambda 表示这是一个 lambda 表达式。
lambda 之后是该匿名函数的一个或多个参数(用英文逗号分隔),然后是一个英文冒号 :。和函数相似,lambda 表达式中的参数名称是随意的。
最后一部分是被评估并在该函数中返回的表达式,和你可能会在函数中看到的 return 语句很像。
filter函数

map函数

当map()函数中传入的列表多于一个时,map()函数可以并行执行,以下代码执行结果为:[33,55] ---->[9, 25]
rest = map(lambda x, y: x*y, [3, 5], [3, 5])
print(list(rest))
reduce函数

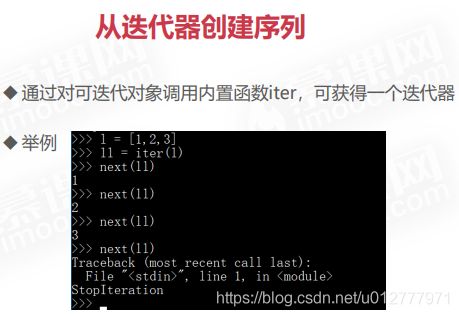
迭代器和生成器
迭代器是每次可以返回一个对象元素的对象,例如返回一个列表。我们到目前为止使用的很多内置函数(例如 enumerate)都会返回一个迭代器。
迭代器是一种表示数据流的对象。这与列表不同,列表是可迭代对象,但不是迭代器,因为它不是数据流。
生成器是使用函数创建迭代器的简单方式。
下面是一个叫做 my_range 的生成器函数,它会生成一个从 0 到 (x - 1) 的数字流。
def my_range(x):
i = 0
while i < x:
yield i
i += 1
注意,该函数使用了 yield 而不是关键字 return。这样使函数能够一次返回一个值,并且每次被调用时都从停下的位置继续。
关键字 yield 是将生成器与普通函数区分开来的依据。
注意,因为这段代码会返回一个迭代器,因此我们可以将其转换为列表或用 for 循环遍历它,以查看其内容。例如,下面的代码:
for x in my_range(5):
print(x)
生成器的优劣势:
生成器是构建迭代器的 “懒惰” 方式。当内存不够存储完整实现的列表时,或者计算每个列表元素的代价很高,你希望尽量推迟计算时,就可以使用生成器。但是这些元素只能遍历一次。
由于使用生成器是一次处理一个数据,在内存和存储的需求上会比使用list方式直接全部生成再存储节省很多资源。
由此区别,在处理大量数据时,经常使用生成器初步处理数据后,再进行长期存储,而不是使用 list。因为无论使用生成器还是 list,都是使用过就要丢弃的临时数据。既然功能和结果一样,那就不如用生成器。
但是生成器也有自己的局限,它产生的数据不能回溯,不像list可以任意选择。



模块
模块就是程序,模块名就是不含.py后缀的文件名。

模块的优点:可维护性更强,且方便代码重用。

包




注:点(.)指的是同级目录,点点(…)指的是父级目录。
from . import XXX指的是在当前文件同级目录下寻找制定模块或者包XXX导入。
标准模块


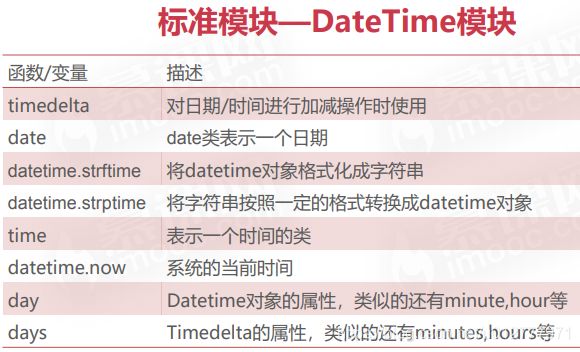
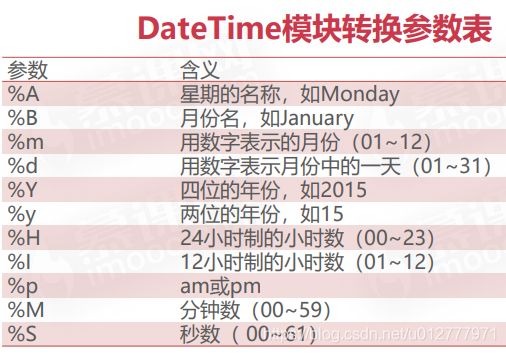
datetime对象之间加减操作
timedelta
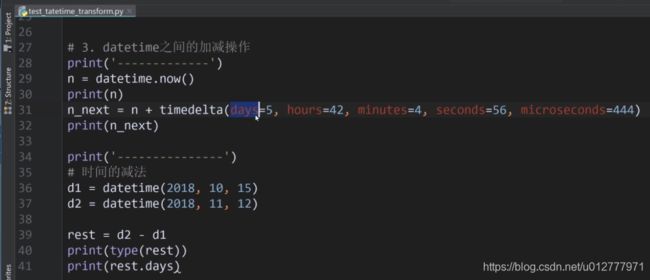
日期、时间与字符串制件转换
1.字符串转换datetime对象
datetime.strptime
分隔符/及T可以修改为其它,只要格式化要求同步即可;
2.datetime对象转换字符串
strftime
格式化要求可以年月日时分秒局部提取转化
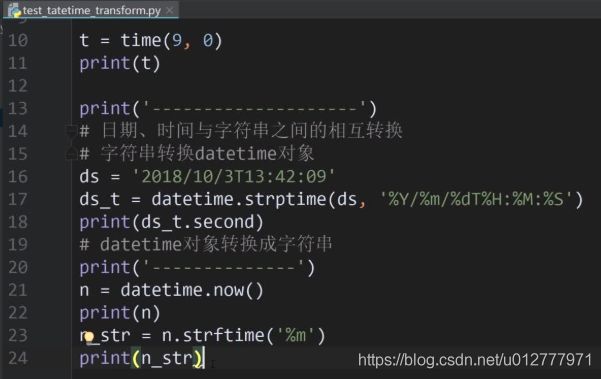
自定义时间
1.datetime 自定义日期加时间
2.date 自定义日期
3.time 自定义时间

类和对象







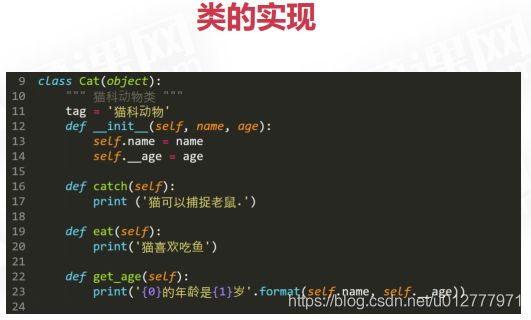





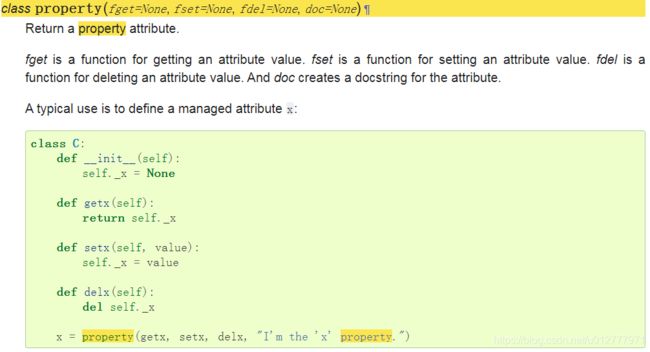
property类和@property装饰器

slots__为指定的类设定一个静态属性列表
slots__定义的属性, 方法仅对当前类起作用,对继承的子类是不起作用的, 如果子类中也定义__slots,那么子类允许定义的属性,方法就是自身的__slots__加上父类的__slots。 即如果子类没有slots则不会继承父类的slots,如果子类有slots,则在当前限制的属性下还要继承父类的slots




虚拟环境
virtualenv
pipenv
脚本编写
Python 是一种“脚本语言”。脚本,对应的英文是:script。一般人看到script这个英文单词,或许想到的更多的是:电影的剧本,就是一段段的脚本,所组成的。电影剧本的脚本,决定了电影中的人和物,都做哪些事情,怎么做。而计算机中的脚本,决定了:计算机中的操作系统和各种软件工具,要做哪些事情,以及具体怎么做。
你可能想要了解脚本与一般程序的区别是什么。
脚本与一般程序的主要区别在于是否编译。相对于程序而言,脚本更加随性。写完了脚本,直接就可以在某种具有解释功能的环境中运行。
而非脚本语言(编译语言),比如 C、Java 语言。我们需要通过编译(Compile)和链接(link)等步骤,生成可执行文件。然后通过可执行文件在计算机上运行。
在脚本中接受原始输入
可以使用内置函数 input 获取用户的原始输入,该函数接受一个可选字符串参数,用于指定在要求用户输入时向用户显示的消息。
name = input("Enter your name: ")
print("Hello there, {}!".format(name.title()))
input 函数获取用户输入的任何内容并将其存储为字符串。如果你想将输入解析为字符串之外的其他类型,例如整数(如以下示例所示),需要用新的类型封装结果并从字符串转换为该类型。
num = int(input("Enter an integer"))
print("hello" * num)
我们还可以使用内置函数 eval 将用户输入解析为 Python 表达式。该函数会将字符串评估为一行 Python 代码。
result = eval(input("Enter an expression: "))
print(result)
#如果用户输入 2 * 3,输出为 6。
处理错误
我们可以使用 try 语句处理异常。你可以使用 4 个子句(除了视频中显示的子句之外还有一个子句)。
try:这是 try 语句中的唯一必需子句。该块中的代码是 Python 在 try 语句中首先运行的代码。
except:如果 Python 在运行 try 块时遇到异常,它将跳到处理该异常的 except 块。
else:如果 Python 在运行 try 块时没有遇到异常,它将在运行 try 块后运行该块中的代码。
finally:在 Python 离开此 try 语句之前,在任何情形下它都将运行此 finally 块中的代码,即使要结束程序,例如:如果 Python 在运行 except 或 else 块中的代码时遇到错误,在停止程序之前,依然会执行此finally 块。
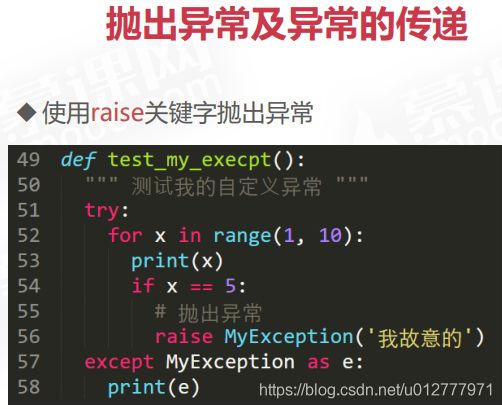
我们实际上可以指定要在 except 块中处理哪个错误,如下所示:
try:
# some code
except ValueError:
# some code
即使已经处理异常以防止程序崩溃,也可以访问错误信息。
try:
# some code
except Exception as e:
# some code
print("Exception occurred: {}".format(e))
Exception 是所有内置异常的基础类。



读写文件
读取文件
f = open('my_path/my_file.txt', 'r')
file_data = f.read()
f.close()
首先使用内置函数 open 打开文件。需要文件路径字符串。open 函数会返回文件对象,它是一个 Python 对象,Python 通过该对象与文件本身交互。在此示例中,我们将此对象赋值给变量 f。
你可以在 open 函数中指定可选参数。参数之一是打开文件时采用的模式。在此示例中,我们使用 r,即只读模式。这实际上是模式参数的默认值。
使用 read 访问文件对象的内容。该 read 方法会接受文件中包含的文本并放入字符串中。在此示例中,我们将该方法返回的字符串赋值给变量 file_data。
当我们处理完文件后,使用 close 方法释放该文件占用的系统资源。
写入文件
f = open('my_path/my_file.txt', 'w')
f.write("Hello there!")
f.close()
以写入 (‘w’) 模式打开文件。如果文件不存在,Python 将为你创建一个文件。如果以写入模式打开现有文件,该文件中之前包含的所有内容将被删除。如果你打算向现有文件添加内容,但是不删除其中的内容,可以使用附加 (‘a’) 模式,而不是写入模式。
使用 write 方法向文件中添加文本。
操作完毕后,关闭文件。
With
Python 提供了一个特殊的语法,该语法会在你使用完文件后自动关闭该文件。
with open('my_path/my_file.txt', 'r') as f:
file_data = f.read()



导入本地脚本
我们实际上可以导入其他脚本中的 Python,如果你处理的是大型项目,需要将代码整理成多个文件并重复利用这些文件中的代码,则导入脚本很有用。如果你要导入的 Python 脚本与当前脚本位于同一个目录下,只需输入 import,然后是文件名,无需扩展名 .py
Import 语句写在 Python 脚本的顶部,每个导入语句各占一行。该 import 语句会创建一个模块对象,叫做 useful_functions。模块是包含定义和语句的 Python 文件。要访问导入模块中的对象,需要使用点记法。
import useful_functions
useful_functions.add_five([1, 2, 3, 4])
我们可以为导入模块添加别名,以使用不同的名称引用它。
import useful_functions as uf
uf.add_five([1, 2, 3, 4])
使用 if main 块
为了避免运行从其他脚本中作为模块导入的脚本中的可执行语句,将这些行包含在 if name == “main” 块中。或者,将它们包含在函数 main() 中并在 if main 块中调用该函数。
每当我们运行此类脚本时,Python 实际上会为所有模块设置一个特殊的内置变量 name。当我们运行脚本时,Python 会将此模块识别为主程序,并将此模块的 name 变量设为字符串 “main”。对于该脚本中导入的任何模块,这个内置 name 变量会设为该模块的名称。因此,条件 if name == "main"会检查该模块是否为主程序。
导入模块技巧
1 要从模块中导入单个函数或类:
from module_name import object_name
2 要从模块中导入多个单个对象:
from module_name import first_object, second_object
3 要重命名模块:
import module_name as new_name
4 要从模块中导入对象并重命名:
from module_name import object_name as new_name
5 要从模块中单个地导入所有对象(请勿这么做):
from module_name import *
6 如果你真的想使用模块中的所有对象,请使用标准导入 module_name 语句并使用点记法访问每个对象。
import module_name
模块、软件包和名称
为了更好地管理代码,Standard 标准库中的模块被拆分成了子模块并包含在软件包中。软件包是一个包含子模块的模块。子模块使用普通的点记法指定。
子模块的指定方式是软件包名称、点,然后是子模块名称。你可以如下所示地导入子模块。
import package_name.submodule_name
第三方库
独立开发者编写了成千上万的第三方库!你可以使用 pip 安装这些库。pip 是在 Python 3 中包含的软件包管理器,它是标准 Python 软件包管理器,但并不是唯一的管理器。另一个热门的管理器是 Anaconda,该管理器专门针对数据科学。
要使用 pip 安装软件包,在命令行中输入“pip install”,然后是软件包名称,如下所示:pip install package_name。该命令会下载并安装该软件包,以便导入你的程序中。安装完毕后,你可以使用从标准库中导入模块时用到的相同语法导入第三方软件包
使用 requirements.txt 文件
大型 Python 程序可能依赖于十几个第三方软件包。为了更轻松地分享这些程序,程序员经常会在叫做 requirements.txt 的文件中列出项目的依赖项。下面是一个 requirements.txt 文件示例。
beautifulsoup44.5.1
bs40.0.1
pytz2016.7
requests2.11.1
该文件的每行包含软件包名称和版本号。版本号是可选项,但是通常都会包含。不同版本的库之间可能变化不大,可能截然不同,因此有必要使用程序作者在写程序时用到的库版本。
你可以使用 pip 一次性安装项目的所有依赖项,方法是在命令行中输入
pip install -r requirements.txt
实用的第三方软件包
IPython - 更好的交互式 Python 解释器
requests - 提供易于使用的方法来发出网络请求。适用于访问网络 API。
Flask - 一个小型框架,用于构建网络应用和 API。
Django - 一个功能更丰富的网络应用构建框架。Django 尤其适合设计复杂、内容丰富的网络应用。
Beautiful Soup - 用于解析 HTML 并从中提取信息。适合网页数据抽取。
pytest - 扩展了 Python 的内置断言,并且是最具单元性的模块。
PyYAML - 用于读写 YAML 文件。
NumPy - 用于使用 Python 进行科学计算的最基本软件包。它包含一个强大的 N 维数组对象和实用的线性代数功能等。
pandas - 包含高性能、数据结构和数据分析工具的库。尤其是,pandas 提供 dataframe!
matplotlib - 二维绘制库,会生成达到发布标准的高品质图片,并且采用各种硬拷贝格式和交互式环境。
ggplot - 另一种二维绘制库,基于 R’s ggplot2 库。
Pillow - Python 图片库可以向你的 Python 解释器添加图片处理功能。
pyglet - 专门面向游戏开发的跨平台应用框架。
Pygame - 用于编写游戏的一系列 Python 模块。
pytz - Python 的世界时区定义。
在线资源的优先级
虽然有很多关于编程的在线资源,但是并非所有资源都是同等水平的。下面的资源列表按照大致的可靠性顺序排序。
Python 教程 - 这部分官方文档给出了 Python 的语法和标准库。它会举例讲解,并且采用的语言比主要文档的要浅显易懂。确保阅读该文档的 Python 3 版本!
Python 语言和库参考资料 - 语言参考资料和库参考资料比教程更具技术性,但肯定是可靠的信息来源。当你越来越熟悉 Python 时,应该更频繁地使用这些资源。
第三方库文档 - 第三方库会在自己的网站上发布文档,通常发布于 https://readthedocs.org/ 。你可以根据文档质量判断第三方库的质量。如果开发者没有时间编写好的文档,很可能也没时间完善库。
非常专业的网站和博客 - 前面的资源都是主要资源,他们是编写相应代码的同一作者编写的文档。主要资源是最可靠的资源。次要资源也是非常宝贵的资源。次要资源比较麻烦的是需要判断资源的可信度。Doug Hellmann 等作者和 Eli Bendersky 等开发者的网站很棒。不出名作者的博客可能很棒,也可能很糟糕。
StackOverflow - 这个问答网站有很多用户访问,因此很有可能有人之前提过相关的问题,并且有人回答了!但是,答案是大家自愿提供的,质量参差不齐。在将解决方案应用到你的程序中之前,始终先理解解决方案。如果答案只有一行,没有解释,则值得怀疑。你可以在此网站上查找关于你的问题的更多信息,或发现替代性搜索字词。
Bug 跟踪器 - 有时候,你可能会遇到非常罕见的问题或者非常新的问题,没有人在 StackOverflow 上提过。例如,你可能会在 GitHub 上的 bug 报告中找到关于你的错误的信息。这些 bug 报告很有用,但是你可能需要自己开展一些工程方面的研究,才能解决问题。
随机网络论坛 - 有时候,搜索结果可能会生成一些自 2004 年左右就不再活跃的论坛。如果这些资源是唯一解决你的问题的资源,那么你应该重新思考下寻找解决方案的方式。