他山之石:网易机器学习工程师二面面经
一、说一下做的最久的项目
二、过程中遇到的问题,解决的办法
三、最近看了什么算法?介绍SVD和xgboost
1、SVD(奇异值分解)
(1)目的:提取出一个矩阵最重要的特征
(2)方阵A: A v = λ v Av = \lambda v Av=λv,其中 v v v是特征向量(彼此正交), λ \lambda λ是特征向量 v v v对应的特征值
(3)特征值分解:
![]()
这里Q是矩阵A的特征向量组成的矩阵, ∑ \sum ∑是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向。(一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换)。当矩阵是高维的情况下,可以利用前N个变化方向近似这个矩阵的线性变换。
(4)特征值分解的局限性:变换的矩阵A必须为方阵。
(5)奇异值分解:
![]()

U是一个M * M的方阵(里面的向量是正交的,U里面的向量称为左奇异向量)
Σ是一个M * N的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值)
V的转置是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量)
(6)奇异值和特征值的对应方法
![]()
这里得到的v,就是我们上面的右奇异向量

这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。
(7)奇异值分解的优点
奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
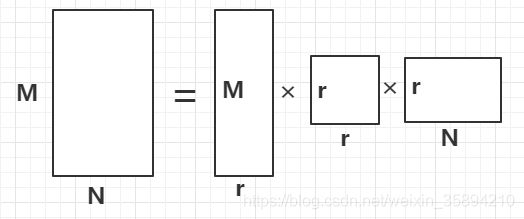
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
(8)奇异值的计算
奇异值的计算是一个难题,是一个O(N^3)的算法。
其实SVD还是可以用并行的方式去实现的,在解大规模的矩阵的时候,一般使用迭代的方法,当矩阵的规模很大(比如说上亿)的时候,迭代的次数也可能会上亿次,如果使用Map-Reduce框架去解,则每次Map-Reduce完成的时候,都会涉及到写文件、读文件的操作。个人猜测Google云计算体系中除了Map-Reduce以外应该还有类似于MPI的计算模型,也就是节点之间是保持通信,数据是常驻在内存中的,这种计算模型比Map-Reduce在解决迭代次数非常多的时候,要快了很多倍。
(9)奇异值与主成分分析(PCA)
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
![]()
之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…
2、xgboost
数学原理
1、目标函数公式推导(忽略原文中的r和diag,应该是图片显示问题),这里面是以决策树为奇函数做的推导,如果使用线性模型为基函数,在正则化项有变化,直接使用L2正则化就可以了,但是无法将每个样本节点转化为叶子结点(小样本和)进行化简。
2、最优切分点划分算法
如何找到叶子结点的最优切分点,Xgboost支持两种节点分裂方法:贪心算法和近似算法
(1)贪心算法
a.如何计算分裂收益?分裂前的目标函数-分裂后的目标函数;该特征收益也可作为特征重要性输出的重要依据。观察分裂后的收益,我们会发现节点划分不一定会使得结果变好,因为我们有一个引入新叶子的惩罚项,也就是说引入的分割带来的增益如果小于一个阀值的时候,我们可以剪掉这个分割。
(2)近似算法
贪婪算法可以的到最优解,但当数据量太大时则无法读入内存进行计算(无法进行扫描前的排序),近似算法主要针对贪婪算法这一缺点给出了近似最优解。对于每个特征,只考察分位点可以减少计算复杂度。该算法会首先根据特征分布的分位数提出候选划分点,然后将连续型特征映射到由这些候选点划分的桶中,然后聚合统计信息找到所有区间的最佳分裂点。在提出候选切分点时有两种策略:
a. Global:学习每棵树前就提出候选切分点,并在每次分裂时都采用这种分割;
b. Local:每次分裂前将重新提出候选切分点。
直观上来看,Local 策略需要更多的计算步骤,而 Global 策略因为节点没有划分所以需要更多的候选点。
事实上, XGBoost 不是简单地按照样本个数进行分位,而是以二阶导数值 h i hi hi作为样本的权重进行划分(加权分位数缩略图)。
3、稀疏感知算法(应对数据缺失)
XGBoost 在构建树的节点过程中只考虑非缺失值的数据遍历,而为每个节点增加了一个缺省方向,当样本相应的特征值缺失时,可以被归类到缺省方向上,最优的缺省方向可以从数据中学到。至于如何学到缺省值的分支,其实很简单,分别枚举特征缺省的样本归为左右分支后的增益,选择增益最大的枚举项即为最优缺省方向。(注意这里不是将所有的样本统一划分到左右分支,而是分别枚举,如果含缺失值的样本很多,那将造成很大的计算量,是否可以设计一个阈值?当缺失特征样本数量超过总样本量的多少百分比之后,直接全体划分到左右分之,或根据重要特征分桶划分)在构建树的过程中需要枚举特征缺失的样本,乍一看该算法的计算量增加了一倍,但其实该算法在构建树的过程中只考虑了特征未缺失的样本遍历,而特征值缺失的样本无需遍历只需直接分配到左右节点,故算法所需遍历的样本量减少,下图可以看到稀疏感知算法比 basic 算法速度块了超过 50 倍。
工程实现
1、块结构设计:减少寻找最佳分裂点的计算消耗。
XGBoost 在训练之前根据特征对数据进行了排序(本来有一份样本,每个样本有5个特征,每个特征都需要对数据重新排序,那需要存储5倍于原样本总量的数据),然后保存到块结构中,并在每个块结构中都采用了稀疏矩阵存储格式(Compressed Sparse Columns Format,CSC)进行存储,后面的训练过程中会重复地使用块结构,可以大大减小计算量。
(1) 将排序后的数据保存在CSC块存储结构中,能够减少存储量;
(2) 预排序的操作使得在进行分裂节点扫描时加快了选择进度;
(3) 块结构存储的特征之间相互独立,在对节点进行分裂时需要选择增益最大的特征作为分裂,这时各个特征的增益计算可以同时进行;
(4) 每个特征会存储指向样本梯度统计值的索引,方便计算一阶导和二阶导数值.
2、核外块计算
当数据量过大时无法将数据全部加载到内存中,只能先将无法加载到内存中的数据暂存到硬盘中,直到需要时再进行加载计算,而这种操作必然涉及到因内存与硬盘速度不同而造成的资源浪费和性能瓶颈。为了解决这个问题,XGBoost 独立一个线程专门用于从硬盘读入数据,以实现处理数据和读入数据同时进行。
此外,XGBoost 还用了两种方法来降低硬盘读写的开销:
**块压缩:**对 Block 进行按列压缩,并在读取时进行解压;
**块拆分:**将每个块存储到不同的磁盘中,从多个磁盘读取可以增加吞吐量。
优缺点
1、优点:
(1) 基分类器可以是决策树也可以是线性模型,更加灵活;
(2) 损失函数进行了二阶泰勒展开,一方面增加了精度,另一方面也是为了能够自定义损失函数,二阶泰勒展开可以近似大量损失函数;
(3) 损失函数中增加了正则化项,控制模型复杂度,有助于防止过拟合;
(4) 支持列抽样,降低过拟合,减少计算量;
(5) 缺失值处理:稀疏感知算法极大的加快了节点分裂速度;
(6) 并行化操作: 块结构的设计可以很好的支持并行计算.
2、缺点:
(1) 虽然利用预排序和近似算法可以降低寻找最佳分裂点的计算量, 但在节点分裂过程中仍然需要遍历数据集;
(2) 预排序过程的空间复杂度过高,不仅需要存储特征值, 还要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存.
四、xgboost如何进行正则化?如何并行?
xgboost损失函数如下:
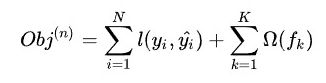
第二部分即为正则化项(基模型为决策树),正则化函数具体如下:

这里主要是两个参数: γ \gamma γ、 λ \lambda λ。其中 γ \gamma γ值限制树的叶节点数量, λ \lambda λ限制每个叶节点的权值大小。添加正则项也是对于树模型剪枝的过程。
并行:这种块结构存储的特征之间相互独立,方便计算机进行并行计算。在对节点进行分裂时需要选择增益最大的特征作为分裂,这时各个特征的增益计算可以同时进行,这也是 Xgboost 能够实现分布式或者多线程计算的原因。
五、C++指针和引用的区别?
(1)定义:
指针:指针是一个变量,只不过这个变量存储的是一个地址,指向内存的一个存储单元;
引用:引用跟原来的变量实质上是同一个东西,只不过是原变量的一个别名而已。
如:
int a=1;int *p=&a;
int a=1;int &b=a;
上面定义了一个整形变量和一个指针变量p,该指针变量指向a的存储单元,即p的值是a存储单元的地址。而下面2句定义了一个整形变量a和这个整形a的引用b,事实上a和b是同一个东西,在内存占有同一个存储单元。
(2)引用不可以为空,当被创建的时候,必须初始化,而指针可以是空值,可以在任何时候被初始化。
(3)指针的值在初始化后可以改变,即指向其它的存储单元,而引用在进行初始化后就不会再改变了。
(4)可以有const指针,但是没有const引用;
(5)指针可以有多级,但是引用只能是一级(int **p;合法 而 int &&a是不合法的)
(6)如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄漏;
(7)”sizeof引用”得到的是所指向的变量(对象)的大小,而”sizeof指针”得到的是指针本身的大小;
(8)指针和引用的自增(++)运算意义不一样;
六、C++虚函数
(1)虚函数定义在基类中其他继承此基类的派生类都可以重写该虚函数,虚函数是C++语言多态特性中非常重要的概念。了解虚函数,主要弄明白一个问题:派生类也可以重写基类中的其他的常规函数(非虚函数)呀,那为什么还要引入虚函数这样看起来很复杂的概念呢?
举例说明其实解决的主要问题是,当基类中的一个函数被多个派生类重写的时候,如果只通过基类指针访问,即使传入的是派生类对象,也只能访问基类中的函数,但是通过重写虚函数,即使通过基类指针访问,只要传入的是派生类对象,就会调用派生类的函数。
(2)常规的非虚函数是静态解析的,即在编译时即可根据指针指向的对象确定是否被调用;而虚函数就不同了,它是动态解析的,也即在程序被编译后,运行时才根据对象的类型,而不是指向对象的指针类型决定其是否被调用,这就是说为的“动态绑定”。
(3)如果某个类有虚函数,那么大多数编译器都会自动的为其对象维护一个隐藏的“虚指针(virtul-pointer)”,虚指针指向一个全局“虚表(virtual-table)”,虚表中存放若干函数指针,这些函数指针指向类中的虚函数。虚表是属于类的,而不是对象的,也就是说,即使有成千上万个 A 对象,虚表也仅有一个,这些对象共用一个类虚表。
(4)一昧的使用虚函数可能会造成语义上的歧义,隐藏程序员的设计。仅将需要被继承的基类中需要被重写的函数定义为虚函数,要比将所有函数定义为虚函数清晰多了。(程序可读性低);虚函数的效率实际上是没有常规函数高的,同样的功能中,仅从被调用过程来看,它的时间开销和空间开销都比常规函数高,每个对象还需要额外的虚指针索引虚表。(效率低,占内存)
七、Python有哪些数据类型?
数值型(整型、浮点型、布尔型、复数)、集合、字符串、元组、列表、字典
八、python lambda?
python 使用 lambda 来创建匿名函数。
lambda只是一个表达式,函数体比def 简单很多,并不会带来程序运行效率的提高。
lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
配合着filter\map\reduce等python内置函数体使用
可以使用for … in … if的列表表达式代替lambda
九、堆和栈的区别?从操作系统和数据结构角度?
操作系统角度:
1、堆空间的内存是动态分配的,一般存放对象,并且需要手动释放内存。堆空间比较大。堆空间一般存放对象本身,block的copy等。分配方式类似于数据结构中的链表。相比在栈上分配内存要慢。可能造成内存泄露。(二级缓存)
2、栈空间的内存是由系统自动分配,一般存放参数值、局部变量,比如对象的地址等值,不需要程序员对这块内存进行管理,比如,函数中的局部变量的作用范围(生命周期)就是在调完这个函数之后就结束了。这些在系统层面都已经限定住了,程序员只需要在这种约束下进行程序编程就好,根本就没有把这块内存的管理权给到程序员,肯定也就不存在让程序员管理一说。栈空间比较小。栈空间中一般存储基本数据类型,对象的地址。(一级缓存)
数据结构角度:
栈:先进后出,数据项按序排列的数据结构;
堆:堆是一种经过排序的树形数据结构。每个节点都有一个值,通常我们所说的堆的数据结构是指二叉树。所以堆在数据结构中通常可以被看做是一棵树的数组对象。而且堆需要满足以下两个性质:
(1)堆中某个节点的值总是不大于(最小堆,小根堆)或不小于(最大堆,大根堆)其父节点的值;
(2)堆总是一棵完全二叉树。
十、进程和线程的区别?

进程:一个内存中的应用程序(windows .exe),每个进程都拥有自己独立的一块内存空间。
线程:进程中的一个执行任务(控制单元),负责当前进程中程序的执行,多个线程可共享数据。(不能独立存在)
同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多。(共享堆,独有栈)
根本区别:进程是操作系统资源分配的基本单位(OS),而线程是处理器任务调度和执行的基本单位(CPU);
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但一个线程崩溃整个进程都死掉。所以多进程比多线程健壮。
十一、文件描述符是什么?
Linux 中一切皆文件,比如 C++ 源文件、视频文件、Shell脚本、可执行文件等,就连键盘、显示器、鼠标等硬件设备也都是文件。一个 Linux 进程可以打开成百上千个文件,为了表示和区分已经打开的文件,Linux 会给每个文件分配一个编号(一个 ID),这个编号就是一个整数,被称为文件描述符(File Descriptor)。
文件描述符是动态分配的,而所有的文件都在“打开文件表”和’i-node表"中有备案,文件描述符就是将自己的“描述”与实际的备案表相对应,从而实现对文件的读写。
十二、进程间的通信方法(本地进程)?
1、为什么需要进程通信?
有时候想要在两个进程之间实现数据传输、资源共享、通知事件(例如进程终止时会通知父进程)以及进程控制。但是进程之间是相互独立的,都有自己独立的虚拟内存空间,很难通信,这时候内核就提供一份公共资源让多个进程都可以访问,借此实现进程间的通信(类似,天南海北的买家和卖家无法直接有金钱交易,就出现了第三方支付宝,一个公共平台)
2、通信方式及特点
(1)管道:(管道在Linux环境下也是一个文件)管道也是一个文件,多个进程都能看到,进程A在管道一头写数据,进程B在就可以在另一端读数据。管道又分为匿名管道和命名管道,匿名管道用pipe()创建,只能在就有亲缘关系(父子进程)的进程间通信,而命名管道适用于任意进程。命名管道的特点a.适用于任意进程;b.面向字节流;c.半双工通信;d.生命周期随进程;e.内置同步与互斥机制。(京东送货到家,本人签收,TCP)
(2)消息队列:(固定大小)消息队列是一个链表,进程A可以向队列中写数据,队列中一旦有数据了,进程B就可以开始读数据,读完了就不能再读了(圆通、韵达到快递站点自取,UDP)。消息队列的特点:a.适用于任意进程;b.面向数据报;c.全双工通信(读写);生命周期随内核;e.内置同步与互斥机制
(3)共享内存:内存可以随机访问,将一块物理内存映射到不同的虚拟地址空间,不同的虚拟空间即代表不同的进程,所以多个进程可以共享这块内存进行读写。共享内存是进程间通信最快的方式。(越接近底层,速度越快)。共享内存特点:a.适用于任意进程;b.全双工通信;c.生命周期随内核。
(4)信号量:可以理解为是一个计数器加上等待队列,当多个进程同时访问临界资源就会产生死锁,信号量记录可申请的资源的数量,没申请一次信号量减1,用完释放就加1,等待队列就是当信号量为0时,在申请临界资源的线程就会加入等待队列,一旦有资源释放,就可以申请到。信号量的特点:同步与互斥。
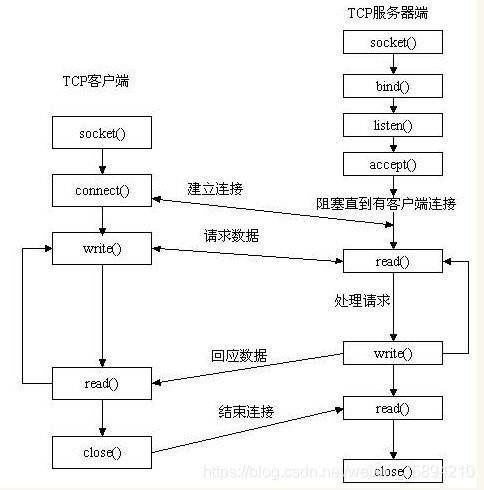
十三、介绍socket(网络进程通信)?
基于TCP/IP协议,连通网络上不同计算机程序之间的管道,把一堆数据从管道A端扔进去,会从管道的B端(C\D\E…)冒出来。管道的端口由两个信息确定:IP地址和程序端口号。(利用三元组(ip地址,协议,端口)就可以标识网络的进程)
Socket可以支持数据的发送和接收,它会定义一种称为套接字的变量,发送数据时首先创建套接字,然后使用该套接字的sendto等方法对准某个IP/端口进行数据发送;接收端也首先创建套接字,然后将该套接字绑定到一个IP/端口上,所有发向此端口的数据会被该套接字的recv等函数读出。如同读出文件中的数据一样。(下图是socket工作原理)
TCP/IP的socket提供下列三种类型套接字:流式套接字、数据报式套接字、原始式套接字。
十四、梯度消失和梯度爆炸的原因和解决办法?
前提:深层神经网络,使用梯度下降法(迭代法)去更新网络参数,减小目标函数(结构风险最小化)。
当网络很深时,采用反向传播算法进行链式求导计算梯度,使得梯度更新的变化量是指数增加的(连乘效应),这时就会出现梯度消失和梯度爆炸!!
梯度消失的原因:饱和激活函数在梯度值变化在饱和区间时,梯度几乎为0,指数变化导致梯度接近于0;
梯度爆炸的原因:权值初始值太大导致梯度大于1,指数变化使得梯度无限放大。
解决办法:
(1)梯度剪切+权重正则化(梯度爆炸)
(2)采用ReLU激活函数系列
(3)BN
参考文章:
1、https://blog.csdn.net/m0_37673307/article/details/82317696
2、https://www.jianshu.com/p/5f148c3e4f7d
3、https://blog.csdn.net/ThinkWon/article/details/102021274
4、https://blog.csdn.net/wan13141/article/details/89433379
5、https://blog.csdn.net/cx2479750196/article/details/81150955
6、https://www.cnblogs.com/wangcq/p/3520400.html
7、https://baijiahao.baidu.com/s?id=1653132502323288772&wfr=spider&for=pc
8、https://www.cnblogs.com/hotsnow/p/9925593.html